简单回顾
在开始 lab3 的学习之前,我们先简单回顾下 到目前为止,我们的内核能做了什么:
lab1中,我们学习了 PC启动的过程,看到BIOS将我们编写的boot loader 载入内存,然后通过bootloader 将内核载入内存。同时,使用了一个写死的临时页表(entry_pgdir)完成了简单的地址映射;我们的内核最后执行monitor函数(一个简单的shell),这是个看起来像是xxx管理系统的C语言课程设计程序,他接收命令行输入,将输入解析成命令,并逐个调用相关函数。
但是,问题在于,这样简单的页表,只能映射4MB大小的物理内存,如果我们的内核代码增加了(更不用说加载用户进程了),4MB不够用了,就直接G了,因此发展内核的当务之急就是解决内存的生存空间危机。因此lab2中,我们学习了如何通过 pageinfo 构成的数组pages 和 链表 page_free_list 来管理物理内存;然后学习了页表的映射原理,并编写代码实现了增删查改页表,达到pageinfo和pte之间的映射和取消映射。拥有了这样的基础设施,我们可以将所有物理内存全部利用起来。
但是到现在为止,我们的JOS的功能还是只有一个简单的monitor,无法加载用户进程(或者说,加载运行其他的可执行文件)。为了能够实现加载用户进程,在lab3中,我们要实现进程加载、调度的基础设施。
lab3主要内容是
- 完成进程管理的初始化
- 完成中断管理的初始化
- 完成系统调用的中断处理
- 完成内存保护
lab3 新增的代码源文件如下,没必要一开始就全看,跟着手册遇到什么看什么,最后自然就看完了。
| 目录 | 文件 | 备注 |
|---|---|---|
| inc/ | env.h | Public definitions for user-mode environments |
| trap.h | Public definitions for trap handling | |
| syscall.h | Public definitions for system calls from user environments to the kernel | |
| lib.h | Public definitions for the user-mode support library | |
| kern/ | env.h | Kernel-private definitions for user-mode environments |
| env.c | Kernel code implementing user-mode environments | |
| trap.h | Kernel-private trap handling definitions | |
| trap.c | Trap handling code | |
| trapentry.S | Assembly-language trap handler entry-points | |
| syscall.h | Kernel-private definitions for system call handling | |
| syscall.c | System call implementation code | |
| lib/ | Makefrag | Makefile fragment to build user-mode library, obj/lib/libjos.a |
| entry.S | Assembly-language entry-point for user environments | |
| libmain.c | User-mode library setup code called from entry.S | |
| syscall.c | User-mode system call stub functions | |
| console.c | User-mode implementations of putchar and getchar, providing console I/O | |
| exit.c | User-mode implementation of exit | |
| panic.c | User-mode implementation of panic | |
| user/ | * | Various test programs to check kernel lab 3 code |
Part A 用户进程和异常处理
就像使用 pages 数组管理物理内存一样,JOS 使用 envs 数组管理所有的进程。在 lab3 中,我们的目标是加载、运行一个用户环境,但是一个操作系统当然要处理多个进程了,不过这是 lab4要做的事情了,现在我们要做的是熟悉JOS 维护进程的数据结构和相应的函数。
在 kern/env.c 中看到的,内核维护着三个与环境有关的主要全局变量:
struct Env *envs = NULL; // All environments
struct Env *curenv = NULL; // The current env
static struct Env *env_free_list; // Free environment list
一旦 JOS 启动并运行,envs 指针就会指向一个代表系统中所有环境的 Env 结构数组。在我们的设计中,JOS 内核最多可同时支持 NENV 个活动环境,不过在任何时候运行的环境通常都要少得多。(NENV 是一个在 inc/env.h 中 #define 的常量。)分配完毕后,envs 数组将包含一个 Env 数据结构实例,用于表示每个 NENV 可能的环境。
JOS 内核会将所有不活动的 Env 结构保存在 env_free_list 中。这种设计可以方便地分配和取消分配环境,因为只需将它们添加到空闲列表或从空闲列表中移除即可。这和 page_free_list 异曲同工。
核使用 curenv 符号随时跟踪当前正在执行的环境。在启动过程中,在第一个环境开始运行之前,curenv 初始化为 NULL。
现在我们要先熟悉 env 结构体,其位于 inc/env.h。
struct Env {
struct Trapframe env_tf; // 保存的寄存器
struct Env *env_link; // 下一个空闲的进程
envid_t env_id; // 进程的唯一标识符
envid_t env_parent_id; // 该进程的父进程的 env_id
enum EnvType env_type; // 用于标识是否是特殊的系统进程
unsigned env_status; // 进程状态
uint32_t env_runs; // 进程运行次数
// Address space
pde_t *env_pgdir; // Kernel virtual address of page dir
};
可以看到,比较关键的有进程id、进程状态、特殊进程标识,这些在 inc/env.h 中都有定义。比较令人迷惑的是这个运行次数,暂时不知道是什么含义。先来看看进程ID的定义:
typedef int32_t envid_t;
// An environment ID 'envid_t' has three parts:
//
// +1+---------------21-----------------+--------10--------+
// |0| Uniqueifier | Environment |
// | | | Index |
// +------------------------------------+------------------+
// \--- ENVX(eid) --/
//
// The environment index ENVX(eid) equals the environment's index in the
// 'envs[]' array. The uniqueifier distinguishes environments that were
// created at different times, but share the same environment index.
//
// All real environments are greater than 0 (so the sign bit is zero).
// envid_ts less than 0 signify errors. The envid_t == 0 is special, and
// stands for the current environment.
#define LOG2NENV 10
#define NENV (1 << LOG2NENV)
#define ENVX(envid) ((envid) & (NENV - 1))
可以看到 env_id 本质上就是 32位整数,然后低10位代表其在envs中的下标,之后21位用来区分不同时间被创建的进程。这里还是有点迷惑,一个进程被多次载入后,为啥要共用相同的 environment index。
进程 status
这里直接看手册就行了,手册带着介绍了下 struct env以及相关知识。
分配进程数组
Exercise 1
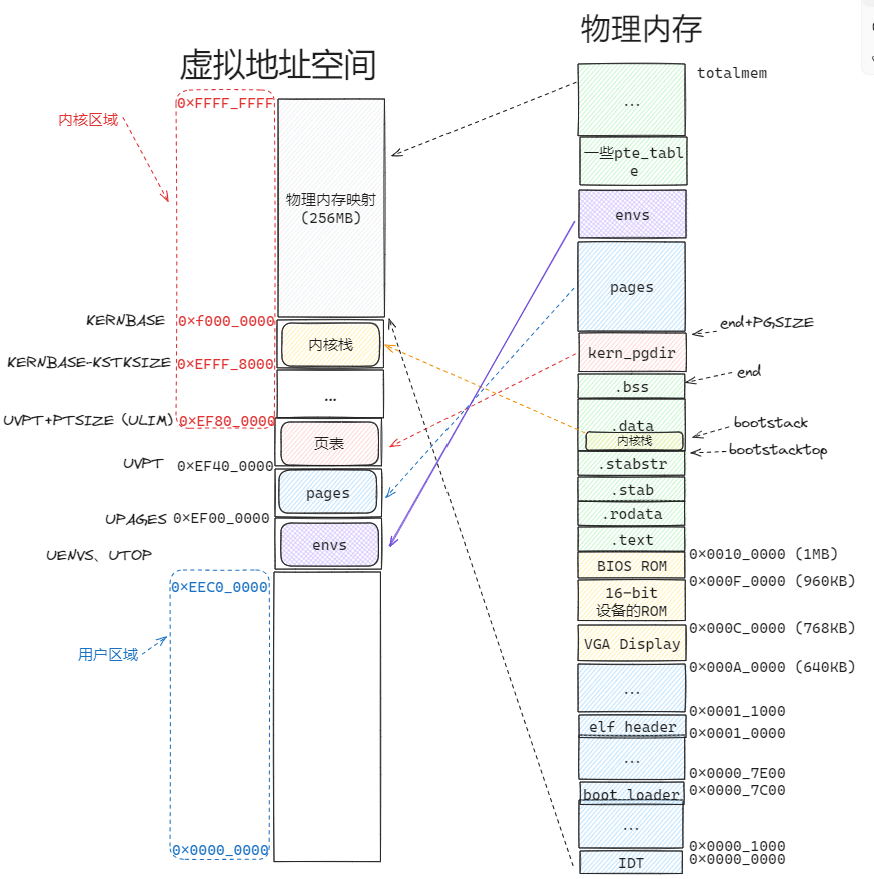
练习 1. 修改 `kern/pmap.c` 中的 `mem_init()` ,分配并映射 `envs` 数组。该数组由 `Env` 结构的 `NENV` 实例组成,分配方式与分配页面数组类似。与页面数组一样,支持 `envs` 的内存也应在 `UENVS`(定义于 `inc/mlayout.h` )处映射为用户只读,这样用户进程才能读取该数组。
你应该运行代码并确保 `check_kern_pgdir()` 成功。
[[lab3 - 翻译#^988084]]
这里和 lab2 的对pages的处理是一样的:
envs = (struct Env *)boot_alloc(sizeof(struct Env) * NENV);
memset(envs, 0, sizeof(struct Env) * NENV);
//...
