1.背景简述
在技术运维过程中,很难从某服务庞杂的日志中,单独找寻出某次API调用的全部日志。
为提高排查问题的效率,在多个系统及应用内根据 统一的TraceId 查找同一次请求链路上的日志,根据日志快速定位问题,同时需对业务代码无侵入,特别是在高频请求下,也可以方便的搜索此次请求的日志内容。
本此分享一个使用MDC实现日志链路跟踪,在微服务环境中,我们经常使用Skywalking、Spring Cloud Sleut等去实现整体请求链路的追踪,但是这个整体运维成本高,架构复杂,本次我们来使用MDC通过Log来实现一个轻量级的会话事务跟踪功能,需要的朋友可以参考一下。
应用效果图
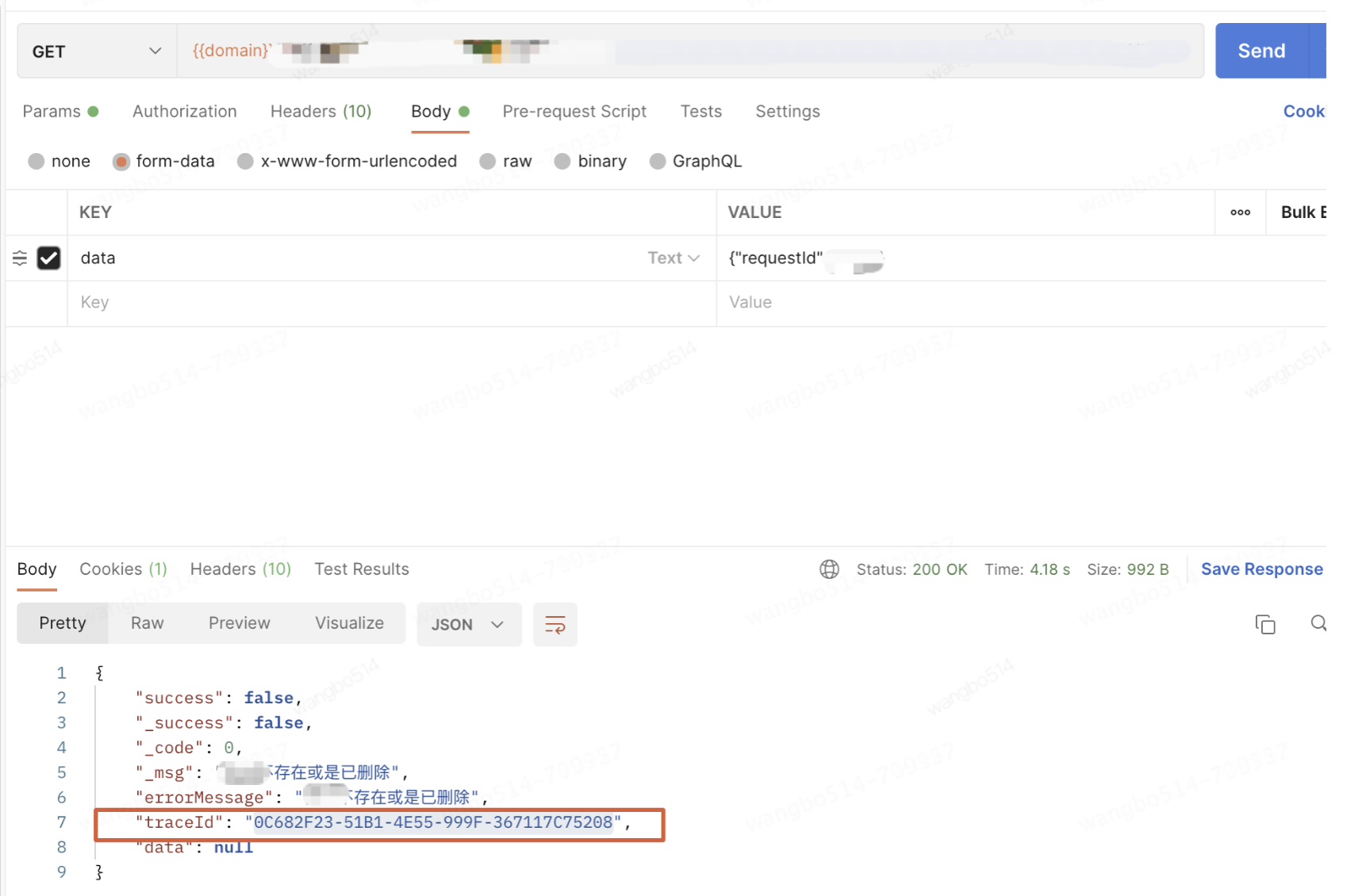
我们知道了MDC的好处后,其实在用户从第一时间调用请求时候,我们其实可以将请求增加tarceid一并返回,这样用户反馈时候,我们直接用traceid就可以全链路追踪到所有请求的情况了,做到信息的闭环。
请求效果图:
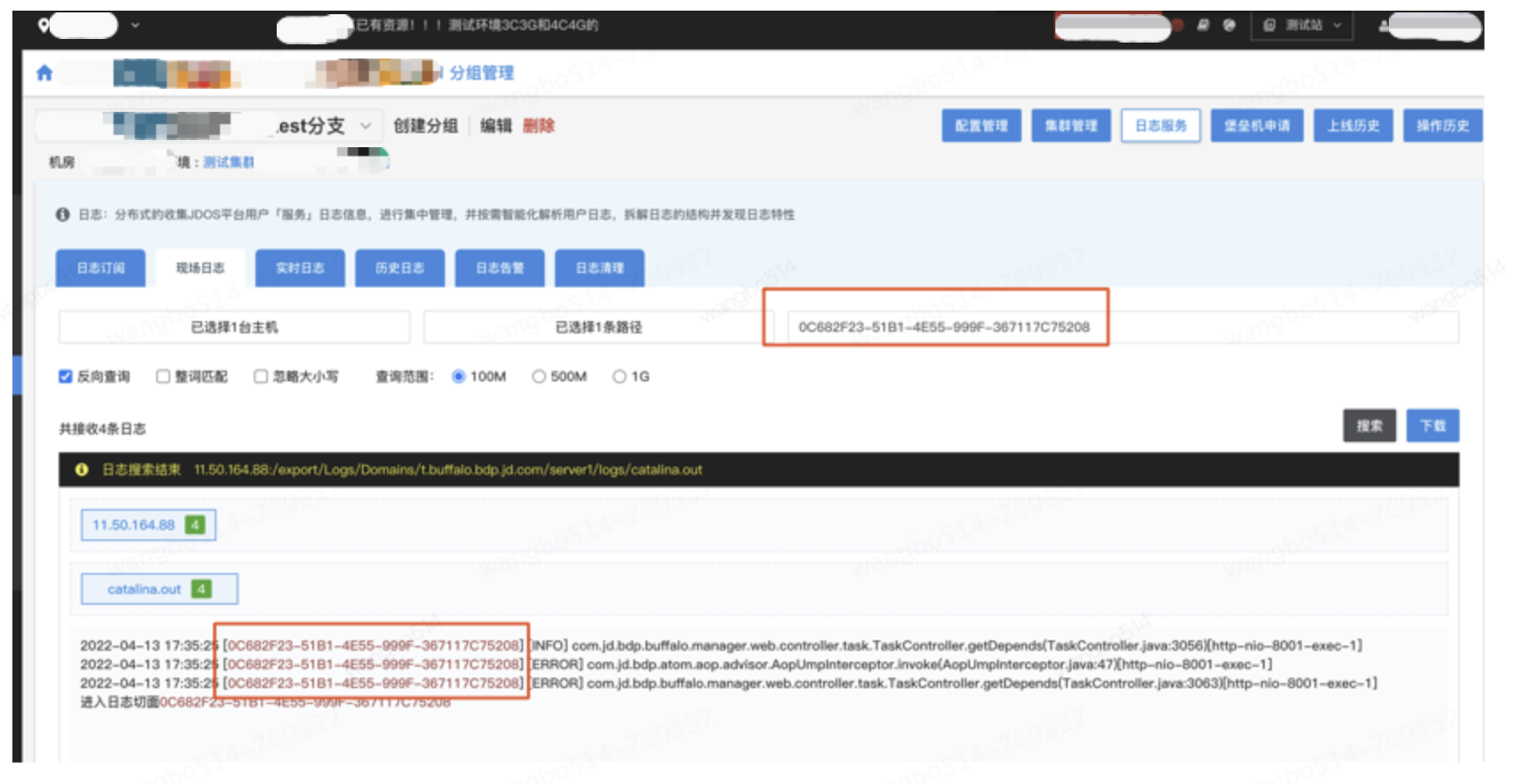
LOGBOOK效果图:
2.关键思路
2.1.MDC
日志追踪目标是每次请求级别的,也就是说同一个接口的每次请求,都应该有不同的traceId。 每次接口请求,都是一个单独的线程,所以自然我们很容易考虑到通过ThreadLocal实现上述需求。 考虑到log4j本身已经提供了类似的功能MDC,所以直接使用MDC进行实现。
关于MDC的简述
MDC(Mapped Diagnostic Context)是一个映射,用于存储运行上下文的特定线程的上下文数据。因此,如果使用log4j进行日志记录,则每个线程都可以拥有自己的MDC,该MDC对整个线程是全局的。属于该线程的任何代码都可以轻松访问线程的MDC中存在的值。
API说明:
•clear() => 移除所有MDC •get (String key) => 获取当前线程MDC中指定key的值 •getContext() => 获取当前线程MDC的MDC •put(String key, Object o) => 往当前线程的MDC中存入指定的键值对 •remove(String key) => 删除当前线程MDC中指定的键值对 。
