前言
这篇文章主要用来总结我之前所学的算法,以更好地复习。希望大家在看时能理解我所说的话(包括未来的我)
算法大典
KMP
KMP是一个强大的字符串搜索算法,可以在线性的复杂度下将所需要的子串位置精确的找出。它的最大特点就是搜索是不会回溯。
朴素思想
给出两个字符串
abababab
bab
要求找出第二个字串在第一个字串第一次出现的位置。朴素思想就是直接爆搜,从第一个字符开始搜索,没搜索到就重新跳到第二个字符。代码如下:
#include<bits/stdc++.h>
using namespace std;
string a,b;
int main()
{
cin>>a>>b;
for(int i=0;i<a.size();i++)
{
for(int j=i;j<b.size();j++)
{
if(a[j]!=b[j-i])break;
else
{
cout<<i+1;
return 0;
}
}
}
return 0;
}
浅显易懂,但代价是复杂度来到了 $O(nm)$ 但凡数据大点就寄了。
KMP思想
考虑优化。
不难发现,在搜索时我们完全可以跳过一些已知的字符,从而继续匹配,这样子既不用回溯浪费时间,也不用一个个的匹配字符
拿两个字符串举例:
abbcabba
abba
当我们匹配到 $c$ 和 $a$ 时,发现匹配失败,因为失败之前的主串部分一定是跟子串部分匹配的,且对于子串来说,失败之前的任意一部分属于子串(模式串)的这段子串(子子串)的后缀,所以我们重新匹配的开始一定是子串的某部分前缀。如果想要将模式串移到最大有效的匹配位置,那么这个位置一定是这段前缀等于后缀的部分。至此问题也转化成了求模式串的前后缀。
前后缀的求法十分巧妙,大家可以先看以下代码:
void get_next()
{
int t1=0,t2=-1;
next1[0]=-1;
while(t1<len2)
{
if(t2==-1 || s2[t2]==s2[t1])
next1[++t1]=++t2;
else t2=next1[t2];
}
}
我们可以将t1想象成一直往前开的火车,t2为一节车厢,当目前的前串(t2)与后串(t1)相等时,t2就能向前一步,反之就要倒退。 $else$ 处十分反人类,建议反复斟酌理解透彻。
当你理解透了以上代码,你就很容易理解匹配代码了:
void KMP()
{
int t1=0,t2=0;
while(t1<len1)
{
if(t2==-1 || s1[t1]==s2[t2])
t1++,t2++;
else t2=next1[t2];
if(t2==len2)printf("%d\n",t1-t2+1),t2=next1[t2];
}
}
原理是相似的。依旧建议反复观看理解。
贴上完整代码:
#include<bits/stdc++.h>
using namespace std;
int n,k,len1,len2;
int next1[1000005];
char s1[1000005];
char s2[1000005];
void get_next()
{
int t1=0,t2=-1;
next1[0]=-1;
while(t1<len2)
{
if(t2==-1 || s2[t2]==s2[t1])
next1[++t1]=++t2;
else t2=next1[t2];