boot_map_region(kern_pgdir, UENVS, PTSIZE, PADDR(envs), PTE_U | PTE_P);
经过 mem_init 之后内存映射情况如下:
创建并运行进程
经过 练习1,我们有了进程管理的基本数据结构,但是没有初始化和维护这些数据结构的代码,接下来就是实现这一切的重头戏,在 kern/env.c 中编写运行用户环境所需的代码 。
因为我们还没有文件系统,所以我们 将设置内核来加载嵌入在内核本身中的静态二进制映像 。JOS将该二进制文件作为ELF可执行映像嵌入内核。但是,如何将可执行文件嵌入到内核里呢?这种活当然是链接器来干了,看看kern/Makefrag ,链接器命令行上的 -b 二进制选项会将这些文件作为 "原始 "未解释的二进制文件链接进去,而不是编译器生成的普通 .o 文件。
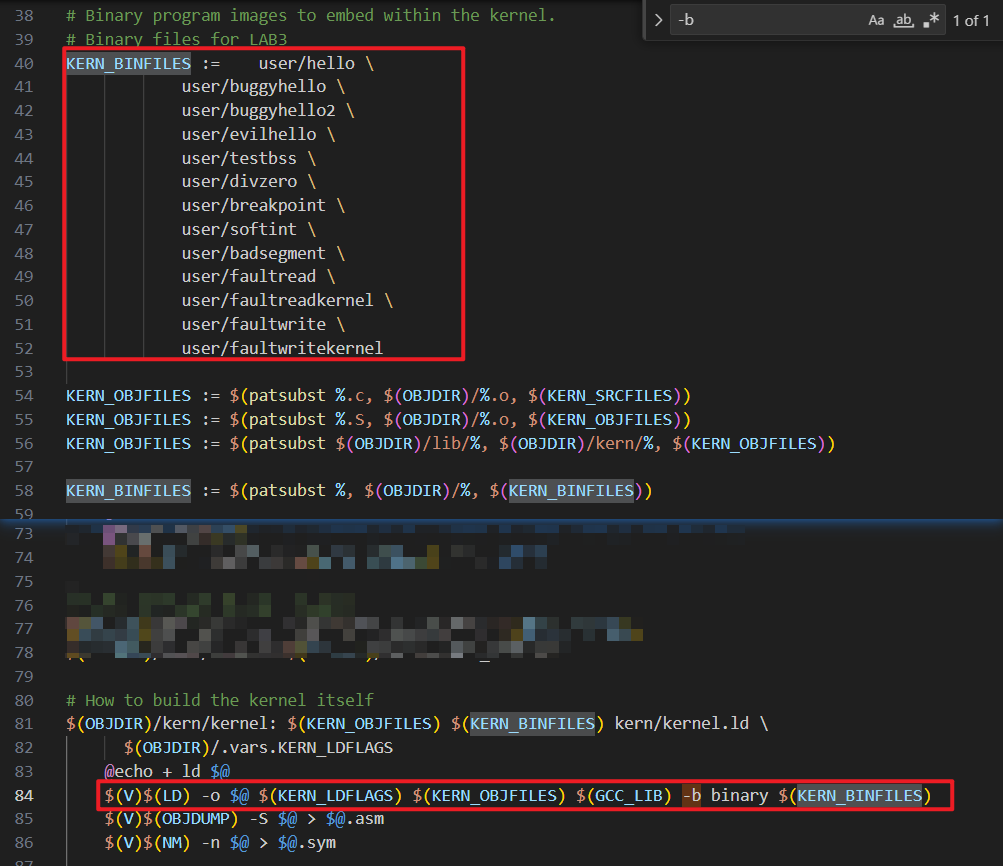
Paart A 的目标就是将用户的进程运行起来,之前,我们的内核在最终会循环调用monitor。现在发生了一些变化:
void
i386_init(void)
{
extern char edata[], end[];
// Before doing anything else, complete the ELF loading process.
// Clear the uninitialized global data (BSS) section of our program.
// This ensures that all static/global variables start out zero.
memset(edata, 0, end - edata);
// Initialize the console.
// Can't call cprintf until after we do this!
cons_init();
cprintf("6828 decimal is %o octal!\n", 6828);
// Lab 2 memory management initialization functions
mem_init();
// Lab 3 user environment initialization functions
env_init();
trap_init();
#if defined(TEST)
// Don't touch -- used by grading script!
ENV_CREATE(TEST, ENV_TYPE_USER);
#else
// Touch all you want.
ENV_CREATE(user_hello, ENV_TYPE_USER);
#endif // TEST*
// We only have one user environment for now, so just run it.
env_run(&envs[0]);
}
在mem_init后又出现了 env_init、trap_init,然后就是用于创建进程的 ENV_CREATE,最后由 env_run将用户进程执行起来,monitor被去掉了。
ENV_CREATE是个宏,在这里他的含义对 user_hello 这个用户进程调用 env_create。
env_create(_binary_obj_user_hello_start, ENV_TYPE_USER)
该宏定义于 kern/env.h :
#define ENV_PASTE3(x, y, z) x ## y ## z
#define ENV_CREATE(x, type) \
do { \
extern uint8_t ENV_PASTE3(_binary_obj_, x, _start)[]; \
env_create(ENV_PASTE3(_binary_obj_, x, _start), \
type); \
} while (0)
#endif // !JOS_KERN_ENV_H
Excercise 2
练习 2.在 env.c 文件中,完成下列函数的编码:
env_init()
初始化 envs 数组中的所有 Env 结构,并将它们添加到env_free_list中。同时调用env_init_percpu,该函数用于为权限级别 0(内核)和权限级别 3(用户)配置独立的分段硬件。
env_setup_vm()
为新环境分配页面目录,并初始化新环境地址空间的内核部分。
region_alloc()
为环境分配和映射物理内存
load_icode()
您需要解析 ELF 二进制映像,就像 Boot Loader 已经做的那样,并将其内容加载到新环境的用户地址空间。
env_create()
用 env_alloc 分配一个环境,然后调用 load_icode 将 ELF 二进制文件加载到该环境中。
env_run()
启动以用户模式运行的给定环境。
在编写这些函数时,您可能会发现新的 cprintf verb %e 非常有用--它会打印出与错误代码相对应的描述。例如r = -E_NO_MEM;
panic("env_alloc: %e", r);
就会出现 "env_alloc: 内存不足 "的提示。
env_init
就像 page_init 一样将 envs 数组初始化
// 将 “envs ”中的所有环境标记为空闲环境,
// 将它们的 env_ids 设置为 0,并将它们插入 env_free_list 中。
// 确保环境在空闲列表中的顺序与它们在 envs 数组中的顺序一致(
// 也就是说,这样第一次调用 env_alloc()时就会返回 envs[0])。
//
void
env_init(void)
{
// Set up envs array
// LAB 3: Your code here.
