Multi-Camara Methods
Co-Communication Graph Convolutional Network for Multi-View Crowd Counting https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9860092
针对问题
以往方法利用多视角图像特征像素级匹配,匹配关系估计亲和矩阵,错误匹配会导致估计结果不准确
方法
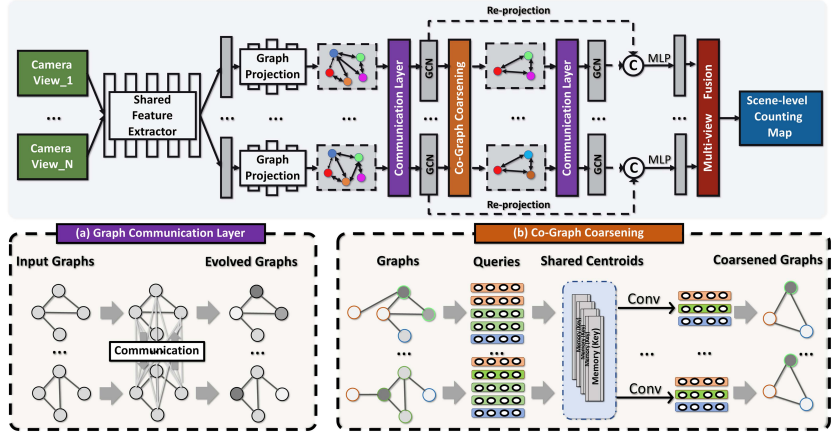
将每个摄像机试图投射到一个图中,节点为Vi,边为Ei,用于捕捉视图内的上下文依赖关系和视图间的互补关系
-
输入:
- 多摄像头视角数据集,模型输入是一组来自多个摄像机视角的图像,记作
-
输出:
- 场景级密度图,模型的输出是一个场景级密度图(D),该密度图表示整个监控区域的估计人流量。该密度图是通过融合所有视角的信息得到的,并且可以从中计算出总人数。
-
单视角特征提取层:
- 使用全卷积网络(例如截断的VGG网络)从每个输入图像中提取特征,得到一组初始单视角表示 {f1, f2, ..., fn}。
-
图构建层:
- 对于每个特征图 fi,使用聚类方法将其投影到一个图 Gi = (Vi, Ei) 上,其中 Vi 是节点集合,Ei 是边集合,表示特征向量之间的相关性。
-
图通信层(GCL):
- 通过建立图之间的显式链接来编码跨视角的互补信息。这一层使用匹配函数(如余弦相似性)和消息传递函数来更新每个图的节点表示。
-
图卷积层(GCN):
- 对每个更新后的图表示进行图卷积操作,以捕获单视角内的上下文依赖性。这一层使用标准的图卷积网络来实现。
-
图重投影层:
- 将图卷积层输出的节点表示重新投影回原始特征图的坐标空间,以增强特征表示。这通常通过注意力机制实现。
-
共记忆层(CoML):
- 这一层通过层次化图池化过程来学习每个单视角图的层次化表示。它使用共享的键值记忆机制来粗化图,并生成一系列层次化的图表示。
-
宽区域表示学习层:
- 这一层将多视角特征映射到场景级坐标空间,并使用融合函数(例如连接层后跟1x1卷积层)来产生最终的场景级表示。
-
分类器:
- 最后,使用一个可学习的分类器(通常是1x1卷积层)将场景级表示映射到相应的密度图 D,通过求和所有值来计算总人数。
效果图
