一、 架构设计与仿真
1 架构设计
因为我参加了第六期一生一芯,因此使用自己的设计。
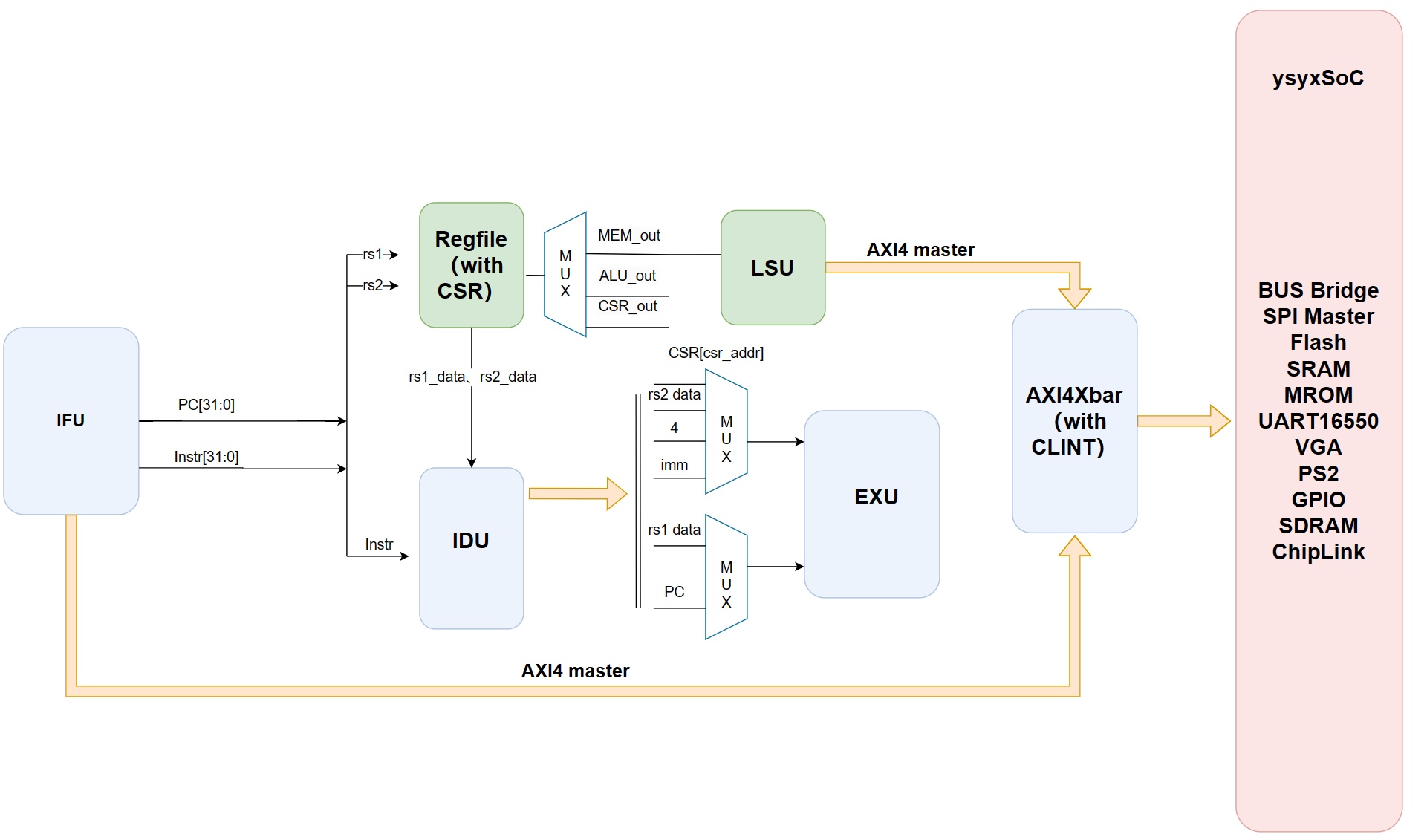
芯片架构图如下,采用RISCV32IE指令集,并包括ZiCSR指令拓展。由于一生一芯的宗旨是先完成后完美,而我正在进行SoC计算机系统的搭建,通过AXI4总线Xbar接入SoC部分。因此CPU的微架构比较简单,还未引入流水线和Cache。
2 仿真与演示
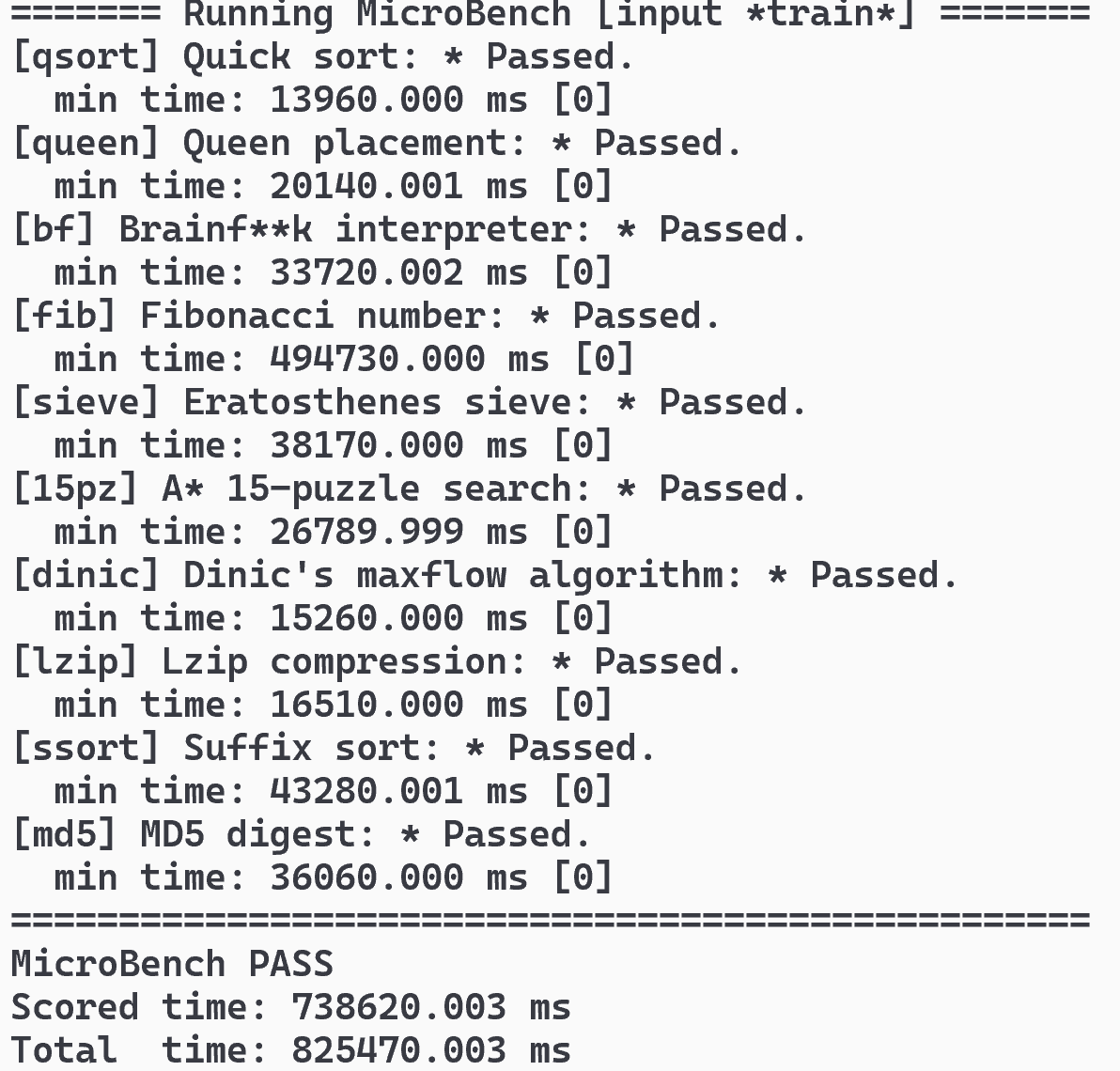
- 运行microbench
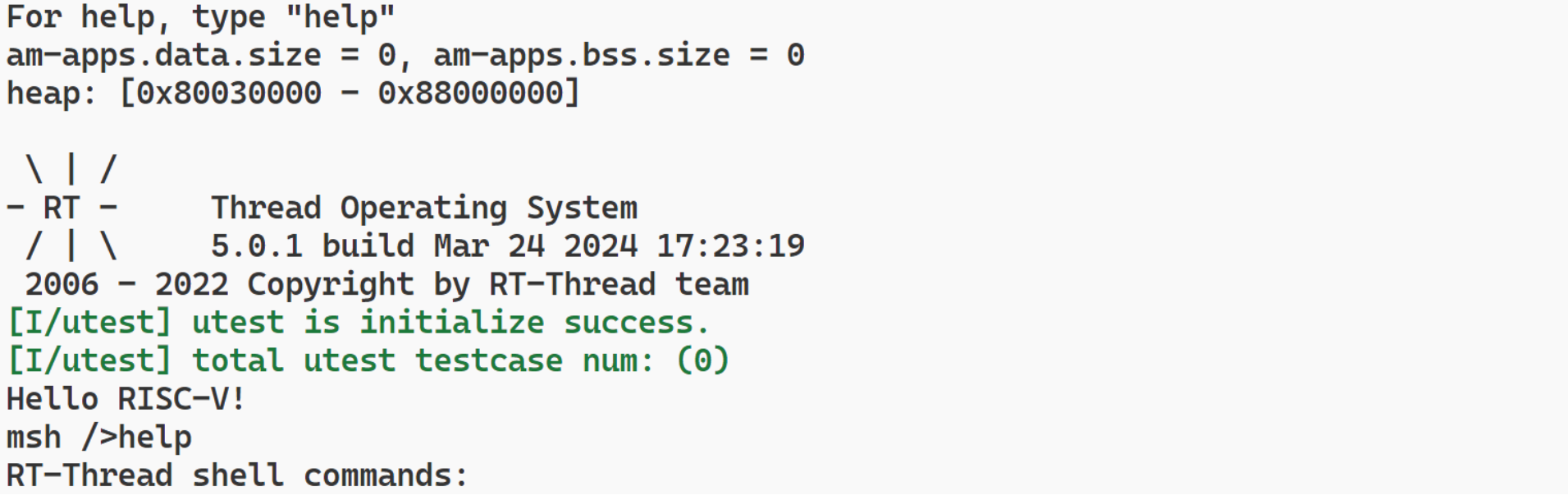
- 由于CPU包括ZiCSR指令拓展,引入了异常处理,因此可以移植RT-Thread,演示如下。
二、安装、使用和学习记录
0 安装
采用的系统是WSL2 Ubuntu20.04 ,与推荐一致,因此安装过程比较顺畅。安装后,简单跑了全流程测试。
进入到scripts目录下后执行如下命令
./run_flow.py -d gcd -s "synth,floorplan,tapcell,pdn,gplace,resize,dplace,cts,filler,groute,droute,layout" -f sky130 -t HS -c TYP -v V1 -l V1
得到最终版图,安装成功。
1 综合 Synthesis
1.1 概念
设计好的RTL通过验证后,下一步就是综合。综合的作用是将前端的 RTL 代码映射到给定的工艺库上,添加时序和物理等约束,将RTL代码进行逻辑优化,最后生成门级网表。
综合可分为三步:Translation + Logic Optimization + Gate Mapping

-
翻译(Translation):把RTL代码,在约束下转换成通用门级描述的电路,生成 GTECH 格式的网表。(与工艺库无关)。
