PyTorch深度学习快速入门教程
一、基础知识
1.1 Python学习中的两大法宝
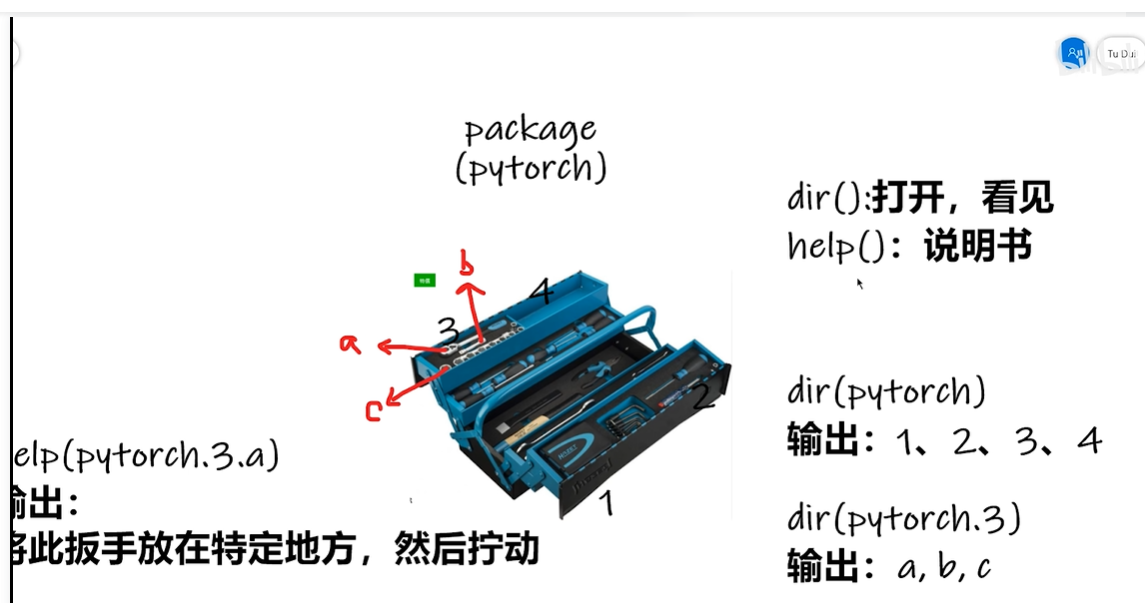
1.2 pycharm以及jupyter使用及对比
- 将环境写入Notebook的kernel中:
python -m ipykernel install --user --name 环境名称 --display-name "Python (环境名称)" - 打开Jupyter notebook,新建Python文件,这时候你就能看见你的创建的环境
快捷运行每一行:shift+回车
1.3 pytorch加载数据
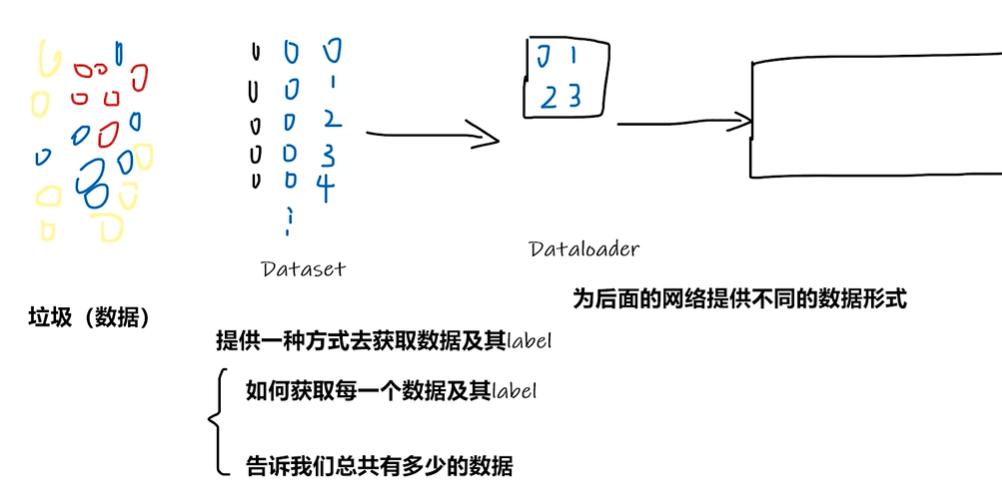
复制地址的时候可以选中图片ctrl shift +c ,Windows环境地址要用\

from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/hymenoptera_data/train"
ants_label_dir = "ants"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_label_dir = "bees"
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset = ants_dataset + bees_dataset
- 如一个文件夹内存放多个同类的图片:文件夹的名称就是其label
- 数据和label存放在不同的文件夹内
1.4 TensorBoard 的 使用
安装
pip install tensorboard
运行代码,会生成logs文件夹
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs') #把对应的事件文件存储到logs文件夹下
# writer.add_image()
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
add_scalar() 方法的使用
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):
添加一个标量数据到 Summary 当中,需要参数
- tag:Data指定方式,类似于图表的title
- scalar_value:需要保存的数值(y轴)
- global_step:训练到多少步(x轴)
启动
tensorboard --logdir=logs --port=6007
这里不指定端口port 默认是6006
add_image() 的使用
def add_image(self, tag, img_tensor, global_step=None):
- tag:对应图像的title
