训练大型语言模型(llm),即使是那些“只有”70亿个参数的模型,也是一项计算密集型的任务。这种水平的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(LoRA)等参数高效方法,可以在消费级gpu上对大量模型进行微调。
GaLore是一种新的方法,它不是通过直接减少参数的数量,而是通过优化这些参数的训练方式来降低VRAM需求,也就是说GaLore是一种新的模型训练策略,可让模型使用全部参数进行学习,并且比LoRA更省内存。
GaLore将这些梯度投影到低秩空间上,显著减少了计算负荷,同时保留了训练所需的基本信息。与传统的优化器在反向传播后同时更新所有层的方法不同,GaLore在反向传播期间实现逐层更新。这种方法进一步减少了整个训练过程中的内存占用。
就像LoRA一样,GaLore可以让我们在具有24 GB VRAM的消费级GPU上微调7B模型。结果模型的性能与全参数微调相当,并且似乎优于LoRA。
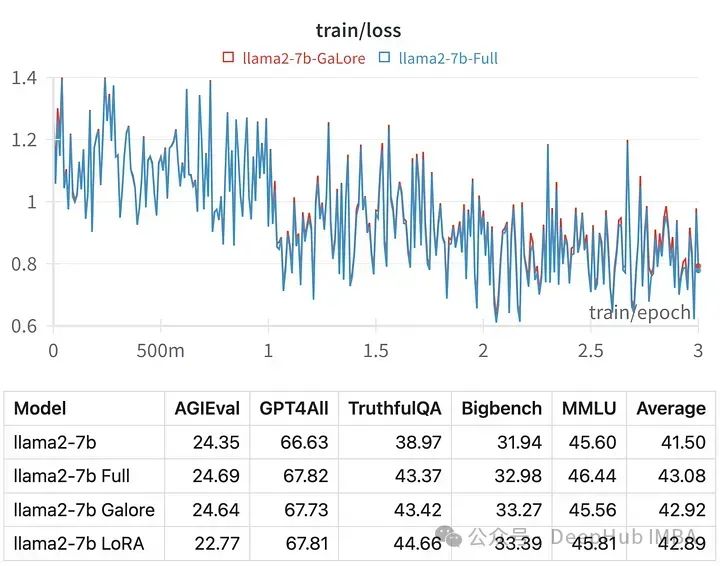
优于目前Hugging Face还没有官方代码,我们就来手动使用论文的代码进行训练,并与LoRA进行对比
https://avoid.overfit.cn/post/0b15de8db27040f0abcaa7e554b0b993
标签:训练,模型,GaLore,调优,参数,LLM,GPU,LoRA From: https://www.cnblogs.com/deephub/p/18093779