字符编码
字符编码简介
字符(character)是计算机与人交互的媒介,人虽然可以看懂二进制串,但文字是更加直观的。所以需要用数字来表示字符,字符与数字的对应关系就叫编码(coding)。
-
ASCII:使用1个字节表示字符,8位二进制一共可表示256个不同的值,但实际只用到了前面的128个位置。
-
GBK:双字节编码,两个字节表示字符,汉字编码国家标准。
-
BIG5:台湾地区繁体中文标准字符集,采用双字节编码,共收录 13053 个中文字。
-
unicode: 在计算机科学领域中,Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准,囊括世界上大部分国家的文字编码方式,使得全球的计算机在文字编码上能够拥有统一的标准。
所有编码都会兼容ASCII码,因为一共就127个字符。
如果说unicode是通过3个字节保存一个字符,那么一个字符abc,则是0x00,0x00,0x61,0x00,0x00,0x62,0x00,0x00,0x63,需要9个字节保存3个字符,对于纯英文的国家,就算是造成了大量的浪费。
字符编码表示
unicode有以下几种表示方法,但不限于:
- utf-8
- utf-16BE
- utf-16LE
以下是字符abc在不同编码格式下的二进制数据表示:
utf-8:

utf-16LE:

FF FE 表示小端。
utf-16BE:

FE FF 表示大端。
unicode只是字符集,规定了数字到字符的映射,但是没有规定数据是如何存储的,这里面的utf-8编码具有更多优点。
UTF-8的存储规则
以下引用阮一峰老师对应UTF-8的讲解:
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
文本文件的二进制数据代表什么,取决于编码格式,最后显示为字体文件,字体文件包含编码表、字体数据信息。
显示文字
文字编码方式
源文件用不同的编码方式编写,会导致执行结果不一样。
怎么解决?编译程序时,需要要指定字符集。
man gcc , /charset 查找gcc的编码命令
-finput-charset=charset 表示源文件的编码方式, 默认以UTF-8来解析
-fexec-charset=charset 表示可执行程序里的字时候以什么编码方式来表示,默认是UTF-8
gcc -o a a.c //默认为utf-8格式
gcc -finput-charset=GBK -fexec-charset=UTF-8 -o utf-8_2 ansi.c //输入字符集里面是GBK编码,但是要以UTF-8输出可执行文件。
英文字母、汉字的点阵显示
在SDRAM内存中划分一块空间,为FrameBuffer显存空间;开发板包含CPU和LCD控制器,外接一块LCD屏幕。
LCD控制器会从显存中取出数据,发送给LCD,屏幕会根据数据在屏幕上像素点的相应位置表示颜色。
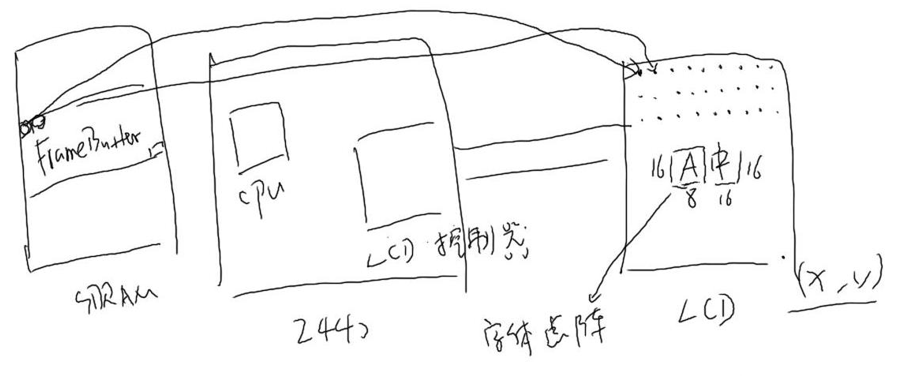
英文字符输出到LCD上
以下是数据到屏幕的映射方式:
816像素的点阵显示,就是816bit的字节显示。
/**
* @name: lcd_put_ascii
* @brief: 输出ascii字符到LCD的(x,y)位置上
* @param: {None}
* @retval:
* @param {int} x x轴
* @param {int} y y轴
* @param {unsigned char} c 字符
*/
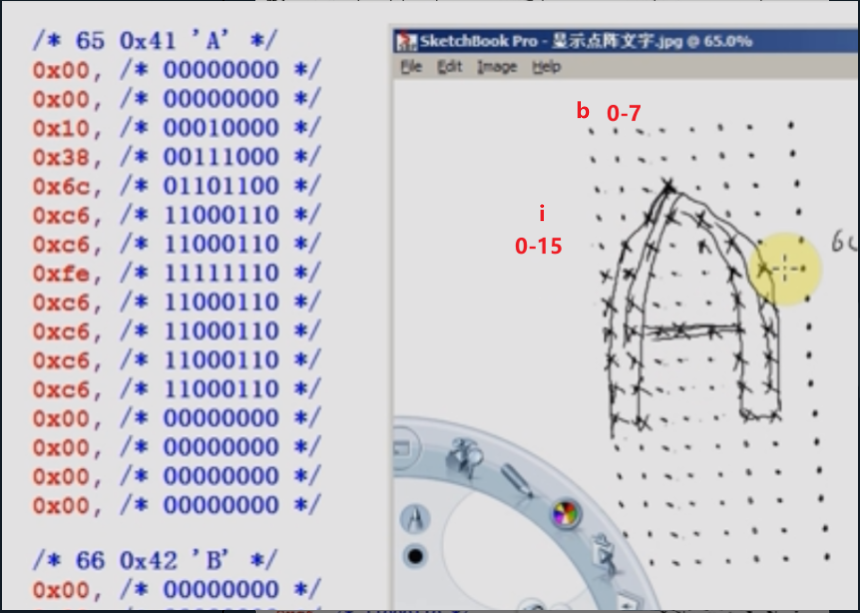
void lcd_put_ascii(int x, int y, unsigned char c)
{
unsigned char *dots = (unsigned char *)&fontdata_8x16[c*16];//从fontdata获得字符c首地址,每个ascii码,占据16个字节,1个字节8位
int i, b;
unsigned char byte;
for (i = 0; i < 16; i++)//y轴像素
{
byte = dots[i];
for (b = 7; b >= 0; b--)//x轴像素
{
if (byte & (1<<b))//从高到低取出字节
{
/* show */
lcd_put_pixel(x+7-b, y+i, 0xffffff); /* 白 输出颜色到指定(x,y)位置上*/
}
else
{
/* hide */
lcd_put_pixel(x+7-b, y+i, 0); /* 黑 */
}
}
}
}
屏幕可变信息结构体:

mmap函数说明:

我们也可以通过mmap将一个文件映射为物理空间,而不需要用read函数读取数据,可以通过fstat函数获得文件大小。

输出16*16中文字符到LCD
HZK16 字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。其中一级汉字有3755个,按 声序排列,二级汉字有3008个,按偏旁部首排列。我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
我们知道一个GB2312汉字是由两个字节编码的,范围为A1A1~FEFE。A1-A9为符号区,B0到F7为汉字区。每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)。下面以汉字“我”为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。
前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的 位号。其中,每个区记录94个汉字,位号为该字在该区中的位置。所以要找到“我”在hzk16库中的位置就必须得到它的区码和位码。(为了区别使用了区码 和区号,其实是一个东西,别被我误导了)
区码:区号(汉字的第一个字节)-0xa0 (因为汉字编码是从0xa0区开始的,所以文件最前面就是从0xa0区开始,要算出相对区码)
位码:位号(汉字的第二个字节)-0xa0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:
offset=(94(区码-1)+(位码-1))32
注解:1、区码减1是因为数组是以0为开始而区号位号是以1为开始的
2、(94*(区号-1)+位号-1)是一个汉字字模占用的字节数 3、最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息(前面提到一个汉字要有32个字节显示)有了偏移地址就可以从HZK16中读取汉字编码了,