- img_tensor:图像的数据类型,只能是torch.Tensor、numpy.array、string/blobnaem
- global_step:训练步骤,int 类型

在Python控制台输出图片类型:
# 打开控制台,其位置就是项目文件夹所在的位置
# 故只需复制相对地址
image_path = "data/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(image_path)
print(type(img))
PIL.格式不符合要求。

利用opencv(numpy.array())读取图片,获得numpy型图片数据
import numpy as np
img_array=np.array(img)
print(type(img_array)) # numpy.ndarray
在Python控制台输出图片类型:

from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter('logs')
image_path = "data/train/ants_image/5650366_e22b7e1065.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("test2",img_array,1,dataformats="HWC") #(512,768,3) 即(H,W,C)(高度,宽度,通道)
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
在一个title下,通过滑块显示每一步的图形,可以直观地观察训练中给model提供了哪些数据,或者想对model进行测试时,可以看到每个阶段的输出结果
如果想要单独显示,重命名一下title即可,即 writer.add_image() 的第一个字符串类型的参数
1.4 Transforms 的 使用
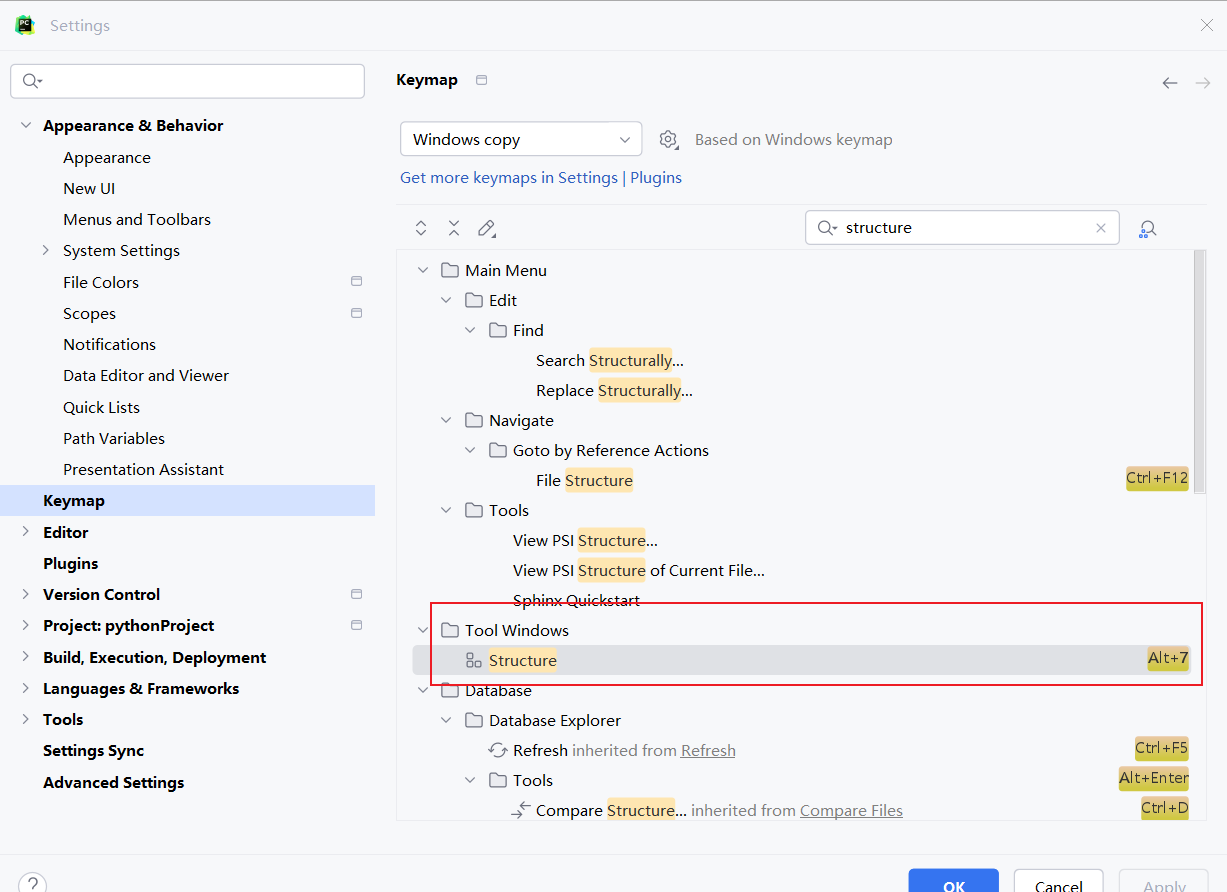
搜索结构快捷键:
File—> Settings—> Keymap—> 搜索 structure(快捷键 Alt+7)
一些类:
- Compose类:结合不同的transforms
- ToTensor类:把一个PIL的Image或者numpy数据类型的图片转换成 tensor 的数据类型
- ToPILImage类:把一个图片转换成PIL Image
- Normalize类:归一化,标准化,用来对数据预处理
- Resize类:尺寸变换
- CenterCrop类:中心裁剪
- Regularize类:正则化,防止模型过拟合的技术
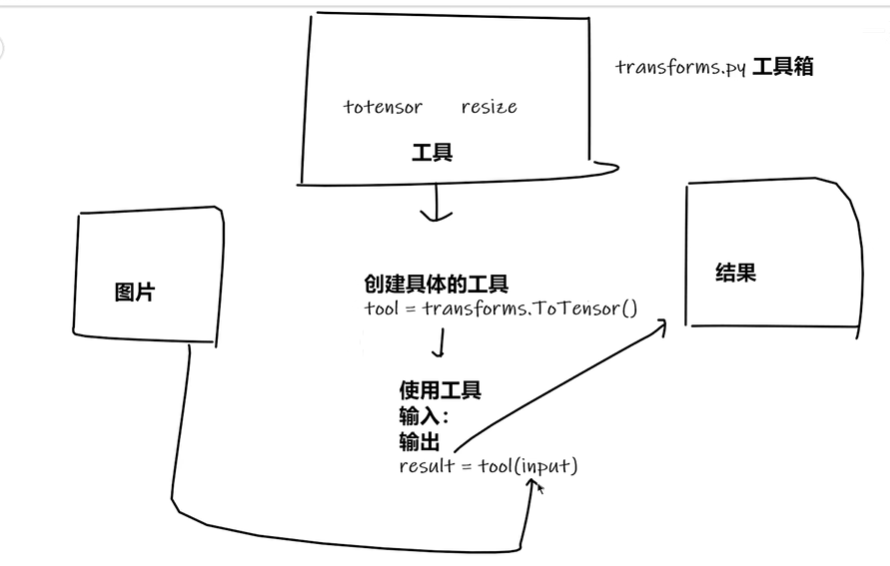
使用
- transforms.py 工具箱
- 工具箱里放着 totensor / resize等类 工具