3.目标
1.需要一个全服务唯一的id,即traceId,如何保证? 2.traceId如何在服务内部传递? 3.traceId如何在服务间传递? 4.traceId如何在多线程中传递?
4、实现方式
4.1 需要一个全服务唯一的id,即traceId,如何保证?
使用最简单的uuid即可。复杂的话可以配置redis,雪花算法等方式。本次分享选最简单uuid生成traceId的方式。
4.2 traceId如何在服务间传递?
1)在xml 的日志格式中添加 %X{traceId} 配置。
2)新增拦截器,拦截所有请求,从 header 中获取 traceId 然后放到 MDC 中,如果没有获取到,则直接用 UUID 生成一个。
| @Slf4j @Component public class LogInterceptor implements HandlerInterceptor { private static final String TRACE_ID = "traceId"; @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception arg3) throws Exception { } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView arg3) throws Exception { } @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { String traceId = request.getHeader(TRACE_ID); if (StringUtils.isEmpty(traceId)) { MDC.put(TRACE_ID, UUID.randomUUID().toString()); } else { MDC.put(TRACE_ID, traceId); } return true; } } |
3)配置拦截器
| @Configuration public class WebConfig implements WebMvcConfigurer { @Resource private LogInterceptor logInterceptor; @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(logInterceptor) .addPathPatterns("/**"); } } |
4.3 traceId如何在服务间传递?
封装Http工具类,把traceId加入头中,带到下一个服务。
| @Slf4j public class HttpUtils { public static String get(String url) throws URISyntaxException { RestTemplate restTemplate = new RestTemplate(); MultiValueMap<String, String> headers = new HttpHeaders(); headers.add("traceId", MDC.get("traceId")); URI uri = new URI(url); RequestEntity<?> requestEntity = new RequestEntity<>(headers, HttpMethod.GET, uri); ResponseEntity<String> exchange = restTemplate.exchange(requestEntity, String.class); if (exchange.getStatusCode().equals(HttpStatus.OK)) { log.info("send http request success"); } return exchange.getBody(); } } |
4.4 traceId如何在多线程中传递?
