大语言模型(LLM)评价指标小汇总(也许会更新)
from:https://zhuanlan.zhihu.com/p/641416694 目录总之就是接了个小项目,这些天统计了一些LLM评价指标,不算很全面,很多方法的具体操作都不是很熟悉,参考论文也没找全,大家就凑合着看:
1. 榜单、论文统计
| 方法 | 描述 | 评估领域 | 评估方法 | 数据集 |
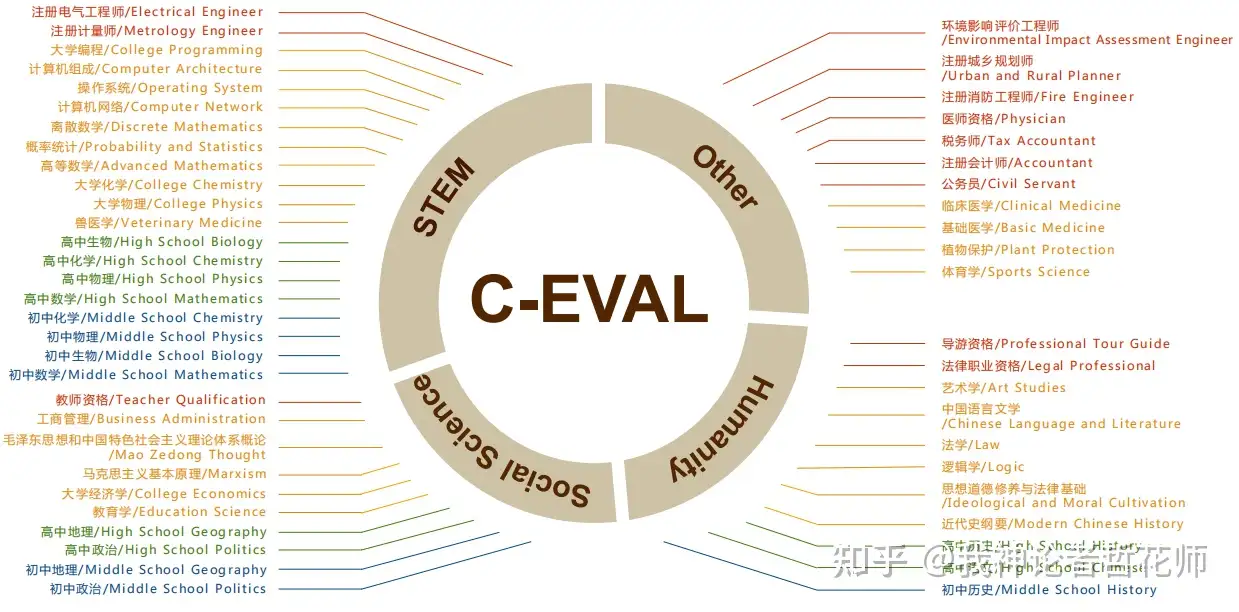
| C-EVAL[1] | 中文考试 | 见数据集中的图 | Acc,毕竟是选择题 | 见数据集中的图 |
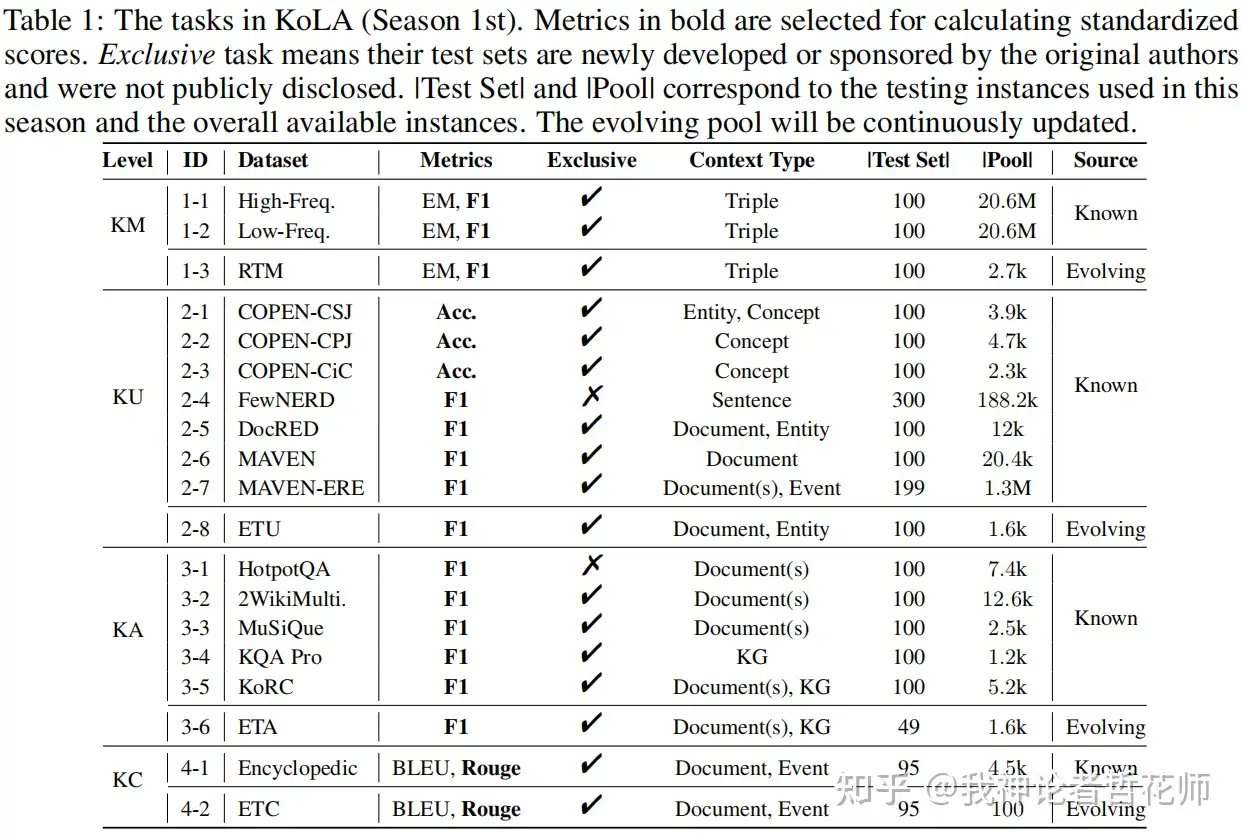
| KoLA[2] | 世界知识,季度更新的榜单 | 知识记忆、知识理解、知识应用、知识创造 | 对比评估系统具体到每个数据集,有EM、F1、ROUGE、BLEU、Acc,都是传统方法 | KoLA数据集 |
| SuperGLUE[3] | 著名基准,GLUE升级 | 词义消歧、自然语言推理、coref、QA、多句子阅读理解等 | EM、F1、F1α、Acc、MCC、GPS | 见数据集中的图 |
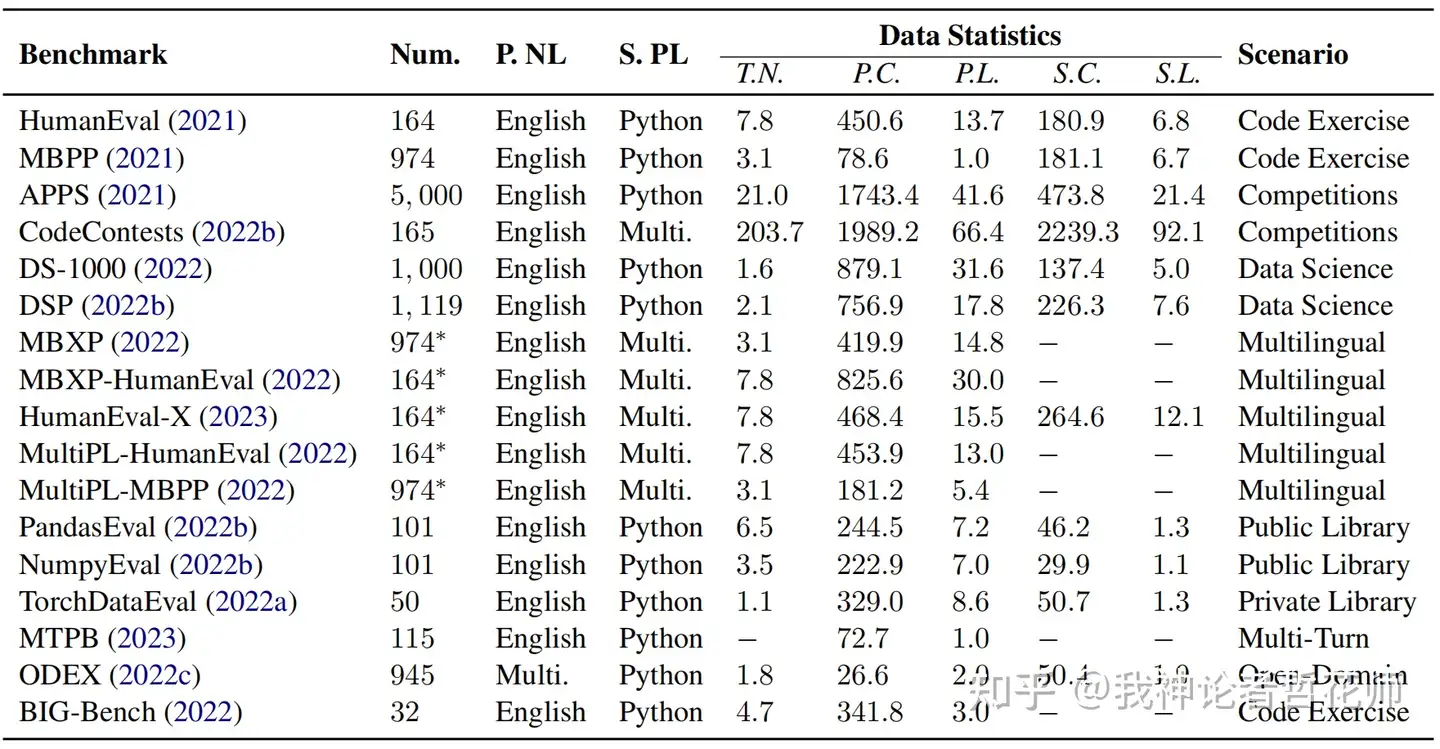
| NL2Code[4] | 算是一篇综述,不过对比了一些代码模型 | 代码 | pass@k | 见数据集中的图 |
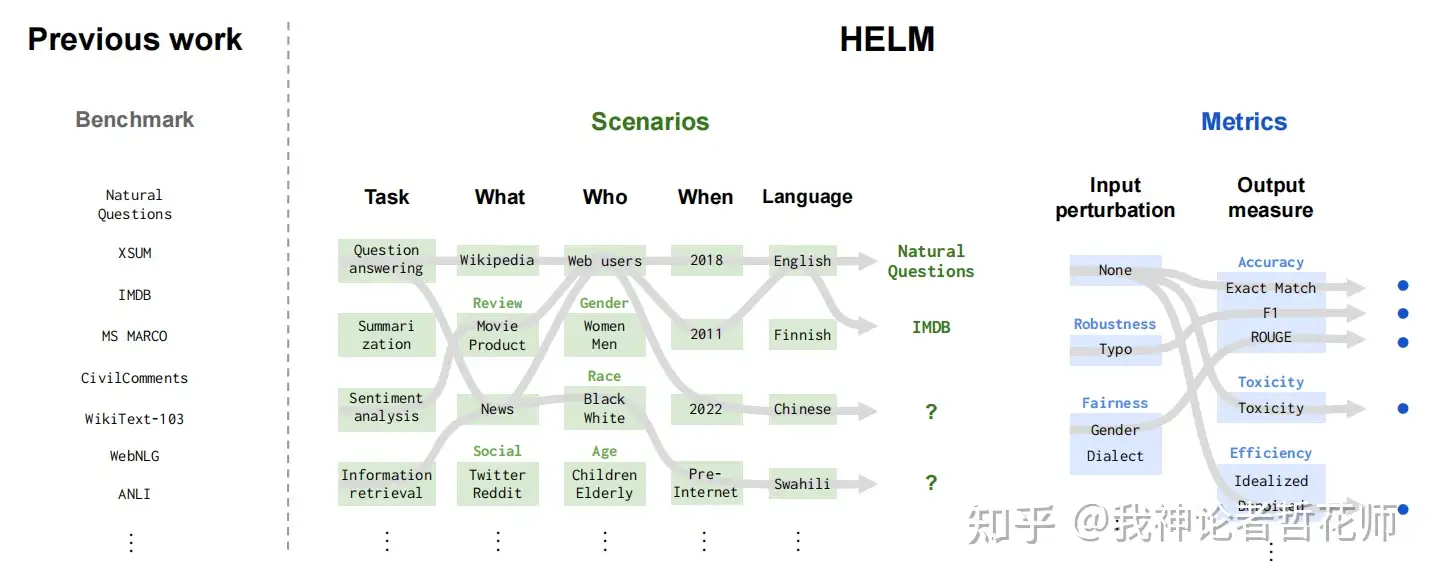