拿一些特定格式的图片,经过工具(class文件)后,就会输出我们想要的图片变换的结果。
两个问题
python的用法 ——> tensor数据类型
通过 transforms.ToTensor去解决两个问题
- Transforms该如何使用
- Tensor数据类型与其他图片数据类型有什么区别?为什么需要Tensor数据类型
from PIL import Image
from torchvision import transforms
# 绝对路径 D:\PycharmProjects\pythonProject\pytorchlearn\data\train\ants_image\0013035.jpg
# 相对路径 data/train/ants_image/0013035.jpg
img_path="data/train/ants_image/0013035.jpg" #用相对路径,绝对路径里的\在Windows系统下会被当做转义符
# img_path_abs="C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg",双引号前加r表示转义
img = Image.open(img_path) #Image是Python中内置的图片的库
print(img) # PIL类型
问题一:transforms 该如何使用(python)
从transforms中选择一个class,对它进行创建,对创建的对象传入图片,即可返回出结果
ToTensor将一个 PIL Image 或 numpy.ndarray 转换为 tensor的数据类型
# 1、Transforms该如何使用
tensor_trans = transforms.ToTensor() #从工具箱transforms里取出ToTensor类,返回tensor_trans对象
tensor_img=tensor_trans(img) #创建出tensor_trans后,传入其需要的参数,即可返回结果
print(tensor_img)
问题二:为什么我们需要 Tensor 数据类型
在Python Console输入:
from PIL import Image
from torchvision import transforms
img_path= "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
Tensor 数据类型包装了反向神经网络所需要的一些理论基础的参数,如:_backward_hooks、_grad等(先转换成Tensor数据类型,再训练)
下载opencv
报错ERROR: Could not build wheels for opencv-python
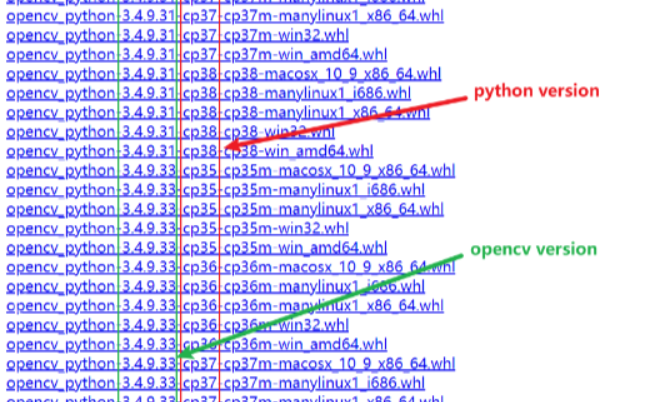