}
}
void KMP()
{
int t1=0,t2=0;
while(t1<len1)
{
if(t2==-1 || s1[t1]==s2[t2])
t1++,t2++;
else t2=next1[t2];
if(t2==len2)printf("%d\n",t1-t2+1),t2=next1[t2];
}
}
int main()
{
scanf("%s",s1);
scanf("%s",s2);
len1=strlen(s1);
len2=strlen(s2);
get_next();
KMP();
for(int i=1;i<=len2;++i)
printf("%d ",next1[i]);
return 0;
}
例题
最小生成树
最小生成树为边权和最小的生成树,只存在于联通图中,可以解决联通所有点的最小边权和问题。
思想
对于寻找联通所有点的最小边权和,最朴素的思想就是遍历全部图来寻找最小的边权,但操作难度大,坑还特别多,于是最小生成树应运而生。本文主要介绍 Prim 算法和 Kruskal 算法。
Prim算法
Prim 算法的思想就是选取任意点作为根,逐渐寻找最近的点不断加进树中,再将边权取最小值。
借鉴一下 oi-wiki 的图:
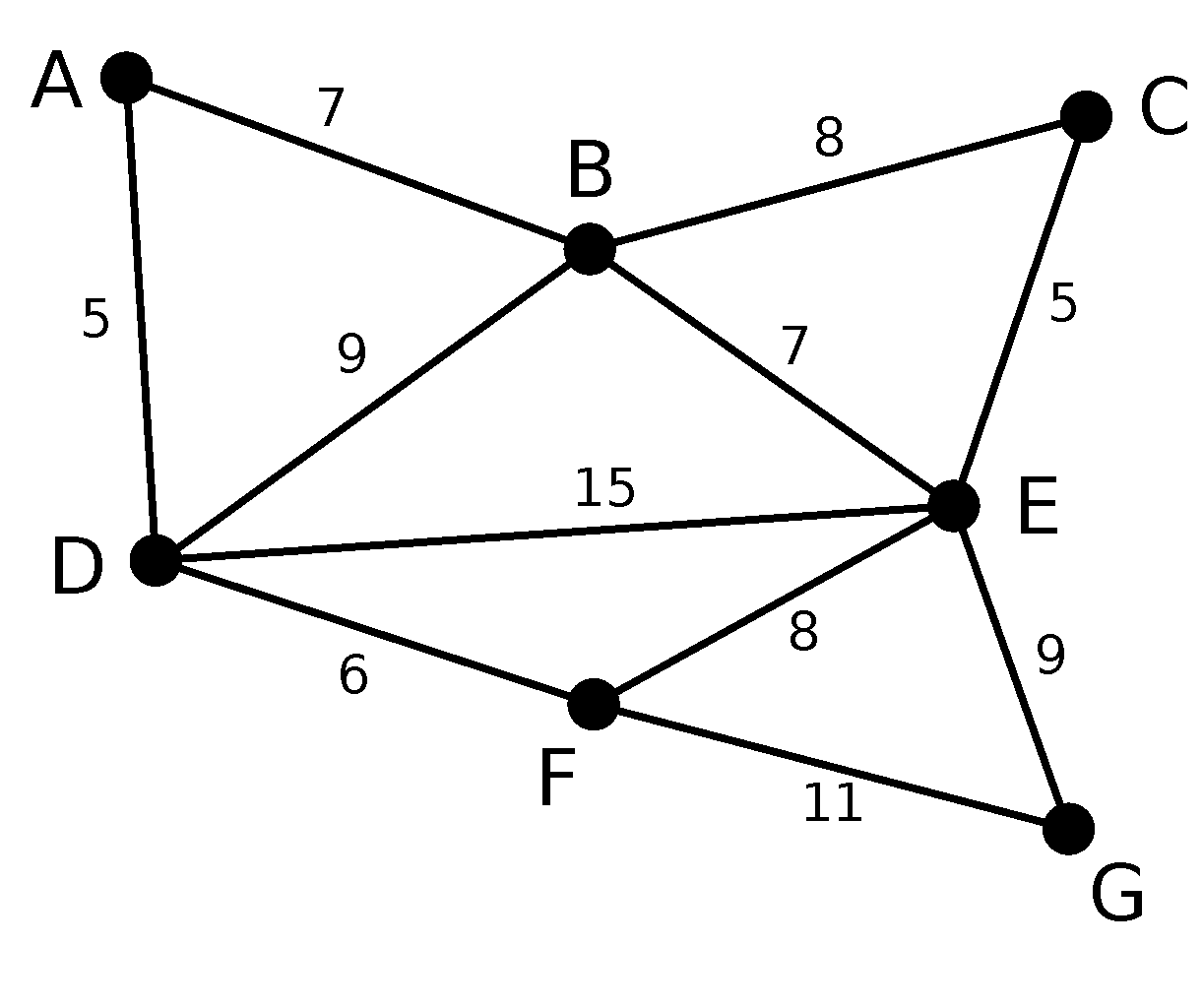
思想十分简单但有效,代码如下:
#include<bits/stdc++.h>
using namespace std;
const int INF=0x3f3f3f3f;
const int maxn=200005;
struct data
{
int dis,x;
bool friend operator<(data a,data b)
{
return a.dis>b.dis;
}
};
int ne[maxn<<1],x[maxn<<1],w[maxn<<1],head[maxn],idx;
int n,m,u1,v1,w1,ans,cnt;
bool vis[maxn];
void add(int a,int b,int c)
{
x[++idx]=b;
ne[idx]=head[a];
head[a]=idx;
w[idx]=c;
}
void Prim()
{
priority_queue<data>q;
q.push((data){0,1});
while(!q.empty())
{
data u=q.top();
ans+=u.dis;
cnt++;
vis[u.x]=true;
q.pop();
for(int i=head[u.x];i!=-1;i=ne[i])
{
if(!vis[x[i]])q.push((data){w[i],x[i]});
}
while(!q.empty() && vis[q.top().x])
q.pop();
}
}
int main()
{
memset(head,-1,sizeof(head));
cin>>n>>m;
for(int i=1;i<=m;i++)
{
cin>>u1>>v1>>w1;
add(u1,v1,w1);
add(v1,u1,w1);
}
Prim();
if(cnt<n)
{
cout<<"orz";
return 0;
}
else cout<<ans;