spring项目也使用到了很多线程池,比如@Async异步调用,zookeeper线程池、kafka线程池等。不管是哪种线程池都大都支持传入指定的线程池实现,
拿@Async举例:
原理为:
MDC底层使用TreadLocal来实现,那根据TreadLocal的特点,它是可以让我们在同一个线程中共享数据的,但是往往我们在业务方法中,会开启多线程来执行程序,这样的话MDC就无法传递到其他子线程了。这时,我们需要使用额外的方法来传递存在TreadLocal里的值。
MDC提供了一个叫getCopyOfContextMap的方法,很显然,该方法就是把当前线程TreadLocal绑定的Map获取出来,之后就是把该Map绑定到子线程中的ThreadLocal中了
改造Spring的异步线程池,包装提交的任务。
| @Slf4j @Component public class TraceAsyncConfigurer implements AsyncConfigurer { @Override public Executor getAsyncExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(8); executor.setMaxPoolSize(16); executor.setQueueCapacity(100); executor.setThreadNamePrefix("async-pool-"); executor.setTaskDecorator(new MdcTaskDecorator()); executor.setWaitForTasksToCompleteOnShutdown(true); executor.initialize(); return executor; } @Override public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() { return (throwable, method, params) -> log.error("asyc execute error, method={}, params={}", method.getName(), Arrays.toString(params)); } public static class MdcTaskDecorator implements TaskDecorator { @Override public Runnable decorate(Runnable runnable) { Map<String, String> contextMap = MDC.getCopyOfContextMap(); return () -> { if (contextMap != null) { MDC.setContextMap(contextMap); } try { runnable.run(); } finally { MDC.clear(); } }; } } } public class MDCLogThreadPoolExecutor extends ThreadPoolExecutor { public MDCLogThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue); } @Override public void execute(Runnable command) { super.execute(MDCLogThreadPoolExecutor.executeRunable(command, MDC.getCopyOfContextMap())); } @Override public Future<?> submit(Runnable task) { return super.submit(MDCLogThreadPoolExecutor.executeRunable(task, MDC.getCopyOfContextMap())); } @Override public <T> Future<T> submit(Callable<T> callable) { return super.submit(MDCLogThreadPoolExecutor.submitCallable(callable,MDC.getCopyOfContextMap())); } public static Runnable executeRunable(Runnable runnable ,Map<String,String> mdcContext){ return new Runnable() { @Override public void run() { if (mdcContext == null) { MDC.clear(); } else { MDC.setContextMap(mdcContext); } try { runnable.run(); } finally { MDC.clear(); } } }; } private static <T> Callable<T> submitCallable( Callable<T> callable, Map<String, String> context) { return () -> { if (context == null) { MDC.clear(); } else { MDC.setContextMap(context); } try { return callable.call(); } finally { MDC.clear(); } }; } } |
接下来需要对ThreadPoolTaskExecutor的方法进行重写:
| package com.example.demo.common.threadpool; import com.example.demo.common.constant.Constants; import lombok.extern.slf4j.Slf4j; import org.slf4j.MDC; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import java.util.Map; import java.util.UUID; import java.util.concurrent.Callable; import java.util.concurrent.Future; /** * MDC线程池 * 实现内容传递 * * @author wangbo * @date 2021/5/13 */ @Slf4j public class MdcTaskExecutor extends ThreadPoolTaskExecutor { @Override public <T> Future<T> submit(Callable<T> task) { log.info("mdc thread pool task executor submit"); Map<String, String> context = MDC.getCopyOfContextMap(); return super.submit(() -> { T result; if (context != null) { //将父线程的MDC内容传给子线程 MDC.setContextMap(context); } else { //直接给子线程设置MDC