Part B Copy-on-Write Fork
Unix 提供 fork() 系统调用作为主要的进程创建基元。fork()系统调用复制调用进程(父进程)的地址空间,创建一个新进程(子进程)。
不过,在调用 fork() 之后,子进程往往会立即调用 exec(),用新程序替换子进程的内存。例如,shell 通常就是这么做的。在这种情况下,拷贝父进程地址空间所花费的时间基本上是白费的,因为子进程在调用 exec() 之前几乎不会使用它的内存。
因此,后来的 Unix 版本利用虚拟内存硬件,允许父进程和子进程共享映射到各自地址空间的内存,直到其中一个进程实际修改了内存。这种技术被称为 "写时拷贝"(copy-on-write)。 为此,内核会在 fork() 时将父进程的地址空间映射复制到子进程,而不是映射页的内容,同时将现在共享的页标记为只读。 当两个进程中的一个试图写入其中一个共享页面时,该进程就会发生页面错误。此时,Unix 内核会意识到该页面实际上是一个 "虚拟 "或 "写时拷贝 "副本,因此会为发生故障的进程创建一个新的、私有的、可写的页面副本。 这样,单个页面的内容在实际写入之前不会被复制。这种优化使得在子进程中执行 fork() 之后执行 exec() 的成本大大降低:在调用 exec() 之前,子进程可能只需要复制一个页面(堆栈的当前页面)。
我们接下来的目标就是实现写时复制的fork
用户级页面故障处理 User-level page fault handling
为了实现用户级的写时复制 fork(),exercise7做的syscall外,我们还需要实现一些基础设施,即用户级页面故障处理。
注意啊,是用户级的页面故障处理,在 lab3 中,缺页故障的处理函数使用的是自带的简易实现,它是由 trap() 调用的,这个过程显然是在内核态完成的。手册中描述如下:
内核需要跟踪的信息太多了。与传统的 Unix 方法不同,你将在用户空间中决定如何处理每个页面故障,因为在用户空间中,错误的破坏性较小。 这种设计的另一个好处是,允许程序非常灵活地定义其内存区域;稍后在映射和访问基于磁盘的文件系统上的文件时,我们将使用用户级页面故障处理方法。
做到这里一定有一堆疑问,所以可以看一下 part B后面的小标题,实际上 JOS 实现用户级页面故障的思路是:
- 增加一个系统调用,
sys_env_set_pgfault_upcall,允许用户进程指定自己的页面故障程序 - 在 lab3 的
page_fault_handler的基础上修改,检查异常来源是否是用户态,如是,则调用上一步部指定的页面故障程序
设置页面故障处理程序
为了处理自己的页面故障,用户环境需要向 JOS 内核注册一个页面故障处理程序入口点。用户环境通过新的 sys_env_set_pgfault_upcall 系统调用来注册其页面故障入口点。我们在 Env 结构中添加了一个新成员 env_pgfault_upcall,以记录这一信息。
练习8
练习 8. 执行
sys_env_set_pgfault_upcall系统调用。由于这是一个 "危险 "的系统调用,因此在查找目标环境的环境 ID 时一定要启用权限检查。
实现 sys_env_set_upcall 系统调用。
// 通过修改相应结构体 Env 的 “env_pgfault_upcall ”字段,
// 为 “envid ”设置页面故障上调。
// 当 “envid ”导致页面故障时,
// 内核会将故障记录推送到异常堆栈,然后分支到 “func”。
//
// 成功时返回 0,错误时返回 <0。 错误包括
// -E_BAD_ENV 如果环境 envid 当前不存在,或者调用者没有权限更改 envid。
static int
sys_env_set_pgfault_upcall(envid_t envid, void *func)
{
// LAB 4: Your code here.
// panic("sys_env_set_pgfault_upcall not implemented");
struct Env * e;
if(envid2env(envid, &e, 1)<0) // 检查envid是否有误
return -E_BAD_ENV ;
e->env_pgfault_upcall = func; // 设置该环境page fault的handler
return 0;
}
记得将这个系统调用假如 kern/syscal.c : syscall 的分发里:
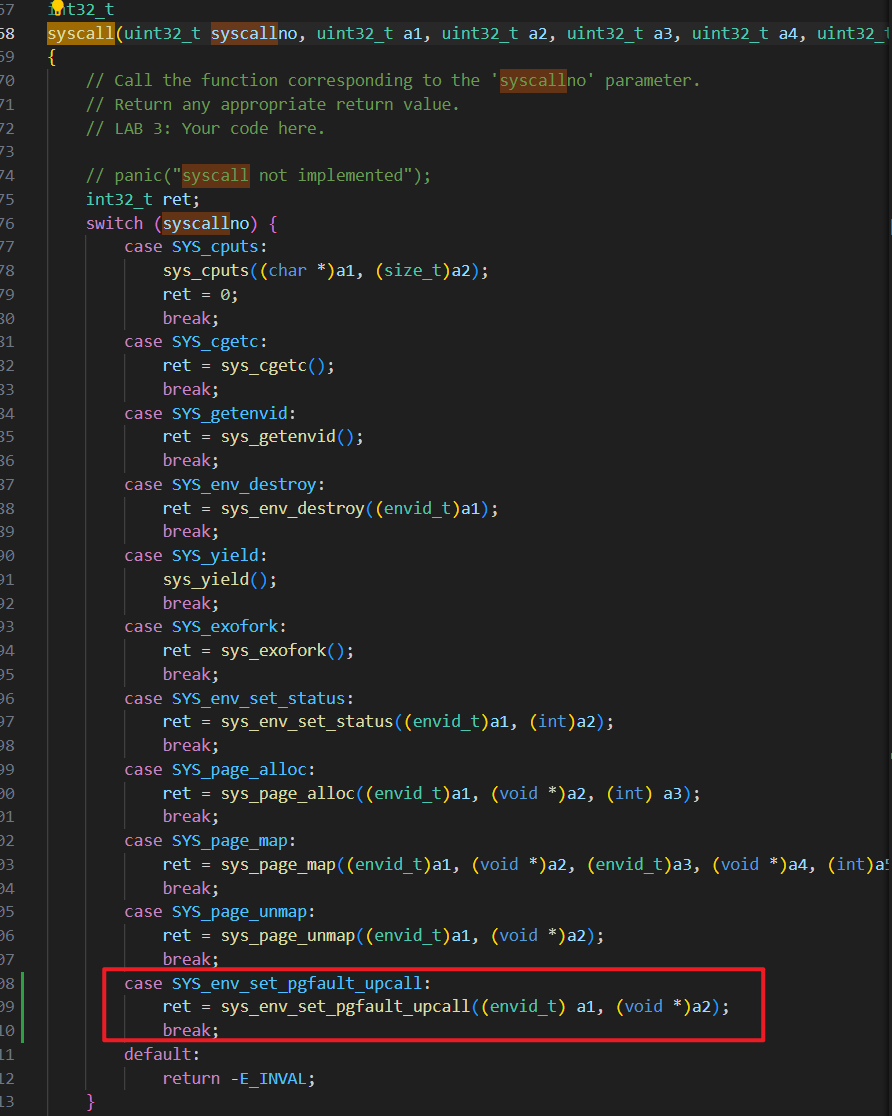
调用用户页面故障处理程序
现在我们终于要完善页面故障处理程序 —— page_fault_handler 了。
我们知道目前的 page_fault_handler 仅仅是一个简单实现,但他确是所有页面故障处理的入口。如果我们希望实现用户级页面故障处理,那么应该在这个地方调用上一步设置的处理程序。
但是, page_fault_handler 还不只是这么简单。想一想,如果是 page_fault_handler 自然是内核态的,但是用户自己的处理程序肯定是用户态的,然而我们目前中断使用的栈却是内核栈,用户的处理程序肯定访问不到。怎么办呢?
