有了开窗函数,让我们做统计方便很多。
row_number(),sum,等常规用法,便不在这里讲。
我们从一个问题开始
with abc as
(
select 1 as id union all
select 2 union all
select 3 union all
select 4
)
select id,
FIRST_VALUE(id) over(order by id ) as firstid,
LAST_VALUE(id) over(order by id) as lastid
from abc
看结果 明显第二列我的原意是想取得最后一行的值。即为4
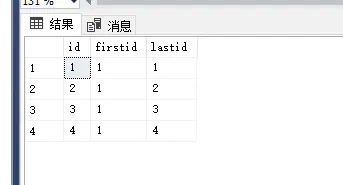
FIRST_VALUE 一看就明白了。但last_value 为什么就是当前行的值呢?明明该是4才对啊。
原因在于这两个函数 可以用rows 指定作用域。 而默认的作用域是
RANGE UNBOUNDED PRECEDING AND CURRENT ROW
就是说从窗口的第一行到当前行。 所以last_value 最后一行肯定是当前行了。
知道原因后,只需要改掉行的作用域就可以了。
with abc as
(
select 1 as id union all
select 2 union all
select 3 uno union all
select 4
)
select id,
FIRST_VALUE(id) over(order by id ) as firstid,
LAST_VALUE(id) over(order by id rows between UNBOUNDED PRECEDING AND UNBOUNDED following ) as lastid
from abc
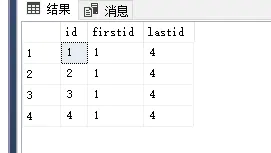
rows 子句的一些关键字
UNBOUNDED PRECEDING 窗口函数第一行
UNBOUNDED following 窗口函数最后一行
CURRENT ROW 当前行
n PRECEDING 当前行的前几行
所以用开窗函数,一定要注意行的作用域
我们再继续作用域
那窗口函数的行作用域到底哪些呢?
排名函数
rank、ntile、dense_rank、row_number 行的作用域都是全结果集,且不支持指定 rows_range_clause
聚合函数
count、sum,count,max,min等 都支持指定rows_range_clause 但如果不指定order by 则是全表,指定了order by 则行范围默认就是 RANGE UNBOUNDED PRECEDING AND CURRENT ROW
;with abc as
(
select 0 as id union all
select 1 union all
select 2 union all
select 3
)
select id,
sum(id) over(),
count(id)over(),
sum(id) over(order by id),
count(id)over(order by id),
sum(id) over(order by id rows between UNBOUNDED PRECEDING AND UNBOUNDED following ),
count(id)over(order by id rows between UNBOUNDED PRECEDING AND UNBOUNDED following )
from abc
分析函数
lag,lead 都不支持 指定rows_range_clause