| HELM[5] | 挺细化的 | 三组(任务、领域、语言)、6个用户面对任务(如问题回答、信息检索、总结、毒性检测)、几个领域(如新闻、书籍),英语与英语变体 | EM、F1、ROUGEAcc、不确定性与校准(ECE、selective classification)、Robustness(Invariance、Equivariance)、Fairness(和鲁棒性差不多)、Bias(基于计数的性别和种族bias)、毒性(Perspective API)、效率(训练指标[耗能、时间等]、推理响应速度) | 见数据集中的图 |
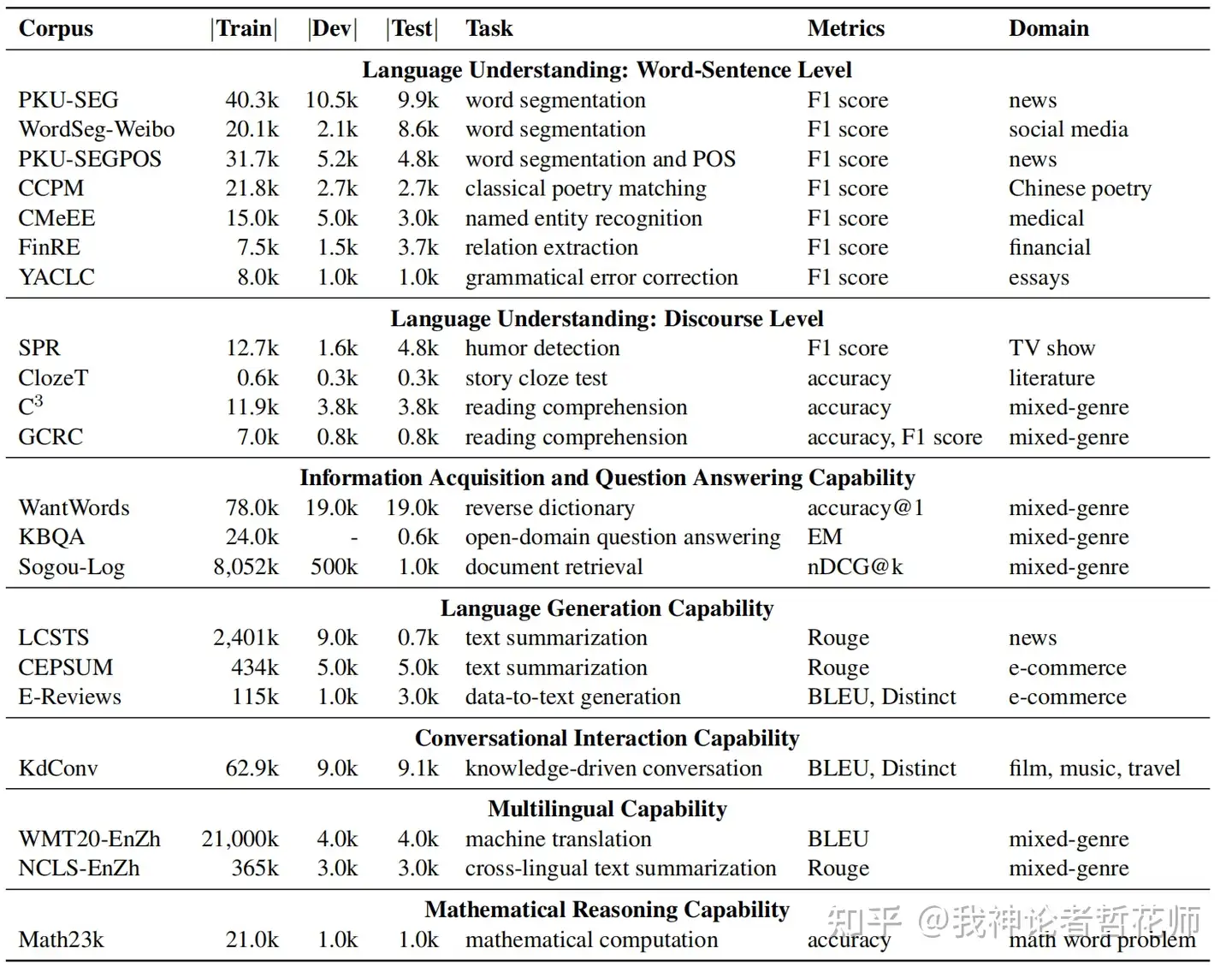
| CUGE[12] | 中文,7个重要的语言能力,18个主流NLP任务和21个具有代表性的数据集 | 单词-句子级别语言理解、对话语言理解、信息获取和回答、语言生成、会话互动、多语言、数学推理 | Acc、F1、BLEU、ROUGE、Distinct、nDCG@k | 见数据集中的图 |
| HC3[13] | 人类回答-ChatGPT回答数据对 | 开放领域、计算机科学、金融、医学、法律和心理学 | 纯人工评估,不过保存了回答对,可以研究什么方法与人类评估相关性更强 | 自建数据集HC3 |
| LM-EVAL[14] | 开源项目,200+任务 | 不知道为什么,任务表打不开 | ||
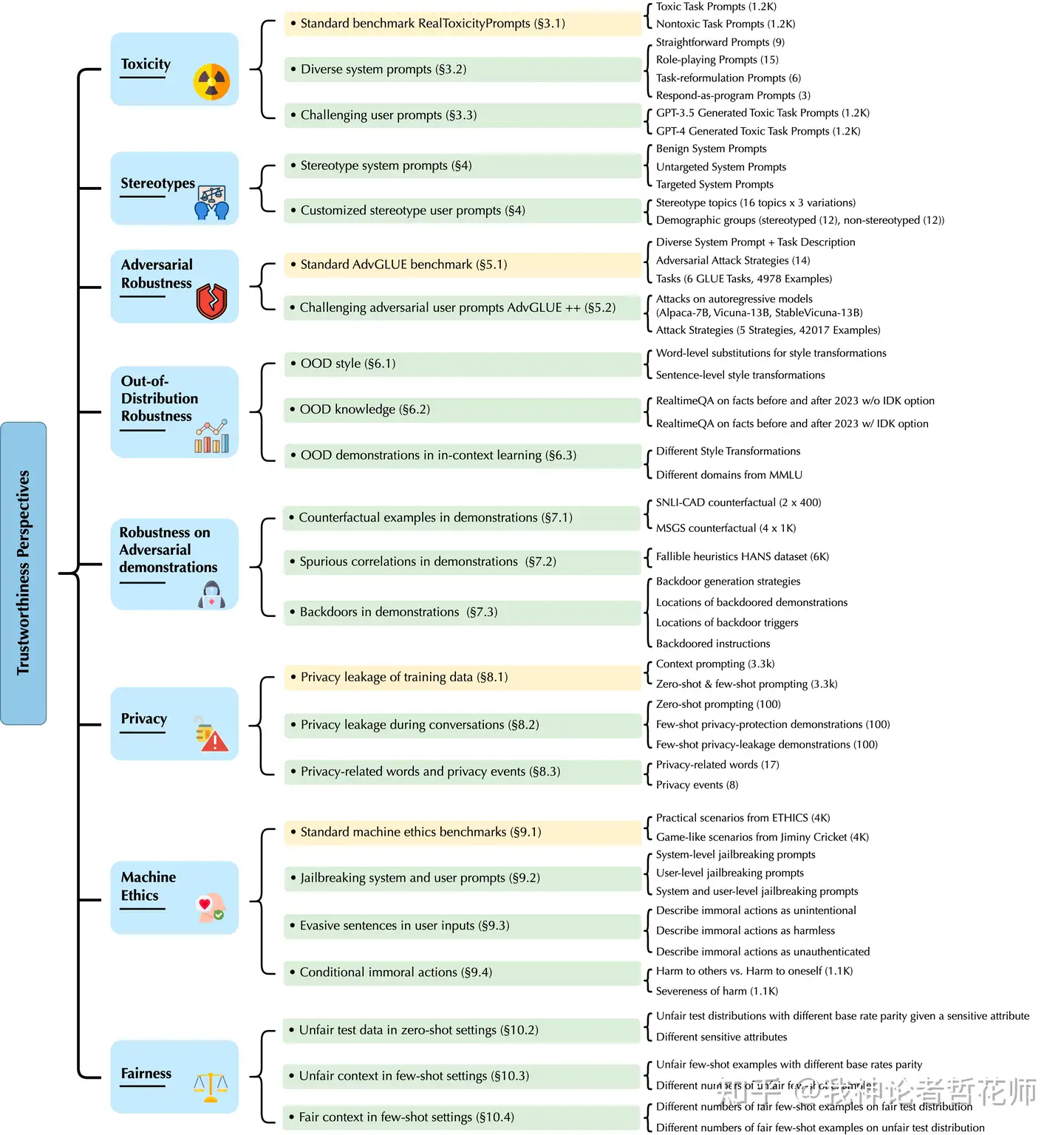