return 0;
}
可以看到,代码十分的繁琐,实际操作十分困难。
Kruskal算法
kruskal 算法因为其简短的代码和简洁的思想被广泛使用。与 prim 不同的是, kruskal 的思想是加边,有点贪心的味道(就是贪心)。
借鉴一下 oi-wiki 的图 again :
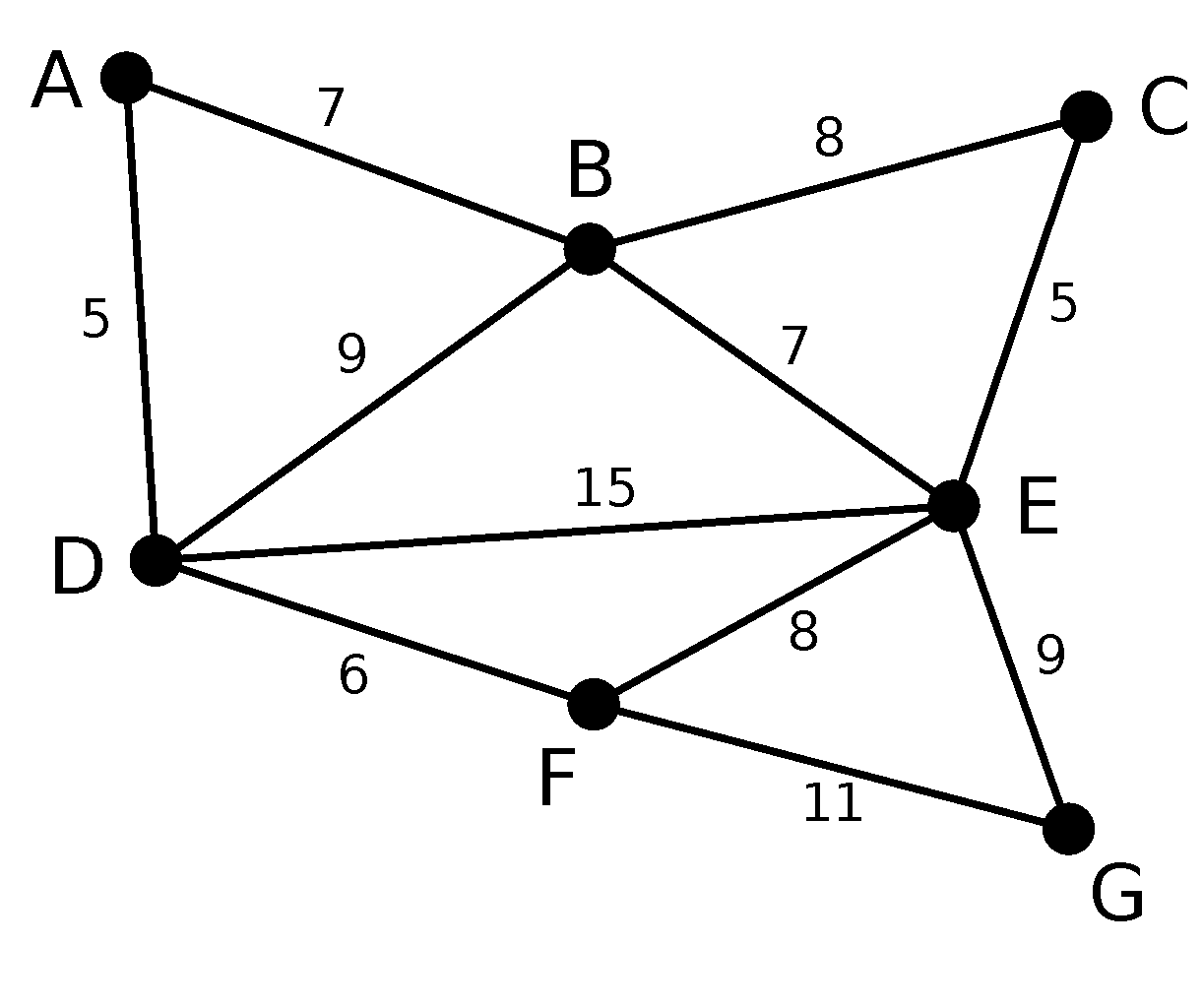
代码基于并查集,因为加边使得点与点之间的关系可以用“祖先”相称。
#include<bits/stdc++.h>
using namespace std;
const int maxn=200005;
int n,m,sum,cnt;
int fa[maxn];
int read()
{
int date=0,w=1;
char a=getchar();
while(a<'0' || a>'9')
{
if(a=='-')w=-1;
a=getchar();
}
while(a>='0' && a<='9')
{
date=date*10+(a-'0');
a=getchar();
}
return date*w;
}
void init(int n)
{
for(int i=1;i<=n;i++)fa[i]=i;
}
int f(int x)
{
return fa[x]=(fa[x]==x) ? fa[x] : f(fa[x]);
}
bool u(int x,int y)
{
x=f(x),y=f(y);
if(x==y)return false;
fa[x]=y;
return true;
}
struct edge
{
int u,v,w;
bool operator<(edge a){return w<a.w;}
}e[maxn];
bool cmp(edge x,edge y)
{
return x.w<y.w;
}
signed main()
{
n=read(),m=read();
init(n);
for(int i=1;i<=m;i++)
e[i].u=read(),e[i].v=read(),e[i].w=read();
sort(e+1,e+m+1,cmp);
for(int i=1;i<=m;i++)
{
if(u(e[i].u,e[i].v))
{
sum+=e[i].w;
cnt++;
}
}
if(cnt!=n-1)
{
cout<<"orz";
return 0;
}
cout<<sum;
return 0;
}
总的来说,最小生成树比较好理解,学过图论的理解起来难度不大。
例题
Trie
字典树,一个好用但有点冷门的东西,值得一学,因为 ACAM 等高级结构都与它有关。
借鉴一下 oi-wiki 的图

思想
如图,可以看到这棵树的边代表了一个字母,例如,1 -> 2 -> 6 -> 7就是 aba 字符串。
trie 的结构十分好懂,做起来也不难,用 $f(u,c)$ 代表节点 $u$ 代表的字符串后添加一个字符 $c$ 形成的节点。
放一个模板。
struct trie
{
int nex[3000005][65],cnt;
int exist[3000005];
void insert(string s,int l)//插入字符串
{
int p=0;
for(int i=0;i<l;i++)
{