-
逻辑优化(Logic Optimization):对通用门级描述的电路进行优化,例如调整路径,简化门的数量。
-
门级映射(Gate Mapping):工具使用fab厂的工艺库把电路映射出来,得到ddc文件,其包括了映射的门电路信息和网表,.sdf(standard delay format)延时信息文件,.v网表文件以及.sdc工作约束文件等。
1.2 输入文件
-
RTL代码,(包括 Verilog、VHDL)。
-
库文件(.lib 文件),包含所有标准单元和宏单元的信息:
- cell 的信息:功能、面积、功耗等。
- 连线负载模型:电阻、电容。
- 工作环境:工艺、电压、温度。
- 涉及约束规则:最大最小电容、最大最小转换时间、最大最小扇出。
-
约束文件(.sdc 文件),包含设计中所有的时序约束:PVT(Process、Voltage、Temperature)、
Input drives(驱动能力)、transition times(转换时间)、Capacitive output loads
(驱动电容负载)、内部寄生的 RC(线负载模型)
1.3 EDA使用记录
iFlow 使用的综合工具是 yosys。
由于ysyxSoC外设部分比较多,并且大部分代码都是给好的,只有一小部分如SPI XIP、uart等是自己写的,因此在不放入综合和后端中。只包括CPU和AXI4Xbar部分。
拷贝设计到rtl目录,并设置sdc约束,频率为200MHz。执行
./run_flow.py -d mycpu -s synth
综合面积为: 143728.128000
2 布局 Place
2.1 概念
布局是为了规划芯片的面积及形状,并将综合后输出的网表中所包含的instance 摆放到芯片上。在布局中,主要实现以下四个过程
- 确定芯片的尺寸,形状
- IO单元、填充和角落pad的位置
- 宏单元的放置和blockages的规划