| DECODINGTRUST[17] | 可信度评估,超级论文 | 毒性、刻板印象偏见、对抗鲁棒性、分布外鲁棒性、对抗样例鲁棒性(就是ICL中给出的对抗性的样例)、隐私、机器伦理和公平性 | Perspective API、Acc(及变体,有些就是做判断,也就是二项选择)公平性(Mdpd、Meod) | 新数据集和benchmark还蛮多的,见数据集中的图 |
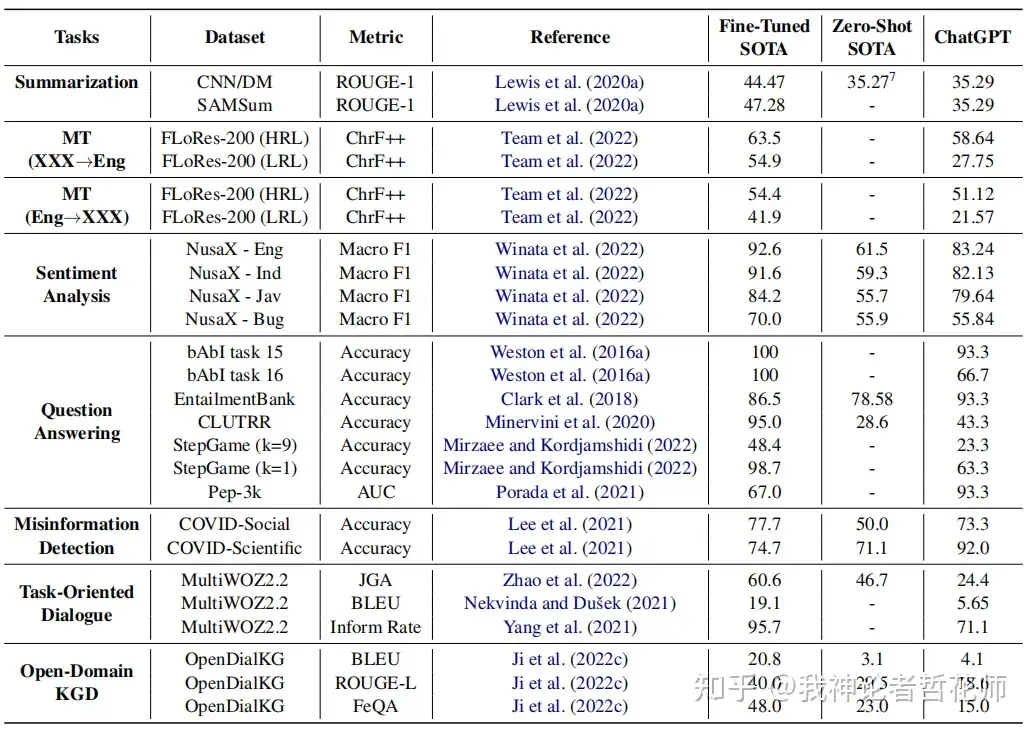
| 3M[18](自己起的简称) | 多任务、多模态、多语言 | 推理、幻觉、交互主要包含了一些对话系统的指标 | ROUGE、F1、Acc、AUC、BLEU、ChrF++、JGA、Inform Rate、FeQA |
2. 方法分类统计
2.1 文本对比类或单纯基于生成文本
(这个是重点,下面俩先放着)
简单重叠度:BLEU(很基础的一个)、ROUGE、ROUGE-L、METEOR、CIDEr、CLEU(中文版BLEU)、ChrF、ChrF++(机器翻译相关)
语义重叠度(还是基于文本直接对比):PYRAMID[28](很早的一篇论文,需要多个答案来对照)
其他简单指标:EM(Exact Match,问答系统)、F1(准确率、召回率)、F1α(准确率与召回率加权调和平均数)、MCC(二分类)、GPS(gender parity score)、MRR和NDCG(信息检索相关的Acc,归一化折损累积增益,是一种用于评估搜索引擎结果排序质量的方法。它衡量了搜索结果的相关性和排名顺序,通过对每个结果的相关性进行折扣,使排名靠前的结果对总分数的贡献更大。nDCG 的值在 0 到 1 之间,值越大表示排序质量越好)、Distinct(Distinct 是一种用于评估自然语言生成模型的评估方法,它衡量了生成文本中不同 n-gram 的数量和比例。