结合ViT和LLM的力量进行图像-文本检索任务

引言
图像与语言看似属于两个不同的领域,
以及与之相关的常见问题。显然,解决图像分类或物体分割任务时,我们关注的是图像;而在进行情感分析或意图识别任务时,我们只关注相关的文本。但若我请你描述一张图片,语言与视觉之间便建立了联系。图像与文本的交互催生了新的研究分支,如视觉问答、图像描述、图像-文本检索以及从文本提示生成新图像等。
在这个故事中,我关注的是图像-文本检索任务。假设你有一个数据库,存储了成千上万的图像,而你想找到其中某一张。最新的算法提供了多种搜索方式。如果你幸运的话,你可能拥有该图像的副本或知道它在数据库中的确切位置。否则,你可以通过使用相似的图像、描述它,或结合相似图像与描述来进行搜索。
在这里,我想展示BLIP[1]和BLIP-2[2]算法是如何解决图像-文本检索任务的。作为一个热爱烹饪的意大利人,我创建了一个小型玩具数据集,包含了各种类型的菜肴。我从网上下载了总共68张图片,分为披萨、第一道菜、第二道菜和甜点。因此,每张图片我都用意大利语编写了相应的描述。在推理时,由于模型是在英语中训练的,我利用deep-translator包自动将每条描述翻译成英语。图[1]展示了每种菜肴的示例。

图1. 玩具数据集中使用的菜肴示例。每张图片都配有一条先以意大利语编写,后翻译成英语的描述
你可以在我的GitHub仓库中找到此故事的数据集和代码,链接如下:链接。
BLIP与BLIP-2
注意力机制极大地推动了文本和图像分析新技术的开发。如今,从大型语言模型(如BERT、GPT或Llama)到视觉转换器(ViT),都采用了转换器类型的架构。
BLIP和BLIP-2代表“引导语言-图像预训练,用于统一视觉-语言理解和生成”。通过LLM和ViT,BLIP和BLIP-2在视觉-语言任务(如图像描述、视觉问答和图像-文本检索)上取得了非常显著的成果。它们是视觉-语言预训练模型。严格来说,它们的训练分为两个步骤。首先,它们以通用方式进行预训练,然后在特定的下游任务上进行微调。
BLIP
BLIP架构由两个组件构成,如图[2]所示。一个视觉转换器作为图像编码器,将输入图像分割成块并编码为嵌入序列。另一个转换器作用于文本,根据情况可以是编码器或解码器。为了预训练一个兼具理解和生成能力的统一模型,该架构是一个多模态混合的编码器-解码器,即一个多任务模型,可以执行以下三种功能之一:
- unimodal encoder,单模态编码器,分别编码图像和文本,其中文本编码器与BERT相同
- image-grounded text encoder,图像基础文本编码器,通过在文本编码器的每个转换器块的自注意力层和前馈网络之间插入一个额外的交叉注意力层来注入视觉信息
- image-grounded text decoder,图像基础文本解码器,将图像基础文本编码器中的双向自注意力层替换为因果自注意力层

图2. BLIP的预训练模型架构和目标
预训练阶段通过联合优化以下三个目标进行:
- 图像-文本对比损失(Image-Text Contrastive Loss,ITC)激活单模态编码器。其目的是通过鼓励正样本图像-文本对在特征空间中具有相似表示,与负样本对形成对比,来对齐视觉和文本转换器的特征空间
- 图像-文本匹配损失(Image-Text Matching Loss,ITM)激活图像基础文本编码器。其目的是学习能够捕捉视觉和语言之间细粒度对齐的图像-文本多模态表示。ITM是一个二分类任务,模型使用ITM头来预测给定其多模态特征的图像-文本对是正样本(匹配)还是负样本(不匹配)
- 语言建模损失(Language Modeling Loss,LM)激活图像基础文本解码器,其目的是根据图像生成文本描述
每个图像-文本对只需通过视觉转换器进行一次前向传递,并通过文本转换器进行三次前向传递,以激活不同的功能来计算三个损失。为了在利用多任务学习的同时进行高效预训练,文本编码器和解码器共享除自注意力层外的所有参数,因为正是这一层捕捉了编码和解码任务之间的差异。
预训练阶段从初始化图像转换器为在ImageNet上预训练的ViT-B,以及文本转换器为BERT base开始。作为预训练数据集,使用了COCO、Visual Genome、Conceptual Captions、Conceptual 12M、SBU captions和LAION数据集的联合,总共包含129M个图像-文本对。
在微调阶段,模型针对特定任务进行优化。特别是对于图像-文本检索任务,预训练模型在COCO上使用ITC和ITM损失进行微调。
BLIP-2
由于预训练的视觉模型提供了高质量的视觉表示,而预训练的LLM提供了强大的语言生成和零样本迁移能力,BLIP-2架构及其训练策略试图从这两个组件中提取最佳性能。为了降低计算成本并对抗灾难性遗忘问题,单模态预训练模型在预训练阶段保持冻结状态。
BLIP-2引入了一个新组件,即查询转换器(Q-Former),作为一个可训练模块,以桥接冻结的图像编码器和冻结的LLM之间的差距。如图[3]所示,Q-Former通过两阶段预训练策略进行预训练。在第一阶段,进行视觉-语言表示学习,强制Q-Former学习对文本最相关的视觉表示。在第二阶段,通过将Q-Former的输出连接到冻结的LLM,并训练Q-Former使其输出视觉表示能被LLM解释,进行视觉到语言的生成学习。