- 电源地网络的分布
2.2 输入文件
管脚约束文件,根据设计师的设计自己编写,描述摆放pad/pin的位置。
2.3 EDA使用记录
iEDA把布局阶段分为六小步,分别为 floorplan、tapcell、PDN、gplace、resize、dplace。按顺序依次执行。
-
floorplan
在 floorplan 这一步中,主要对芯片进行面积和形状规划。通常情况下,chip-level的floorplan由Core Area和Pad Area组成。Core Area用于摆放宏单元和标准单元。
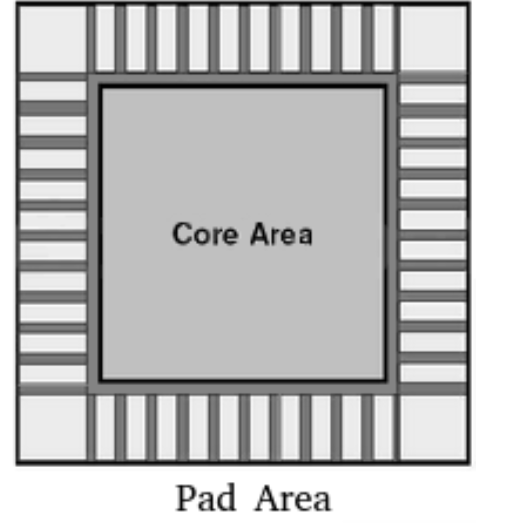
设置面积如下

-
tapcell
在 Core Area 内插入 tapcell,tapcell 的作用是为所有标准单元的 N 阱和衬底提供偏置电源。在 另外还需要在边界处、sram 及 ip 周围插入 endcap,目的是消除不对称性,平衡密度。
-
PDN
全称power plan。这一步主要是构建为整个芯片供电的电源网络,电源网络质量会直接影响整体芯片的性能。
-
gplace
全称global place。在完成电源网络的构建后,接下来需要将标准单元摆放到 core area 范围中,在gplace 阶段,需要配置的主要参数有两个,一个为线 RC 参数的抽取层,主要是为了在 gplace 阶段抽取线 RC 参数进行延时的评估,从而更好地优化标准单元的摆放位置;另一个为布局密度,这一参数是用于设置摆放标准单元时的密度。
-
resize
在 dplace 前,进行一部分标准单元的更换及插入,其中包括将逻辑 0 和逻辑 1 的驱动端加上 Tie cell(电压钳位单元) 和在需要 fix fanout(改善扇出) 的驱动端加上buffer。
-
dplace
全称detail place。dplace 的主要作用是对 gplace 阶段已经摆放的标准单元进行合法化,