env_free_list = NULL;
for(int i = NENV-1;i>=0;--i){
envs[i].env_status = ENV_FREE;
envs[i].env_id = 0;
envs[i].env_link = env_free_list;
env_free_list = &envs[i];
}
// Per-CPU part of the initialization
env_init_percpu(); //加载 GDT 和段描述符。
}
注意 for 循环必须是从 NENV 至 0 进行遍历。这样才能保证 env_free_list 的循序和 envs 数组中的顺序一致。
这里看一眼 env_init_percpu()是干什么的
// 加载 GDT 和段描述符。
void
env_init_percpu(void)
{
lgdt(&gdt_pd);
// 内核从不使用 GS 或 FS,因此我们将其设置为用户数据段。
asm volatile("movw %%ax,%%gs" : : "a" (GD_UD|3));
asm volatile("movw %%ax,%%fs" : : "a" (GD_UD|3));
// 内核会使用 ES、DS 和 SS。 我们将根据需要在内核和用户数据段之间进行切换。
asm volatile("movw %%ax,%%es" : : "a" (GD_KD));
asm volatile("movw %%ax,%%ds" : : "a" (GD_KD));
asm volatile("movw %%ax,%%ss" : : "a" (GD_KD));
// 将内核文本段载入 CS。
asm volatile("ljmp %0,$1f\n 1:\n" : : "i" (GD_KT));
// 为了稳妥起见,清除本地描述符表(LDT),因为我们不使用它。
lldt(0);
}
env_setup_vm
// 为环境 e 初始化内核虚拟内存布局。
// 分配一个页面目录,相应设置 e->env_pgdir,并初始化新进程地址空间的内核部分。
// 暂时不要将任何内容映射到环境虚拟地址空间的用户部分。
//
// 成功时返回 0,错误时返回 <0。 错误包括
// -E_NO_MEM 如果页面目录或表无法分配。
//
static int
env_setup_vm(struct Env *e)
{
int i;
struct PageInfo *p = NULL;
// 为页面目录分配页面
// 由于我们在构造一个新的pgdir,而不是向已经存在的kern_pgdir中插入 pde,或插入增加映射
// 我们不能使用 page_insert、pgdir_walk等用于页表管理的方法,
// 只能通过 物理内存管理的方法,申请物理页,并手动调整七计数
if (!(p = page_alloc(ALLOC_ZERO)))
return -E_NO_MEM;
// 现在,设置 e->env_pgdir 并初始化页面目录。
//
// 提示:
// 所有环境的 VA 空间在 UTOP 以上是相同的(UVPT 除外,我们在下面设置)。
// 有关权限和布局,请参见 inc/memlayout.h。
// 能否将 kern_pgdir 用作模板? 提示:可以。
// (确保您在lab 2 中正确设置了权限)。
// - UTOP 下面的初始 VA 是空的。
// - 你不需要再调用 page_alloc。
// - 注意:一般情况下,pp_ref 不会被维护。
// 但 env_pgdir 是个例外 -- 你需要增加 env_pgdir 的 pp_ref 才能使 env_free 正常工作。
// - kern/pmap.h 中的函数非常方便。
// LAB 3: Your code here.
e->env_pgdir = page2kva(p);
memcpy(e->env_pgdir, kern_pgdir, PGSIZE);
// UVPT 将环境自身的页表映射为只读。
p->pp_ref ++;
// Permissions: kernel R, user R
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;// p在此时被映射到UVPT
p->pp_ref ++;//由于直接调用了page_alloc,需要手动计数
return 0;
}
env_setup_vm 会在初始化一个 env 的时候发挥作用,这里看看已经写好的 env_alloc
env_alloc
// 分配并初始化一个新环境。
// 成功后,新环境将存储在 *newenv_store 中。
//
// 成功时返回 0,失败时返回 <0。 错误包括
// -E_NO_FREE_ENV 如果所有 NENV 环境都已分配完毕
// 内存耗尽时返回 E_NO_MEM
//
int
env_alloc(struct Env **newenv_store, envid_t parent_id)
{
int32_t generation;
int r;
struct Env *e;
if (!(e = env_free_list))//从空闲列表中取下一个 env
return -E_NO_FREE_ENV;
// 为该环境分配和设置页面目录。
if ((r = env_setup_vm(e)) < 0)
return r;
// 为该环境生成 env_id。
generation = (e->env_id + (1 << ENVGENSHIFT)) & ~(NENV - 1);
if (generation <= 0) // Don't create a negative env_id.
generation = 1 << ENVGENSHIFT;
e->env_id = generation | (e - envs);
// 设置基本状态变量。
e->env_parent_id = parent_id;
e->env_type = ENV_TYPE_USER;
e->env_status = ENV_RUNNABLE;
e->env_runs = 0;
// 清除所有已保存的寄存器状态,
// 以防止该 Env 结构中先前环境的寄存器值 “泄漏 ”到我们的新环境中。
memset(&e->env_tf, 0, sizeof(e->env_tf));
// 为段寄存器设置适当的初始值。
// GD_UD 是 GDT 中的用户数据段选择器,
// GD_UT 是用户文本段选择器(参见 inc/memlayout.h)。
// 每个段寄存器的低 2 位包含请求者权限级别(RPL);3 表示用户模式。
// 当我们切换权限级别时,硬件会对 RPL 和存储在描述符中的
// 描述符权限级别(DPL)进行各种检查。
e->env_tf.tf_ds = GD_UD | 3;
e->env_tf.tf_es = GD_UD | 3;
e->env_tf.tf_ss = GD_UD | 3;
e->env_tf.tf_esp = USTACKTOP;
e->env_tf.tf_cs = GD_UT | 3;
// You will set e->env_tf.tf_eip later.
// commit the allocation
env_free_list = e->env_link;
*newenv_store = e;
cprintf("[%08x] new env %08x\n", curenv ? curenv->env_id : 0, e->env_id);
return 0;
}
region_alloc()
//
// 为环境 env 分配 len 字节的物理内存,并将其映射到环境地址空间中的虚拟地址 va。
// 不会以任何方式将映射页清零或初始化。
// 页面应可被用户和内核写入。
// 如果任何分配尝试失败,就会panic。
//
static void
region_alloc(struct Env *e, void *va, size_t len)
{
// 实验 3:此处为您的代码。
// (但仅限于 load_icode 需要时)。
// 提示:如果调用者可以传递非页面对齐的'va'和'len'值,则使用 region_alloc 会更容易。
// 应该将 va 向下舍入,将 (va + len) 向上舍入。
// (注意拐角情况!)。
void *begin = ROUNDDOWN(va, PGSIZE), *end = ROUNDUP(va+len, PGSIZE);
while(begin < end){
struct PageInfo *pp = page_alloc(ALLOC_ZERO);
if(!pp){
panic("region_alloc failed\n");
}
page_insert(e->env_pgdir, pp, begin, PTE_P | PTE_W | PTE_U);
begin += PGSIZE;
}
}
load_icode
细节看注释,需要强调的一点是:
在加载各个段时需要切换到这个进程的页表目前进程的页表内容和 kern_pgdir 是一样的(UVPT除外)
因此,使用进程的页表一样能访问到链接的二进制文件(这里的 elfhdr)
为什么要切换呢?每个进程都有自己的页表,将物理内存中的代码数据映射到自己独立的地址空间
//
// 为用户进程设置初始程序二进制文件、堆栈和处理器标志。
// 该函数只在内核初始化期间,即运行第一个用户模式环境之前调用。
//
// 该函数将 ELF 二进制映像中的所有可加载段加载到环境的用户内存中,从 ELF 程序头中指示的相应虚拟地址开始。
// 同时,它将程序头中标记为映射但实际上不存在于 ELF 文件中的任何部分(即程序的 bss 部分)清零。
// 除了 Boot Loader 还需要从磁盘读取代码外,所有这些都与 Boot Loader 的工作非常相似。 看看 boot/main.c 就会明白。
//
// 最后,这个函数为程序的初始堆栈映射了一个页面。
//
// load_icode 在遇到问题时会panic
// - load_icode 怎么会失败? 给定的输入可能有什么问题?