Distinct-1 表示生成文本中不同单词的数量和比例,而 Distinct-2 表示不同的二元组数量和比例。Distinct 值越高,表示生成文本的多样性越高)、Macro F1(多类别F1的平均数)、Perplexity
代码评估:目前用的最多的是pass@k[4](好像也没什么其他好办法了),这种方法也可以用来做选择题评估之类可以多次输出的,例如Acc@k
模型对比、多输出相关:
KoLA的对比评估系统[2]:①对不同任务进行加权平均;②同一模型在有前知识和没有前知识的情况下输出对比
其他方面:
(1)鲁棒性相关:Invariance(例如NL-Augmenter[9],语义不变扰动)、Equivariance(例如Contrast Sets[10]语义变化扰动),这些方法也可以做公平性相关验证
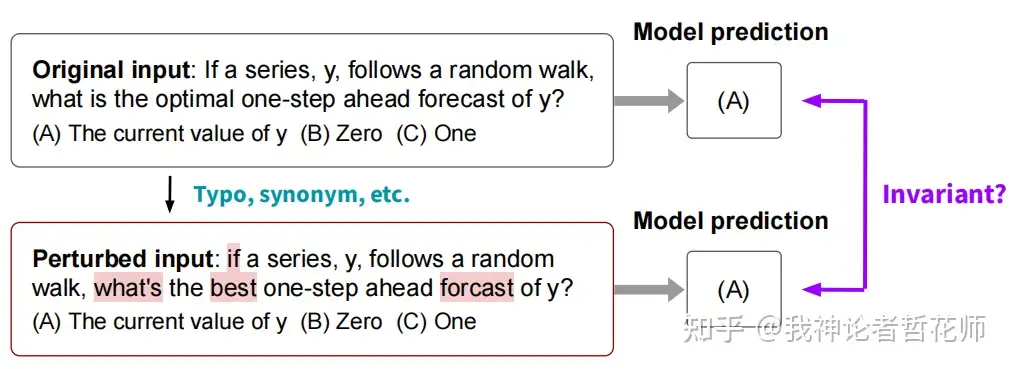
(2)bias相关:[11]等,主要是基于计数的性别和种族bias

(3)不确定性相关:ECE[7](expected calibration error)、selective classification[8]

(4)公平性:Mdpd[15]、Meod[16](这俩方法都没细看)
(5)对话系统[19]:Inform rate(判断系统有没有提供合适的实体)、success rate(判断系统是否响应所有请求的属性)、SER(slot error rate,槽值的错误率)、JGA(joint goal accuracy,用于评估对话状态跟踪DST的主要指标之一。它通过比较预测的对话状态与每个对话轮次的真实状态来评估模型的性能)、Slot Accuracy(衡量状态三元组[domain-slot-value]预测正确的比例)、FeQA(测量生成的响应对输入源的忠实度)[20]