图3. 带有两阶段预训练策略的BLIP-2框架
如图[4]所示,Q-Former由两个共享相同自注意力层的转换器子模块组成。有一个图像转换器与冻结的图像编码器交互,用于视觉特征提取,以及一个同时作为文本编码器和解码器的文本转换器。图像转换器的输入是一组32个可学习的查询向量,每个向量的维度为768,它们通过自注意力层相互交互,并通过交叉注意力层与冻结的图像特征交互。Q-Former初始化为BERT-base的预训练权重,而交叉注意力层则是随机初始化的。

图4. (左)Q-Former的模型架构和BLIP-2第一阶段视觉-语言表示学习目标。(右)每个目标的自注意力掩码策略,以控制查询-文本交互
在视觉-语言表示学习阶段,Q-Former与冻结的图像编码器相连,并使用图像-文本对进行预训练。这一阶段的目的是训练Q-Former,使得查询能够学习提取对文本最有信息价值的视觉表示。至于BLIP,联合优化了三个预训练目标,即图像-文本对比学习、基于图像的文本生成和图像-文本匹配。每个目标共享相同的输入格式和模型参数,但采用不同的查询与文本之间的注意力掩蔽策略来控制它们的交互(见图[4])。

图5. BLIP-2的第二阶段视觉到语言生成预训练,从冻结的大型语言模型(LLMs)引导。(顶部)引导基于解码器的LLM(例如OPT)。(底部)引导基于编码器-解码器的LLM(例如FlanT5)。
在生成预训练学习阶段,Q-Former一侧与冻结的视觉编码器相连,另一侧与冻结的LLM相连。如图[5]所示,一个全连接(FC)层将输出查询嵌入投影到与LLM的文本嵌入相同的维度。投影后的查询嵌入随后被前置到输入文本嵌入中。它们作为软视觉提示,根据Q-Former提取的视觉表示来条件化LLM。
BLIP-2已经实验了两种类型的LLM:基于解码器的LLM和基于编码器-解码器的LLM。对于基于解码器的LLM,使用了OPT系列的无监督训练模型。在这种情况下,预训练伴随着语言建模损失,冻结的LLM被任务生成基于Q-Former视觉表示的文本。对于基于编码器-解码器的LLM,使用了FlanT5系列的指令训练模型。在这种情况下,预训练伴随着前缀语言建模损失,文本被分成两部分。前缀文本与视觉表示连接作为LLM编码器的输入。后缀文本用作LLM解码器的生成目标。
为了更准确地理解BLIP-2,除了原始论文外,我建议阅读以下非常精彩的故事
实验
对于图像-文本检索任务,我尝试了五个模型:BLIP预训练、BLIP在COCO上微调、BLIP-2预训练与ViT-g/14、BLIP-2预训练与ViT-L/14、BLIP-2在COCO上微调。为了看到差异,对于每个模型,我执行了相同的流程,构建了相同的相似度矩阵,并在相同的图像和文本上进行了测试。
加载模型
BLIP和BLIP-2架构在LAVIS项目中发布,其GitHub位于此链接。为了使用预训练模型,只需使用pip命令安装LAVIS库
pip install salesforce-lavis
安装后,从_model_zoo_中我们可以看到所有支持的模型
from lavis.models import model_zoo
print(model_zoo)
==================================================
Architectures Types
==================================================
albef_classification ve
albef_feature_extractor base
albef_nlvr nlvr
albef_pretrain base
albef_retrieval coco, flickr
albef_vqa vqav2
alpro_qa msrvtt, msvd
alpro_retrieval msrvtt, didemo
blip_caption base_coco, large_coco
blip_classification base
blip_feature_extractor base
blip_image_text_matching base, large
blip_nlvr nlvr
blip_pretrain base
blip_retrieval coco, flickr
blip_vqa vqav2, okvqa, aokvqa
blip2_opt pretrain_opt2.7b, pretrain_opt6.7b, caption_coco_opt2.7b, caption_coco_opt6.7b
blip2_t5 pretrain_flant5xl, pretrain_flant5xl_vitL, pretrain_flant5xxl, caption_coco_flant5xl
blip2_feature_extractor pretrain, pretrain_vitL, coco
blip2 pretrain, pretrain_vitL, coco
blip2_image_text_matching pretrain, pretrain_vitL, coco
pnp_vqa base, large, 3b
pnp_unifiedqav2_fid
img2prompt_vqa base
clip_feature_extractor ViT-B-32, ViT-B-16, ViT-L-14, ViT-L-14-336, RN50
clip ViT-B-32, ViT-B-16, ViT-L-14, ViT-L-14-336, RN50
gpt_dialogue base
要使用BLIP架构执行图像-文本检索任务,我们可以使用以下命令实例化base pretrained模型与ViT-B图像变换器以及图像和文本处理器
要使用BLIP-2架构实例化图像-文本检索模型,您必须使用相同的命令,name = “blip2_feature_extractor” 和 model_type = “pretrain”, “pretrain_vitL” 或 “coco”,分别为来自EVA-CLIP的ViT-g14图像变换器模型、来自CLIP的ViT-L14图像变换器模型和在COCO数据集上微调的模型。如源代码中所述,blip2_feature_extractor功能是通过第一阶段模型与Q-Former和视觉变换器获得的。
一旦模型被实例化,我们可以加载图像,将文本从意大利语翻译成英语,预处理它们,最后提取图像、文本和多模态特征嵌入如下
不幸的是,LAVIS包不支持在COCO上微调的BLIP模型。只能使用在此GitHub发布的BLIP项目代码来测试此模型。要克隆项目,实例化模型,预处理图像和文本,并提取图像、文本和多模态特征,我们必须执行以下步骤
from lavis.models import load_model_and_preprocess
model, vis_processors, txt_processors = load_model_and_preprocess(name="blip_feature_extractor", model_type="base", is_eval=True, device=device)
