标签:请求 gRPC 实践 客户端 使用 序列化 ProtoBuf
目录介绍
- 01.gRPC学习背景
- 1.1 为什么要学RPC
- 1.2 RPC是什么
- 1.3 网络库收益分析
- 1.4 学习计划说明
- 1.5 学习问题思考
- 02.ProtoBuf的介绍
- 2.1 ProtoBuf是什么
- 2.2 ProtoBuf和json
- 2.3 ProtoBuf问题思考
- 2.4 ProtoBuf特点
- 2.5 ProtoBuf存储格式
- 2.6 ProtoBuf优缺点
- 2.7 创建proto文件
- 2.8 ProtoBuf核心思想
- 2.9 转化为Json数据
- 2.10 ProtoBuf总结
- 2.11 Proto遇到的坑
- 03.gRPC实践的介绍
- 3.1 gRPC简单介绍
- 3.2 为何要用gRPC
- 3.3 gRPC定义服务
- 3.4 gRPC生成代码
- 3.5 gRPC如何使用
- 3.6 同步和异步操作
- 3.7 gRPC一些操作
- 3.8 gRPC设置超时
- 3.9 gRPC问题解决
- 3.10 理解gRPC协议
- 04.gRPC通信实践
- 4.1 gRPC通信技术点
- 4.2 Channel创建和复用
- 4.3 如何添加公参
- 4.4 请求/响应的读写操作
- 4.5 网络日志打印
- 4.6 如何做网络缓存
- 4.7 如何请求域名
- 4.8 如何处理错误和异常
- 4.9 设置CA证书校验
- 4.10 如何保证安全性
- 4.11 如何兼容OkHttp
- 05.ProtoBuf核心原理
- 5.1 ProtoBuf数据结构
- 5.2 ProtoBuf编码方式
- 5.3 充分理解TLV设计
- 5.4 TLV设计中Type原理
- 5.5 TLV设计中Length原理
- 06.gRPC核心设计思想
- 6.1 Channel核心设计思想
- 6.2 Stub核心设计思想
- 6.3 NameResolver核心设计思想
- 6.4 gRPC网络框架设计层次
- 6.5 gRPC包设计说明
- 07.gRPC核心原理
- 7.1 gRPC核心设计思路
- 7.2 NameResolver域名解析
- 7.3 Channel层设计原理
- 7.4 Stub层设计原理
01.gRPC学习背景
1.1 为什么要学gRPC
- 在Android开发中,使用gRPC可以带来以下好处:
- 高效性:gRPC使用ProtoBuf作为默认的序列化协议,比JSON和XML等其他序列化协议更高效,可以减少网络带宽和CPU使用率。
- 可靠性:gRPC使用HTTP/2协议作为底层传输协议,可以提供更可靠的连接和流控制,同时支持TLS加密和认证。
- 易于使用:gRPC提供了自动生成代码的工具,可以方便地生成客户端和服务器端的代码,同时提供了丰富的文档和示例。
- 可扩展性:gRPC支持多种类型的RPC,包括简单RPC、流式RPC和双向流式RPC,可以满足不同的应用场景和需求。
- 项目demo地址:
1.2 RPC是什么
- rpc概述
- RPC(Remote Procedure Call)-远程过程调用,他是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
- RPC 协议包括序列化、协议编解码器和网络传输栈。
- gRPC介绍
- gRPC 一开始由 Google 开发,是一款语言中立、平台中立、开源的远程过程调用(RPC)系统。
- rpc和http区别
- RPC 和 HTTP都是微服务间通信较为常用的方案之一,其实RPC 和 HTTP 并不完全是同一个层次的概念,它们之间还是有所区别的。
- 1.RPC 是远程过程调用,其调用协议通常包括序列化协议和传输协议。序列化协议有基于纯文本的 XML 和 JSON、有的二进制编码的ProtoBuf。传输协议是指其底层网络传输所使用的协议,比如 TCP、HTTP。
- 2.可以看出HTTP是RPC的传输协议的一个可选方案,比如说 gRPC 的网络传输协议就是 HTTP。HTTP 既可以和 RPC 一样作为服务间通信的解决方案,也可以作为 RPC 中通信层的传输协议(此时与之对比的是 TCP 协议)。
1.3 网络库收益分析
- 使用gRPC作为网络方案可以带来以下收益:
- 使用gRPC作为网络方案可以带来高效性、跨平台和语言、可靠性、易于使用和可扩展性等收益。
- 同时可以减少手动编写代码的工作量,提高开发效率。
1.4 学习计划说明
- 基础入门掌握
- 1.完成ProtoBuf基础了解和学习【3h】【完成】
- 2.尝试ProtoBuf和json效率测试【3h】【完成】
- 3.gRPC环境配置和官方文档和Demo学习【6h】【完成】
- 4.熟练使用gRPC,比如将玩Android接口,用gRPC方式去请求【8h】【进行中】
- 5.gRPC的四种通信模式【4h】【未开始】
- 原理解读说明
- 1.理解gRPC的基础通信原理【4h】【进行中】
- 2.gRpc网络请求的核心设计思路【4h】【未开始】
- 3.Proto文件如何在编译期间生成java文件原理研究【4h】【完成】
- 4.Proto有哪些缺点,如何优化,跟json,xml空间上性能分析【4h】【完成】
- 技术精进计划
- 1.理解各种网络请求库的设计,性能对比,各自偏向解决问题【4h】【完成】
- 2.通透理解protoBuf实现数据缓冲的原理,谷歌如何做性能优化的反思【4h】【完成】
- 3.讲出来,实践写Demo,内化。和同事讨论关键技术点【8h】【完成】
1.5 学习问题思考
- gRPC框架问题思考
- gRPC主要是解决什么问题,其设计初衷是什么。该框架设计的总思想是什么样的?