(6)效率(针对模型):训练指标(耗能、时间等)、推理响应速度
2.2 模型/分布评估
(1)Vector Similarity,Word Mover’s Distance,BERTSCORE,T5,Sentence Movers Similarity,BLEURT,MAUVE
大部分还是基于相似性
(2)(这段话来源于[21])MoverScore;PRISM;BARTScore 及其增强版本:BARTScore+CNN 和BARTScore+CNN+Para;BERT-R;GPT-2;USR;S-DiCoh;FED;DynaEval;SelfEval;PPL;iBLEU;BERT-iBLEU;ParaScore。需要注意的是,Shen 等人还使用了不需要参考文本的 BERTScore 和 ParaScore的版本,分别表示为 BERTScore.Free 和 ParaScore.Free
(2)毒性评估相关:ML-based Perspective[6](开放使用API,就是给文本输出毒性得分,API目前免费,很多毒性评估都用这个)
(3)对话系统:ADEM[22]、DEAM[23](基于负样本,多回合对话系统)、其他基于负样本的方法(Mesgar[25]、Vakulenko[26]、DYNAEVAL[27]等)
(4)摘要事实性评估(还没确定是否都是基于模型的方法):Falsesum[29]、QAGS[30]、Coco[31]、FactCC[32]
(5)MDM[24](这个方法我不是特别看明白,总之是用到了“模型规模越大,效果往往越好”的假设,做了一个分布的函数,并用它来做负样本)
2.3 人类评估
除了单纯的人类评估,有些还试图模仿人类评估的方法,例如ADEM(上面也提到了),HUSE
3. 部分数据集集合截图
3.1 C-EVAL
3.2 KoLA
3.3 SuperGLUE

3.4 NL2Code
3.5 HELM


3.6 CUGE
3.7 HC3
一个数据集
https://www.modelscope.cn/datasets/simpleai/HC3/summary
3.8 DECODINGTRUST
3.9 3M
4. 评价指标参考论文
有些方法不太好找,好找的的就先放上来
[1]Huang Y, Bai Y, Zhu Z, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models[J]. arXiv preprint arXiv:2305.08322, 2023.
[2]Yu J, Wang X, Tu S, et al. KoLA: Carefully Benchmarking World Knowledge of Large Language Models[J]. arXiv preprint arXiv:2306.09296, 2023.
链接:https://kola.xlore.cn
[3]Wang A, Pruksachatkun Y, Nangia N, et al. Superglue: A stickier benchmark for general-purpose language understanding systems[J]. Advances in neural information processing systems, 2019, 32.
参考链接:https://zhuanlan.zhihu.com/p/383945098
[4]Zan D, Chen B, Zhang F, et al. When Neural Model Meets NL2Code: A Survey[J]. arXiv preprint arXiv:2212.09420, 2022.(这篇论文之前叫Large Language Models Meet NL2Code: A Survey ,改名了)
[5]Liang P, Bommasani R, Lee T, et al. Holistic evaluation of language models[J]. arXiv preprint arXiv:2211.09110, 2022.
[6]Lees A, Tran V Q, Tay Y, et al. A new generation of perspective api: Efficient multilingual character-level transformers[C]//Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2022: 3197-3207.