python版本要和opencv版本相对应,否则安装的时候会报错
上面查看python版本和opencv版本的对应关系,如图,红框内是python版本,绿框内是opencv版本
pip install opencv-python==4.5.4.60
(适合python3.6版本)

设置永久镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple

两种读取图片的方式
1.PIL Image
from PIL import Image
img_path = "xxx"
img = Image.open(img_path)
img.show()
2. numpy.ndarray(通过opencv)
import cv2
cv_img=cv2.imread(img_path)
上节课以 numpy.array 类型为例,这节课使用 torch.Tensor 类型:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python的用法 ——> tensor数据类型
# 通过 transforms.ToTensor去解决两个问题
# 1、Transforms该如何使用
# 2、Tensor数据类型与其他图片数据类型有什么区别?为什么需要Tensor数据类型
# 绝对路径 C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg
# 相对路径 data/train/ants_image/0013035.jpg
img_path="data/train/ants_image/0013035.jpg" #用相对路径,绝对路径里的\在Windows系统下会被当做转义符
# img_path_abs="C:\Users\11842\Desktop\Learn_torch\data\train\ants_image\0013035.jpg",双引号前加r表示转义
img = Image.open(img_path) #Image是Python中内置的图片的库
#print(img)
writer = SummaryWriter("logs")
# 1、Transforms该如何使用
tensor_trans = transforms.ToTensor() #从工具箱transforms里取出ToTensor类,返回tensor_trans对象
tensor_img = tensor_trans(img) #创建出tensor_trans后,传入其需要的参数,即可返回结果
#print(tensor_img)
writer.add_image("Tensor_img",tensor_img) # .add_image(tag, img_tensor, global_step)
