开篇
近日,由阿里云计算平台大数据基础工程技术团队主导,与南京大学、宾夕法尼亚州立大学、清华大学等高校合作,解释时间序列预测模型的论文《Explaining Time Series via Contrastive and Locally Sparse Perturbations》被机器学习领域顶会ICLR 2024接收。该论文提出了一种创新的基于扰动技术的时间序列解释框架ContraLSP,该框架主要包含一个学习反事实扰动的目标函数和一个平滑条件下稀疏门结构的压缩器。论文在白盒时序预测,黑盒时序分类等仿真数据,和一个真实时序数据集分类任务中进行了实验,ContraLSP在解释性能上超越了SOTA模型,显著提升了时间序列数据解释的质量。
背景
在金融、游戏和医疗保健等领域,为机器学习模型所做的预测提供可靠的解释具有极高的重要性,因为透明度和可解释性通常是道德和法律的先决条件。如图1所示,学者们经常处理复杂的视觉、文本、图结构数据通过选择最显著的因子,但是对解释时间序列模型的方法的研究仍然是一个未充分探索的前沿。此外,将最初为不同数据类型设计的解释器进行适配带来了挑战,因为它们的归纳偏差可能难以适应时间序列数据本质上的复杂性和较低的可解释性。
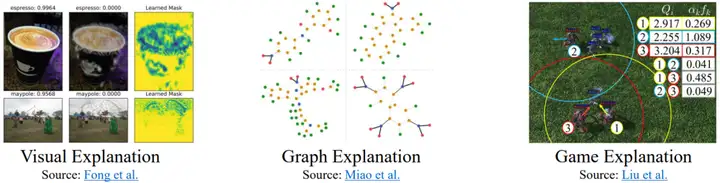 图一:基于显著图的解释在视觉、图数据、游戏场景的应用
图一:基于显著图的解释在视觉、图数据、游戏场景的应用
挑战
现有的解释方法涉及使用显著性方法,这些方法的解释区分取决于它们与任意模型的交互方式。一些工作建立了显著图,例如,结合梯度或构造注意力机制,以更好地处理时间序列特征,而它们难以发现时间序列模式。其他替代方法,包括Shapley值或LIME,通过加权线性回归在局部近似模型预测,为我们提供解释。这些方法主要提供实例级别的显著图,但特征间的互相关常常导致显著的泛化误差。在时间序列中最常见的基于扰动的方法通常通过基线、生成模型或使数据无信息的特征来修改数据,但这些扰动的非显著区域并不总是无意义的并且存在不在数据分布内的样本,导致解释模型存在偏差,如图二所示。我们的工作通过样本间反事实扰动,专注于理解模型在不同群组间的整体和具体行为。
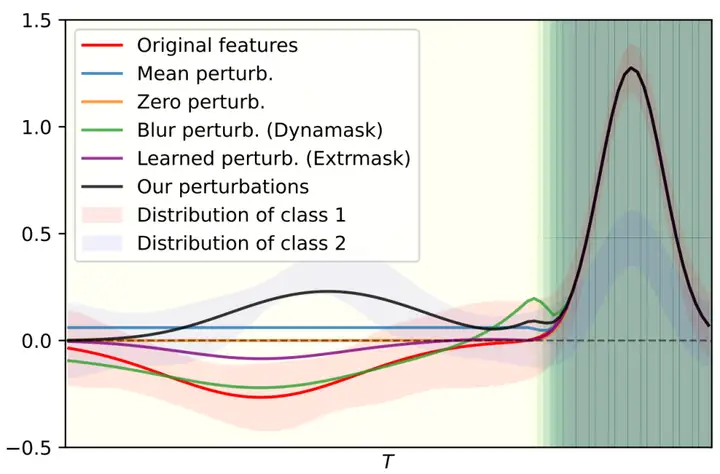
图二:在阐述不同风格的扰动时,图示中的红线代表属于两个类别中类别1的一个样本,而深色背景表示显著特征,其他部分则为非显著特征。其他扰动可能不是无信息的或不在数据分布内,而我们的扰动是反事实的,即朝向负样本的分布。
破局