JOS的方法是,为每个用户进程在各自的地址空间中划分用户异常栈,这个栈不可能由CPU来自动push值了,因此由我们的 page_fault_handler 来传值。传值的形式和 struct trapframe 类似,用户异常栈使用 struct UTrapframe,从栈顶 UXSTACKTOP 开始,形如:
<-- UXSTACKTOP
trap-time esp
trap-time eflags
trap-time eip
trap-time eax start of struct PushRegs
trap-time ecx
trap-time edx
trap-time ebx
trap-time esp
trap-time ebp
trap-time esi
trap-time edi end of struct PushRegs
tf_err (error code)
fault_va <-- %esp when handler is run
不过存在这种情况:进行用户级页面处理的过程中,又发生了页面故障,这个时候应该在目前的用户异常栈的基础上,先push一个空32字,再继续push数据。 那如何判断某次处理究竟是不是递归的情况呢?
答案是:测试 tf->tf_esp 是否已经位于用户异常栈之中。
最后,再调用用户的处理程序。
所以说,我们要做的事情:
- 判断curenv->env_pgfault_upcall 是否设置
- 修改esp,将其切换到异常栈
- 对于首次缺页,是直接切换
- 对于递归缺页,是在当前tf->tf_esp的下方。
- 再异常栈上压入一个UTrapframe
- 将eip设置为env_pgfault_upcall
page_fault_handler
void
page_fault_handler(struct Trapframe *tf)
{
uint32_t fault_va;
// Read processor's CR2 register to find the faulting address
fault_va = rcr2(); //获取发生页错误的地址
// Handle kernel-mode page faults.
// LAB 3: Your code here.
if ((tf->tf_cs & 3) == 0)
panic("page_fault_handler():page fault in kernel mode!\n");
// 我们已经处理过内核模式异常,所以如果我们到达这里,页面故障就发生在用户模式下。
// 调用环境的页面故障上调(如果有的话)。
// 在用户异常堆栈(低于 UXSTACKTOP)上建立一个页面故障堆栈框架,
// 然后分支到 curenv->env_pgfault_upcall。
//
// 页面故障向上调用可能会导致另一个页面故障,
// 在这种情况下,我们会递归分支到页面故障向上调用,
// 在用户异常堆栈顶部推送另一个页面故障堆栈框架。
//
// 从页面故障返回的代码(lib/pfentry.S)在陷阱时间栈的顶部有一个字的抓取空间,
// 这对我们来说很方便,可以更容易地恢复 eip/esp。
// 在非递归情况下,我们不必担心这个问题,因为常规用户栈的顶部是空闲的。
// 在递归情况下,这意味着我们必须在当前的异常栈顶和新的栈帧之间多留一个字,
// 因为异常栈 _ 就是陷阱时间栈。
//
// 如果没有向上调用页面故障,环境没有为其异常堆栈分配页面或无法写入页面,
// 或者异常堆栈溢出,则销毁导致故障的环境。
// 请注意,本级脚本假定您将首先检查页面故障上调,
// 如果没有,则打印下面的 “用户故障 va ”信息。
// 其余三个检查可以合并为一个测试。
//
// 提示:
// user_mem_assert() 和 env_run() 在这里很有用。
// 要改变用户环境的运行方式,请修改'curenv->env_tf' // ('tf'变量的值为 0)。
// tf'变量指向'curenv->env_tf')。
// LAB 4: Your code here.
//检查是否有处理页错误的handler
if(curenv->env_pgfault_upcall)
{
uintptr_t stacktop = UXSTACKTOP;
//检查是否在递归调用handler
if(tf->tf_esp > UXSTACKTOP-PGSIZE && tf->tf_esp < UXSTACKTOP)
stacktop = tf->tf_esp;
//预留32位字的scratch space
uint32_t size = sizeof(struct UTrapframe) + sizeof(uint32_t);
//检查是否有权限读写exception stack
user_mem_assert(curenv, (void *)(stacktop-size), size, PTE_U|PTE_W);
//填充UTrapframe
struct UTrapframe *utf = (struct UTrapframe *)(stacktop-size);
utf->utf_fault_va = fault_va;
utf->utf_err = tf->tf_err;
utf->utf_regs = tf->tf_regs;
utf->utf_eip = tf->tf_eip;
utf->utf_eflags = tf->tf_eflags;
utf->utf_esp = tf->tf_esp;
//设置eip和esp,运行handler
curenv->env_tf.tf_eip = (uintptr_t)curenv->env_pgfault_upcall;
curenv->env_tf.tf_esp = (uintptr_t)utf;
env_run(curenv);
}
// Destroy the environment that caused the fault.