- gRPC如何请求网络,解析流程是什么,请求过程是怎样的,如何处理解析异常和请求异常的逻辑?
- gRPC创建通道的原理是什么,什么场景下需要做通道复用?四种通信模式的设计原理是什么,分别用在什么场景?
- Proto编码传输协议问题思考
- ProtoBuf传输协议是如何设计的?其设计初衷是什么?和序列化json有什么区别,两者的效率有何不同?有何优缺点?
- 网络请求实践中问题思考
- 如何添加网络拦截器,监听请求状态?拦截器的工作原理是什么?
- 同步和异常请求分别是如何使用,其原理是什么,如何处理请求超时的逻辑?
- Stub相关类是如何在编译器生成的,网络请求的框架层次如何理解?
02.ProtoBuf的介绍
2.1 ProtoBuf是什么
- ProtoBuf简单介绍
- 它是Google公司发布的一套开源编码规则,基于二进制流的序列化传输,可以转换成多种编程语言,几乎涵盖了市面上所有的主流编程语言,是目前公认的非常高效的序列化技术。
- ProtoBuf是一种灵活高效可序列化的数据协议
- 相于XML,具有更快、更简单、更轻量级等特性。支持多种语言,只需定义好数据结构,利用ProtoBuf框架生成源代码,就可很轻松地实现数据结构的序列化和反序列化。
- 一旦需求有变,可以更新数据结构,而不会影响已部署程序。
- ProtoBuf的Github主页:
2.2 ProtoBuf和json
- ProtoBuf就好比信息传输的媒介
- 如果用一句话来概括ProtoBuf和JSON的区别的话,那就是:对于较多信息存储的大文件而言,ProtoBuf的写入和解析效率明显高很多,而JSON格式的可读性明显要好。
- 如何对json和ProtoBuf进行效率测试
- 核心思路:创建同样数据内容的对象。然后将对象序列化成字节数组,获取字节数据大小,最后又将字节反序列化成对象。
- 效率对比:主要是比较序列化耗时,序列化之后的数据大小,以及反序列化的耗时。注意:必须保证创建数据内容是一样的。
- 测试案例分析如下
2023-05-09 09:31:49.699 23442-23442/com.yc.appgrpc E/Test效率测试:: Gson 序列化耗时:14
2023-05-09 09:31:49.699 23442-23442/com.yc.appgrpc E/Test效率测试:: Gson 序列化数据大小:188
2023-05-09 09:31:49.701 23442-23442/com.yc.appgrpc E/Test效率测试:: Gson 反序列化耗时:2
2023-05-09 09:31:49.701 23442-23442/com.yc.appgrpc E/Test效率测试:: Gson 数据:{"persons":[{"id":1,"name":"张三","phones":[{"number":"110","type":"HOME"}]},{"id":2,"name":"李四","phones":[{"number":"130","type":"MOBILE"}]},{"id":3,"name":"王五","phones":[{}]}]}
2023-05-09 09:31:49.720 23442-23442/com.yc.appgrpc E/Test效率测试:: protobuf 序列化耗时:4
2023-05-09 09:31:49.720 23442-23442/com.yc.appgrpc E/Test效率测试:: protobuf 序列化数据大小:59
2023-05-09 09:31:49.722 23442-23442/com.yc.appgrpc E/Test效率测试:: protobuf 反序列化耗时:2
2023-05-09 09:31:49.725 23442-23442/com.yc.appgrpc E/Test效率测试:: protobuf 数据:# com.yc.appgrpc.AddressBookProto$AddressBook@83d0213a
people {
id: 1
name: "\345\274\240\344\270\211"
phones {
number: "110"
type: HOME
type_value: 1
}
}
people {
id: 2
name: "\346\235\216\345\233\233"
phones {
number: "120"
}
}
people {
id: 3
name: "\347\216\213\344\272\224"
phones {
number: "130"
}
}
- 测试结果说明
- 空间效率:Json:188个字节;ProtoBuf:59个字节
- 时间效率:Json序列化:14ms,反序列化:2ms;ProtoBuf序列化:4ms 反序列化:2ms
- 可以得出结论
- 通过以上的时间效率和空间效率,可以看出protoBuf的空间效率是JSON的2-5倍,时间效率要高,对于数据大小敏感,传输效率高的模块可以采用protoBuf库。
2.3 ProtoBuf问题思考
- ProtoBuf 是一个小型的软件框架,也可以称为protocol buffer 语言,带着疑问会发现Proto 有很多需要了解:
- Proto 文件书写格式,关键字package、option、Message、enum 等含义和注意点是什么?