消除标准单元之间的重叠,将标准单元对齐到 core area 范围内的 Row 上,从而确保电源网络能为标准单元供电。
综合完成后执行
./run_flow.py -d mycpu -s "floorplan,tapcell,pdn,gplace,resize,dplace" -p synth
如果初始size设计过小会失败,增大Core Area和Die Area即可。
3 时钟树综合 CTS
3.1 概念
CTS 的全称为 Clock Tree Synthesis,时钟树综合,这是后端物理设计的一个关键步骤,EDA 工具会根据时序约束文件,创建真实的时钟,并构建时钟树,目的是通过插入 buffer 或 inverter 的方法使得同一时钟域到各个寄存器时钟端的延迟尽可能保持一致,即时钟 skew 尽可能小。
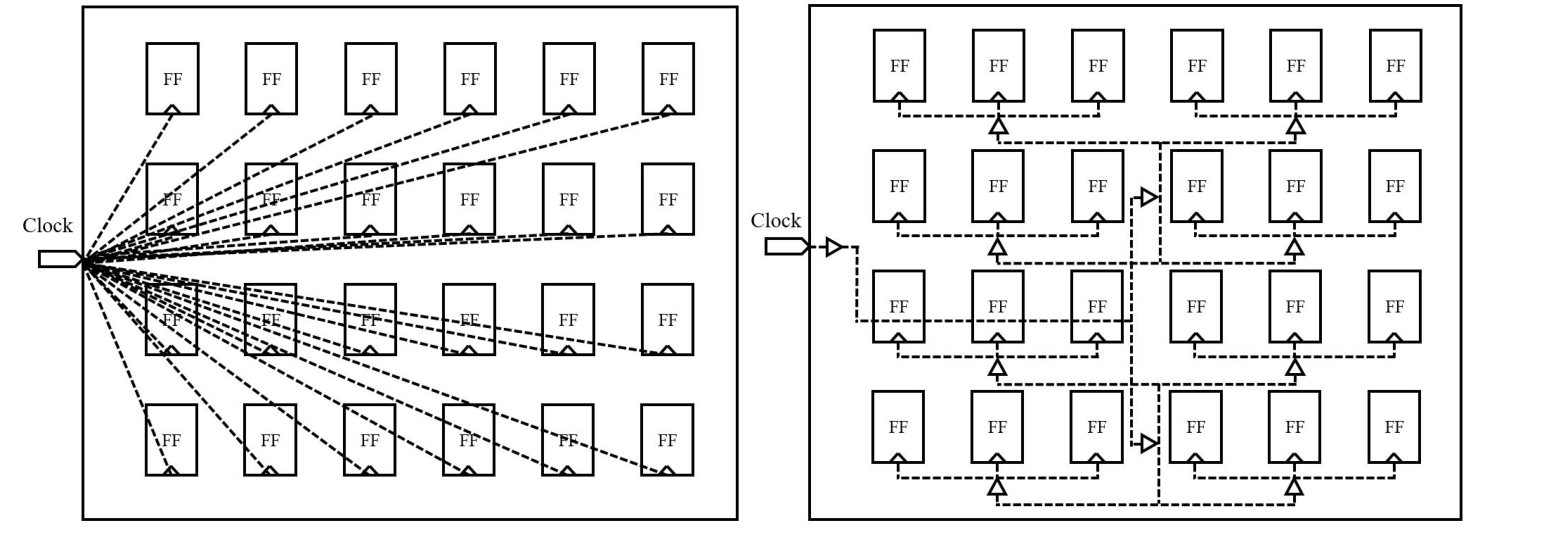
左图是CTS前,右图为CTS后
CTS构建过程:
-
生长时钟树
-
优化时钟树及时序
-
时钟树绕线
-
手动调节时钟树
-
查看时钟树报告,重复前面 4 个过程
3.2 EDA使用记录
CTS相关命令如下。在布局阶段resize后,已经更换为驱动能力更强的 buffer和 inverter,在CTS阶段再插入。插入后还需再进行一次dplace来保证标准单元位置摆放的合法化。
# Run CTS
set_wire_rc -layer $WIRE_RC_LAYER
repair_clock_inverters # repair cap slew skew
clock_tree_synthesis \
-buf_list $BUF_LIST \
-root_buf $ROOT_BUF \
-sink_clustering_enable \
-out_path $RESULT_PATH/
repair_clock_nets
