背景
最近在给 opentelemetry-operator提交一个标签选择器的功能时,因为当时修改的函数是私有的,无法添加单测函数,所以社区建议我补充一个 e2e test.
因为在当前的版本下,只要给 deployment 打上了
instrumentation.opentelemetry.io/inject-java: "true"这类注解就会给该 deployment 注入 agent。
但没办法指定不同的 agent 版本(或者不同的环境变量),所以希望可以新增一个选择器,同时可以针对不同的 deployment 维护不同版本的Instrumentation(是用于控制需要注入 deployment 的资源);这样就可以灵活控制了。

在这之前我其实也很少做 kubernetes 的 operator 开发,对如何做 kubernetes 的 e2e 测试也比较陌生,好在社区提供了详细的贡献文档。
安装
简单来说需要两个关键组件:
- kind: kubernetes in docker,是可以在本地利用 docker 启动一个 kubernetes 集群的工具,通常用于在本地进行开发、测试关于 kubernetes 相关的功能。
- 安装 kind 的前提是本地已经安装好了 docker。
- chainsaw: 一个 e2e 测试框架,提供了声明式的方式定义测试用例,也有着丰富断言功能。
他们的安装都很简单,只要本地安装好了 golang,直接使用 go install 即可:
go install sigs.k8s.io/kind@v0.22.0
go install github.com/kyverno/chainsaw@latest
kind 使用
在开始前还是先预习下 kind 的基本使用。
安装好 kind 之后,使用 create cluster 命令可以在本地创建一个 kubernetes 集群。
kind create cluster -h
Creates a local Kubernetes cluster using Docker container 'nodes'
Usage:
kind create cluster [flags]

之后只需要等待集群安装成功即可,它会在我们的 cat ~/.kube/config 文件中追加刚才新建集群的连接信息。
k config get-contexts
k config use-context xxx
这样就可以使用这两个命令来查看和切换不同的集群了,虽说是一个本地模拟的 kubernetes 集群,但他的核心功能和一个标准的集群没有什么区别。
kind delete clusters --all
使用完成之后可以使用这个命令将所有集群都删除掉。
准备集群数据
在 opentelemetry-operator 中有给我们准备好一个 make 命令: make prepare-e2e ;使用它会帮我们将 operator 的测试环境初始化好。
大概分为以下几步:
- 安装 chainsaw
- 修改 controller 的镜像为我们本地构建的镜像名称
- 本地 docker 镜像打包
- 安装 cert-manager
- 安装 Operator 需要的 CRD
- 部署 Operator deployment
- 等待 Operator 启动成功
不过这里的安装过程可能会遇到问题(本质上都是我们的网络问题):


这种情况可以想办法手动先把镜像拉取到本地,然后 kubernetes 就会从本地仓库获取到这个镜像。
e2e test
通常我们需要将同一类的测试功能放到一个文件夹里,比如这样:

默认情况下 Chainsaw 会查找目录下名为 chainsaw-test.yaml 作为引导文件。
apiVersion: chainsaw.kyverno.io/v1alpha1
kind: Test
metadata:
creationTimestamp: null
name: instrumentation-java
spec:
steps:
- name: step-00
try:
- command:
entrypoint: kubectl
args:
- annotate
- namespace
- ${NAMESPACE}
- openshift.io/sa.scc.uid-range=1000/1000
- --overwrite
- command:
entrypoint: kubectl
args:
- annotate
- namespace
- ${NAMESPACE}
- openshift.io/sa.scc.supplemental-groups=3000/3000
- --overwrite
- apply:
file: 00-install-collector.yaml
- apply:
file: 00-install-instrumentation-select.yaml
- name: step-01
try:
- apply:
file: 01-install-app-select.yaml
- assert:
file: 01-assert*.yaml
catch:
- podLogs:
selector: app=my-java-select
tests/e2e-instrumentation/instrumentation-select
├── 00-install-collector.yaml
├── 00-install-instrumentation-select.yaml
├── 01-assert-select.yaml
├── 01-assert-without-select.yaml
├── 01-install-app-select.yaml
└── chainsaw-test.yaml
以我这里的这份文件为例,在其中定义了几个步骤:
- 初始化环境信息,包含创建 namespace
- 安装我们测试所需要的资源
- 00-install-collector.yaml:这里主要是安装一个 OpenTelemetry 的 collector
- 00-install-instrumentation-select.yaml:安装 Instrumentation 注入资源
- 01-install-app-select.yaml:应用一个我们需要测试的 deployment 资源
01-assert*.yaml:最后对最终生成的 yaml 资源与 assert*.yaml 的进行断言匹配,只有匹配成功后才能测试成功。
这里的测试目的主要是完成一个完整的 Java 应用的 deployment 注入 OpenTelemetry 的 agent 过程还有一些与 OpenTelemetry 相关的环境变量。
以 00-install-instrumentation-select.yaml 文件为例:
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: java-select
spec:
selector:
matchLabels:
app: my-java-select
env:
- name: OTEL_TRACES_EXPORTER
value: otlp
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://localhost:4317
exporter:
endpoint: http://localhost:4317
propagators:
- jaeger
- b3
sampler:
type: parentbased_traceidratio
argument: "0.25"
java:
env:
- name: OTEL_JAVAAGENT_DEBUG
value: "true"
它的预期效果是选择 app: my-java-select 的 deployment 将这些环境变量都注入进去,同时默认也会在 deployment 的容器中挂载一个 javaagent.jar:
ls /otel-auto-instrumentation-java/
javaagent.jar
而我们的 01-assert-select.yaml:
apiVersion: v1
kind: Pod
metadata:
annotations:
instrumentation.opentelemetry.io/inject-java: "true"
sidecar.opentelemetry.io/inject: "true"
labels:
app: my-java-select
spec:
containers:
- env:
- name: OTEL_JAVAAGENT_DEBUG
value: "true"
- name: JAVA_TOOL_OPTIONS
value: ' -javaagent:/otel-auto-instrumentation-java/javaagent.jar'
- name: OTEL_TRACES_EXPORTER
value: otlp
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://localhost:4317
- name: OTEL_TRACES_SAMPLER
value: parentbased_traceidratio
- name: OTEL_SERVICE_NAME
value: my-java-select
- name: OTEL_PROPAGATORS
value: jaeger,b3
- name: OTEL_RESOURCE_ATTRIBUTES
name: myapp
- args:
- --config=env:OTEL_CONFIG
name: otc-container
initContainers:
- name: opentelemetry-auto-instrumentation-java
status:
containerStatuses:
- name: myapp
ready: true
started: true
initContainerStatuses:
- name: opentelemetry-auto-instrumentation-java
ready: true
phase: Running
最终就是把实际的 deployment 的 yaml 内容和这份文件进行对比。
所以这个 e2e 测试就有点类似于集成测试,不会测试具体的功能函数,只需要最终结果能匹配就可以。
当然这个和单元测试也是相辅相成的,缺一不可,不能完全只依赖 e2e 测试,也有可能是概率原因导致最终生成的资源相同;单元测试可以保证函数功能与预期相同。
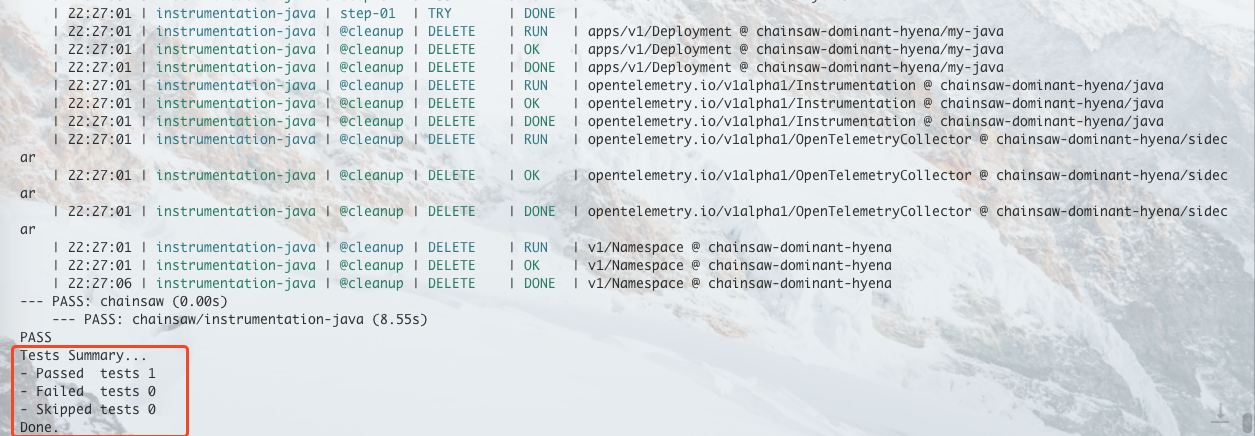
都准备好之后便可以进行测试了,测试的时候也很简单,只需要执行以下命令即可:
chainsaw test --test-dir ./tests/e2e-multi-instrumentation
这样它就会遍历该目录下的 chainsaw-test.yaml文件进行测试,执行我们上面定义的那些步骤,最终输出测试结果:
同时 Chainsaw 也提供了 Github action,可以方便的让我们和 github CI 进行集成。
jobs:
example:
runs-on: ubuntu-latest
permissions: {}
name: Install Chainsaw
steps:
- name: Install Chainsaw
uses: kyverno/action-install-chainsaw@v0.1.0
with:
release: v0.0.9
- name: Check install
run: chainsaw version
这样我们就可以在 github 中查看我们的测试结果了:

总结
最后不得不感叹作为 CNCF 下面的项目 OpenTelemetry 的开发者体验真好,只要我们跟着贡献者文档一步步操作都能顺利通过 CI 测试,同时还能避免一些 Code Review 过程中的低级错误。
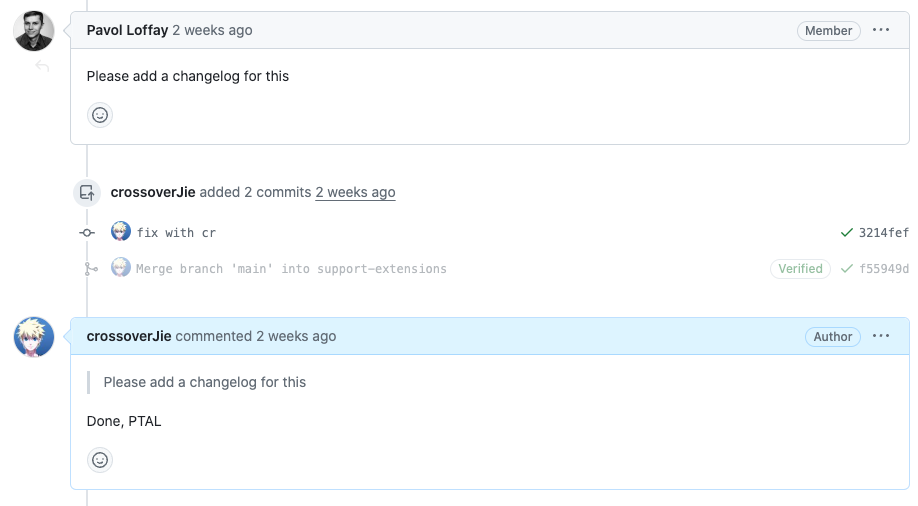
比如我第一次提 PR 的时候没有添加 changlog 文件,后面在贡献者手册里发现只需要执行 make chlog-new 就会基于当前分支信息帮我们生成一个 changelog 文件模板,然后只需要往里面填写内容即可。
这些工具链让不同开发者提交的代码和流程都符合规范,同时也降低了贡献难度。
以上所有的相关源码都可以在 https://github.com/open-telemetry/opentelemetry-operator 中进行查看。
参考链接:
- https://github.com/open-telemetry/opentelemetry-operator/pull/2778
- https://kind.sigs.k8s.io/
- https://kyverno.github.io/chainsaw/latest/
- https://github.com/open-telemetry/opentelemetry-operator/blob/main/CONTRIBUTING.md