背景
前两天收到业务反馈有一个 topic 的分区消息堆积了:

根据之前的经验来看,要么是业务消费逻辑出现问题导致消费过慢,当然也有小概率是消息队列的 Bug(我们使用的是 pulsar)。
排查
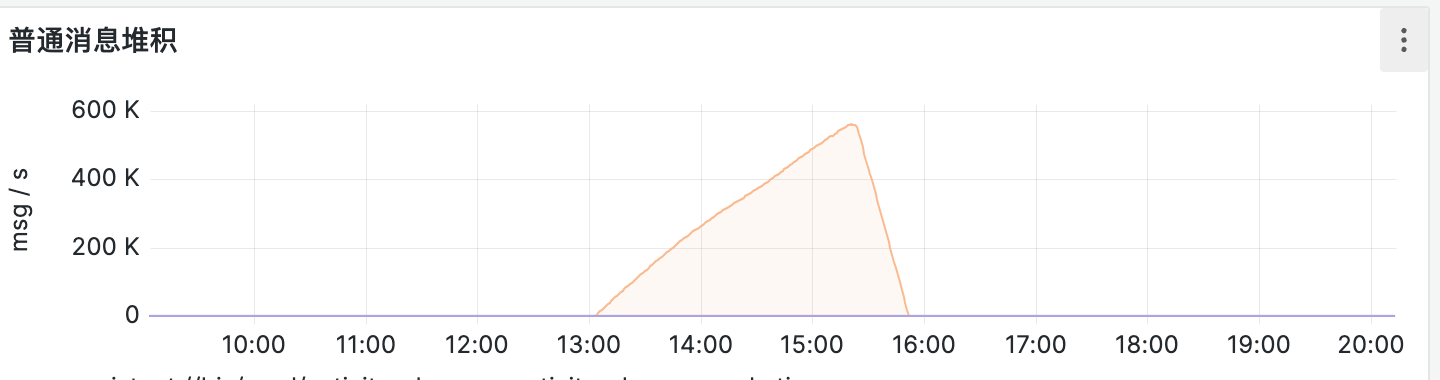
通过排查,发现确实是在一点多的时候消息堆积了(后面是修复之后堆积开始下降)。
于是我在刚才堆积处查看了一条堆积消息的列表:

获取到其中一条消息的 messageId.
这里本质上使用的是 pulsar-admin 的 API。
org.apache.pulsar.client.admin.Topics#peekMessages
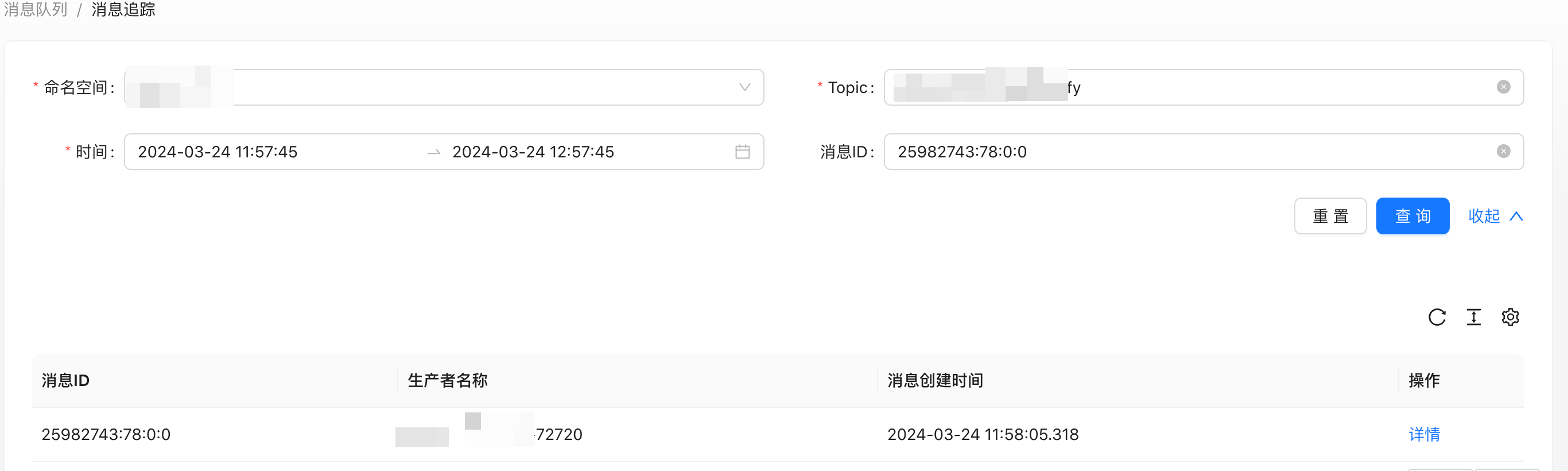
再通过这条消息的 id (为了演示,这里的 messageId 可能不一样)在我们的 pulsar 消息链路系统中找到了消息的发送链路:
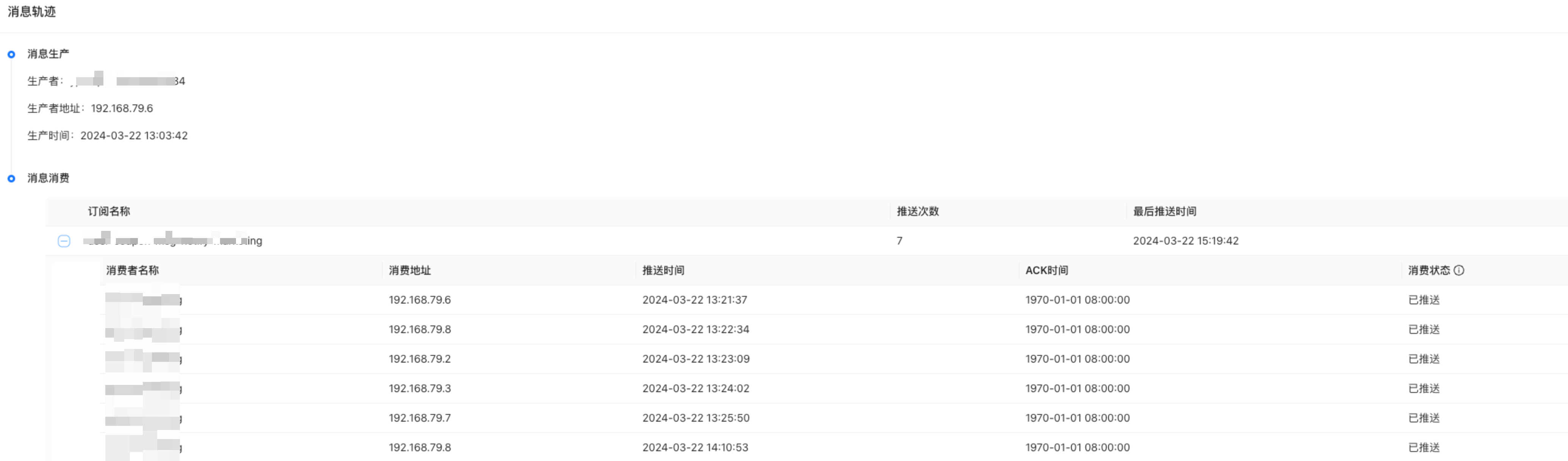
通过这个链路会发现消息一直在推送,但就是没有收到客户端的 ACK 响应。
相关的消息链路埋点可以参考这里:如何编写一个 Pulsar Broker Interceptor 插件
简单来说就是在以下几个 broker 提供的拦截器接口加上埋点数据即可:
- messageProduced
- messageDispatched
- messageAcked
既然知道了是客户端没有响应 ACK,那就得知道客户端此时在干什么。
首先排查了 JVM 内存、CPU 等监控情况,发现一切都挺正常的,这段时间没有明显的尖刺。
Arthas 排查
于是便准备使用 arthas 查看下线程的运行情况。
我们进入到对应 Pod 的容器,执行:
java -jar arthas-boot.jar
因为 JVM 内存都没有啥异常,所以先看看 thread 的运行堆栈,考虑到是 pulsar 消费线程卡住了,所以我们需要加上线程状态已经过滤下线程的名称:

thread --state WAITING | grep pulsar
此时就会列出当前 Java 进程中状态为 WATING 并且线程名称以 pulsar 开头的线程。
我在之前的文章 从 Pulsar Client 的原理到它的监控面板 中分析过客户端的原理。
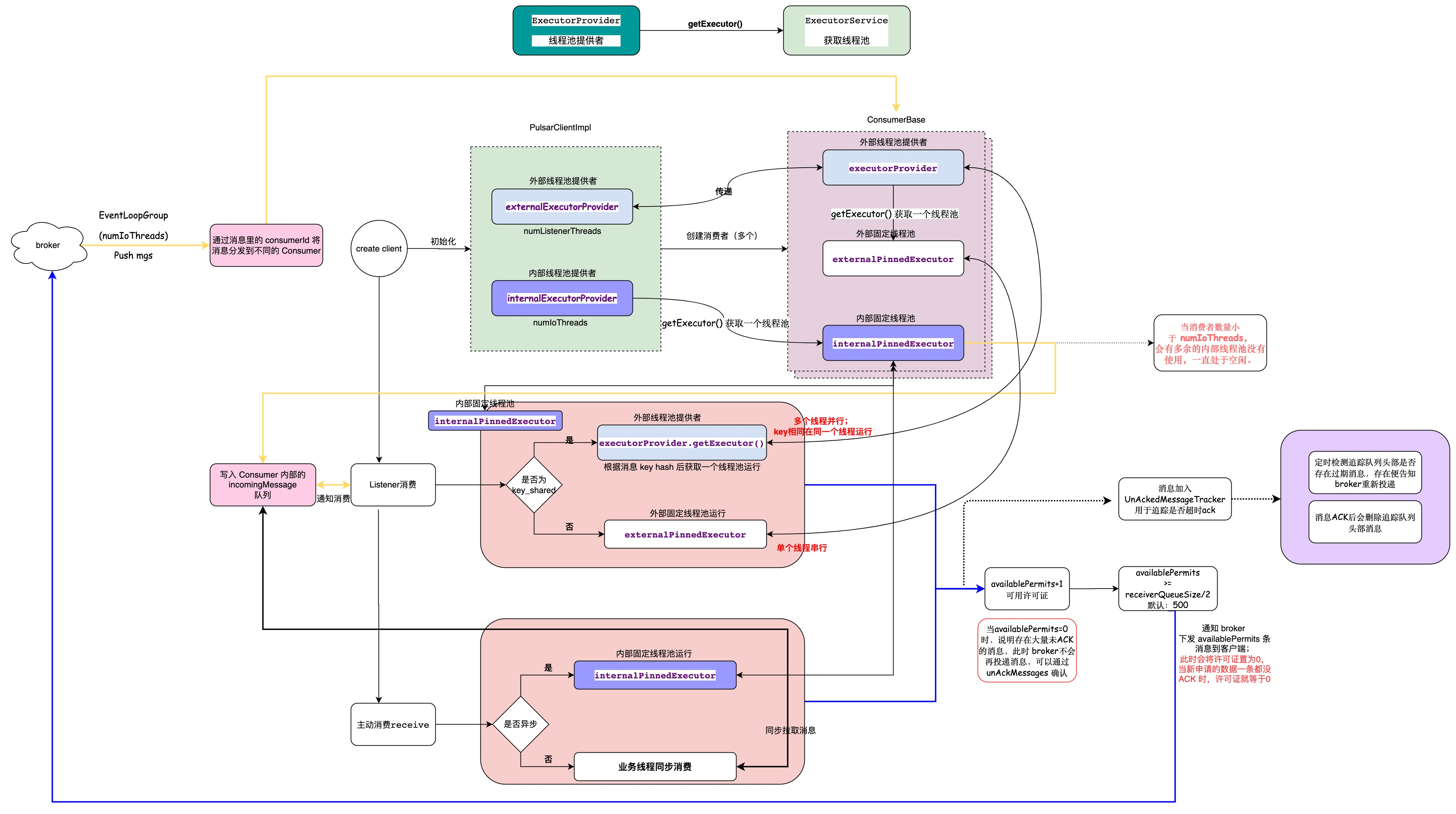

可以知道 pulsar 客户端在其中使用的是 pulsar-打头的线程名称,所以这样就列出了我们需要重点关注的线程。
我们以图中列出的线程 Id:320 为例:
thread 320

此时便会打印当前线程的堆栈。
从上述堆栈中会发现线程一直处于 IO 操作中,看起来是在操作数据库。
我们再往下翻一翻,会发现上层调用的业务代码:

查阅代码得知这是一个数据库的写入操作,看起来是在这个环节数据库响应过慢导致的 pulsar 线程被阻塞了;从而导致消息没有及时 ACK。
为了最终确认是否由数据库引起的,于是继续查询了当前应用的慢 SQL 情况:

发现其中有一个查询语句调用频次和平均耗时都比较高,而且正好这个表也是刚才在堆栈里操作的那张表。
经过业务排查发现这个慢 SQL 是由一个定时任务触发的,而这个定时任务由于某些原因一直也没有停止,所以为了快速解决这个问题,我们先尝试将这个定时任务停掉。
果然停掉没多久后消息就开始快速消费了:
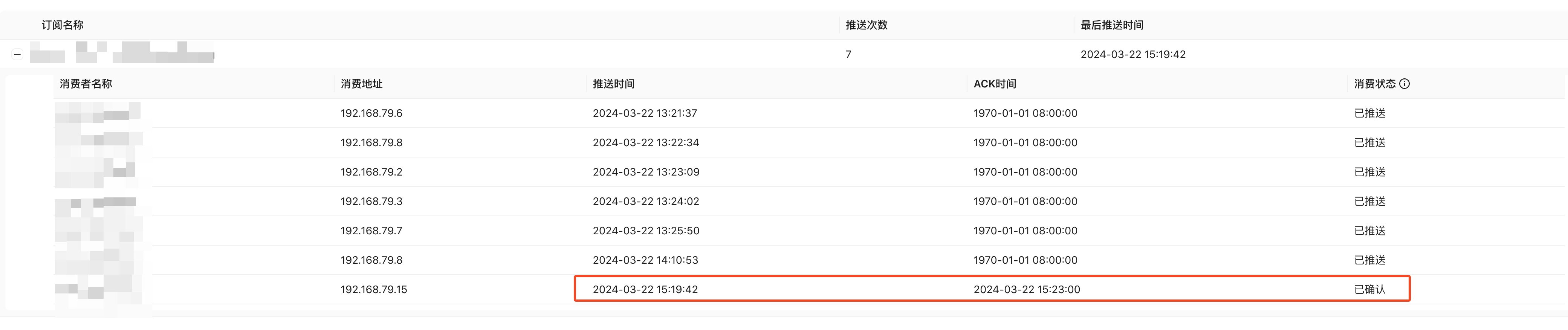
从这个时间线也可以看得出来了,在服务端推送了多次之后终于收到了 ACK。
修复之后业务再去排查优化这个慢 SQL,这样这个问题就得到根本的解决了。
更多好用技巧
当然 arthas 好用的功能还远不止此,我觉得还有以下功能比较好用:
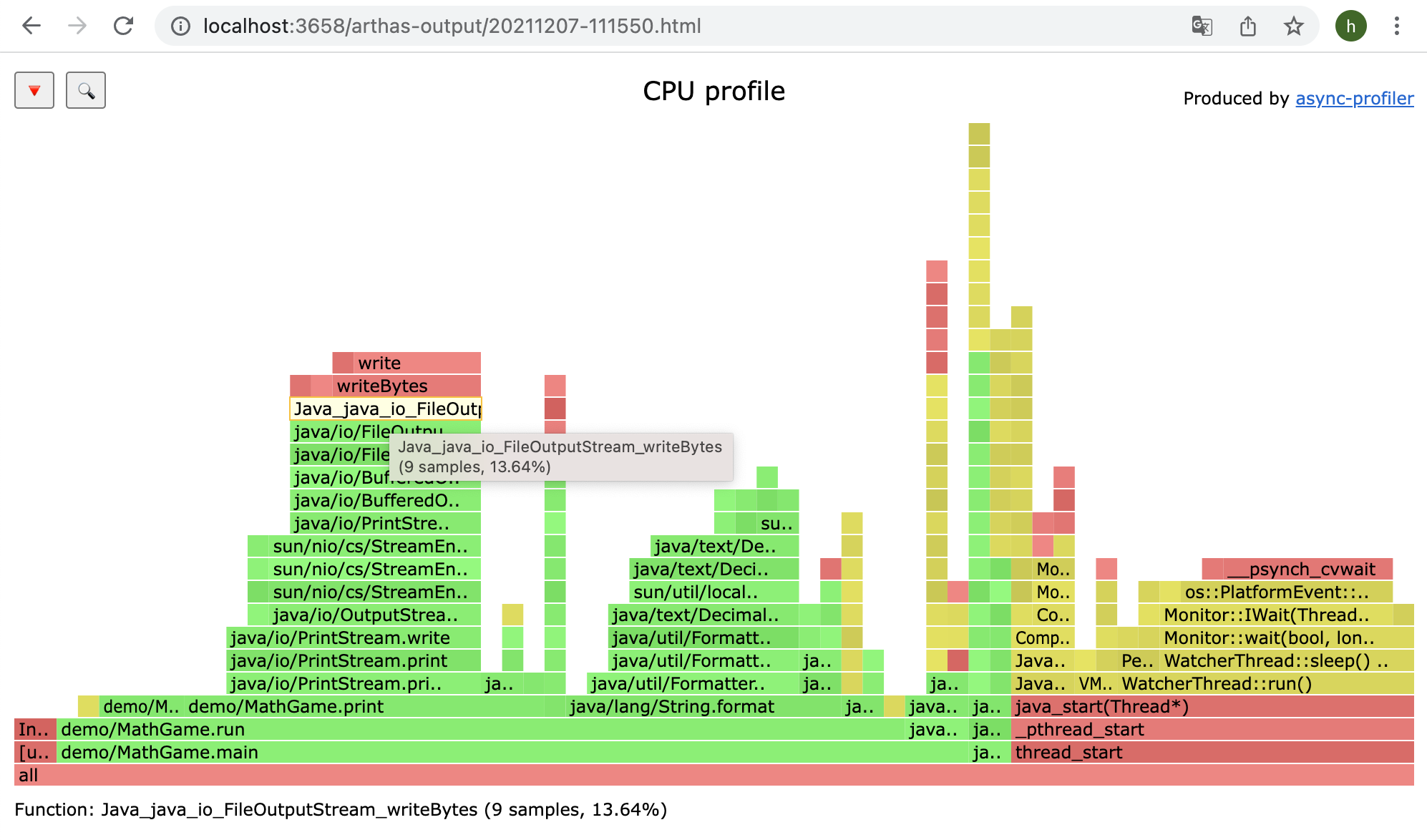
火焰图
profile:可以输出火焰图,在做性能分析的时候非常有用。
动态修改内存数据
还记得之前我们碰到过一个 pulsar 删除 topic 的 Bug,虽然最终修复了问题,但是在发布修复版本的时候为了避免再次触发老版本的 bug,需要在内存中将某个关键字段的值修改掉。
而且是不能重启应用的情况下修改,此时使用 arthas 就非常的方便:
curl -O https://arthas.aliyun.com/arthas-boot.jar && java -jar arthas-boot.jar 1 -c "vmtool -x 3 --action getInstances --className org.apache.pulsar.broker.ServiceConfiguration --express 'instances[0].setTopicLevelPoliciesEnabled(false)'"
这里使用的是 vmtool 这个子命令来获取对象,最终再使用 express 表达式将其中的值改为了 false。
当然这是一个高危操作,不到万不得已不推荐这么使用。
Arthas Tunnel & Web Console
这是一个方便开发者通过网页就可以连接到 arthas 的功能,避免直接登录到服务器进行操作。