set_placement_padding -global -left 3 -right 3
detailed_placement
check_placement
执行命令如下
./run_flow.py -d mycpu -s cts -p dplace
4 填充 filler
4.1 概念
在构建时钟树,并完成 timing 的修复之后,所有的标准单元已经固定,这时,我们需要在整个 core area 范围内填满 filler cell,用于填充标准单元之间的空隙,将整个扩散层连接起来,以满足DRC(Design Rule Check)要求,构成 power rail(电源轨)。
4.2 EDA使用记录
在 iFlow 中,filler cell插入默认是在 CTS 之后,布线之前,用户也可以根据需求,布线后再插入。
执行命令如下
./run_flow.py -d mycpu -s filler -p cts
5 布线 Route
5.1 概念
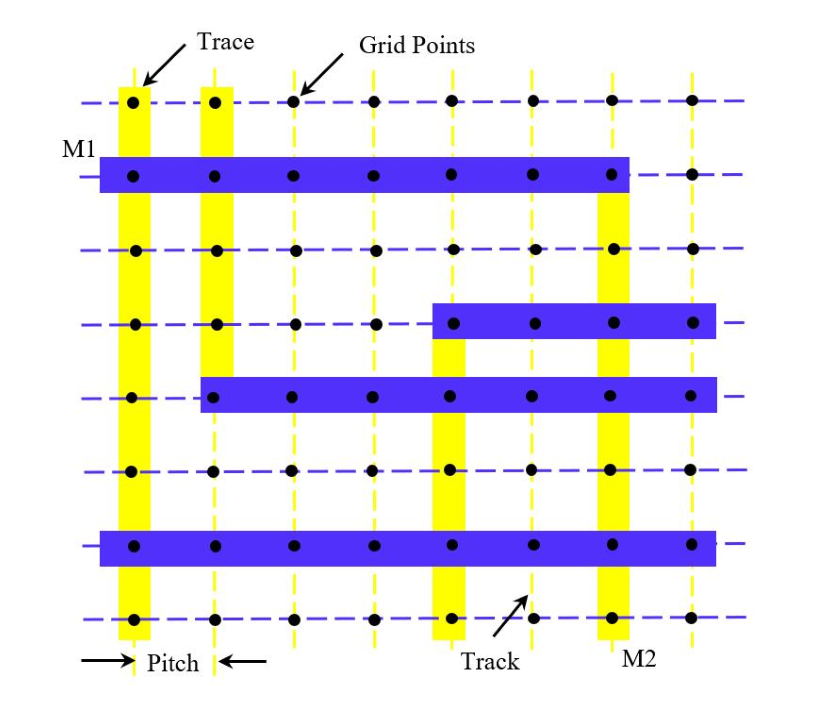
基于格点的布线图
- track:黄色和蓝色的虚线,没有宽度,基于格点的布线要求所有的金属走线
都要在 track 上。 - pitch:两条 track 之间的间距。
- trace:实际走在 track 上的金属走线,有宽度。
- grid point:两条 track 的交点。
标准单元的高宽都是 pitch 的整数倍,布局时标准单元的 pin 都放到了 grid point 上。
Route步骤:
- Global routing(全局布线)
规划布线路径,确定大体位置及走向,并不会做实际的连线。 - Track assignment(track 分配)
把每一根线分配到 track 上,并对连线进行实际的布线,布线时尽可能使用长直的金属连线,减少孔的数量,这个阶段不做 DRC(设计规则检查)。 - Detail Routing(详细布线)