# tag即名称
# img_tensor的类型为torch.Tensor/numpy.array/string/blobname
# global_step为int类型
writer.close()
1.5 常见的transforms
图片有不同的格式,打开方式也不同
| 图片格式 | 打开方式 |
|---|---|
| PIL | Image.open() ——Python自带的图片打开方式 |
| tensor | ToTensor() |
| narrays | cv.imread() ——Opencv |
1.5.1 Compose的使用
把不同的 transforms 结合在一起,后面接一个数组,里面是不同的transforms
Example:图片首先要经过中心裁剪,再转换成Tensor数据类型
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
Python中 call 的用法
class Person:
def __call__(self, name):
print("call"+name)
def hello(self,name):
print("hi"+name)
person = Person()
# 如果定义了call方法可以对象名(传入参数)来调用
person("zhangsan")
person.hello("lisi")
1.5.2 ToTensor的使用
把 PIL Image 或 numpy.ndarray 类型转换为 tensor 类型(TensorBoard 必须是 tensor 的数据类型)(运行前要先把之前的logs进行删除)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("images/pytorch.png")
print(img) # 可以看到类型是PIL
# ToTensor的使用
trans_totensor = transforms.ToTensor() # 将类型转换为tensor
img_tensor = trans_totensor(img) # img变为tensor类型后,就可以放入TensorBoard当中
writer.add_image("ToTensor", img_tensor)
writer.close()
1.5.3 ToPILImage 的使用
把 tensor 数据类型或 ndarray 类型转换成 PIL Image
1.5.4 Normalize 的使用
用平均值/标准差归一化 tensor 类型的 image(输入)
图片RGB三个信道,将每个信道中的输入进行归一化
output[channel] = (input[channel] - mean[channel]) / std[channel]
设置 mean 和 std 都为0.5,则 output= 2*input -1。如果 input 图片像素值为0~1范围内,那么结果就是 -1~1之间