cprintf("[%08x] user fault va %08x ip %08x\n",
curenv->env_id, fault_va, tf->tf_eip);
print_trapframe(tf);
env_destroy(curenv);
}
用户模式页面故障入口点
用户级页面故障管理还有一个问题,那就是谁负责初始化、维护用户异常栈。我们知道,内核会帮用户将trap-time时的状态保存到用户异常栈上。
但实际上,这个用户异常栈,从始至终都没有被初始化过。
对于内核而言,每个用户都有一个默认的页面故障处理程序,那就是打印错误地址。然后退出。
用户页面故障是个自选的功能,JOS让需要自定义处理的进程,自己初始化、维护用户异常栈。内核至负责必要的传值工作,即 page_fault_handler。而page_fault_handler 最后直接使用 env_run 将控制权归还用户了,这意味着,用户需要自己销毁内核传到用户异常栈上的数据。并且自己恢复到 trap-time 状态。
实际上,这一步还挺不容易的,这里存在的困难在于,我们要让所有寄存器保持trap-time state,并跳转回去。
- 我们不能调用 "jmp xxx",因为这要求我们将地址加载到某个寄存器中,而这会使得该寄存器无法保持trap-time state
- 我们也不能从异常堆栈调用 "ret",因为如果这样做,%esp 就不是trap-time 的值。
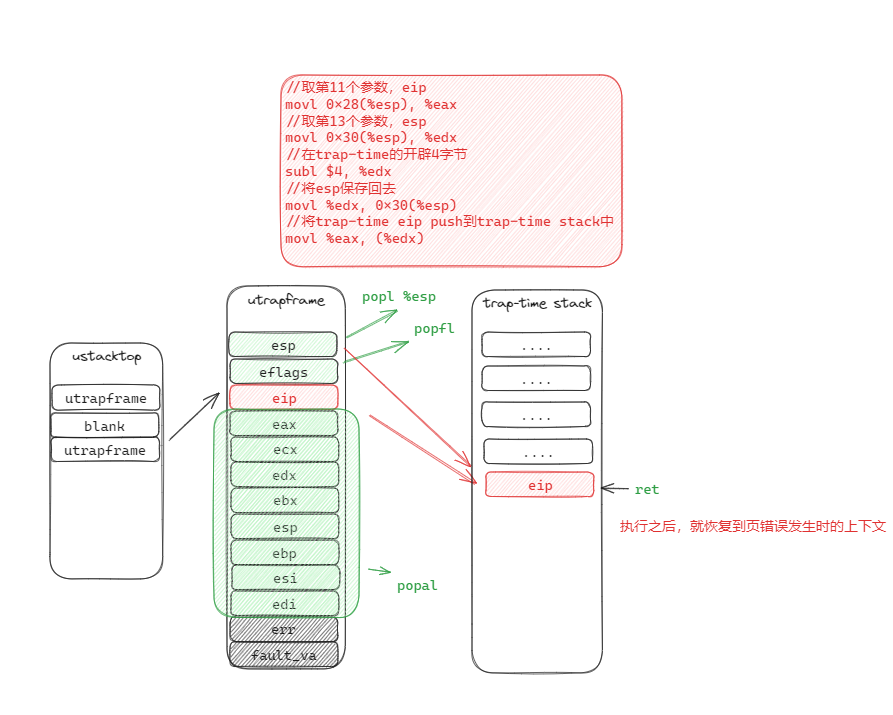
因此,手册给出的答题思路是:
- 从用户异常栈上读取 trap-time 的 sp
- 将 trap-time 的 eip 推送到 trap-time 的stack (即保存到 trap-time 的 sp 所指位置)
- 从 用户异常栈上的utrapframe,恢复寄存器状态(跳过 eip)
- 恢复 esp (切换回 trap-time 的sp),由于第二步的操作,此时esp所指位置是 trap-time的eip
- ret,将 esp 所指的值弹给 PC。
接下来练习10 完成恢复 trap-time state,在练习11 完成用户异常栈的初始化
Exercise 10
练习 10. 实现
lib/pfentry.S中的_pgfault_upcall例程。有趣的部分是返回到用户代码中引起页面故障的原始点。你将直接返回到那里,而无需返回内核。困难的部分是同时切换堆栈和重新加载 EIP。
_pgfault_upcall
// 每当我们在用户空间引发页面故障时,
// 我们都会要求内核将我们重定向到这里
//(参见 pgfault.c 中对 sys_set_pgfault_handler 的调用)。
//
// 当页面故障实际发生时,如果我们尚未进入用户异常堆栈,
// 内核会将我们的 ESP 切换到用户异常堆栈,
// 然后将一个 UTrapframe 推入用户异常堆栈:
//
// 陷阱时 esp
// 陷阱时 eflags
// 陷阱时 eip
// utf_regs.reg_eax
// ...
// utf_regs.reg_esi
// utf_regs.reg_edi
// utf_err(错误代码)
// utf_fault_va <-- %esp
//
// 如果这是一个递归故障,
// 内核将在陷阱时 esp 的上方为我们保留一个空白字,
// 以便在我们解除递归调用时进行从头处理。
//
// 然后,我们在 C 代码中调用相应的页面故障处理程序,
// 该处理程序由全局变量“_pgfault_handler ”指向。
.text
.globl _pgfault_upcall
_pgfault_upcall:
// Call the C page fault handler.
pushl %esp // function argument: pointer to UTF
movl _pgfault_handler, %eax
call *%eax
addl $4, %esp // pop function argument
// Now the C page fault handler has returned and you must return
// to the trap time state.
// Push trap-time %eip onto the trap-time stack.
//
// Explanation:
// We must prepare the trap-time stack for our eventual return to
// re-execute the instruction that faulted.
// Unfortunately, we can't return directly from the exception stack:
// We can't call 'jmp', since that requires that we load the address
// into a register, and all registers must have their trap-time
// values after the return.
// We can't call 'ret' from the exception stack either, since if we
// did, %esp would have the wrong value.
// So instead, we push the trap-time %eip onto the *trap-time* stack!
// Below we'll switch to that stack and call 'ret', which will
// restore %eip to its pre-fault value.
//
// In the case of a recursive fault on the exception stack,
// note that the word we're pushing now will fit in the
// blank word that the kernel reserved for us.
//
// Throughout the remaining code, think carefully about what
// registers are available for intermediate calculations. You
// may find that you have to rearrange your code in non-obvious
// ways as registers become unavailable as scratch space.