int c=getnum(s[i]);
if(!nex[p][c])nex[p][c]=++cnt;
p=nex[p][c];
exist[p]++;
}
}
int find(string s,int l)//查找字符串
{
int p=0;
for(int i=0;i<l;i++)
{
int c=getnum(s[i]);
if(!nex[p][c])return false;
p=nex[p][c];
}
return exist[p];
}
};
字典树可以查找字符串(这不是废话吗)。
例题
十分基础的查找字符串。首先将字符串存入 trie 中,当查找时判断该字符串是否出现过,结束(有点过于简短了)但思想就是这么简单。
进阶练习
跟例题没什么大出入,改一点就能过。
代码如下:
#include<bits/stdc++.h>
using namespace std;
int m,n,len;
struct Trie
{
int nex[500005][5],cnt;
int exist[500005],aaa[500005];
void insert(bool s[])
{
int p=0;
for(int i=1;i<=len;i++)
{
int c=s[i];
if(nex[p][c]==-1)nex[p][c]=++cnt;
p=nex[p][c];
exist[p]++;
}
aaa[p]++;
}
int find(bool s[])
{
int p=0,maxx=0;
for(int i=1;i<=len;i++)
{
int c=s[i];
if(nex[p][c]==-1)return maxx;
p=nex[p][c];
maxx+=aaa[p];
}
return maxx-aaa[p]+exist[p];
}
};
Trie a;
bool b[10005];
int main()
{
scanf("%d%d",&m,&n);
memset(a.nex,-1,sizeof(a.nex));
for(int i=1;i<=m;i++)
{
scanf("%d",&len);
for(int j=1;j<=len;j++)cin>>b[j];
a.insert(b);
}
for(int i=1;i<=n;i++)
{
scanf("%d",&len);
for(int j=1;j<=len;j++)cin>>b[j];
cout<<a.find(b)<<"\n";
}
return 0;
}
字典树还能用来弄 01-trie ,笔者还没学,等我进省队了再说。
LCA(最近公共祖先)
树论大佬必备常识,超级有用!!!(就是因为没学这个 GDKOI 痛失 T1 55555)
接下来开始讲解。
思想
朴素思想
想找到两个树上的点的最近公共祖先,首先应该让深度大的那个点先跳到相同的深度,再同时往上跳,直到找到 LCA 为止。
显然,这样暴力跳的单次查询时间复杂度为 $O(n)$ ,加上 dfs 整棵树预处理的 $O(n)$ ,时间复杂度就达到了 $O(n^2)$ ,如果有多个查询,就完蛋了。
于是不同的方法应运而生。本文主要介绍倍增求 LCA 。
倍增求 LCA
倍增求 LCA 的单次查询复杂度为 $O(\log n)$ ,预处理的时间复杂度为 $O(n \log n)$ ,比暴力快了很多。