加入step值:
第一步
#Normalize的使用
print(img_tensor[0][0][0]) # 第0层第0行第0列
trans_norm = transforms.Normalize([4,6,7],[3,2,6]) # mean,std,因为图片是RGB三信道,故传入三个数
img_norm = trans_norm(img_tensor) # 输入的类型要是tensor
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,1)#第一步
第二步
#Normalize的使用
print(img_tensor[0][0][0]) # 第0层第0行第0列
trans_norm = transforms.Normalize([2,6,7],[1,2,2]) # mean,std,因为图片是RGB三信道,故传入三个数
img_norm = trans_norm(img_tensor) # 输入的类型要是tensor
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,2)#第二步
1.5.5resize的使用
输入:PIL Image 将输入转变到给定尺寸
- 序列:(h,w)高度,宽度
- 一个整数:不改变高和宽的比例,只单纯改变最小边和最长边之间的大小关系。之前图里最小的边将会匹配这个数(等比缩放)
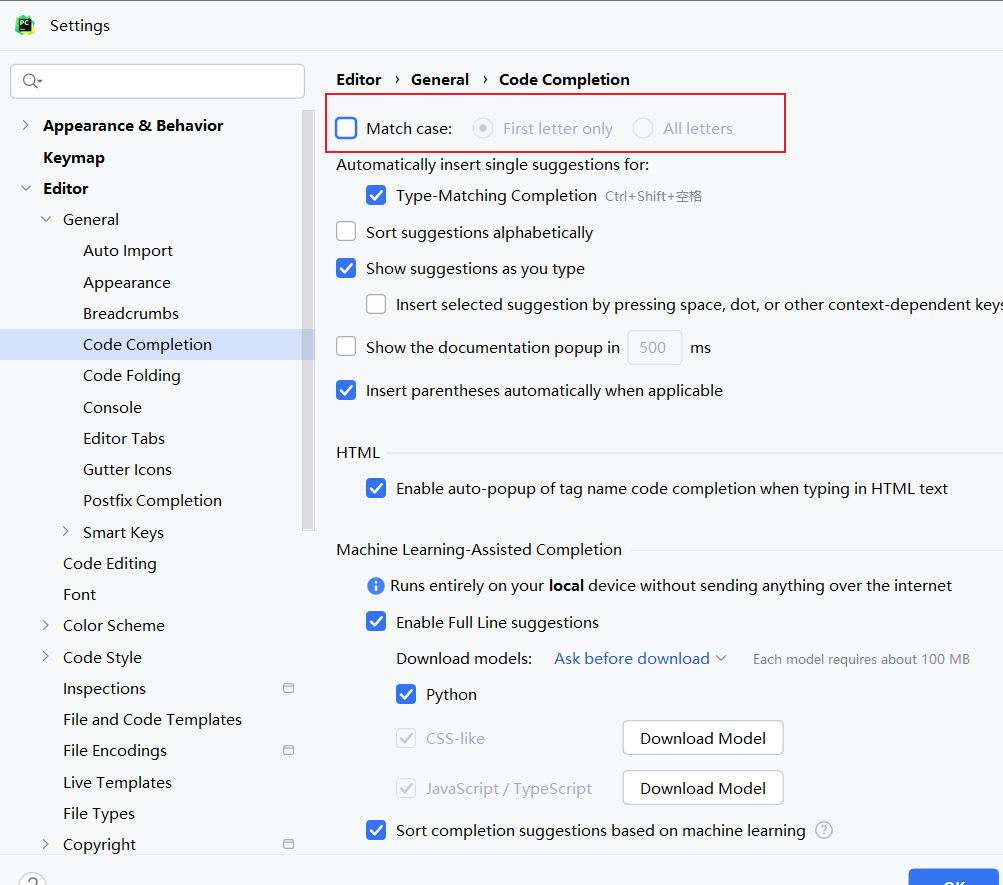
取消首字母匹配
一般情况下,你需要输入R,才能提示出Resize
我们想设置,即便你输入的是r,也能提示出Resize,也就是忽略了大小写进行匹配提示
File—> Settings—> 搜索case—> Editor-General-Code Completion-去掉Match case前的√—>Apply—>OK
#Resize的使用
print(img.size) # 输入是PIL.Image
trans_resize = transforms.Resize((512,512))
#img:PIL --> resize --> img_resize:PIL
img_resize = trans_resize(img) #输出还是PIL Image
#img_resize:PIL --> totensor --> img_resize:tensor(同名,覆盖)
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
Compose() 中的参数需要是一个列表,Python中列表的表示形式为[数据1,数据2,...]
在Compose中,数据需要是transforms类型,所以得到Compose([transforms参数1,transforms参数2,...])