//
// LAB 4: Your code here.
addl $8, %esp // 清除 fault_va 和 error code
movl 32(%esp), %eax // 取 trap-time-eip 到 eax
movl 40(%esp), %edx // 取 trap-time-esp 到 edx
subl $4, %edx // 在 trap-time的栈上开辟4字节用于存储 trap-time-eip
movl %eax, (%edx) // 将 trap-time-eip 保存到 trap-time-esp
movl %edx, 40(%esp) // 将修改后的trap-time esp保存回栈上
// Restore the trap-time registers. After you do this, you
// can no longer modify any general-purpose registers.
// LAB 4: Your code here.
popal // 恢复寄存器
// Restore eflags from the stack. After you do this, you can
// no longer use arithmetic operations or anything else that
// modifies eflags.
// LAB 4: Your code here.
addl $4, %esp // 跳过 eip
popfl // 恢复 eflags
// Switch back to the adjusted trap-time stack.
// LAB 4: Your code here.
popl %esp // 切换会 trap-time栈
// Return to re-execute the instruction that faulted.
// LAB 4: Your code here.
ret // 回到 trap-time的指令
Exercise 11
练习 11. 完成 lib/pf 中的 set_pgfault_handler()。
void
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r;
if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
// panic("set_pgfault_handler not implemented");
// 为当前环境分配异常栈
if(sys_page_alloc(0, (void *)(UXSTACKTOP - PGSIZE), PTE_U|PTE_W | PTE_P)<0)
panic("set_pgfault_handler failed.");
sys_env_set_pgfault_upcall(0, _pgfault_upcall);
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
}
小总结:页面故障的流程
页面错误时的控制流:
- 用户进程首先调用 set_pgfault_handler,设置自定义的页面故障处理过程。(绿色、黄色箭头)
- 用户进程正常执行,直至触发页面故障(红色箭头)