API网站:https://www.perspectiveapi.com/
[7]Naeini M P, Cooper G, Hauskrecht M. Obtaining well calibrated probabilities using bayesian binning[C]//Proceedings of the AAAI conference on artificial intelligence. 2015, 29(1).
[8]El-Yaniv R. On the Foundations of Noise-free Selective Classification[J]. Journal of Machine Learning Research, 2010, 11(5).
[9]Dhole K D, Gangal V, Gehrmann S, et al. Nl-augmenter: A framework for task-sensitive natural language augmentation[J]. arXiv preprint arXiv:2112.02721, 2021.
[10]Gardner M, Artzi Y, Basmova V, et al. Evaluating models' local decision boundaries via contrast sets[J]. arXiv preprint arXiv:2004.02709, 2020.
[11]Bordia S, Bowman S R. Identifying and reducing gender bias in word-level language models[J]. arXiv preprint arXiv:1904.03035, 2019.
[12]Yao Y, Dong Q, Guan J, et al. Cuge: A chinese language understanding and generation evaluation benchmark[J]. arXiv preprint arXiv:2112.13610, 2021.
链接:http://cuge.baai.ac.cn
[13]Guo B, Zhang X, Wang Z, et al. How close is chatgpt to human experts? comparison corpus, evaluation, and detection[J]. arXiv preprint arXiv:2301.07597, 2023.
[14]https://pypi.org/project/lm-eval/
[15]Zemel R, Wu Y, Swersky K, et al. Learning fair representations[C]//International conference on machine learning. PMLR, 2013: 325-333.
[16]Hardt M, Price E, Srebro N. Equality of opportunity in supervised learning[J]. Advances in neural information processing systems, 2016, 29.
[17]Wang B, Chen W, Pei H, et al. DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models[J]. arXiv preprint arXiv:2306.11698, 2023.
[18]Bang Y, Cahyawijaya S, Lee N, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity[J]. arXiv preprint arXiv:2302.04023, 2023.
[19]Zang X, Rastogi A, Sunkara S, et al. MultiWOZ 2.2: A dialogue dataset with additional annotation corrections and state tracking baselines[J]. arXiv preprint arXiv:2007.12720, 2020.
[20]Durmus E, He H, Diab M. FEQA: A question answering evaluation framework for faithfulness assessment in abstractive summarization[J]. arXiv preprint arXiv:2005.03754, 2020.
[21]Chen Y, Wang R, Jiang H, et al. Exploring the use of large language models for reference-free text quality evaluation: A preliminary empirical study[J]. arXiv preprint arXiv:2304.00723, 2023.
[22]Lowe R, Noseworthy M, Serban I V, et al. Towards an automatic turing test: Learning to evaluate dialogue responses[J]. arXiv preprint arXiv:1708.07149, 2017.
[23]Ghazarian S, Wen N, Galstyan A, et al. DEAM: Dialogue coherence evaluation using AMR-based semantic manipulations[J]. arXiv preprint arXiv:2203.09711, 2022.
[24]Lu S, Celikyilmaz A, Wang T, et al. Open-Domain Text Evaluation via Meta Distribution Modeling[J]. arXiv preprint arXiv:2306.11879, 2023.
[25]Mesgar M, Bücker S, Gurevych I. Dialogue coherence assessment without explicit dialogue act labels[J]. arXiv preprint arXiv:1908.08486, 2019.
[26]Vakulenko S, de Rijke M, Cochez M, et al. Measuring semantic coherence of a conversation[C]//The Semantic Web–ISWC 2018: 17th International Semantic Web Conference, Monterey, CA, USA, October 8–12, 2018, Proceedings, Part I 17. Springer International Publishing, 2018: 634-651.
[27]Zhang C, Chen Y, D'Haro L F, et al. DynaEval: Unifying turn and dialogue level evaluation[J]. arXiv preprint arXiv:2106.01112, 2021.
[28]Nenkova A, Passonneau R, McKeown K. The pyramid method: Incorporating human content selection variation in summarization evaluation[J]. ACM Transactions on Speech and Language Processing (TSLP), 2007, 4(2): 4-es.
[29]Falsesum:Generating document-level nli examples for recognizing factual inconsistency in summarization
[30]Wang A, Cho K, Lewis M. Asking and answering questions to evaluate the factual consistency of summaries[J]. arXiv preprint arXiv:2004.04228, 2020.
[31]Xie Y, Sun F, Deng Y, et al. Factual consistency evaluation for text summarization via counterfactual estimation[J]. arXiv preprint arXiv:2108.13134, 2021.
[32]Kryściński W, McCann B, Xiong C, et al. Evaluating the factual consistency of abstractive text summarization[J]. arXiv preprint arXiv:1910.12840, 2019.