在浦语大模型的第三课《基于Internlm和LangChain构建你的知识库》中,北辰老师以其生动有趣的风格,深入浅出地讲解了RAG(Retrieval Augmented Generation)的基本概念,并指导我们如何利用茴香豆搭建一个RAG助手。在此之前,我阅读过一些关于大型语言模型的资料,心中一直存有一个疑惑:既然这些模型是预先训练好的,它们如何能够处理实时更新的信息呢?
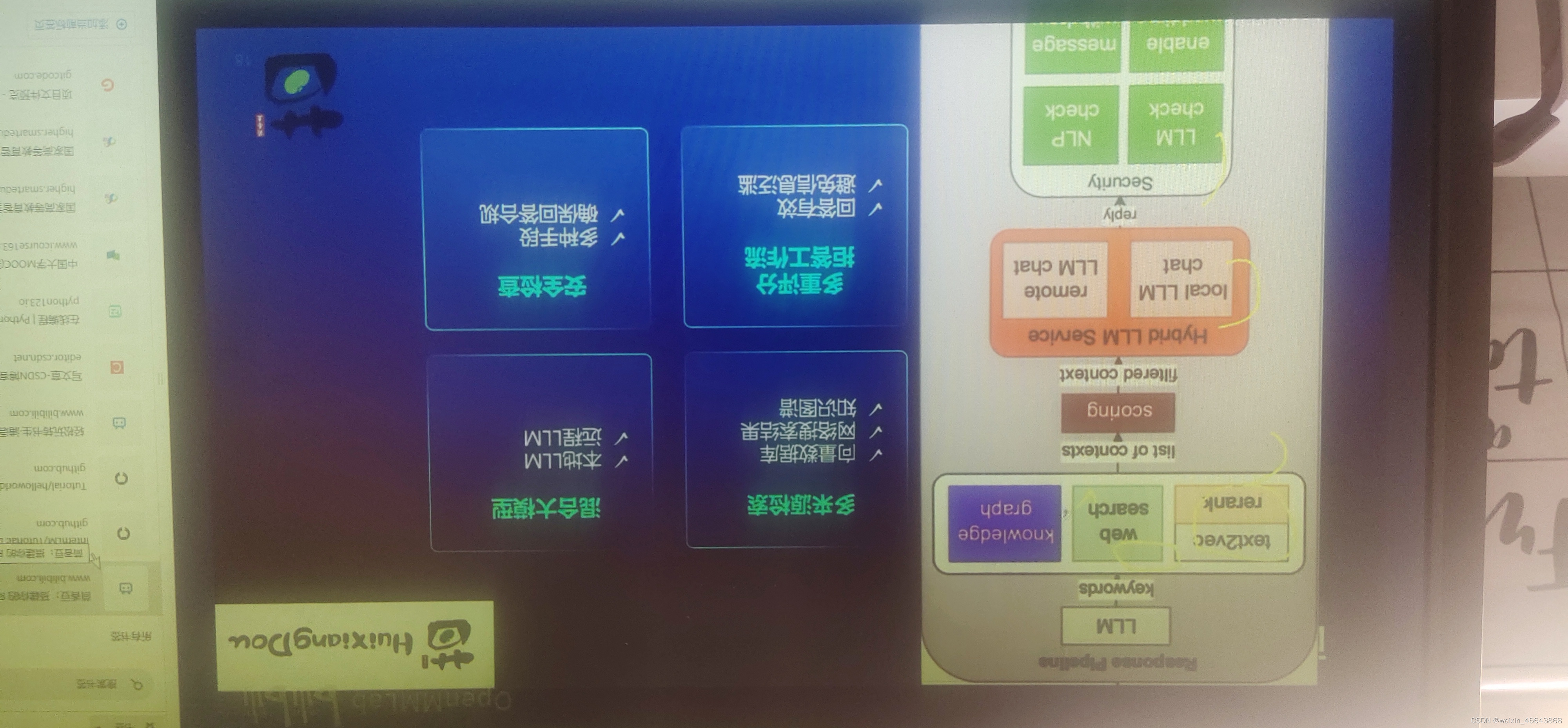
通过学习本节课,我的疑问得到了解答。大型模型可以利用RAG技术来克服这一难题,确保即使在预先训练的基础上,也能整合最新的信息。具体的实现方式,通过一张图就能清晰展示。不过,由于我无法直接展示图片,我会尽力用文字来描述这一过程。
简单来说,RAG技术允许模型在生成回答时检索和整合最新的信息。它通过结合预先训练的语言模型的能力和实时的信息检索,使得模型能够利用最新的数据来生成回答。这样,即使模型本身是在旧数据上训练的,它也能利用RAG技术来访问和利用新信息,从而确保回答的实时性和准确性。
北辰老师通过详细的步骤和生动的例子,让我们明白了如何利用茴香豆搭建一个RAG助手,从而使得语言模型能够与时俱进,提供更准确和全面的信息。这无疑是大模型在实际应用中的一个重要进步,也是我们在构建知识库时必须考虑的一个重要因素。这是教程提供的RAG的图片:
这是我对本节课学习的一点心得。