- 内核处理中断,将控制权归还给用户自定义页面故障处理(蓝色箭头)
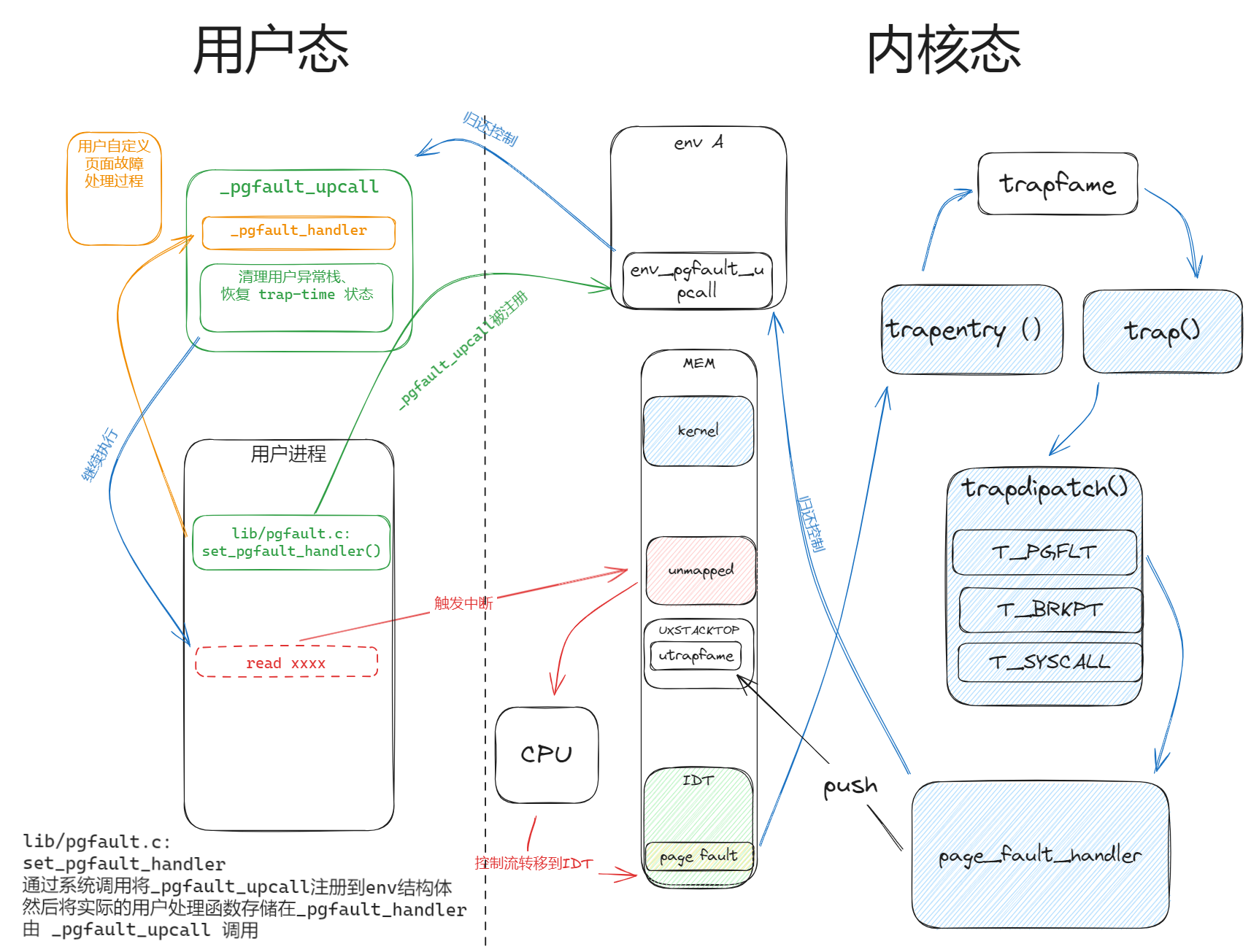
有一点就是,set_pgfault_handler 这个函数,只会将 _pgfault_upcall 这个过程注册到 env 结构体中。
用户自定义的页面故障处理被保存在 _pgfault_handler,由 _pgfault_upcall调用。
也就是说_pgfault_upcall 相当于是个页面故障处理模版,帮助用户进程处理用户异常栈的恢复过程。
发生页错误后,_page_upcall 负责调用 _pgfault_handler,并恢复上下文
测试
debug的时候发现,lib/pgfault.c:set_pgfault_handler 怎么装不上handler。
导致过不了很多测试。来回查了半天,发现 sys_env_set_pgfault_upcall 在做exercise 8的时候忘了给注册到 syscall 里去了。
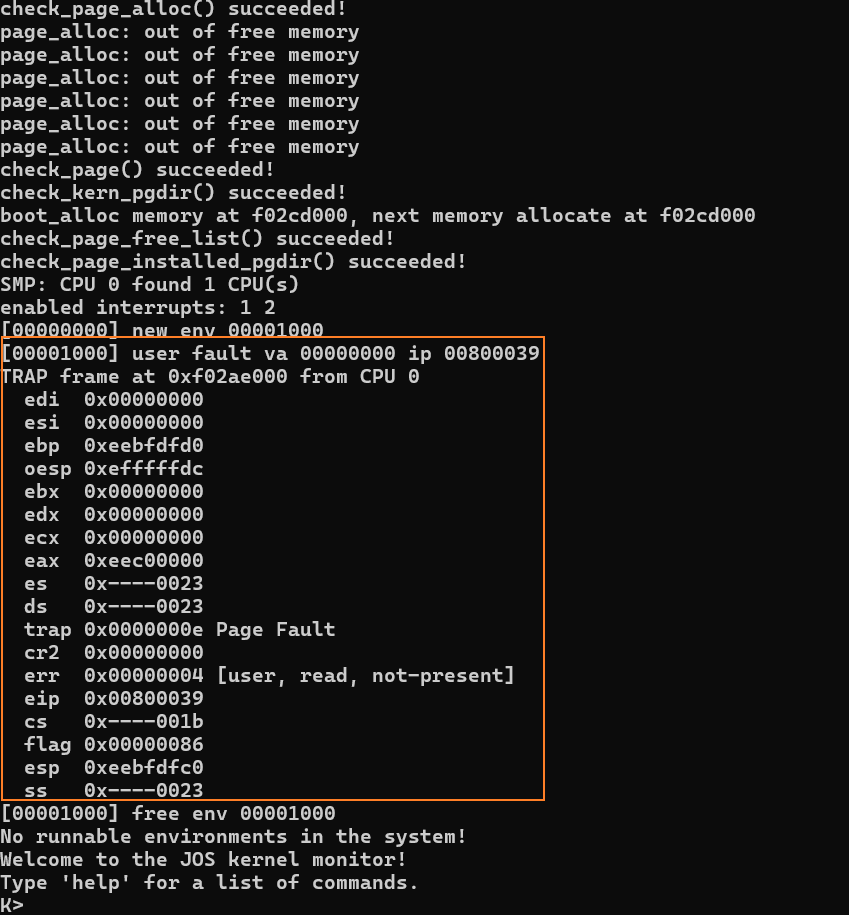
user/faultread
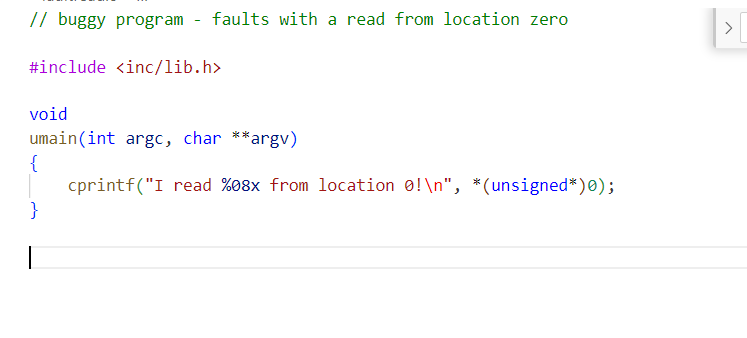
这个程序没有注册handler,那就会在 page_fault_handler 检查handler合规时失败,打印trapframe后销毁环境。

user/faultdie
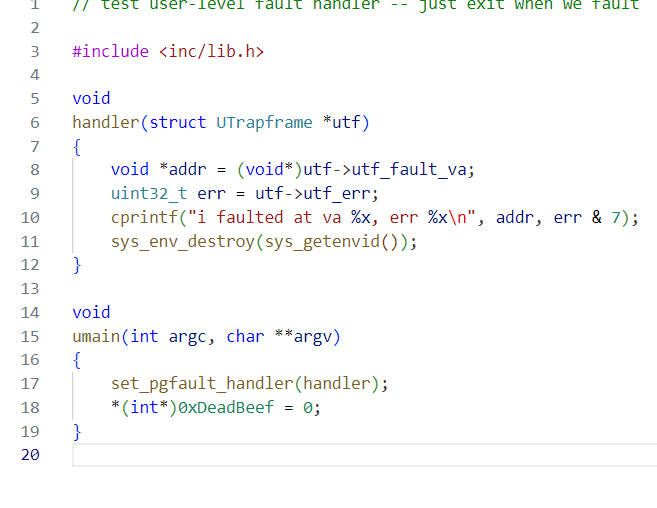
这个用户程序的handler打印了引发页错误的地址和错误号。
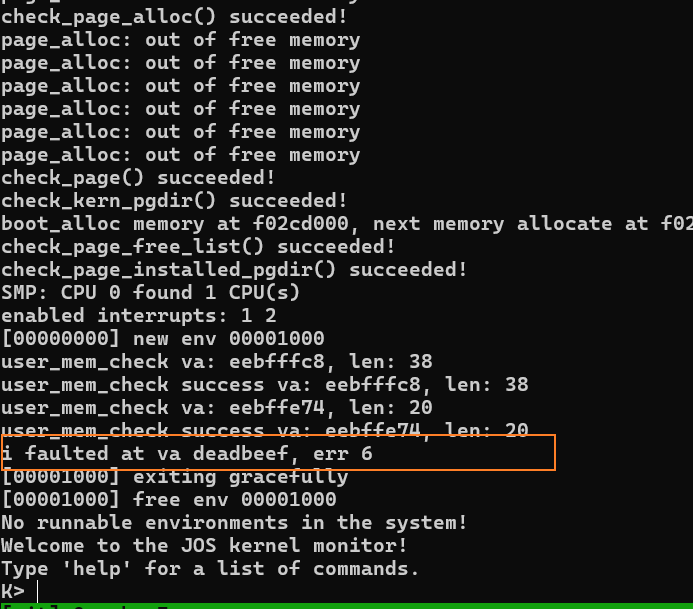
user/faultalloc
#include <inc/lib.h>
void
handler(struct UTrapframe *utf)
{
int r;
void *addr = (void*)utf->utf_fault_va;
cprintf("fault %x\n", addr);
if ((r = sys_page_alloc(0, ROUNDDOWN(addr, PGSIZE),
PTE_P|PTE_U|PTE_W)) < 0)
panic("allocating at %x in page fault handler: %e", addr, r);
snprintf((char*) addr, 100, "this string was faulted in at %x", addr);
}
void
umain(int argc, char **argv)
{
set_pgfault_handler(handler);
cprintf("%s\n", (char*)0xDeadBeef);
cprintf("%s\n", (char*)0xCafeBffe);
}
faultalloc 尝试访问两个地址,然后handler中通过 sys_page_alloc 申请这两个地址再访问。
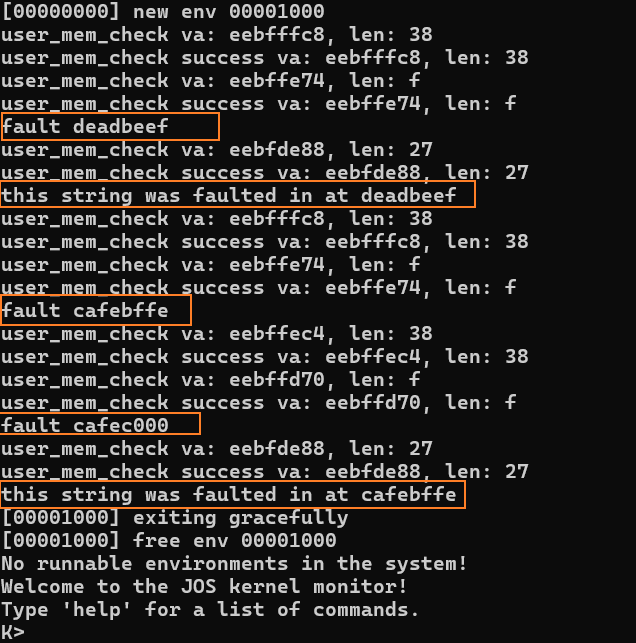
deadbeef这个地址在发生页错误后,通过 handler 申请内存页后成功访问了。
但是 cafebffe 在发生一次页错误后,似乎又发生了一次页错误,因为 cafebffe 在页中正好处于 倒数第二个字节(0xffe),handler又将一长串字符保存到了cafebffe,所以引发了第二次页错误。