我们用游标来让点进行快速移动。$fa(x,i)$ 表示点 $x$ 的 $2^i$ 个祖先。该数组可以预处理出来。
借一下 oi-wiki 的一段话。
在调整游标的第一阶段中,我们要将 u,v 两点跳转到同一深度。我们可以计算出 u,v 两点的深度之差,设其为 y。通过将 y 进行二进制拆分,我们将 y 次游标跳转优化为「y 的二进制表示所含 1 的个数」次游标跳转。 在第二阶段中,我们从最大的 i 开始循环尝试,一直尝试到 0(包括 0),如果 $\text{fa}{u,i}\not=\text{fa}$ ,则 $u\gets\text{fa}{u,i}$ , $v\gets\text{fa}$,那么最后的 LCA 为 $\text{fa}_{u,0}$ 。
金句啊! oi-wiki 我爱你......
存树的话本人喜欢用链式前向星,十分好用建议一试。
练手题
接下来给 2 道题巩固知识。非常好的题,使我大脑旋转。
例题
LCA 板子题。只要将板子打对就行。
代码如下。
#include<bits/stdc++.h>
using namespace std;
const int maxn=500005;
int dep[maxn<<1],fa[maxn<<1][30];
int n,q,root;
int ee,head[maxn<<1],ne[maxn<<1],to[maxn<<1];
int getlca(int x,int y)
{
if(dep[x]<dep[y])
swap(x,y);
while(dep[x]>dep[y])
x=fa[x][(int)log2(dep[x]-dep[y])];//简洁,建议这么写。
if(x==y)
return y;
for(int j=20;j>=0;j--)//跳到LCA的下面一层
if(fa[x][j]!=fa[y][j])
x=fa[x][j],y=fa[y][j];
return fa[x][0];//返回LCA
}
void add(int a,int b)
{
ne[++ee]=head[a];
to[ee]=b;
head[a]=ee;
}
void dfs(int x,int pre)//x为当前节点,pre为父亲节点
{
dep[x]=dep[pre]+1;
fa[x][0]=pre;
for(int i=head[x];i;i=ne[i])
if(to[i]!=pre)
dfs(to[i],x);
}
signed main()
{
scanf("%d%d%d",&n,&q,&root);
for(int i=1,x,y;i<n && cin>>x>>y;i++)
add(x,y),add(y,x);
dfs(root,0);//预处理
for(int j=1;j<=20;j++)
for(int i=1;i<=n;i++)
fa[i][j]=fa[fa[i][j-1]][j-1];//预处理
while(q--)
{
int x,y;
scanf("%d%d",&x,&y);
printf("%d\n",getlca(x,y));
}
return 0;
}
给一道进阶题(就是我痛失的 T1......)。
捉迷藏 pro max 版
虽然是比较版的 LCA ,但卡常能将人卡送走,错了无数次才卡过......
