Kafka的结构与工作原理
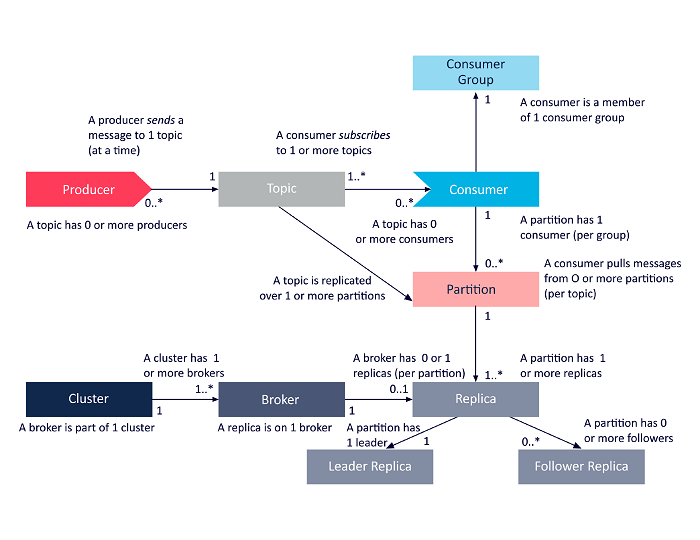
Kafka是一种分布式流处理平台,广泛应用于实时数据处理和数据管道。它的核心组件包括Producer、Topic、Partition、Broker、Consumer和Consumer Group。以下是Kafka从生产到消费端的工作流程及其关键概念的解释。
1. 生产者(Producer)
功能:生产者负责将数据发送到Kafka集群中的Topic。
操作:
- 生产者将消息发送到指定的Topic。
- 根据分区策略(如轮询、哈希等),消息被分配到不同的Partition中。
2. Topic与Partition
Topic:Topic是Kafka中的基本消息分类单位,相当于消息的“主题”。
Partition:
- 一个Topic可以有多个Partition,分区使得数据可以并行处理,提高了吞吐量。
- 每个Partition是一个有序的、不可变的消息队列。
- 每条消息在Partition中都有一个唯一的offset(偏移量)。
3. Broker
功能:Broker是Kafka集群中的服务器实例,负责接收、存储和提供消息。
操作:
- 每个Broker负责管理一个或多个Partition。
- 分区的Leader副本处理所有读写请求,Follower副本同步Leader的数据以确保高可用性。
4. 消费者(Consumer)与消费者组(Consumer Group)
功能:消费者从Kafka集群中读取数据。
操作:
- 消费者订阅一个或多个Topic。
- 消费者组允许多个消费者实例共享消费任务,每个分区的消息只能被同一消费者组中的一个实例消费。
- 不同消费者组之间独立消费同一个Topic的消息,不会相互影响。
Kafka的工作流程
-
消息生产:
- 生产者将消息发送到指定的Topic。
- 消息根据分区策略分配到不同的Partition。
-
消息存储:
- Broker接收消息并存储在对应的Partition中。
- 分区的Leader负责处理消息,Follower副本同步Leader的数据。
-
消息消费:
- 消费者从指定的Topic和Partition中读取消息。
- 消费者组内的实例分工合作,确保每条消息只被消费一次。
关键知识点
-
高可用性:
- 副本机制保证数据的冗余和高可用性,Leader和Follower副本确保在Broker故障时系统仍能正常运行。
-
分布式架构:
- Kafka通过分区和多Broker架构实现高吞吐量和可扩展性,能够处理大量实时数据。
-
偏移量管理:
- Kafka通过偏移量管理消息的读取进度,消费者可以根据偏移量重置消费位置。
Kafka架构示意图
总结
Kafka通过其分布式架构、高可用性设计和灵活的消息处理机制,成为处理实时数据流和构建数据管道的强大工具。通过了解生产者、Topic、Partition、Broker、消费者和消费者组等核心概念,初学者可以迅速掌握Kafka的基本工作原理和操作流程。
资料来源:
标签:消费者,Partition,Broker,Kafka,Topic,消息,结构 From: https://www.cnblogs.com/irobotzz/p/18222163