- 消息等嵌套如何使用?实现的原理?
- Proto 文件对于不同语言的编译,和产生的obj 文件的位置?
- Proto 编译后的cc 和java 文件中不同函数的意义?
- 如何实现.proto 到.java、.h、.cc 等文件?
- 数据包的组成方式、repeated 的含义和实现?
- Proto 在service和client 的使用,在java 端和native 端如何使用?
- 与xml 、json 等相比时间、空间上的比较如何?
2.4 ProtoBuf特点
2.5 ProtoBuf存储格式
- 如何理解TLV结构:TLV全称为Type_Length_Value
- Type块并不是只表示数据类型,其中数据编号也在Tag块中,Tag的生成规则如下:Tag块的后3位表示数据类型,其他位表示数据编号。Tag中1-15编号只占用1个字节,所以确保编号中1-15为常用的,减少数据大小。
- Length不一定有,依据Tag确定,例如数值类型的数据,使用VarInts不需要长度,就只有Tag-Value,string类型的数据就必须是Tag-Length-Value
- Value:消息字段经过编码后的值
2.6 ProtoBuf优缺点
- ProtoBuf优点
- 性能:1.体积小,序列化后,数据大小可缩小3-10倍;2.序列化速度快,比XML和JSON快20-100倍;3.传输速度快,因为体积小,传输起来带宽和速度会有优化
- 使用优点:1.使用简单,proto编译器自动进行序列化和反序列化;2.维护成本低,多平台仅需维护一套对象协议文件(.proto);3.向后兼容性(扩展性)好,不必破坏旧数据格式就可以直接对数据结构进行更新;4.加密性好,Http传输内容抓包只能看到字节
- 使用范围:跨平台、跨语言(支持Java, Python, Objective-C, C+, Dart, Go, Ruby, and C#等),可扩展性好
- ProtoBuf缺点
- 功能缺点:不适合用于对基于文本的标记文档(如HTML)建模,因为文本不适合描述数据结构
- 通用性较差:json、xml已成为多种行业标准的编写工具,而ProtoBuf只是Google公司内部的工具
- 自解耦性差:以二进制数据流方式存储(不可读),需要通过.proto文件才能了解到数据结构
- 阅读性差:.proto文件去生成相应的模型,而生成出来的模型无论从可读性还是易用性上来说都是较差的。并且生成出来的模型文件是不允许修改的(protoBuf官方建议),如果有新增字段,都必须依赖于.proto文件重新进行生成。
- .protoBuf会导致客户端的体积增加许多
- protoBuf所生成的模型文件十分巨大,略复杂一些的数据可以达到1MB,请注意,1MB只是一个模型文件。
- 导致该问题的原因是,protoBuf为了实现对传输数据的信息补全(可以参看编码原理),将编码、解码的代码都整合到了每一个独立的模型文件中,因此导致代码有非常大的冗余
2.7 创建proto文件
2.8 ProtoBuf核心思想
2.9 转化为Json数据
2.10 ProtoBuf总结
- Protocol Buffer 利用 varint 原理压缩数据以后,二进制数据非常紧凑,option 也算是压缩体积的一个举措。
- 所以 pb 体积更小,如果选用它作为网络数据传输,势必相同数据,消耗的网络流量更少。但是并没有压缩到极限,float、double 浮点型都没有压缩。
- Protocol Buffer 比 JSON 和 XML 少了 {、}、: 这些符号,体积也减少一些。再加上 varint 压缩,gzip 压缩以后体积更小!