使用全局布线和 track 分配过程中产生的路径进行布线和布孔。由于 track 分配时只考虑尽量走长线,所以会有很多 DRC 违规产生,详细布线时使用固定尺寸的 sbox 来修复违规,sbox 是整个版图平均划分的小格子,小格子内部违规会被修复,但小格子边界的 DRC 违规就修复不了,这就需要在接下来的步骤中完成修复。 - Search and repair(布线修补)
修复在详细布线中没有完全消除的 DRC 违例,在此步骤中通过逐渐加大 sbox 的尺寸来寻找和修复 DRC 违例。
注:时钟树布线具有最高的优先权。
5.2 EDA使用记录
在 iFlow 中,布线一共分为两步流程,分别是 groute 和 droute,groute 生成一个引导布线文件 guide,droute 读入 guide 完成实际的布线。
分别执行以下命令
./run_flow.py -d mycpu -s groute -p filler
./run_flow.py -d mycpu -s droute -p groute
结果如下

6 静态时序分析 Static Prime Analysis,STA
6.1 概念
静态时序分析是一种通过检查所有路径时序信息从而验证电路时序有效性的方法,其原理如下图所示:
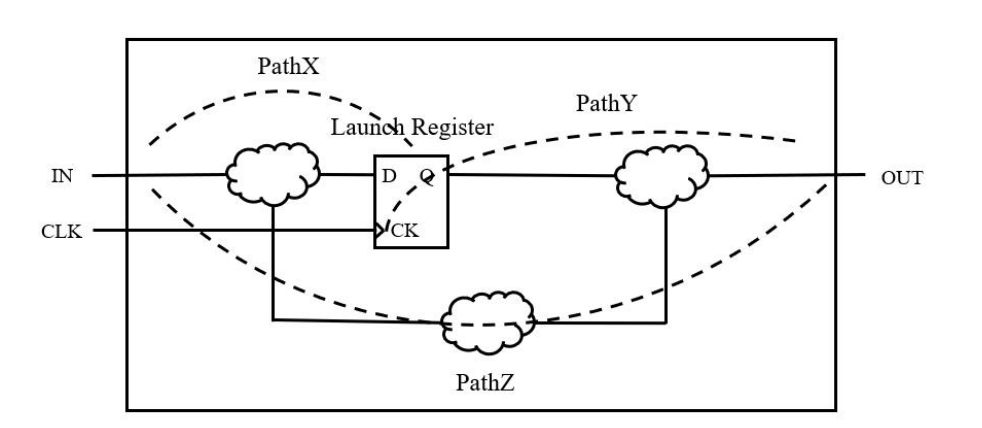
STA 原理
(1)把设计划分为若干路径。
(2)分别计算每个路径的延迟。
(3)检查每个路径的延迟是否满足要求(建立时间和保持时间)。
时序路径图如下,具体计算过程不再赘述,这里只给出修复时序的方法。
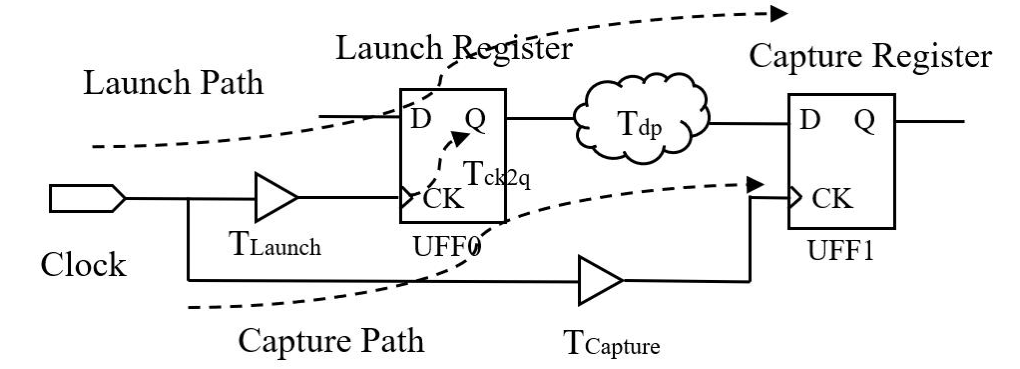
时序路径图
- 修复 Tsetup 时序违例方法:
(1)增加 Tclk:降频。
(2)降低 Tdp:优化组合逻辑、划分流水线、减少关键路径上的负载。