static void
load_icode(struct Env *e, uint8_t *binary)
{
// 提示:
// 按照 ELF 程序段头指定的地址将每个程序段加载到虚拟内存中。
// 只应加载 ph->p_type == ELF_PROG_LOAD 的程序段。
// 每个程序段的虚拟地址可以在 ph->p_va 中找到,其在内存中的大小可以在 ph->p_memsz 中找到。
// ELF 二进制文件中从 “binary + ph->p_offset ”开始的 ph->p_filesz 字节应复制到虚拟地址 ph->p_va。 剩余的内存字节应清零。
// (ELF 头应该是 ph->p_filesz <= ph->p_memsz。)
// 使用前一个lab中的函数分配和映射页面。
//
// 目前所有页面保护位都应为用户读/写。
// ELF 程序段不一定是页面对齐的,但在本函数中可以假设没有两个程序段会接触同一个虚拟页面。
//
// 你可能会发现 region_alloc 这样的函数很有用。
//
// 如果能直接将数据移动到存储在 ELF 二进制文件中的虚拟地址,加载段就会简单得多。
// 那么在执行此函数时,哪个页面目录应该有效呢?
//
// 你还必须对程序的入口点做一些处理,以确保环境在那里开始执行。
// 参见下面的 env_run() 和 env_pop_tf())。
// 实验 3:你的代码在这里。
struct Elf * elfhdr = (struct Elf *) binary;
struct Proghdr *ph = (struct Proghdr *) ((uint8_t *) elfhdr + elfhdr->e_phoff);
if (elfhdr->e_magic != ELF_MAGIC) {
panic("binary is not ELF format\n");
}
ph = (struct Proghdr *) ((uint8_t *) elfhdr + elfhdr->e_phoff);
int ph_num = elfhdr->e_phnum;
// 接下来需要切换到这个 进程的页表,目前进程的页表内容和 kern_pgdir 是一样的(UVPT除外)
// 因此,使用进程的页表一样能访问到链接的二进制文件(这里的 elfhdr)
// 为什么要切换呢?每个进程都有自己的页表,将物理内存中的代码数据映射到自己独立的地址空间
lcr3(PADDR(e->env_pgdir));
for(int i = 0; i < ph_num; i++){
if(ph[i].p_type == ELF_PROG_LOAD){
region_alloc(e, (void *)ph[i].p_va, ph[i].p_memsz);
memset((void*) ph[i].p_va, 0, ph[i].p_memsz);
memcpy((void*) ph[i].p_va, binary + ph[i].p_offset, ph[i].p_filesz);
}
}
lcr3(PADDR(kern_pgdir));
e->env_tf.tf_eip = elfhdr->e_entry;//在 env_alloc 中,唯独 eip 没有初始化
// 现在为程序的初始堆栈映射一个页面
// 虚拟地址 USTACKTOP - PGSIZE.
region_alloc(e, (void *)(USTACKTOP - PGSIZE), PGSIZE);
}
关于 Elf 结构体的 p_memsz 和 p_filesz:
如果一个段是可装载段PT_LOAD(Program Header Type-Loadable):表明本程序头指向一个可装载的段。段的内容会被从文件中拷贝到内存中。段在文件中的大小是 p_filesz,在内存中的大小是 p_memsz。如果 p_memsz 大于 p_filesz,在内存中多出的存储空间应填 0 补充,也就是说,段在内存中可以比在文件中占用空间更大;而相反,p_filesz 永远不应该比 p_memsz 大,因为这样的话,内存中就将无法完整地映射段的内容。
env_create()
// 使用 env_alloc 分配一个新环境,
// 使用 load_icode 将命名的精灵二进制文件载入其中,并设置其 env_type。
// 只有在运行第一个用户模式环境之前,内核初始化过程中才会调用该函数。
// 新环境的父 ID 被设置为 0。
void env_create(uint8_t *binary, enum EnvType type)
{
// LAB 3: Your code here.
struct Env * new_env;
envid_t parent_id = 0;
int r = env_alloc(&new_env, parent_id);
if(r< 0)
panic("env_create error: %e", r);
load_icode(new_env, binary);
new_env->env_type = type;//顺带一体,env_alloc 默认已将type设为 ENV_TYPE_USER
}
然后看一看已经写好的 env_free()
env_free
释放 env e 及其使用的所有内存。
在看代码之前,我们想一想,一个已经 env_create 的 env 占用了哪些物理内存?
- 首先是e env 的 env_pgdir 自身占用的页面
- 然后是代码、数据、栈占用的页面
为了释放掉所有这些内存,首先应该处理后者(因为这个过程依赖前者)
void
env_free(struct Env *e)
{
pte_t *pt;
uint32_t pdeno, pteno;
physaddr_t pa;
// 如果释放当前环境,则在释放页面目录之前切换到 kern_pgdir,以防页面被重复使用。
if (e == curenv)
lcr3(PADDR(kern_pgdir));
// Note the environment's demise.
cprintf("[%08x] free env %08x\n", curenv ? curenv->env_id : 0, e->env_id);
// 清空地址空间用户部分的所有映射页
static_assert(UTOP % PTSIZE == 0);
for (pdeno = 0; pdeno < PDX(UTOP); pdeno++) {
// only look at mapped page tables
if (!(e->env_pgdir[pdeno] & PTE_P))
continue;
// 查找页表的 pa 和 va
pa = PTE_ADDR(e->env_pgdir[pdeno]);
pt = (pte_t*) KADDR(pa);
// unmap all PTEs in this page table
for (pteno = 0; pteno <= PTX(~0); pteno++) {
if (pt[pteno] & PTE_P)
page_remove(e->env_pgdir, PGADDR(pdeno, pteno, 0));
}
// free the page table itself
// 一般来说,我们使用 page_remove,但是这里是对页表占用的内存页进行释放
// 因此不能使用第一参数需要 pgdir 的 page_remove,需要手动处理。
// 这里是 env_setup_vm 中的逆过程,env_setup_vm 由于需要构建页表,
// 也需要手动调用 page_alloc,并处理计数
e->env_pgdir[pdeno] = 0;
page_decref(pa2page(pa));
}
// 释放页目录
pa = PADDR(e->env_pgdir);
e->env_pgdir = 0;
page_decref(pa2page(pa));
// return the environment to the free list
e->env_status = ENV_FREE;
e->env_link = env_free_list;
env_free_list = e;
}
需要注意一点,在执行 env_free 代码时,应该使用kern_pgdir,
但是 kern_pgdir 中没有 env e 的映射,所以需要先用 env e 的 env_pgdir 来获取物理地址,
然后利用 KADDR 宏从地址空间顶部的 物理内存映射区访问。
回忆一下lab2中,我们在mem_init里写过:
//////////////////////////////////////////////////////////////////////
// 将所有物理内存映射到 KERNBASE。
// 也就是说,VA 范围 [KERNBASE, 2^32) 应该映射到 PA 范围 [0, 2^32 - KERNBASE)
// 我们可能没有 2^32 - KERNBASE 字节的物理内存,但我们还是设置了映射。
// 权限:内核 RW,用户 NONE
// Your code goes here:
boot_map_region(kern_pgdir, KERNBASE, 0xffffffff - KERNBASE, 0, PTE_W);
注意,虽然每个进程都有顶部的 物理内存映射区 的页表,但是他们没有权限读写。(这么方便的功能当然只该有内核有权限,这也是执行env_free时,使用kern_pgdir的原因之一)
除此之外,我们需要注意 env_free 中需要手动调用 page_decref。lab2 和 lab3 代码中更多的是调用封装好的 page_insert(不用处理 计数递增)和 page_remove (不用处理 计数递减)。但是一旦涉及到对页表本身占用的物理页做增删处理时,就需要手动调用 page_alloc 或 page_decref 处理计数。
(比如 pgdir_walk(页表二级遍历时,可能需要访问尚未分配的 pte_table)、env_create(用户进程创建页表)和这里的 env_free )
env_run
在看代码之前,我们先想一想,让一个进程 Env e 运行起来,大概需要做那些事呢?
