业务数据脱敏
一、什么是数据脱敏
先来看看什么是数据脱敏?数据脱敏也叫数据的去隐私化,在我们给定脱敏规则和策略的情况下,对敏感数据比如 手机号、银行卡号 等信息,进行转换或者修改的一种技术手段,防止敏感数据直接在不可靠的环境下使用。
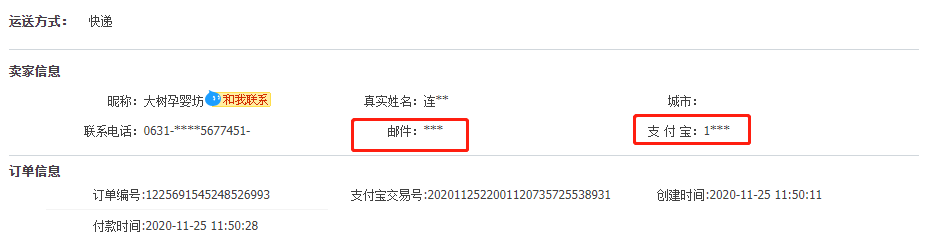
像政府、医疗行业、金融机构、移动运营商是比较早开始应用数据脱敏的,因为他们所掌握的都是用户最核心的私密数据,如果泄露后果是不可估量的。数据脱敏的应用在生活中是比较常见的,比如我们在淘宝买东西订单详情中,商家账户信息会被用 * 遮挡,保障了商户隐私不泄露,这就是一种数据脱敏方式。
数据脱敏又分为静态数据脱敏(SDM)和 动态数据脱敏(DDM):
二、静态数据脱敏
静态数据脱敏(SDM):适用于将数据抽取出生产环境脱敏后分发至测试、开发、培训、数据分析等场景。
有时我们可能需要将生产环境的数据 copy 到测试、开发库中,以此来排查问题或进行数据分析,但出于安全考虑又不能将敏感数据存储于非生产环境,此时就要把敏感数据从生产环境脱敏完毕之后再在非生产环境使用。
这样脱敏后的数据与生产环境隔离,满足业务需要的同时又保障了生产数据的安全。

如上图所示,将用户的真实 姓名、手机号、身份证、银行卡号 通过 替换、无效化、乱序、对称加密 等方案进行脱敏改造。
三、动态数据脱敏
动态数据脱敏(DDM):一般用在生产环境,访问敏感数据时实时进行脱敏,因为有时在不同情况下对于同一敏感数据的读取,需要做不同级别的脱敏处理,例如:不同角色、不同权限所执行的脱敏方案会不同。
注意:在抹去数据中的敏感内容同时,也需要保持原有的数据特征、业务规则和数据关联性,保证我们在开发、测试以及数据分析类业务不会受到脱敏的影响,使脱敏前后的数据一致性和有效性。
总之一句话:你爱怎么脱就怎么脱,别影响我使用就行。
四、数据脱敏方案
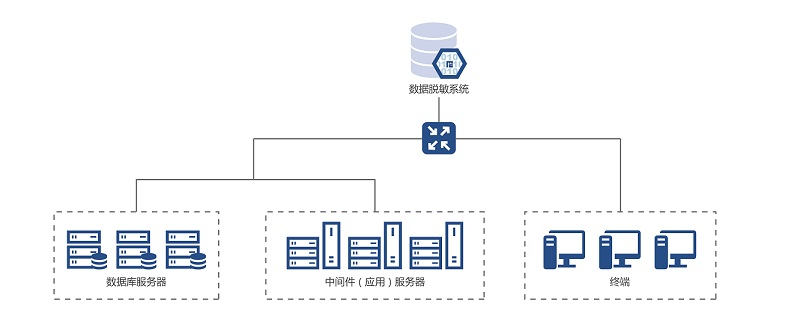
数据脱敏系统可以按照不同业务场景自行定义和编写脱敏规则,可以针对库表的某个敏感字段,进行数据的不落地脱敏。
数据脱敏的方式有很多种,接下来以下图数据为准一个一个的演示每种方案。

4.1无效化
无效化方案在处理待脱敏的数据时,通过对字段数据值进行 截断、加密、隐藏 等方式让敏感数据脱敏,使其不再具有利用价值。一般采用特殊字符(*等)代替真值,这种隐藏敏感数据的方法简单,但缺点是用户无法得知原数据的格式,如果想要获取完整信息,要让用户授权查询。

比如我们将身份证号用 * 替换真实数字就变成了 "220724 ****** 3523",非常简单。

4.2随机值
随机值替换,字母变为随机字母,数字变为随机数字,文字随机替换文字的方式来改变敏感数据,这种方案的优点在于可以在一定程度上保留原有数据的格式,往往这种方法用户不易察觉的。
我们看到 name 和 idnumber 字段进行了随机化脱敏,而名字姓、氏随机化稍有特殊,需要有对应姓氏字典数据支持。

4.3数据替换
数据替换与前边的无效化方式比较相似,不同的是这里不以特殊字符进行遮挡,而是用一个设定的虚拟值替换真值。比如说我们将手机号统一设置成 “13651300000”。

4.4对称加密
对称加密是一种特殊的可逆脱敏方法,通过加密密钥和算法对敏感数据进行加密,密文格式与原始数据在逻辑规则上一致,通过密钥解密可以恢复原始数据,要注意的就是密钥的安全性。

4.5平均值
平均值方案经常用在统计场景,针对数值型数据,我们先计算它们的均值,然后使脱敏后的值在均值附近随机分布,从而保持数据的总和不变。

对价格字段 price 做平均值处理后,字段总金额不变,但脱敏后的字段值都在均值 60 附近。

4.6偏移和取整
这种方式通过随机移位改变数字数据,偏移取整在保持了数据的安全性的同时保证了范围的大致真实性,比之前几种方案更接近真实数据,在大数据分析场景中意义比较大。
比如下边的日期字段create_time中 2020-12-08 15:12:25 变为 2018-01-02 15:00:00。

数据脱敏规则在实际应用中往往都是多种方案配合使用,以此来达到更高的安全级别。
五、总结
无论是静态脱敏还是动态脱敏,其最终都是为了防止组织内部对隐私数据的滥用,防止隐私数据在未经脱敏的情况下从组织流出。所以作为一个程序员不泄露数据是最起码的操守。
标签:加密,业务,随机,敏感数据,数据,替换,脱敏 From: https://www.cnblogs.com/JaxYoun/p/18259057