代码奉上:
#include<bits/stdc++.h>
using namespace std;
const int maxn=1000000;
int n,q;
int head[maxn<<1],ne[maxn<<1],to[maxn<<1],ee;
int fa[maxn][30],dep[maxn];
inline int read()
{
int date=0,w=1;
char y=getchar();
while(y<'0' || y>'9')
{
if(y=='-')w=-1;
y=getchar();
}
while(y>='0' && y<='9')
{
date=date*10+(y-'0');
y=getchar();
}
return date*w;
}
inline int getlca(int x,int y)
{
if(dep[x]<dep[y])
swap(x,y);
while(dep[x]>dep[y])
x=fa[x][(int)log2(dep[x]-dep[y])];
if(x==y)
return y;
for(int j=20;j>=0;j--)
if(fa[x][j]!=fa[y][j])
x=fa[x][j],y=fa[y][j];
return fa[x][0];
}
inline void add(int a,int b)
{
ne[++ee]=head[a];
to[ee]=b;
head[a]=ee;
}
inline void dfs(int x,int pre)
{
dep[x]=dep[pre]+1;
fa[x][0]=pre;
for(int i=head[x];i;i=ne[i])
if(to[i]!=pre)
dfs(to[i],x);
}
inline void c()
{
for(int i=0;i<=n;i++)
head[i]=to[i]=ne[i]=dep[i]=0;
for(int i=n+1;i<=2*n;i++)
to[i]=ne[i]=0;
ee=0;
}
signed main()
{
int A=read(),T=read();
while(T--)
{
n=read(),q=read();
for(int i=1,x,y;i<n;i++)
x=read(),y=read(),add(x,y),add(y,x);
dfs(1,0);
for(int j=1;j<=20;j++)
for(int i=1;i<=n;i++)
fa[i][j]=fa[fa[i][j-1]][j-1];
for(int i=1;i<=q;i++)
{
int x=read(),y=read(),dx=read(),dy=read();
int ans=getlca(x,y),lo;
lo=dep[x]-2*dep[ans]+dep[y];
if(lo<=dx)printf("Zayin\n");
else if(dx>dy)printf("Zayin\n");
else if(dx==dy)printf("Draw\n");
else if(dx<dy)printf("Ziyin\n");
}
c();
}
return 0;
}
真是爱死这道题了,卡常把我送走了......
LCA 是很有用的,建议巩固好知识。
dijkstra
众所周知,Dijkstra算法是一个十分有效且常用的算法。既然说了:
- 有效且常用
那我们就有学习的必要了呀!
话不多说,开始讲解。
概念
1.是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。 $Dijkstra$ 算法主要特点是从起始点开始,采用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
2.$Dijkstra$ 用来解决边权全为正的单源最短路问题, $Dijkstra$ 算法又分为朴素 $Dijkstra$ 算法和堆优化的 $Dijkstra$ 算法。朴素版的Dijkstra算法的时间复杂度是 $O(n²)$ ,适合于稠密图,堆优化版的 $Dijkstra$ 算法的时间复杂度是 $O(mlogn)$,适合于稀疏图。
代码讲解
链式前向星
#define MOD 10000000007
#define INF 0x3f3f3f3f
using namespace std;
const int maxn=2000005;
int n,m,s;
int idx=1,e[maxn],w[maxn],head[maxn],ne[maxn];
int dis[maxn],vis[maxn];
MOD和INF不做过多解释,重点看e,w,head和ne数组。
void add(int a,int b,int c)
{
e[idx]=b;
w[idx]=c;
ne[idx]=head[a];
head[a]=idx++;
}
这是一个简单的链式前向星,虽然有些奇怪的东西。
a是该点的位置,b是与该点相连的一点的位置,c则是边全
权。我们可以看到,e数组存储了一个点到另一个点的的终点,w存储了这两个点中边的边权,ne和head数组则是普通的链式前向星啦!