首先,想到的就是恢复这个进程的寄存器,让EIP指向继续执行的代码,
在那之前还要恢复cr3寄存器,加载 Env e 的页表
除此之外,我们还要考虑,env_run 是什么时候调用的,也许此时有一个进程正在运行,curenv指向其他进程。所以要考虑修改 curenv 、以及 Env e 的 status、runs等变量。
// 从 curenv 到 env e 的上下文切换。
// 注意:如果这是第一次调用 env_run,则 curenv 为空。
// 此函数不返回
//
void
env_run(struct Env *e)
{
// 第 1 步: 如果这是一个上下文切换(一个新环境正在运行):
// 1.如果当前环境是 ENV_RUNNING,则将当前环境(如果有的话)设置回 ENV_RUNNABLE(想想它还能处于什么状态)、
// 2. 将 “curenv ”设置为新环境、
// 3. 将其状态设置为 ENV_RUNNING; // 4、
// 4. 更新 “env_runs ”计数器、
// 5.使用 lcr3() 切换到它的地址空间。
// 第 2 步:使用 env_pop_tf()恢复环境的 // 寄存器,并切换到用户模式。
// 寄存器,并进入环境中的用户模式。
// 提示:该函数从 e->env_tf 加载新环境的状态。 回过头来看看你上面写的代码,确保已经将 e->env_tf 的相关部分设置为合理的值。
// 实验 3:此处为您的代码。
if(curenv != NULL){ //如果这不是第一次调用 env_run ,即,这是一个上下文切换
if(curenv->env_status == ENV_RUNNING){
curenv->env_status = ENV_RUNNABLE;
}
}
curenv = e;
e->env_status = ENV_RUNNING;
lcr3(e->env_pgdir);
// 恢复寄存器,这里直接将覆盖了当前寄存器状态
// 可以想到,当原进程的寄存器状态,应该已经妥当保存好了
// 并且在进程切换时负责进行保存,毕竟这里没有处理。
env_pop_tf(&e->env_tf);
}
正如注释中说的,env_run 如果不是首次调用,说明这是一次进程切换。那么什么时候需要切换进程呢?
大概能想到,发生异常、进程调度等,如果是进程调度这种比较平和的方式,那么curenv 肯定是 ENV_RUNNING了,其他情况暂时等 lab4 学完才能了解到。
注意最后一句 env_pop_tf(&e->env_tf); 寄存器状态恢复,就意味着进程正式运行了,因为eip被改变了。
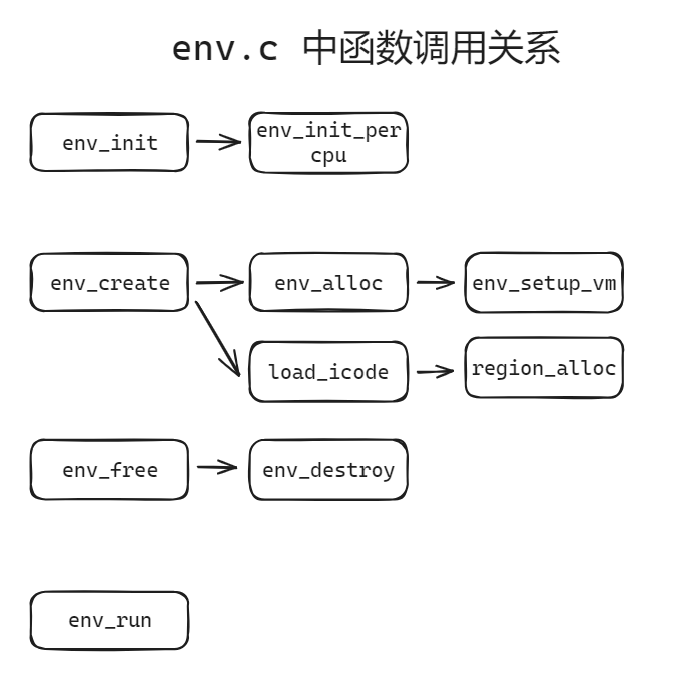
总结:env.c中的函数关系
此时, make qemu ,内核就会将 user/hello.c 编译出来的可执行文件,通过 env_create 创建出来,并通过 env_run 运行起来。在这之前,我们来看一眼这个程序:
// hello, world
#include <inc/lib.h>
void
umain(int argc, char **argv)
{
cprintf("hello, world\n");
cprintf("i am environment %08x\n", thisenv->env_id);
}
注意,用户程序的cprintf的声明虽然和我们刚刚编程时用的cprintf相同,都来自 inc/stdio.h,但是他们的实现不同:
用vscode 搜索可以发现,有两个定义
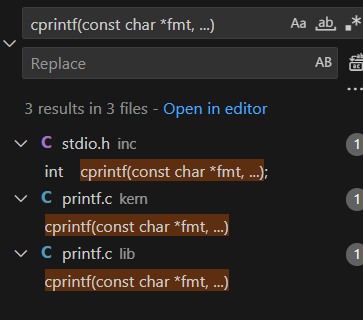
