LoRA:大型语言模型中的低秩自适应调优策略
随着人工智能技术的飞速发展,大型语言模型已成为自然语言处理领域的明星技术。然而,这些模型通常拥有数以亿计的参数,使得在特定任务上进行微调变得既昂贵又耗时。为了克服这一挑战,研究者们提出了一种名为“低秩自适应”(Low-Rank Adaptation,简称LoRA)的参数高效调优方法。本文将深入探讨LoRA的原理、优势以及在编程和数学任务中的性能表现。
一、LoRA的原理与优势
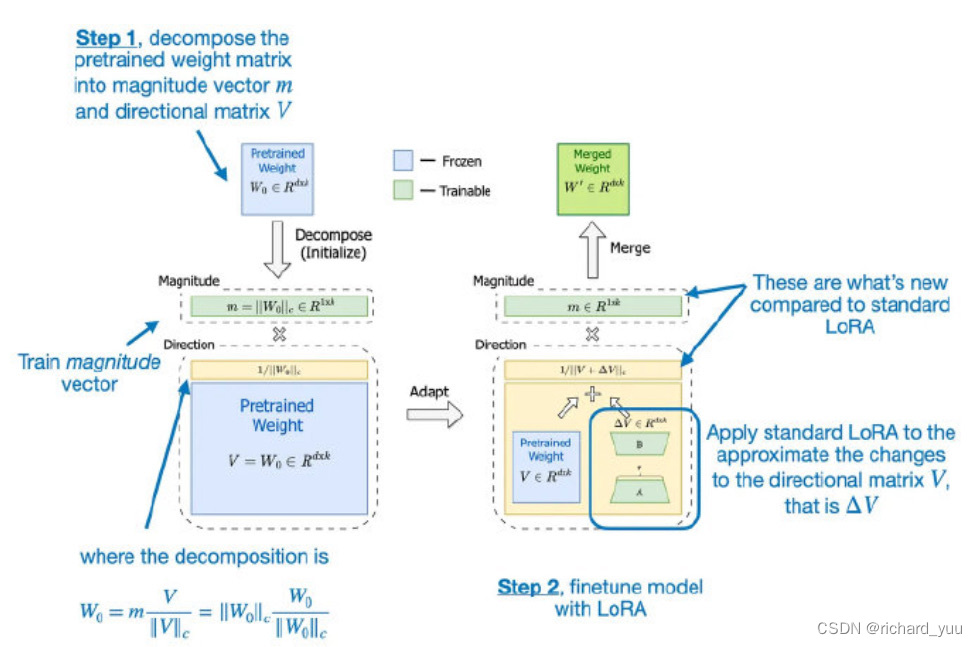
LoRA是一种针对大型语言模型的参数高效调优策略,其核心理念是通过只训练选定权重矩阵的低秩扰动来节省内存和计算资源。在传统的完全微调方法中,模型的所有参数都需要进行更新,这不仅需要巨大的计算资源,还可能导致模型在微调过程中“遗忘”之前学到的知识。而LoRA则通过引入一个低秩矩阵,仅对这部分矩阵进行训练,从而实现对模型的高效调优。
LoRA的优势在于其能够在保证模型性能的同时,显著降低计算和存储成本。具体来说,LoRA通过以下步骤实现参数高效调优:
在预训练模型的基础上,选择一个或多个权重矩阵作为调优目标。
**为每个选定的权重矩阵添加一个低秩矩阵作为扰动项b。
**在微调过程中,仅对低秩矩阵进行训练,而保持原始权重矩阵不变g。
这种方法能够有效地减少需要训练的参数数量,从而降低计算和存储需求。同时,由于低秩矩阵的引入,LoRA还能够在一定程度上防止模型在微调过程中的“遗忘”现象,保持模型在目标域之外任务上的性能。
二、LoRA在编程和数学任务中的性能表现
为了评估LoRA在实际任务中的性能表现,研究者们进行了一系列实验,比较了LoRA和完全微调在编程和数学任务中的性能。实验结果表明,在大多数情况下,LoRA的性能略低于完全微调,但其在目标域之外任务上的性能保持能力更强。
具体来说,在编程任务中,LoRA能够在不显著降低模型性能的前提下,实现对代码的自动补全和错误检测等功能。与完全微调相比,LoRA在保持模型在编程任务上性能的同时,还能够更好地维护模型在其他自然语言处理任务上的性能。这得益于LoRA的低秩扰动策略,使得模型在微调过程中能够保持对原始知识的记忆。
在数学任务中,LoRA同样展现出了良好的性能。研究者们使用LoRA对大型语言模型进行微调,使其能够理解和解答数学问题。实验结果表明,LoRA能够在一定程度上提高模型对数学问题的理解和解答能力,尤其是在处理复杂数学问题时表现出色。这进一步证明了LoRA在参数高效调优方面的优势。
三、LoRA的代码实例
下面是一个使用LoRA对大型语言模型进行微调的简化代码实例:
python
import torch
from loralib import LoRA
# 假设 pretrained_model 是一个预训练好的大型语言模型
pretrained_model = ...
# 选择一个权重矩阵进行LoRA调优
weight_matrix = pretrained_model.some_layer.weight
# 初始化LoRA模块
lora_module = LoRA(weight_matrix, rank=8, lr=1e-3)
# 将LoRA模块添加到模型中
pretrained_model.add_lora_module(lora_module)
# 在训练过程中,只更新LoRA模块的参数
optimizer = torch.optim.SGD(lora_module.parameters(), lr=1e-3)
# ... 训练过程 ...
在上述代码中,我们首先选择了一个权重矩阵作为调优目标,并初始化了一个LoRA模块。然后,我们将LoRA模块添加到预训练模型中,并在训练过程中仅更新LoRA模块的参数。通过这种方式,我们可以实现对大型语言模型的高效调优,同时降低计算和存储成本。
四、总结与展望
LoRA作为一种参数高效调优方法,在大型语言模型领域展现出了巨大的潜力。通过仅训练低秩扰动到选定的权重矩阵,LoRA能够在保证模型性能的同时,显著降低计算和存储成本。虽然LoRA在某些任务上的性能略低于完全微调,但其在目标域之外任务上的性能保持能力更强,这使得LoRA成为一种理想的正则化形式。未来,随着技术的不断发展,我们有理由相信LoRA将在更多领域得到广泛应用。
标签:微调,模型,中低,矩阵,秩自,调优,LoRA,性能 From: https://blog.csdn.net/richard_yuu/article/details/139451370