第二次handler在申请玩cafec000的内存页后,将一长串字符串保存到了cafec000,然后控制流回到第一次handler处理错误,继续将字符保存到cafebffe的位置,然后将控制流返回到umain的最后一句话,将第一次handler的字符串打出来。
handler第二次保存的字符串应该是被第一次保存的字符串覆盖,没覆盖的地方被尾巴'\0'切断了。
user/faultallocbad
// test user-level fault handler -- alloc pages to fix faults
// doesn't work because we sys_cputs instead of cprintf (exercise: why?)
#include <inc/lib.h>
void
handler(struct UTrapframe *utf)
{
int r;
void *addr = (void*)utf->utf_fault_va;
cprintf("fault %x\n", addr);
if ((r = sys_page_alloc(0, ROUNDDOWN(addr, PGSIZE),
PTE_P|PTE_U|PTE_W)) < 0)
panic("allocating at %x in page fault handler: %e", addr, r);
snprintf((char*) addr, 100, "this string was faulted in at %x", addr);
}
void
umain(int argc, char **argv)
{
set_pgfault_handler(handler);
sys_cputs((char*)0xDEADBEEF, 4);
}
结果是没有出发 handler ,反而是 user_mem_assert 输出了。
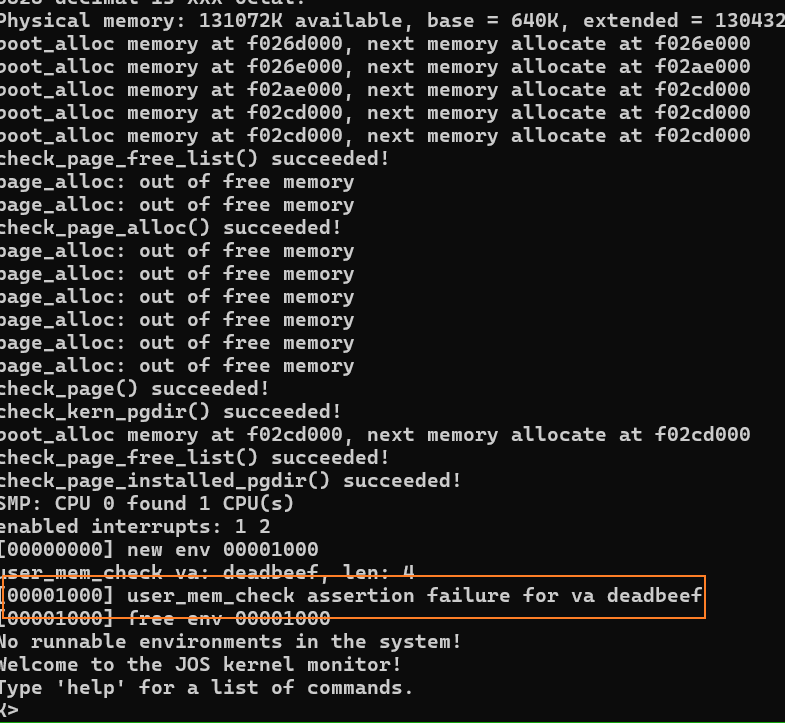
faultallocbad 和 faultalloc 的 handler 是一样的,区别在于使用 sys_cputs 打印。sys_cputs 第一件工作就是用 user_mem_assert 确认 0xDEADBEEF 是否使用,还没有机会触发页错误。
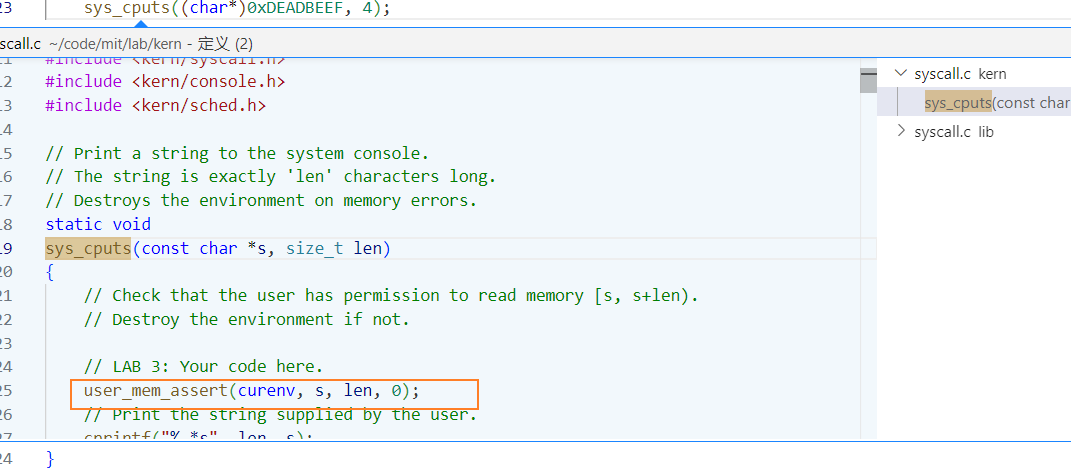
by the way :user_mem_assert的检查方式是查页表,看PTE是否合规。这个过程是不会发生页错误的。
实现写时复制的fork
现在,我们终于完全拥有了完全在用户空间实现写时复制 fork() 的内核设施。
在 lib/fork.c 中 fork() 已经提供了一个骨架。与 dumbfork() 一样,fork() 也会创建一个新环境,然后扫描父环境的整个地址空间,并在子环境中设置相应的页面映射。
不同之处在于,dumbfork() 将每个页面逐个字节的复制。而 fork() 最初只会复制页面映射。
只有当其中一个环境试图写入页面时,fork() 才会复制每个页面。
fork的基本框架如下:
- fork函数:负责复制自身,并调用duppage复制页映射,设置页面故障handler
- duppage:负责复制页映射的具体工作