内核使用的是 kern/printf.c 而 user/hello.c 使用的却是 lib/printf.c,用户的 cprintf 会调用到 lib/syscall.c 中的 sys_cputs
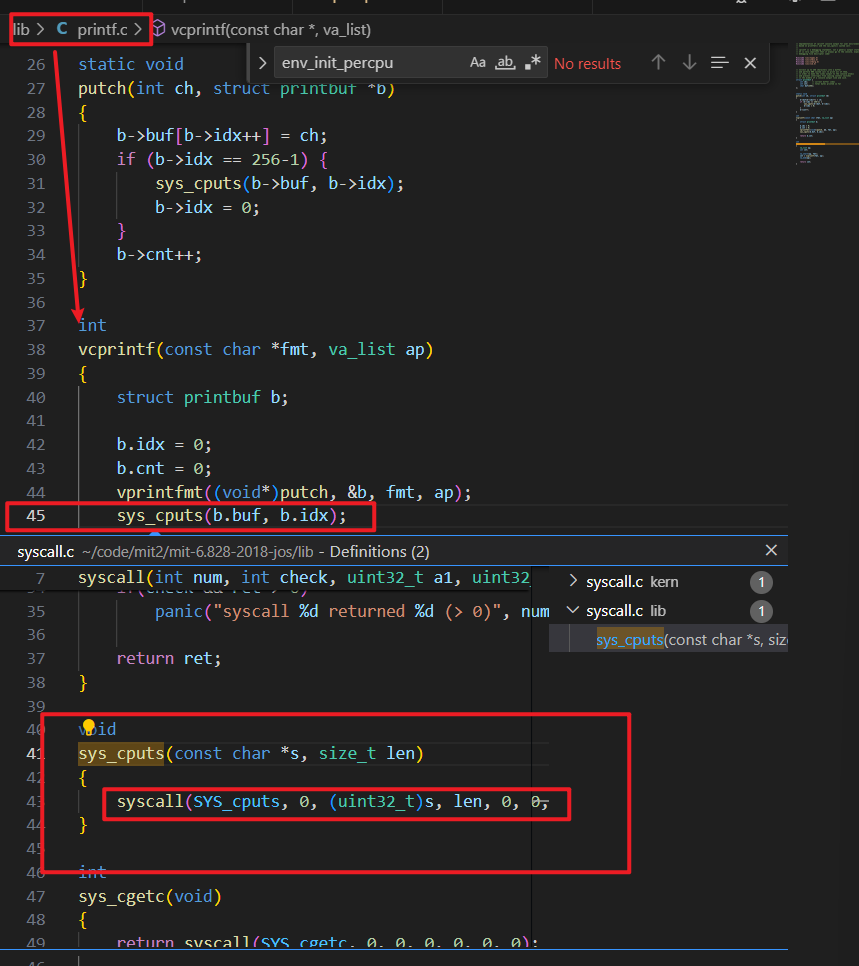
syscall 这个函数的定义如下:
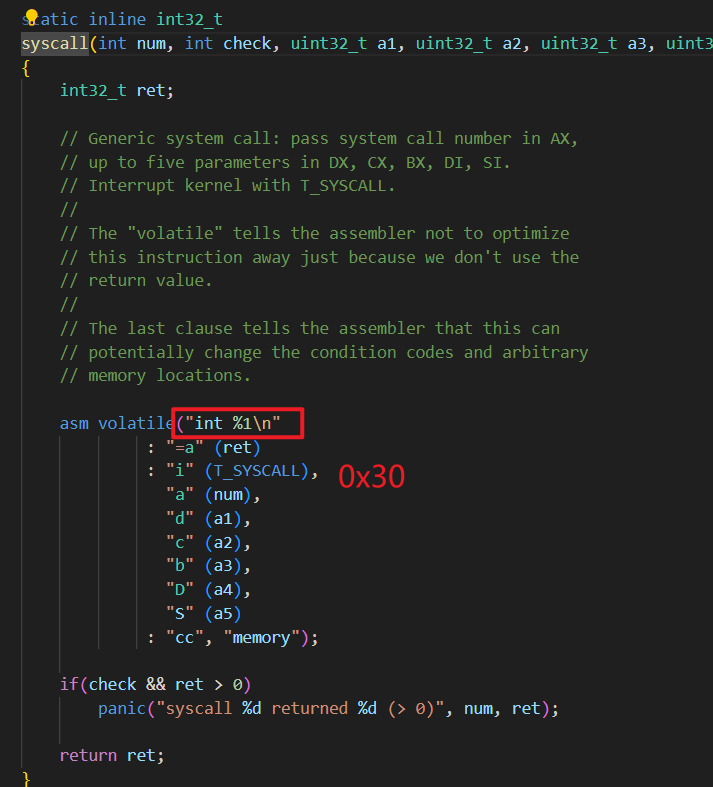
实际上就是使用了 int 0x30 系统调用,这是一个中断。这个中断只能在内核态调用,但是XXX所以 make qemu 会导致三重故障,即:
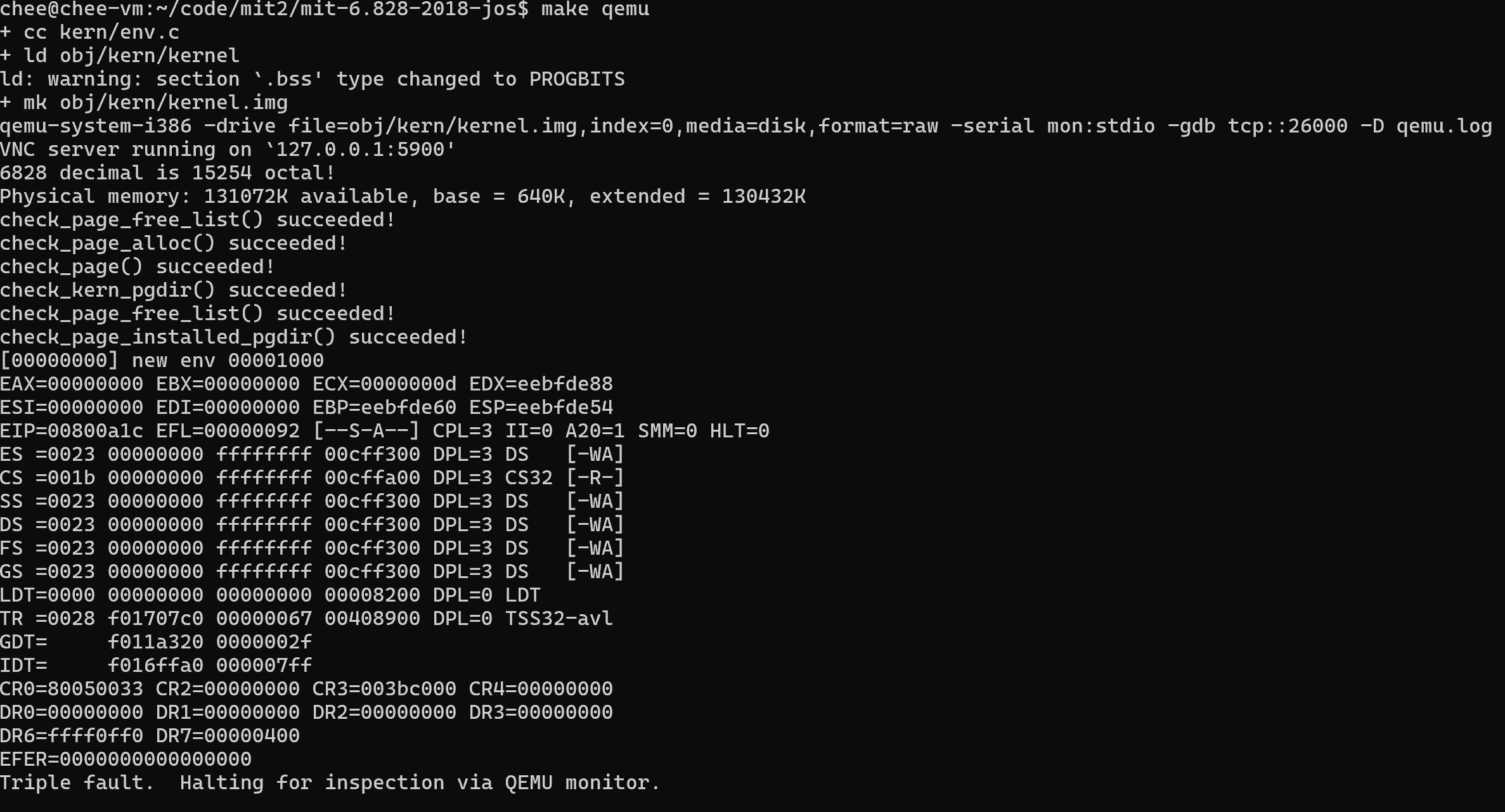
如果一切顺利,系统将进入用户空间并执行 hello 二进制文件,直到使用 int 指令进行系统调用。这时就会出现问题,因为 JOS 没有设置允许从用户空间过渡到内核的硬件。当中央处理器发现自己的设置不允许处理这个系统调用中断时,它就会产生一个一般保护异常,发现自己无法处理这个异常后,又会产生一个双重故障异常,发现自己也无法处理这个异常后,最后就会放弃,这就是所谓的 "三重故障" 。通常情况下,CPU 会重置,系统会重启。虽然这对传统应用程序很重要(请参阅本博文中的原因解释)
就像这个样子:
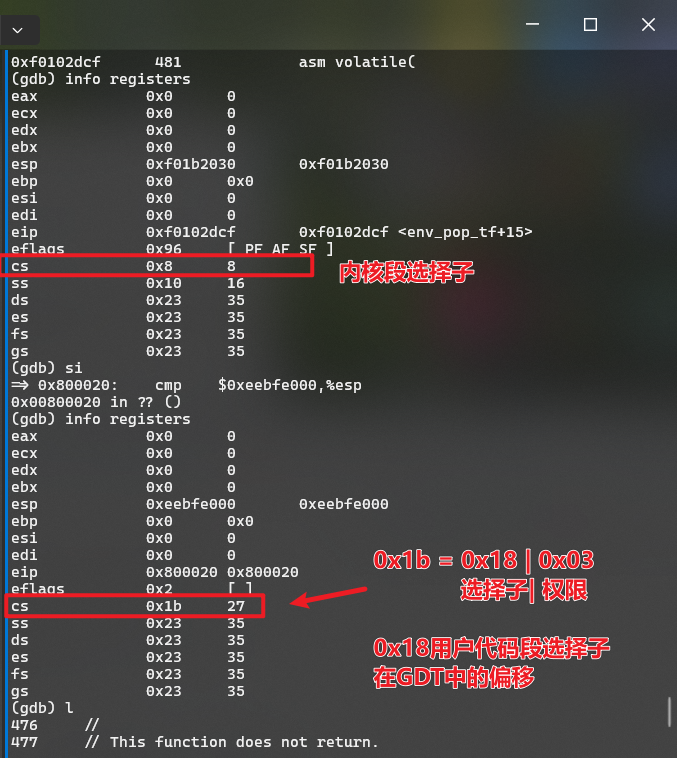
我们用 GDB 在 env_pop_tf() 函数设置断点,然后通过指令 si,单步调试,观察 iret 指令前后寄存器的变化。
为了能让用户进程有能力处理异常,学习如何处理中断和异常
处理中断和异常
在这之前,我们需要彻底摸头 x86中断和异常机制。练习3的任务就是学习80386的手册。
Exercise 3
练习 3. 如果还没有,请阅读《80386 程序员手册》第 9 章 "异常和中断"[Chapter 9, Exceptions and Interrupts](https://pdos.csail.mit.edu/6.828/2018/readings/i386/c09.htm)(或《IA-32 开发人员手册》第 5 章 [IA-32 Developer's Manual](https://pdos.csail.mit.edu/6.828/2018/readings/ia32/IA32-3A.pdf))。
观察下TSS

建立中断描述符表
JOS 在 trapentry.S 中,为每个异常或中断设置处理程序,
在 trap_init() 中用这些处理程序的地址建立 IDT。
那这些处理程序具体要做什么呢?手册提示我们:
- 每个处理程序都应在堆栈上建立一个
struct Trapframe(参见inc/trap.h)
2.将Trapframe的地址作为参数调用trap()(在trap.c中)。
先来看看 trapentry.S
trapentry.S
/* TRAPHANDLER 定义了一个全局可见的陷阱处理函数。
* 它将一个陷阱编号推入堆栈,然后跳转到 _alltraps。
* 使用 TRAPHANDLER 来处理 CPU 自动推送错误代码的陷阱。
*
* 你不应该在 C 语言中调用 TRAPHANDLER 函数,但你可能需要在 C 语言中声明一个函数(例如,在 IDT 设置过程中获取函数指针)。 您可以用以下方式声明函数
* void NAME();
* 其中 NAME 是传递给 TRAPHANDLER 的参数。
*/
#define TRAPHANDLER(name, num) \
.globl name; /* define global symbol for 'name' */ \
.type name, @function; /* symbol type is function */ \