对于一个具体的扰动: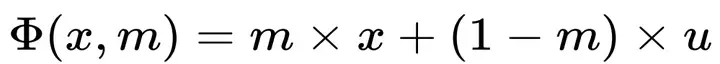 ,我们需要与其原始实例x对于的标签y一致,通过掩码m来计算显著的区域。其优化目标可表示为如下式子,其中第一项保证扰动和原始实例输入到黑盒时序模型f中得到的预测一致性,第二项保证解释区域m最小化,第三项保证解释区域的平滑性。
,我们需要与其原始实例x对于的标签y一致,通过掩码m来计算显著的区域。其优化目标可表示为如下式子,其中第一项保证扰动和原始实例输入到黑盒时序模型f中得到的预测一致性,第二项保证解释区域m最小化,第三项保证解释区域的平滑性。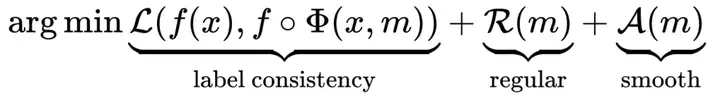 基于此,本文提出了ContraLSP框架,该框架如图三所示。这是一个局部稀疏解释模型,它通过引入反事实样本来构建无信息扰动同时保持样本分布。此外,我们融入了特定于样本的稀疏门控机制来生成更倾向于二值化且平滑的掩码,这有助于简洁地整合时间趋势并精选显著特征。在保证标签的一致性条件下,其整体优化目标修改为:
基于此,本文提出了ContraLSP框架,该框架如图三所示。这是一个局部稀疏解释模型,它通过引入反事实样本来构建无信息扰动同时保持样本分布。此外,我们融入了特定于样本的稀疏门控机制来生成更倾向于二值化且平滑的掩码,这有助于简洁地整合时间趋势并精选显著特征。在保证标签的一致性条件下,其整体优化目标修改为: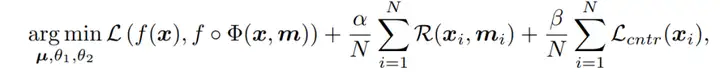
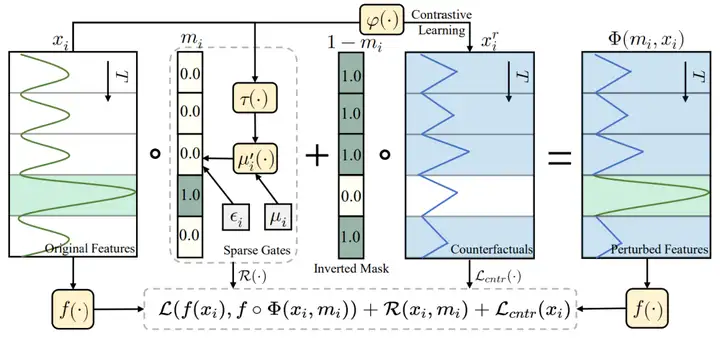 图三: ContraLSP整体框架
图三: ContraLSP整体框架
(1)通过对比学习提取反事实扰动:我们的ContraLSP通过对比学习来学习反事实样本,以增强无信息扰动,同时保持样本分布。这允许在异质样本中将扰动的特征趋向于负样本的分布,从而增加了扰动的影响。具体来说,我们首先通过距离相似性寻找时序样本中的正负样本对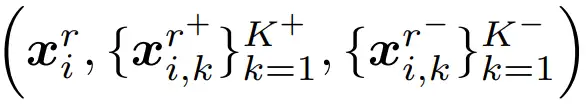 。将当前实例通过一个神经网络生成出反事实示例,使得它更加靠近负样本
。将当前实例通过一个神经网络生成出反事实示例,使得它更加靠近负样本 并更加远离正样本
并更加远离正样本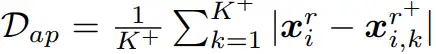 ,如图四所示。其优化三元组的目标函数为:
,如图四所示。其优化三元组的目标函数为: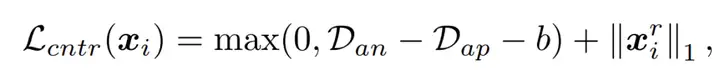
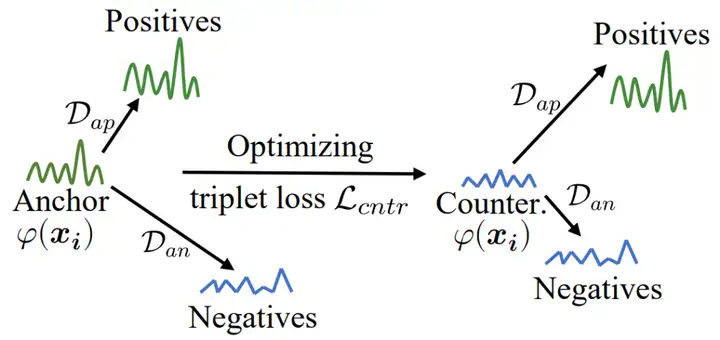 图四:使用三元组损失(triplet loss)生成反事实扰动