#Compose的使用(将输出类型从PIL变为tensor类型,第二种方法)
trans_resize_2 = transforms.Resize(512) # 将图片短边缩放至512,长宽比保持不变
# PIL --> resize --> PIL --> totensor --> tensor
#compose()就是把两个参数功能整合,第一个参数是改变图像大小,第二个参数是转换类型,前者的输出类型与后者的输入类型必须匹配
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img) # 输入需要是PIL Image
writer.add_image("Resize",img_resize_2,1)
1.5.6 RandomCrop的使用
随机裁剪,输入PIL Image
参数size:
- sequence:(h,w) 高,宽
- int:裁剪一个该整数×该整数的图像
(1)以 int 为例:
#RandomCrop()的使用
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10): #裁剪10个
img_crop = trans_compose_2(img) # 输入需要是PIL Image
writer.add_image("RandomCrop",img_crop,i)
(2)以 sequence 为例:
#RandomCrop()的使用
trans_random = transforms.RandomCrop((200,500))
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10): #裁剪10个
img_crop = trans_compose_2(img)
writer.add_image("RandomCropHW",img_crop,i)
1.6 touchvision中的数据集使用
网站地址:https://pytorch.org/vision/0.9/
需要学习知识:
-
- 如何把数据集(多张图片)和 transforms 结合在一起。
-
- 标准数据集如何下载、查看、使用。
各个模块作用
(1)torchvision.datasets
如:COCO 目标检测、语义分割;MNIST 手写文字;CIFAR 物体识别
(2)torchvision.io
输入输出模块,不常用
(3)torchvision.models
提供一些比较常见的神经网络,有的已经预训练好,比较重要,后面会使用到,如分类模型、语义分割模型、目标检测、视频分类等
(4)torchvision.ops
torchvision提供的一些比较少见的特殊的操作,基本不常用
(5)torchvision.transforms
之前讲解过
(6)torchvision.utils
提供一些常用的小工具,如TensorBoard
本节主要讲解torchvision.datasets,以及它如何跟transforms联合使用
1.数据集如何下载
#如何使用torchvision提供的标准数据集
import torchvision
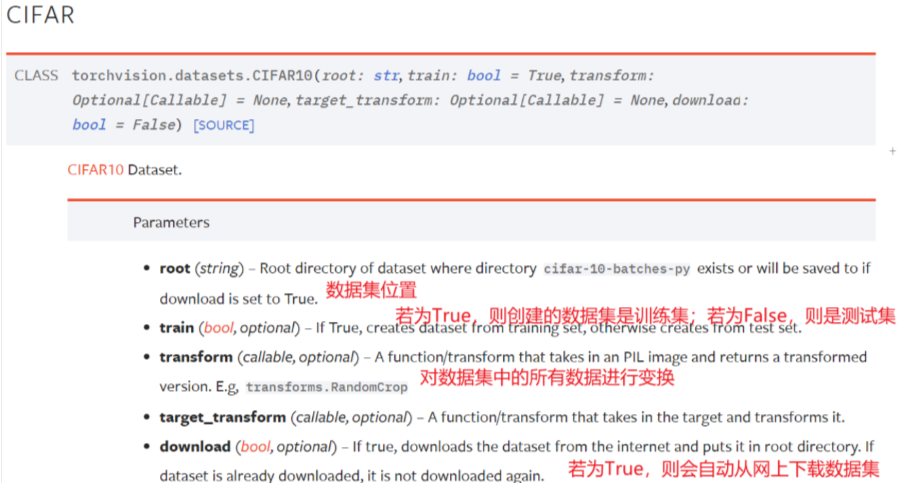
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去。用Ctrl加P查看需要参数。
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
数据集下载过慢时:
获得下载链接后,把下载链接放到迅雷中,会首先下载压缩文件tar.gz,之后会对该压缩文件进行解压,里面会有相应的数据集。
采用迅雷下载完毕后,在PyCharm里新建directory,名字也叫dataset,再将下载好的压缩包复制进去,download依然为True,运行后,会自动解压该数据
2.数据集如何查看与使用
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0]) # 查看测试集中的第一个数据,是一个元组:(img, target)
print(test_set.classes) # 列表
img,target = test_set[0]
print(img)
print(target) # 输出:3。输出为列表第几个类别。从0开始数,这里类别为cat列表第四个
print(test_set.classes[target]) # cat
img.show()
3.CIFAR10数据集 介绍
CIFAR10 数据集包含了6万张32×32像素的彩色图片,图片有10个类别,每个类别有6千张图像,其中有5万张图像为训练图片,1万张为测试图片。
如何把数据集(多张图片)和 transforms 结合在一起
CIFAR10数据集原始图片是PIL Image,如果要给pytorch使用,需要转为tensor数据类型(转成tensor后,就可以用tensorboard了)
transforms 更多地是用在 datasets 里 transform 的选项中
import torchvision
from torch.utils.tensorboard import SummaryWriter
#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
writer = SummaryWriter("logs")