.align 2; /* align function definition */ \
name: /* function starts here */ \
pushl $(num); \
jmp _alltraps
/* 对于 CPU 不推送错误代码的陷阱,使用 TRAPHANDLER_NOEC。
* 它会推送一个 0 来代替错误代码,因此陷阱帧在这两种情况下的格式都是一样的。
* 格式。
*/
#define TRAPHANDLER_NOEC(name, num) \
.globl name; \
.type name, @function; \
.align 2; \
name: \
pushl $0; \
pushl $(num); \
jmp _alltraps
.text
/*
* Lab 3: Your code here for generating entry points for the different traps.
*/
// 按照手册提示,为 /inc/trap.h 中的每一个(lab3是0~31)异常创建处理程序
// 注意,有的异常会在堆栈上推入ErrorCode,有的则没有,需要参照 x86手册
TRAPHANDLER_NOEC(handler_0, T_DIVIDE)
TRAPHANDLER_NOEC(handler_1, T_DEBUG)
TRAPHANDLER_NOEC(handler_2, T_NMI)
TRAPHANDLER_NOEC(handler_3, T_BRKPT)
TRAPHANDLER_NOEC(handler_4, T_OFLOW)
TRAPHANDLER_NOEC(handler_5, T_BOUND)
TRAPHANDLER_NOEC(handler_6, T_ILLOP)
TRAPHANDLER_NOEC(handler_7, T_DEVICE)
TRAPHANDLER(handler_8, T_DBLFLT)
TRAPHANDLER(handler_10, T_TSS)
TRAPHANDLER(handler_11, T_SEGNP)
TRAPHANDLER(handler_12, T_STACK)
TRAPHANDLER(handler_13, T_GPFLT)
TRAPHANDLER(handler_14, T_PGFLT)
TRAPHANDLER_NOEC(handler_16, T_FPERR)
TRAPHANDLER(handler_17, T_ALIGN)
TRAPHANDLER_NOEC(handler_18, T_MCHK)
TRAPHANDLER_NOEC(handler_19, T_SIMDERR)
/*
* Lab 3: Your code here for _alltraps
*/
/*
按照手册的提示:
你的 `_alltraps` 应该
1. 推值,使堆栈看起来像结构 Trapframe
2. 将 `GD_KD` 加载到 `%ds` 和 `%es` 中
3. 推送 `%esp` 以传递一个指向 `Trapframe` 的指针作为 `trap()` 的参数
4. `call trap` ( `trap` 会返回吗?)
*/
_alltraps:
pushl %ds
pushl %es
pushal
pushl $GD_KD
popl %ds
pushl $GD_KD
popl %es
pushl %esp
call trap
trap_init()
void
trap_init(void)
{
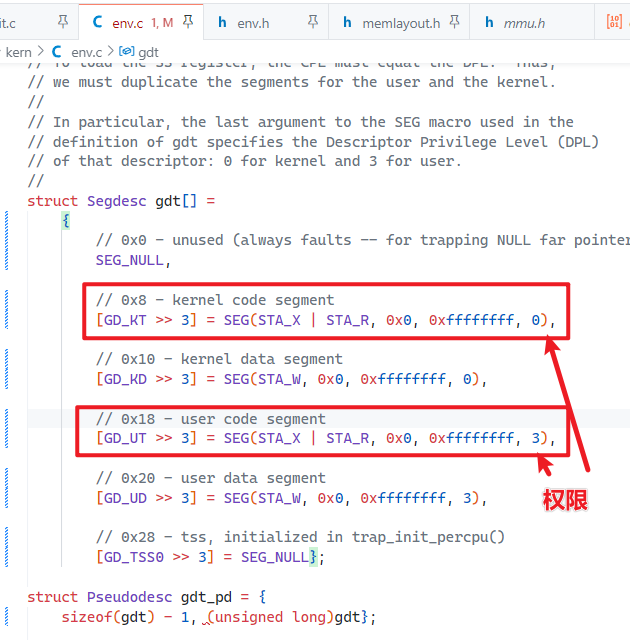
extern struct Segdesc gdt[];
// LAB 3: Your code here.