图四:使用三元组损失(triplet loss)生成反事实扰动
(2)具有平滑约束的稀疏门:在学习掩码时需要保证显著特征的稀疏和平滑。如图五所示,当扰动实例是不平滑的时间序列,输入到的黑盒模型中可能会造成分类错误,影响解释的性能。
 图五:掩码序列是否平滑的对比。如果不平滑,黑盒模型可能会预测错误。
图五:掩码序列是否平滑的对比。如果不平滑,黑盒模型可能会预测错误。
因此,我们采用学习时间趋势描述平滑的扰动,并且用该平滑约束下的l0正则去限制掩码。具体来说,我们令掩码m生成通过门控的形式:![]() ,其中平滑因子为
,其中平滑因子为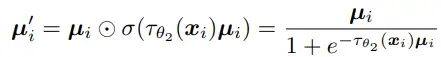 ,通过时间趋势学习温度,使其控制sigmoid-weighted单元。一个不同温度下平滑掩码的示例如图六所示。最后优化掩码的损失函数为:
,通过时间趋势学习温度,使其控制sigmoid-weighted单元。一个不同温度下平滑掩码的示例如图六所示。最后优化掩码的损失函数为: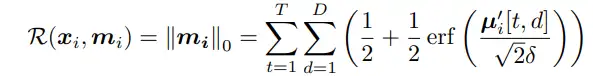
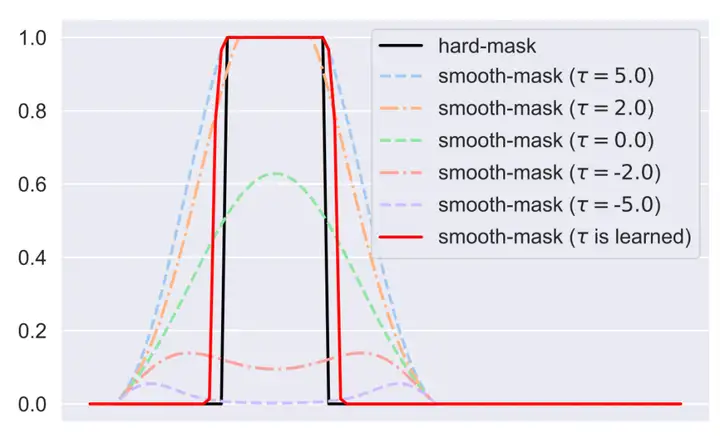 图六:不同温度条件下的sigmoid-weighted单元。平滑掩码(红色)相较于硬掩码(黑色)更好的适应时间序列。
图六:不同温度条件下的sigmoid-weighted单元。平滑掩码(红色)相较于硬掩码(黑色)更好的适应时间序列。
应用
现已将ContraLSP集成到飞天大数据AI管控平台ABM的时序指标下钻和异常检测算法服务中,后续将进一步研究如何将ContraLSP技术与现有平台结合进行时间序列上的根因分析。
- 论文标题:Explaining Time Series via Contrastive and Locally Sparse Perturbations
- 论文作者:刘子川,张颖莹,王天纯,王泽凡,骆东升,杜梦楠,吴敏,王毅,陈春林,范伦挺,文青松
- 论文链接:https://openreview.net/pdf?id=qDdSRaOiyb
- slide链接:https://github.com/zichuan-liu/ContraLSP/blob/main/intro_contralsp_slides.pdf
本文为阿里云原创内容,未经允许不得转载。
标签:ContraLSP,平滑,样本,稀疏,序列,掩码,扰动 From: https://www.cnblogs.com/yunqishequ/p/18224795