- pgfault:页故障handler,当发生对写时复制页进行写操作时,将页面进行实际复制。
fork的具体流程:
- 父级程序会使用上面实现的 set_pgfault_handler() 函数安装 pgfault() 作为用户级页面故障处理程序。
- 父环境调用 sys_exofork(),创建子环境。
- 父环境将[0~UTOP]的地址空间中所有“可写PTE_W”、“写时复制PTE_COW”页面的映射,通过 duppage 复制到子环境中,然后将写时复制页面重新映射到自己的地址空间(为何?不太清楚)。
- 对于 [UXSTACKTOP-PGSIZE, UXSTACKTOP] 的部分则是申请新的页面。
- 对于只读页面直接保持原权限复制即可。
发生页错误时,就会触发 pgfault() 然后将PTE_COW的页面用新页替换。
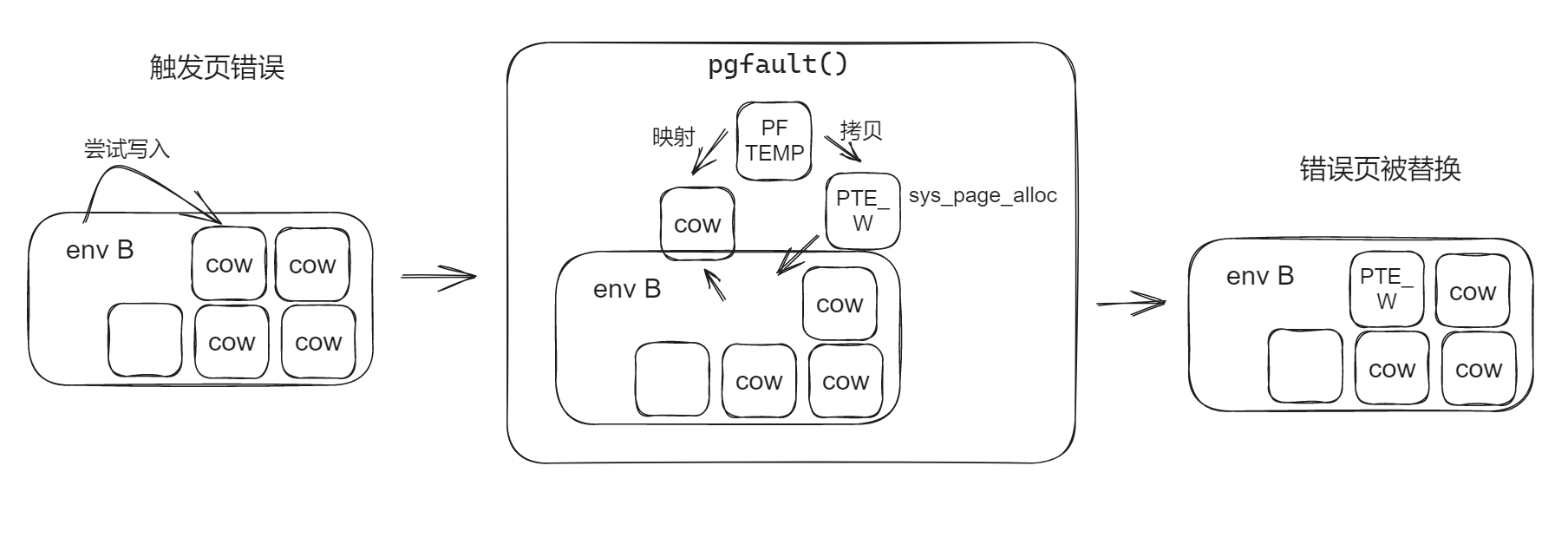
练习12 完成fork, duppage, pgfault
练习 12. 在 `lib/fork.c` 中实现 `fork`、`duppage` 和 `pgfault`。
用 `forktree` 程序测试你的代码。它应该会产生以下信息,其中夹杂着 "new env"、"free env "和 "exiting gracefully "信息。这些信息可能不会按此顺序出现,环境 ID 也可能不同。
1000: I am ''
1001: I am '0'
2000: I am '00'
2001: I am '000'
1002: I am '1'
3000: I am '11'
3001: I am '10'
4000: I am '100'
1003: I am '01'
5000: I am '010'
4001: I am '011'
2002: I am '110'
1004: I am '001'
1005: I am '111'
1006: I am '101'
fork
注意理解 uvpt 和 uvpd
uvpt 就是 UVPT,是虚拟地址,范围是PTSIZE,4mb,使用PGNUM宏搜索,取出pte的虚拟地址。
uvpd 是 pgdir 所在的虚拟地址,范围是一个内存页,4kb,使用PDE宏搜索,取出pde的虚拟地址。。
然后就是关于 PFTEMP,前文中有测试过用户的dupapge,我们需要这个区域实现进程间的页面复制。
// implement fork from user space
#include <inc/string.h>
#include <inc/lib.h>
// PTE_COW 标记写时复制页表项。
// 它是明确分配给用户进程的位之一(PTE_AVAIL)。
#define PTE_COW 0x800
//
// 自定义页面故障处理程序 - 如果故障页面是写时复制、
// 映射到我们自己的私有可写副本中。
//
static void
pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t err = utf->utf_err;
int r;
// 检查故障访问是否 (1) 可写;(2) 是写时复制页。 如果不是,则 panic。
// 提示:
// 在 uvpt 中使用只读页表映射(参见 <inc/memlayout.h>)。
// LAB 4: Your code here.