要使用BLIP-2架构实例化一个图像-文本检索模型,你必须使用相同的命令,其中 name 参数设置为 "blip2_feature_extractor",而 model_type 参数可以分别设置为 "pretrain"、"pretrain_vitL" 或 "coco",以分别使用来自EVA-CLIP的ViT-g/14图像变换器、来自CLIP的ViT-L/14图像变换器,以及在COCO数据集上微调后的模型。正如源代码中指定的,blip2_feature_extractor 功能是通过使用带有Q-former和视觉变换器的第一阶段模型获得的。
一旦模型被实例化,我们可以加载一张图片,将文本从意大利语翻译成英语,预处理它们,最后,按照以下方式提取图像、文本和多模态特征嵌入:
def translate_caption(string):
try:
#print('ita_string: ', string)
string_translated = GoogleTranslator(source='auto', target='en').translate(string)
#print('string_translated: ', string_translated)
return string_translated
except Exception as e:
string_translated = ''
print("Errore per ita_string '{}' - caption '{}' - errore: {}".format(string))
return string_translated
# load image
image = Image.open(path_image).convert("RGB")
#preprocess image
image_processed = vis_processors["eval"](image_target).unsqueeze(0).to(device)
#translate text from ita to eng
text = translate_caption(original_text)
# preprocess text
text_translated = translate_caption(text_target)
text_input = txt_processors["eval"](text_translated)
# build sample
sample = {"image": image_processed, "text_input": [text_input]}
# find features of image and text target
multimodal_emb = model.extract_features(sample).multimodal_embeds[0,0,:] # size (768)
image_emb = model.extract_features(sample, mode="image").image_embeds[0,0,:] # size (768)
text_emb = model.extract_features(sample, mode="text").text_embeds[0,0,:] # size (768)
很遗憾,LAVIS软件包不支持在COCO上微调的BLIP模型。我们可以通过使用在该GitHub上发布的BLIP项目的代码来测试此模型。为了克隆项目、实例化模型、预处理图像和文本,并提取图像、文本和多模态特征,我们需要执行以下步骤:
import sys
#clone the BLIP project
if 'google.colab' in sys.modules:
print('Running in Colab.')
!pip3 install transformers==4.15.0 timm==0.4.12 fairscale==0.4.4
!git clone https://github.com/salesforce/BLIP
%cd BLIP
# function to preprocess the image
def transform_image(image, image_size):
transform = transforms.Compose([
transforms.Resize((image_size,image_size),interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
])
image = transform(image)
return image
# intantiate the BLIP model finetuned on COCO
from models.blip import blip_feature_extractor
image_size = 224
model_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_retrieval_coco.pth'
model = blip_feature_extractor(pretrained=model_url, image_size=image_size, vit='base')
model.eval()
model = model.to(device)
# preprocess the image
image_processed = transform_image(image, image_size).unsqueeze(0).to(device)
# translate the text
text_input = translate_caption(text)
# find features of image and text target
with torch.no_grad():
multimodal_emb = model(image_processed, text_input, mode='multimodal')[0,0] # size (768)
image_emb = model(image_processed, text_input, mode='image')[0,0] # size (768)
text_emb = model(image_processed, text_input, mode='text')[0,0] # size (768)
相似度矩阵
有了玩具数据集的图像-文本对,对于每个模型,我计算了图像、文本和多模态向量嵌入的列表。我想看看各种嵌入之间的关系,因此我计算了它们的余弦相似度。对于每个模型,我检查了一些余弦相似度的组合,如图像-图像、图像-文本、多模态-多模态和图像-多模态。在以下示例中,是LAVIS包支持的某个模型的流程。
相似度矩阵显示了所选每个模型的或多或少相同的模式。在图[6]和[7]中显示了BLIP-2预训练ViT-L模型的结果。从图[6]左侧,您可以看到在图像-图像情况下,最高值集中在对角线上,即图像嵌入特征按菜肴分组。然而,尤其是由于番茄酱意大利面,许多高相似度分数出现在意大利面和比萨的图像之间。同样的行为,但相似度值较低,在图像-文本(图[6]右侧)和图像-多模态情况下(图[7]左侧)也得到了。多模态-多模态情况没有显示出特别的模式。