// 声明 异常处理函数
void handler_0();
void handler_1();
void handler_2();
void handler_3();
void handler_4();
void handler_5();
void handler_6();
void handler_7();
void handler_8();
void handler_10();
void handler_11();
void handler_12();
void handler_13();
void handler_14();
void handler_16();
void handler_17();
void handler_18();
void handler_19();
// 通过异常处理函数建立IDT
SETGATE(idt[0], 0, GD_KT, handler_0, 0);
SETGATE(idt[1], 0, GD_KT, handler_1, 0);
SETGATE(idt[2], 0, GD_KT, handler_2, 0);
SETGATE(idt[3], 0, GD_KT, handler_3, 3);
SETGATE(idt[4], 0, GD_KT, handler_4, 0);
SETGATE(idt[5], 0, GD_KT, handler_5, 0);
SETGATE(idt[6], 0, GD_KT, handler_6, 0);
SETGATE(idt[7], 0, GD_KT, handler_7, 0);
SETGATE(idt[8], 0, GD_KT, handler_8, 0);
SETGATE(idt[10], 0, GD_KT, handler_10, 0);
SETGATE(idt[11], 0, GD_KT, handler_11, 0);
SETGATE(idt[12], 0, GD_KT, handler_12, 0);
SETGATE(idt[13], 0, GD_KT, handler_13, 0);
SETGATE(idt[14], 0, GD_KT, handler_14, 0);
SETGATE(idt[16], 0, GD_KT, handler_16, 0);
SETGATE(idt[17], 0, GD_KT, handler_17, 0);
SETGATE(idt[18], 0, GD_KT, handler_18, 0);
SETGATE(idt[19], 0, GD_KT, handler_19, 0);
// Per-CPU setup
trap_init_percpu();
}
来看看这个最后调用的 trap_init_percpu
// 初始化并加载每个 CPU 的 TSS 和 IDT
void
trap_init_percpu(void)
{
// 设置 TSS,以便在向内核发送陷阱时获得正确的堆栈。
// 当我们向内核发送陷阱时。
ts.ts_esp0 = KSTACKTOP;
ts.ts_ss0 = GD_KD;
ts.ts_iomb = sizeof(struct Taskstate);
// 初始化 gdt 的 TSS 插槽。
gdt[GD_TSS0 >> 3] = SEG16(STS_T32A, (uint32_t) (&ts),
sizeof(struct Taskstate) - 1, 0);
gdt[GD_TSS0 >> 3].sd_s = 0;
// 加载 TSS 选择器(与其他分段选择器一样,最下面的三个比特是特殊的,我们将其置 0)
ltr(GD_TSS0);
// Load the IDT
lidt(&idt_pd);
}
这里的 ts 是用来存储 TSS 数据的结构体,位于 inc/mmu.h。
实际上,到了这里,Part A的练习已经完成,简单小结一下,异常发生后的处理过程
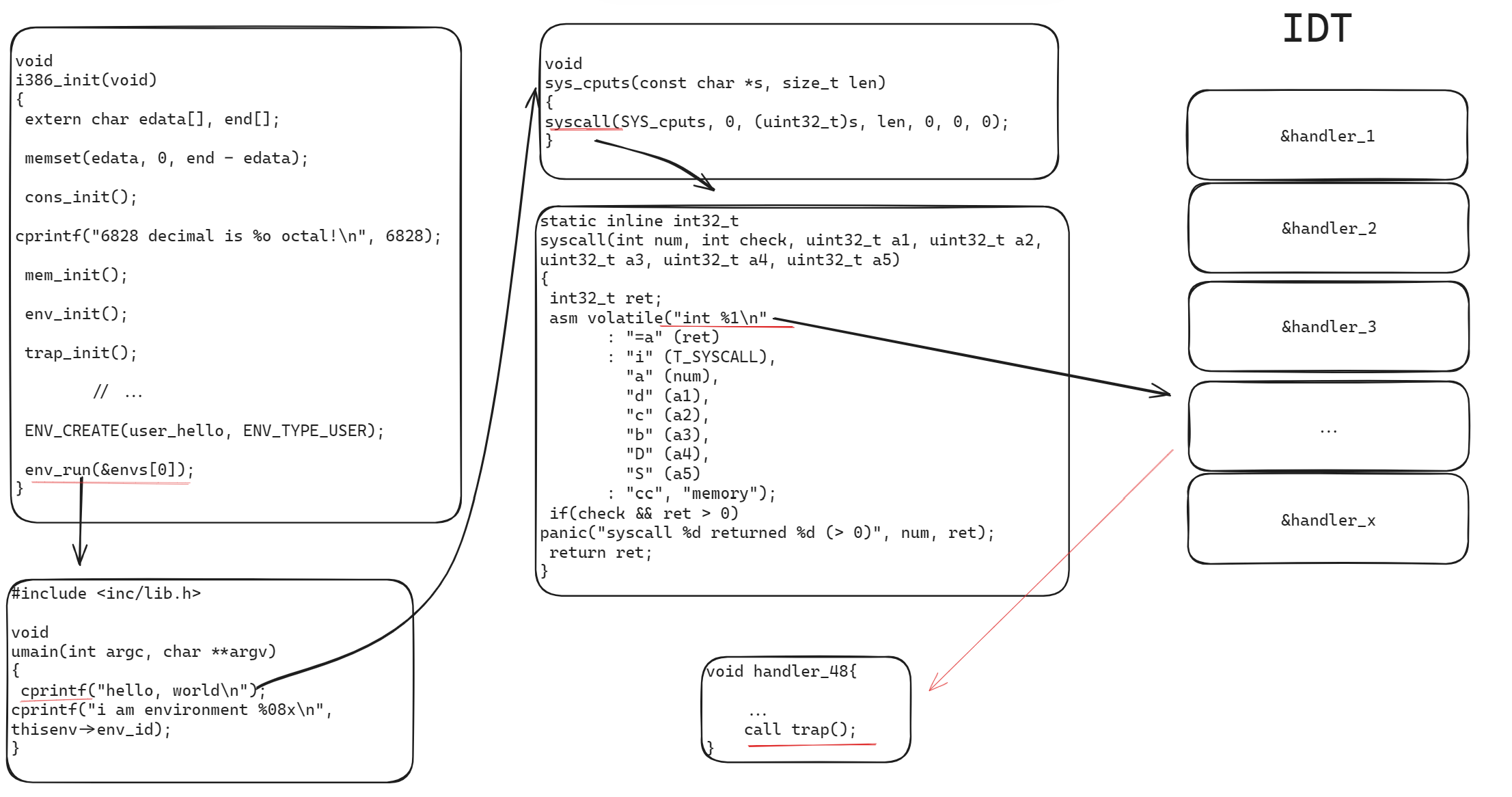
所以说,trap,带着 Trapframe 究竟做了什么呢,在进入 Part B 之前必要将这一切弄明白
JOS 的中断处理过程
先来看看 trap()做了什么
trap
void
trap(struct Trapframe *tf)
{
// 环境可能已经设置了 DF,
// 某些版本的 GCC 依赖于 DF 的明确性
asm volatile("cld" ::: "cc");
// 检查中断是否被禁用。
// 如果断言失败,切勿试图通过在中断路径中插入一个 “cli ”来修复。
assert(!(read_eflags() & FL_IF));
cprintf("Incoming TRAP frame at %p\n", tf);
if ((tf->tf_cs & 3) == 3) {
// 从用户模式捕获。
assert(curenv);
// 将陷阱帧(当前在堆栈上)复制到 “curenv->env_tf ”中,以便在陷阱点重新开始运行环境。
curenv->env_tf = *tf;
// 从现在起,堆栈上的陷阱框架应被忽略。
tf = &curenv->env_tf;
}
// 记录 tf 是最后一个真正的陷阱帧,以便 print_trapframe 可以打印一些附加信息。
last_tf = tf;
// 根据陷阱类型进行调度
trap_dispatch(tf);
// 返回当前运行环境。
assert(curenv && curenv->env_status == ENV_RUNNING);
env_run(curenv);
}
可以看到,trap 的主要工作就是调用 trap_dispatch 处理tf,然后调用 env_run 将控制交换给用户进程。trapdispatch是个需要我们后期补全的函数。
标签:mit6.828,GD,handler,void,lab3,Part,env,pgdir,tf From: https://www.cnblogs.com/toso/p/17810689.html