//只在对“写时复制页面”进行“写操作”才处理
if(!(err & FEC_WR))
{
panic("trapno is not FEC_WR.");
}
if(!(uvpt[PGNUM(addr)] & PTE_COW))
{
panic("fault addr is not COW");
}
// 分配一个新页面,将其映射到临时位置 (PFTEMP),
// 将旧页面的数据复制到新页面,然后将新页面移动到旧页面的地址。
// 提示:
// 你应该调用三次系统调用。
// LAB 4: Your code here.
// panic("pgfault not implemented");
addr = ROUNDDOWN(addr, PGSIZE);
//将当前进程PFTEMP也映射到当前进程addr指向的物理页
if ((r = sys_page_map(0, addr, 0, PFTEMP, PTE_U|PTE_P)) < 0)
panic("sys_page_map: %e", r);
//令当前进程addr指向新分配的物理页
if ((r = sys_page_alloc(0, addr, PTE_P|PTE_U|PTE_W)) < 0)
panic("sys_page_alloc: %e", r);
//将PFTEMP指向的物理页拷贝到addr指向的物理页
memmove(addr, PFTEMP, PGSIZE);
//解除当前进程PFTEMP映射
if ((r = sys_page_unmap(0, PFTEMP)) < 0)
panic("sys_page_unmap: %e", r);
}
//
// 将我们的虚拟页面 pn(地址 pn*PGSIZE)映射到相同虚拟地址的目标 envid 中。
// 如果页面是可写或写时复制的,则必须创建写时复制的新映射,
// 然后我们的映射也必须标记为写时复制。
// (练习: 如果我们的映射在本函数开始时已经是写时复制,为什么还需要再次标记写时复制?)
//
// Returns: 0 on success, < 0 on error.
// It is also OK to panic on error.
//
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
// panic("duppage not implemented");
void *addr = (void *)(pn * PGSIZE);
if(uvpt[pn] & PTE_SHARE)
{
sys_page_map(0, addr, envid, addr, PTE_SYSCALL);
}
else if ((uvpt[pn]&PTE_W)|| (uvpt[pn] & PTE_COW))
{
if ((r = sys_page_map(0, addr, envid, addr, PTE_COW|PTE_U|PTE_P)) < 0)
panic("sys_page_map:%e", r);
if ((r = sys_page_map(0, addr, 0, addr, PTE_COW|PTE_U|PTE_P)) < 0)
panic("sys_page_map:%e", r);
}
else
{
sys_page_map(0, addr, envid, addr, PTE_U|PTE_P); //对于只读的页,只需要拷贝映射关系即可
}
return 0;
}
//
// 使用写时复制的用户级 fork。
// 适当设置页面故障处理程序。
// 创建一个子进程。
// 将我们的地址空间和页面故障处理程序设置复制到子运行程序中。
// 然后将子进程标记为可运行并返回。
//
// 返回:子代的 envid 返回给父代,0 返回给子代,< 0 表示出错。
// 出错时也可以 panic。
//
// 提示
// 使用 uvpd、uvpt 和 duppage。
// 记住在子进程中固定 “thisenv”。
// 用户异常堆栈都不应该标记为写时复制、
// 因此必须为子进程的用户异常堆栈分配一个新页面。
//
envid_t
fork(void)
{
// LAB 4: Your code here.
// panic("fork not implemented");
extern void _pgfault_upcall(void);
set_pgfault_handler(pgfault);
envid_t eid = sys_exofork(); // 创建子进程
if(eid < 0){
panic("sys_exofork Failed, envid: %e", eid);
}
if(eid == 0){ // 子进程进入该分支
thisenv = &envs[ENVX(sys_getenvid())];
return 0;
}
for(uint32_t addr = 0; addr < USTACKTOP; addr += PGSIZE){
if((uvpd[PDX(addr)] & PTE_P) &&
(uvpt[PGNUM(addr)]&PTE_P) &&
(uvpt[PGNUM(addr)] &PTE_U)){
duppage(eid, PGNUM(addr));
}
}
//为子环境的异常栈申请内存页
int r = sys_page_alloc(eid, (void *)(UXSTACKTOP-PGSIZE), PTE_P|PTE_W|PTE_U);
if( r < 0)
panic("sys_page_alloc: %e", r);
//为子环境设置pgfault_upcall
r= sys_env_set_pgfault_upcall(eid, _pgfault_upcall);
if( r < 0 )
panic("sys_env_set_pgfault_upcall: %e",r);
//设置子环境的运行状态
r = sys_env_set_status(eid, ENV_RUNNABLE);
if (r < 0)
panic("sys_env_set_status: %e", r);
return eid;
}
// Challenge!
int
sfork(void)
{
panic("sfork not implemented");
return -E_INVAL;
}
Part B 结束
标签:Fork,addr,handler,PTE,mit6.828,故障,pgfault,Part,页面 From: https://www.cnblogs.com/toso/p/18202341