图6.(左)图像-图像矩阵相似度。(右)图像-文本矩阵相似度。两个矩阵均指BLIP-2 ViT-L模型

图6.(左)图像-多模态矩阵相似度。(右)多模态-多模态矩阵相似度。两个矩阵均指BLIP-2 ViT-L模型
搜索功能
一旦加载了图像-文本对并计算了它们的图像、文本和多模态嵌入,就到了从菜肴数据库中搜索图像的时候了。对于每个模型,我尝试了图像-图像和文本-图像模式搜索,尽管您可以根据可用信息尝试任何类型的搜索组合,如下面的函数所示。
在下面,我展示了一些使用BLIP-2预训练ViT-L模型获得的结果,至少在这些示例中,似乎比其他模型表现更好。我给出一个目标图像在左侧,并要求模型给我数据集中最相似的五个图像,那些在右侧。





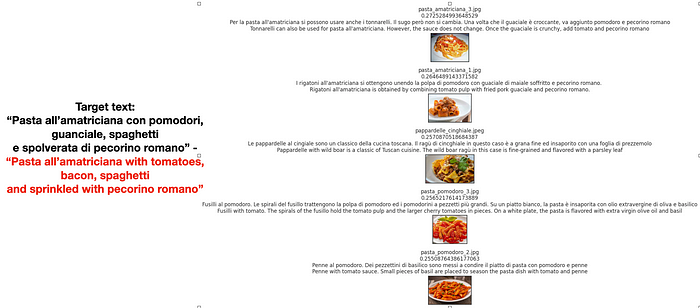
在以下案例中,我给出了左侧的目标文本,并要求模型从数据集中为我提供五个最相似的图像,即右侧的图像。在第二次请求中出现了一个小错误,野猪肉酱宽面条在搜索中排名第二,而排名第一的是阿马特里西娅通心粉。



尝试更多实验!此外,如果你有一个包含大量图像-文本对的数据集,你可以在其上对模型进行微调。BLIP和BLIP-2项目为你提供了所有代码,以便在你的自定义数据集上执行微调操作。
感谢阅读。如果你喜欢,请点赞!
参考文献
[1] BLIP-2: BLIP: 引导语言-图像预训练用于统一视觉-语言理解和生成,https://arxiv.org/abs/2301.12597
[2] BLIP-2: 使用冻结图像编码器和大型语言模型引导语言-图像预训练,https://arxiv.org/abs/2301.12597
标签:模态,text,image,BLIP,图像,特征提取,文本,模型 From: https://www.cnblogs.com/IcyFeather/p/18293836