MDC.put(Constants.LOG_MDC_ID, UUID.randomUUID().toString().replace("-", "")); } try { //执行任务 result = task.call(); } finally { try { MDC.clear(); } catch (Exception e) { log.warn("MDC clear exception", e); } } return result; }); } @Override public void execute(Runnable task) { log.info("mdc thread pool task executor execute"); Map<String, String> context = MDC.getCopyOfContextMap(); super.execute(() -> { if (context != null) { //将父线程的MDC内容传给子线程 MDC.setContextMap(context); } else { //直接给子线程设置MDC MDC.put(Constants.LOG_MDC_ID, UUID.randomUUID().toString().replace("-", "")); } try { //执行任务 task.run(); } finally { try { MDC.clear(); } catch (Exception e) { log.warn("MDC clear exception", e); } } }); } } 然后使用自定义的重写子类MdcTaskExecutor来实现线程池配置: /** * 线程池配置 * * @author wangbo * @date 2021/5/13 */ @Slf4j @Configuration public class ThreadPoolConfig { /** * 异步任务线程池 * 用于执行普通的异步请求,带有请求链路的MDC标志 */ @Bean public Executor commonThreadPool() { log.info("start init common thread pool"); //ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); MdcTaskExecutor executor = new MdcTaskExecutor(); //配置核心线程数 executor.setCorePoolSize(10); //配置最大线程数 executor.setMaxPoolSize(20); //配置队列大小 executor.setQueueCapacity(3000); //配置空闲线程存活时间 executor.setKeepAliveSeconds(120); //配置线程池中的线程的名称前缀 executor.setThreadNamePrefix("common-thread-pool-"); //当达到最大线程池的时候丢弃最老的任务 executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardOldestPolicy()); //执行初始化 executor.initialize(); return executor; } /** * 定时任务线程池 * 用于执行自启动的任务执行,父线程不带有MDC标志,不需要传递,直接设置新的MDC * 和上面的线程池没啥区别,只是名字不同 */ @Bean public Executor scheduleThreadPool() { log.info("start init schedule thread pool"); MdcTaskExecutor executor = new MdcTaskExecutor(); executor.setCorePoolSize(10); executor.setMaxPoolSize(20); executor.setQueueCapacity(3000); executor.setKeepAliveSeconds(120); executor.setThreadNamePrefix("schedule-thread-pool-"); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardOldestPolicy()); executor.initialize(); return executor; } } |
5、扩展点
5.1 JSF接口日志追踪的应用
项目中也运用到了大量的jsf接口,我们其实可以按照上述的思路进行服务间的传递。
调用端:
| // todo 不能在filter里面这么用 RpcContext.getContext().setAttachment("user", "zhanggeng"); RpcContext.getContext().setAttachment(".passwd", "11112222"); // "."开头的对应上面的hide=true xxxService.yyy();// 再开始调用远程方法 // 重要:下一次调用要重新设置,之前的属性会被删除 RpcContext.getContext().setAttachment("user", "zhanggeng"); RpcContext.getContext().setAttachment(".passwd", "11112222"); // "."开头的对应上面的hide=true xxxService.zzz();// 再开始调用远程方法 |
Provider端:
1.filter中直接获取,包括标记为hiden的参数。通过Rpccontext无法获取。 2.| String consumerToken = (String) invocation.getAttachment(".passwd"); |
| String user = RpcContext.getContext().getAttachment("user"); |
tips:调用链中的隐式传参
注意:在调用链例如A–>B–>C,A和B都要隐私传参的时候,由于是同一个线程,会出现数据污染。例如A发参数P1给B,B收到请求拿到P1同时要发参数P2给C,那么C会直接拿到P1,P2。 这种情况,就要求B收到P1,然后设置P2调用C之前,要求自己清空上下文数据(RpcContext.getContext().clearAttachments();)
5.2 接口返回值应用
我们知道了MDC的好处后,其实在用户从第一时间调用请求时候,我们其实可以将有误的请求增加tarceid一并返回,这样用户反馈时候,我们直接用traceid就可以全链路追踪到所有请求的情况了,做到信息的闭环。
效果图:
6、备注:
各位知道了日志追踪的原理,其实很多应用场景可以继续补充,例如MQ,JD的其他中间件也可以应用相同原理进行追踪。其实,当了解了底层的原理后,我们其实就可以了解到JD监控中间件PFinder监控等中间件是如何做的了,本次由于时间情况,就不进行扩展了,各位可以线下去了解Skywalking 分布式链路追踪系统,就可以知道,万变不离其宗。
标签:traceId,return,MDC,链路,线程,executor,日志,public,追踪 From: https://www.cnblogs.com/Jcloud/p/18107888