Boosting、Bagging主要关注降低偏差还是方差?
最近在做项目的过程中遇到了集成学习中的stagging方法,让我想起了之前参加面试的时候碰到的一个问题:Boosting主要关注降低偏差还是方差?Bagging主要关注降低偏差还是方差?这个问题还是很有意思的,如果之前没有看过,即便了解Boosting、Bagging的内容也不一定能很快反应过来。
先公布一下答案
答案:从偏差-方差分解的角度看,Boosting主要关注降低偏差,Bagging主要关注降低方差
偏差-方差分解
"偏差-方差分解" (bias-variance decomposition) 是解释学习算法泛化性能的一种重要工具。
回顾偏差、方差、噪声的含义:偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
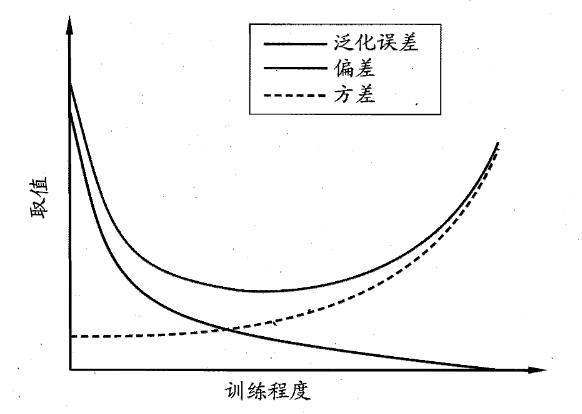
一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境 (bias-variance dilemma)。下面给出了一个示意图给定学习任务,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合。
Boosting
Boosting 是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注, 然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值 T ,最终将这 T 个基学习器进行加权结合。
可以看出,Boosting 方法关注那些先前基学习器做错的训练样本, 并在后续训练中更多加关注这些样本,显然这是降低偏差。
Bagging
Bagging是并行式集成学习方法最著名的代表。它直接基于自助采样法 (bootstrap sampling)。 给定包含 m 个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过 m 次随机采样操作,得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现。
照这样,可以采样出 T 个含 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。
可以看出, Bagging的过程就是为了减轻同样大小的训练集的变动所导致的学习性能的变化,从偏差方差分解的角度看, Bagging 主要关注降低方差。
参考资料
[1] 周志华. 机器学习[M]. 清华大学出版社, 2016.
标签:Bagging,偏差,训练,方差,学习,Boosting From: https://www.cnblogs.com/zhangdoudou/p/18286284