#显示测试数据集中的前10张图片
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i) # img已经转成了tensor类型
writer.close()
1.7 DataLoader的使用
网址:https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader
参数介绍
参数如下(大部分有默认值,实际中只需要设置少量的参数即可):
- dataset:只有dataset没有默认值,只需要将之前自定义的dataset实例化,再放到dataloader中即可
- batch_size:每次抓牌抓几张
- shuffle:打乱与否,值为True的话两次打牌时牌的顺序是不一样。默认为False,但一般用True
- num_workers:加载数据时采用单个进程还是多个进程,多进程的话速度相对较快,默认为0(主进程加载)。Windows系统下该值>0会有问题(报错提示:BrokenPipeError)
- drop_last:100张牌每次取3张,最后会余下1张,这时剩下的这张牌是舍去还是不舍去。值为True代表舍去这张牌、不取出,False代表要取出该张牌

import torchvision
from torch.utils.data import DataLoader
#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor)
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
输出结果:
torch.Size([3, 32, 32]) #三通道,32×32大小
3 #类别为3
dataset
__getitem()__:return img,target
dataloader(batch_size=4):从dataset中取4个数据
-
img0,target0 = dataset[0]
-
img1,target1 = dataset[1]
-
img2,target2 = dataset[2]
-
img3,target3 = dataset[3]
把 img 0-3 进行打包,记为imgs;target 0-3 进行打包,记为targets;作为dataloader中的返回
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)
输出:
torch.Size([4, 3, 32, 32]) #4张图片,三通道,32×32
tensor([0, 4, 4, 8]) #4个target进行一个打包
数据是随机取的(断点debug一下,可以看到采样器sampler是随机采样的),所以两次的 target 0 并不一样
batch_size
# 用上节课torchvision提供的自定义的数据集
# CIFAR10原本是PIL Image,需要转换成tensor
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#batch_size=4,意味着每次从test_data中取4个数据进行打包
writer = SummaryWriter("dataloader")
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("test_data",imgs,step)
step=step+1
writer.close()
由于 drop_last 设置为 False,所以最后16张图片(没有凑齐64张)显示如下:

drop_last
若将 drop_last 设置为 True,最后16张图片(step 156)会被舍去,结果如图:

shuffle
一个 for data in test_loader 循环,就意味着打完一轮牌(抓完一轮数据),在下一轮再进行抓取时,第二次数据是否与第一次数据一样。值为True的话,会重新洗牌(一般都设置为True)
shuffle为False的话两轮取的图片是一样的
在外面再套一层 for epoch in range(2) 的循环
# shuffle为True
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("Epoch:{}".format(epoch),imgs,step)
step=step+1
二、神经网络
2.1 神经网络的基本骨架 nn.Module的使用
神经网络的主要工具都在 torch.nn里 https://pytorch.org/docs/1.8.1/nn.html

Containers
Containers 包含6个模块:
- Module
- Sequential
- ModuleList
- ModuleDict
- ParameterList
- ParameterDict
其中最常用的是 Module 模块(为所有神经网络提供基本骨架)
CLASS torch.nn.Module #搭建的 Model都必须继承该类
标签:PIL,tensor,img,Image,入门教程,PyTorch,transforms,深度,trans From: https://www.cnblogs.com/MyBlogForRecord/p/18187125pycharm 重写类的快捷键 ctrl + O