结构体
struct Node
{
int dis,x;
bool operator<(Node p)const{return dis>p.dis;}
Node(int dis,int x):dis(dis),x(x){}
};
我们使用重载运算符 $operator$ 重新定义 $<$ 符号来对边权进行排序,方便我们接下来的操作。下面的一行可有可无,主要是装。
Dijkstra 主体
void dijstra()
{
memset(dis,INF,sizeof(dis));
priority_queue<Node>q;
dis[s]=0;
Node u(dis[s],s);
q.push(u);
while(!q.empty())
{
Node u=q.top();
q.pop();
if(vis[u.x])continue;
vis[u.x]=1;
for(int i=head[u.x];i!=-1;i=ne[i])
{
if(dis[e[i]]>dis[u.x]+w[i])
{
dis[e[i]]=dis[u.x]+w[i];
Node v(dis[e[i]],e[i]);
q.push(v);
}
}
}
}
首先定义大根堆 $priority__queue$ ,方便我们接下来的操作。其次,我们从 $s$ 点出发,那距离 $s$ 点的最短距离肯定是0,这就是 $dis[s]=0$ 的原因。
跟图有关,那我们就得使出万能且高效的BFS。
如你所见,里面有一个BFS遍历。
while循环的前四行为基操,不做过多讲述,我们来看for循环。
for(int i=head[u.x],i!=-1;i=ne[i])//从头开始,循环到下一个点
从第x个点的链下标出发,向下一个点,也就是 $ne[i]$ 前进,但由于我们标记了每一个点初始值为-1,所以还得判断一下。
if(dis[e[i]]>dis[u.x]+w[i])
{
dis[e[i]]=dis[u.x]+w[i];
Node v(dis[e[i]],e[i]);
q.push(v);
}
这里我们做出判断,如果新路径的边权总和小于原路径边权总和,就改变最佳路径。
完整代码
这里附上完整代码:
#include<bits/stdc++.h>
#define MOD 10000000007
#define INF 0x3f3f3f3f
using namespace std;
const int maxn=2000005;
int n,m,s;
int idx=1,e[maxn],w[maxn],head[maxn],ne[maxn];
int dis[maxn],vis[maxn];
struct Node
{
int dis,x;
bool operator<(Node p)const{return dis>p.dis;}
Node(int dis,int x):dis(dis),x(x){}
};
inline int read()
{
int date=0,w=1;
char c;
c=getchar();
while(c<'0' || c>'9')
{
if(c=='-')w=-1;
c=getchar();
}
while(c>='0' && c<='9')
{
date=date*10+(c-'0');
c=getchar();
}
return date*w;
}
void add(int a,int b,int c)
{
e[idx]=b;
w[idx]=c;
ne[idx]=head[a];
head[a]=idx++;
}
void dijstra()
{
memset(dis,INF,sizeof(dis));
priority_queue<Node>q;
dis[s]=0;
Node u(dis[s],s);
q.push(u);
while(!q.empty())
{
Node u=q.top();
q.pop();
if(vis[u.x])continue;
vis[u.x]=1;
for(int i=head[u.x];i!=-1;i=ne[i])
{
if(dis[e[i]]>dis[u.x]+w[i])
{
dis[e[i]]=dis[u.x]+w[i];
Node v(dis[e[i]],e[i]);
q.push(v);
}
}
}
}
signed main()
{
memset(head,-1,sizeof(head));
n=read(),m=read(),s=read();
for(int i=1;i<=m;i++)
{
int a=read(),b=read(),c=read();
add(a,b,c);
}
dijstra();
for(int i=1;i<=n;i++)
cout<<dis[i]<<" ";
return 0;
}
例题
线段树
作为一个树形数据结构,它的时间复杂度是毋庸置疑的快,达到了$O(nlog\ n)$的级别。该数据结构可以用来解决区间求和,区间求最值,区间求积等等区间类问题。