/**
* @name: lcd_put_chinese
* @brief: 输出16*16像素的中文字符到LCD屏幕上
* @param: {None}
* @retval:
* @param {int} x x轴
* @param {int} y y轴
* @param {unsigned char} *str 中文字符
*/
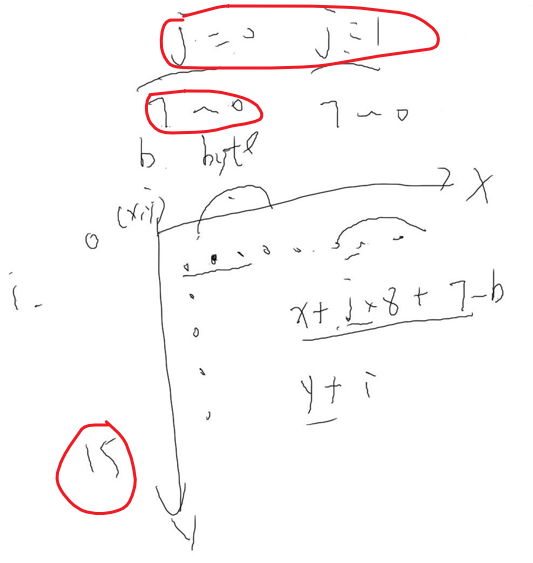
void lcd_put_chinese(int x, int y, unsigned char *str)
{
unsigned int area = str[0] - 0xA1; //区号
unsigned int where = str[1] - 0xA1; //位号
unsigned char *dots = hzkmem + (area * 94 + where)*32;//从汉字库读取数据,因为已经通过mmap映射了,所以可以当成数组读取
unsigned char byte;
int i, j, b;
for (i = 0; i < 16; i++)//16个字节
for (j = 0; j < 2; j++)
{
byte = dots[i*2 + j];
for (b = 7; b >=0; b--)//8bit
{
if (byte & (1<<b))
{
/* show */
lcd_put_pixel(x+j*8+7-b, y+i, 0xffffff); /* 白 */
}
else
{
/* hide */
lcd_put_pixel(x+j*8+7-b, y+i, 0); /* 黑 */
}
}
}
}
输出点阵到屏幕的像素上
前两个函数只是用从字库里面找出了屏幕上的相对位置,但是没有写入到显存的具体位置去。
将LCD屏幕上的像素点映射为物理地址fbmem,写入到这里面,也就控制了数据的显示。
LCD显示屏是由width * height个像素点构成的,显示字符,一个非常容易想到的方法便是对字符取模,然后在LCD屏上打点显示字符,这里的点,就是我们以前用lcd_put_pixel(x, y, 0); 输出点到屏幕上面,先写到显存里面,也就是输出到fbem的相对位置上。一个点对应一个像素,一个像素的x轴看每个像素多少位,一个像素的y轴看输出多少个字节。
/**
* @name: lcd_put_pixel
* @brief: 把字符输出到LCD的屏幕像素上
* @param: {None}
* @retval:
* @param {int} x
* @param {int} y
* @param {unsigned int} color /* color : 0x00RRGGBB */
*/
void lcd_put_pixel(int x, int y, unsigned int color)
{
unsigned char *pen_8 = fbmem+y*line_width+x*pixel_width;
unsigned short *pen_16;
unsigned int *pen_32;
unsigned int red, green, blue;
pen_16 = (unsigned short *)pen_8;
pen_32 = (unsigned int *)pen_8;
switch (var.bits_per_pixel)//匹配一个像素多少位
{
case 8:
{
*pen_8 = color;
break;
}
case 16:
{
/* RBG按照565比例分布 */
red = (color >> 16) & 0xff;
green = (color >> 8) & 0xff;
blue = (color >> 0) & 0xff;
//(red >> 3)表示只保留8-3=5位,然后<<11就是移到color数据的的位置上去
color = ((red >> 3) << 11) | ((green >> 2) << 5) | (blue >> 3);
*pen_16 = color;
break;
}
case 32:
{
*pen_32 = color;
break;
}
default:
{
printf("can't surport %dbpp\n", var.bits_per_pixel);
break;
}
}
}
编译我们的`show_font.c`文件,拷贝show_font还有HZK16到内核里面去:
bleaaach@bleaaach-virtual-machine:~/linux/IMX6ULL/project_frame$ arm-linux-gnueabihf-gcc -o show_font show_font.c
bleaaach@bleaaach-virtual-machine:~/linux/IMX6ULL/project_frame$ ls
HZK16 show_font show_font.c
配置、修改内核支持把led.c编译进去:

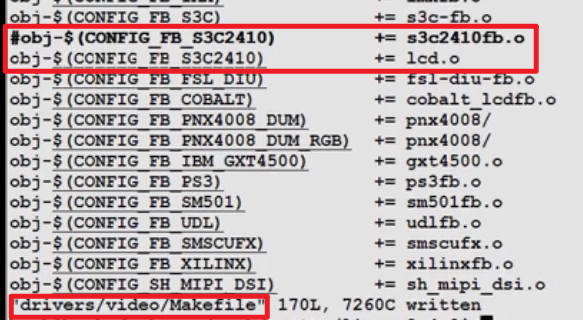
make menuconfig,找到Device Drivers-Support for frame buffer devices:
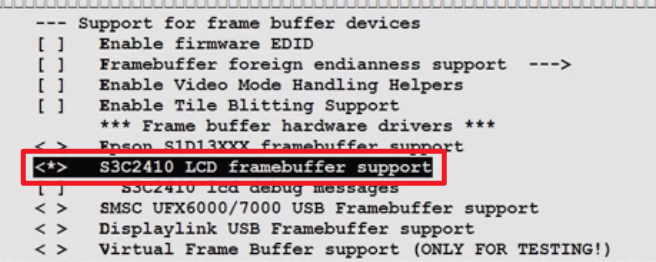
重新编译,生成新的uImage:
使用新内核启动:


测试实验:
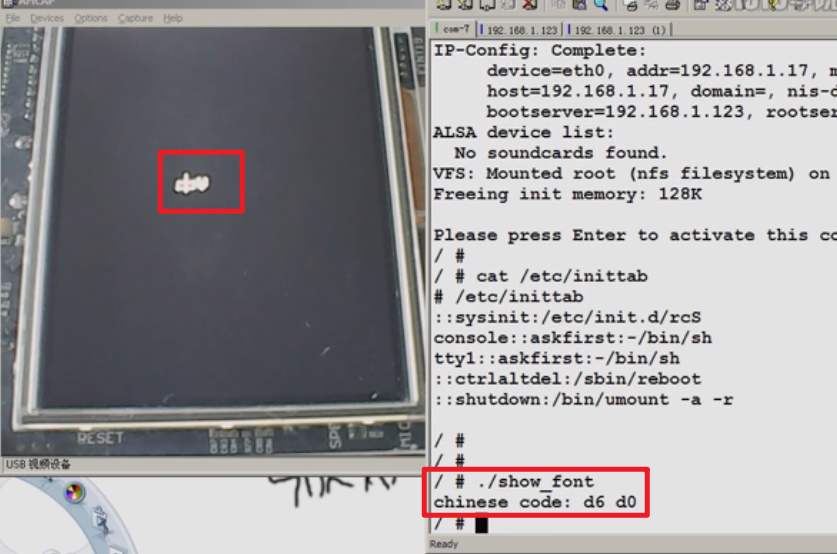
我们的写的是应用程序跟开发板、跟硬件是具体的板子是没有关系的。
总结

关于这一块的描述可以直接参考正点原子官方提供的linux应用编程指南,里面有详细的解释:
参考:
标签:编码,字节,东山,int,16,相框,unsigned,字符 From: https://www.cnblogs.com/rose24/p/18109217/wei-dongshandigital-photo-frame-2-1ejr0m