LAST_VALUE 、FIRST_VALUE 默认就是 RANGE UNBOUNDED PRECEDING AND CURRENT ROW
最后我们再分析一下 rows与range的区别
下面的显示代码为 SQL Server的
declare @t table(ord int,billdate varchar(10),add_value int,dec_value int,end_value int)
insert into @t
select 1,'期初',0,0,100 union all
select 2,'2021-01-01',100,0,0 union all
select 3,'2021-01-02',0,100,0 union all
select 4,'2021-01-03',0,100,0 union all
select 5,'2021-01-04',100,0,0 union all
select 5,'2021-01-04',100,0,0
select *,sum(add_value -dec_value + end_value ) over(order by ord) as new_end
from @t a
end_value 这个字段要实现流水账的功能,即 end_value = 第一行期初行 end_value + add_value - decvalue
执行结果如图
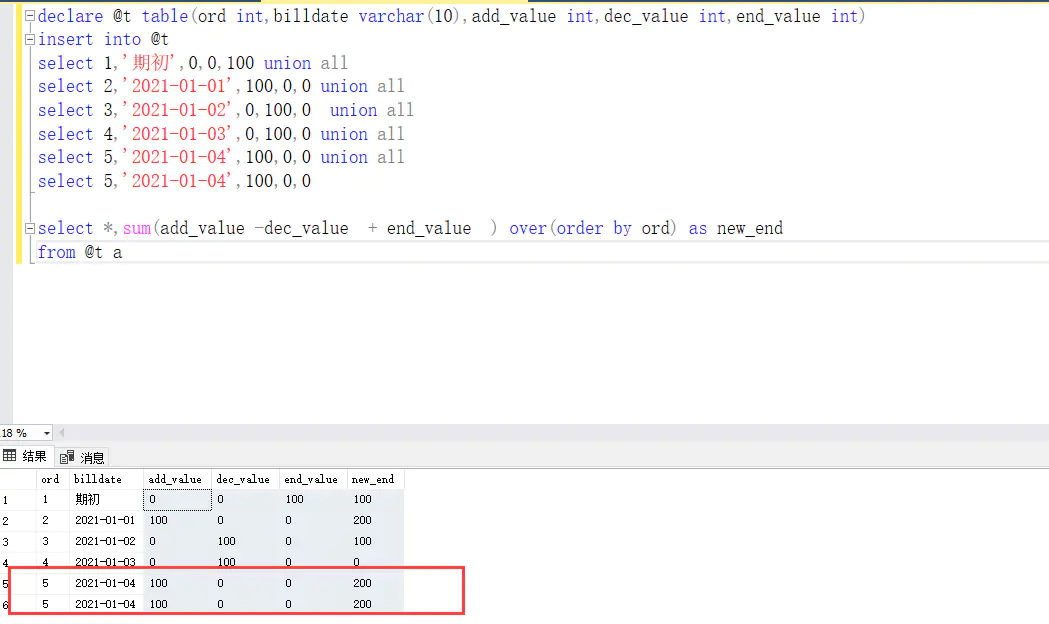
可以看到第5行 NEW_END该为100 而不是200
上面说过。 order by 没有显示给出行的作用域范围。则默认为
RANGE between UNBOUNDED PRECEDING AND CURRENT ROW
我改为显示指定 并且用ROWS关键字
declare @t table(ord int,billdate varchar(10),add_value int,dec_value int,end_value int)
insert into @t
select 1,'期初',0,0,100 union all
select 2,'2021-01-01',100,0,0 union all
select 3,'2021-01-02',0,100,0 union all
select 4,'2021-01-03',0,100,0 union all
select 5,'2021-01-04',100,0,0 union all
select 5,'2021-01-04',100,0,0
select *,sum(add_value -dec_value + end_value ) over(order by ord rows between UNBOUNDED PRECEDING AND CURRENT ROW) as new_end
from @t a
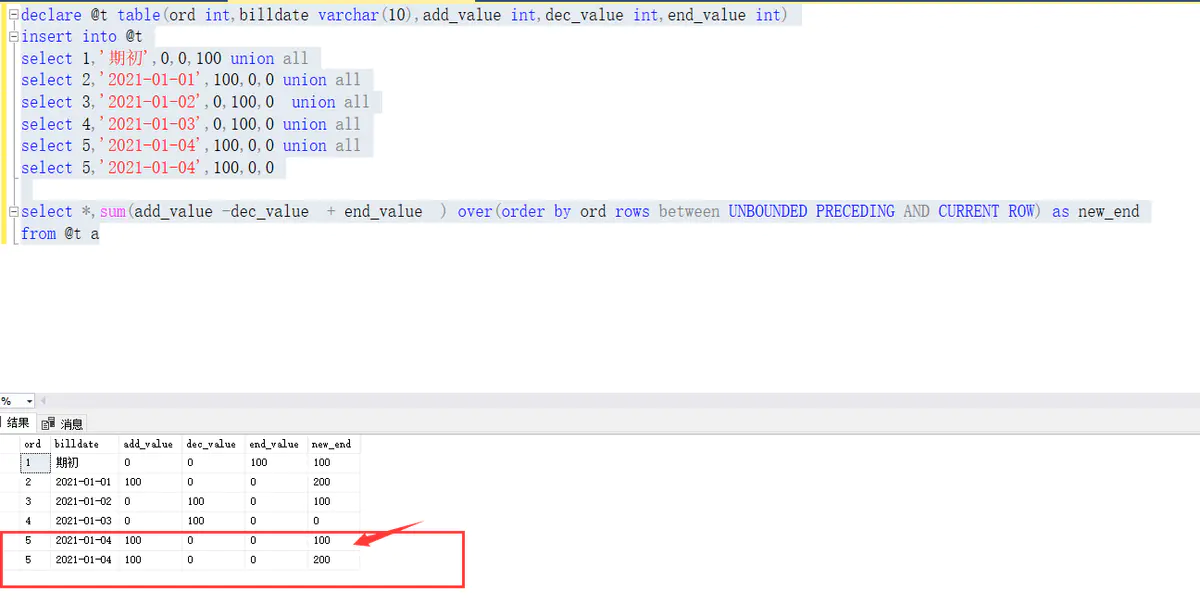
可以看到第5行 new_end结果是我期望的100了。
两个例子可以看出 range 关键字,是以 order by 字段的值 做为基准的。因为最后两行的ord 都 = 5 所以就认为是一样的。
而rows 是行号为基准的。
这就是 rows 与 range的区别
n following 当前行的后几行
转自https://www.modb.pro/db/112099?utm_source=index_ai
标签:last,进阶,union,value,order,100,id,select From: https://www.cnblogs.com/skynight/p/18090181