我们在研效普通也内置了该功能,让开发排查问题更加方便。
CPU 使用过多
cpu 异常使用排查也是一个非常有用的功能,虽然我们可以通过监控得知 JVM 的 cpu 使用情况,但是没法知道具体是哪个线程以及哪行代码造成的 cpu 过高。
thread -n 3

使用以上命令就可以将 cpu 排名前三的线程打印出来,并且列出他的堆栈情况,这样可以很直观的得知 cpu 消耗了在哪些地方了。
当然还有一些 trace 查询:
trace demo.MathGame run '#cost > 10'
比如这是将调用超过 10ms 的函数打印出来,不过如果我们接入了可观测系统(OpenTelemetry、skywalking等)这个功能就用不太上了。
还可以在运行的时候不停机修改日志级别,这种在线上排查一些疑难杂症的时候非常好用(通常情况下 debug 日志是不打印的),我们可以将日志级别调整为 debug 打印出更加详细的信息:
[arthas@2062]$ logger --name ROOT --level debug
update logger level success.
如果是在 kubernetes 环境中执行也有可能碰到 Java 进程启动后没有在磁盘中写入 PID 的情况:
$ java -jar arthas-boot.jar
[INFO] arthas-boot version: 3.6.7
[INFO] Can not find java process. Try to pass <pid> in command line.
Please select an available pid.
导致直接运行的时候无法找到 Java 进程;此时就需要先 ps 拿到 PID 之后再传入 PID 连入 arthas:
$ java -jar arthas-boot.jar 1
更多关于 arthas 的用法可以参考官网。
参考链接:
- https://pulsar.apache.org/docs/3.2.x/admin-api-topics/#peek-messages
- https://crossoverjie.top/2023/12/11/ob/Pulsar-Broker-Interceptor/
- https://arthas.aliyun.com/
- https://crossoverjie.top/2024/01/09/ob/Pulsar-Delete-Topic/