(3)降低 Tck2q:换更快的时序逻辑单元,如采用LVT(低阈值电压)的管子。 - 修复 Thold 时序违例方法:
(1)增大 Tdp:增加组合路径延迟,插 buffer。
(2)降低 Tskew:甚至采用负的 skew。
6.2 输入文件
(1)db 文件:和综合的 db 文件一致,并需要 ss、ff 等多 corner 下的库
(2)门级网表
(3)约束文件.db
(4)反标文件:sdf、spef
6.3 EDA使用记录
在iEDA中,建议在route阶段后再进行filler,最后STA。
./run_flow.py -d mycpu -s filler -p sta
7 版图 layout
7.1 概念
route 完成后输出的是 def 文件,而不是 gds 文件,需要得到用于 foundry 生产的 gds 文件还需要一个 merge 的流程。droute 得到的 def 文件是一个基于金属层层面的描述文件,其中的标准单元、IO cell 以及 marco 等等都是一个黑盒子,只描述了其形状,没有具体的 layer 层描述,merge 是将这些黑盒子的 gds 和 def 文件进行合并,从而得到最终的 gds 文件的过程。
7.2 输入文件
(1)droute 输出的 def
(2)标准单元、IO cell、marco 的 gds 文件
(3)工艺的 layer map 文件 klayout.lyt 和 klayout.lyp
7.3 EDA使用记录
使用开源的klayout工具查看版图
./run_flow.py -d mycpu -s layout -p droute
版图如下
建议
-
iFlow生成目录简化
执行一个步骤后,会在多个目录(log、report、result、work)产生结果文件。并且没有一键clean。如果把同一设计下的相关文件合并到同一个目录,我觉得会更加方便查看和管理。