- Protocol Buffer 是 Tag - Value (Tag - Length - Value)的编码方式的实现,减少了分隔符的使用,数据存储更加紧凑。
- Protocol Buffer 另外一个核心价值在于提供了一套工具,一个编译工具,自动化生成 get/set 代码。
- 简化了多语言交互的复杂度,使得编码解码工作有了生产力。
- Protocol Buffer 不是自我描述的,离开了数据描述 .proto 文件,就无法理解二进制数据流。这点即是优点,使数据具有一定的“加密性”,也是缺点,数据可读性极差。所以 Protocol Buffer 非常适合内部服务之间 RPC 调用和传递数据。
2.11 Proto遇到的坑
- 字段顺序问题:proto 使用字段的编号来标识字段,而不是使用字段的名称。
- 因此,如果更改了字段的顺序,可能会导致与旧版本的 proto 不兼容。为了避免这个问题,建议在 proto 文件中为字段指定唯一的编号,并避免在后续版本中更改字段的编号。
- 字段类型问题:proto 提供了多种字段类型,如 int32、string、bool 等。
- 确保选择正确的字段类型,以适应你的数据需求。如果你更改了字段的类型,可能需要进行相应的代码更改和数据迁移。
03.gRPC实践的介绍
3.1 gRPC简单介绍
- gRPC的简单介绍
- gRPC是一个高性能、开源和通用的RPC框架,面向移动和HTTP/2设计。目前提供C、Java和Go语言版本,分别是grpc、grpc-java、grpc-go。
- gRPC基于HTTP/2标准设计,带来诸如双向流、流控、头部压缩、单TCP连接上的多复用请求等特性。这些特性使得其在移动设备上表现更好,更省电和节省空间占用。
- gRPC由google开发,是一款语言中立、平台中立、开源的远程过程调用系统。
- gRPC(Java)的Github主页:
- gRPC的产生动机和设计原则
3.2 为何要用gRPC
- 为什么要使用ProtoBuf和gRPC
- 简而言之,ProtoBuf就好比信息传输的媒介,类似我们常用的json,而grpc则是传输他们的通道,类似我们常用的socket。
- gRPC被谷歌推荐
- 作为google公司极力推荐的分布式网络架构,基于HTTP2.0标准设计,使用用ProtoBuf作为序列化工具,在移动设备上表现更好,更省电和节省空间占用。
- 像这种国外的开源框架,还是建议大家先直接阅读官方文档,再看国内的文章,这样才不容易被误导。
3.3 gRPC定义服务
3.4 gRPC生成代码
3.5 gRPC如何使用
- 大概的实践步骤如下所示
- 第一步:添加项目中build中的插件配置。添加:classpath "com.google.protobuf:protobuf-gradle-plugin:0.9.1"
- 第二步:在App模块下添加plugin插件配置,添加基础库依赖等操作。还要做一些proto配置。具体看app模块下的build.gradle文件。
- 第三步:在main目录下创建proto目录,创建一个和java目录同级的proto文件夹,这样做是因为在build.gradle文件中指定了去proto文件夹中找到*.proto文件,并且编译成java代码。
- 第四步:编译项目,在build目录(build->generated->source->proto->debug)下看到对应的java文件
- 第五步:开始使用gRPC去做网络请求操作。具体可以看:HelloWorldActivity
- 问题思考一下
- 能否把生成的代码拷贝出来(如果proto不经常变的情况),把插件禁用掉,避免每次都生成???
- 如何使用gRPC去做网络请求
//构建Channel
channel = ManagedChannelBuilder.forAddress(host, port).usePlaintext().build();
//构建服务请求API代理
GreeterGrpc.GreeterBlockingStub stub = GreeterGrpc.newBlockingStub(channel);
//构建请求实体,HelloRequest是自动生成的实体类
HelloRequest request = HelloRequest.newBuilder().setName(message).build();
//进行请求并且得到响应数据
HelloReply reply = stub.sayHello(request);
//得到请求响应的数据
String replyMessage = reply.getMessage();
- 在这个调用代码中,其核心的流程,完成了grpc客户端调用服务器端最重要的三个步骤
- 创建连接到远程服务器的 channel
- 构建使用该channel的客户端stub
- 调用服务方法,执行RPC调用,发出请求并且拿到响应数据
3.6 同步和异步操作
3.7 gRPC一些操作
- RPC 超时
- gRPC 允许客户指定他们愿意等待 RPC 完成多长时间,然后再以错误终止 RPC。在server端,可以查询特定 RPC 是否已过时,或者需要多少时间才能完成 RPC。
- RPC 终止
- 在 gRPC 中,客户端和服务器都对调用的成功做出独立和本地的判断,它们的结论可能不一致。
- 这意味着,例如,您可能有一个 RPC 在服务器端成功完成(“我已经发送了我所有的响应!”)但在客户端失败(“响应到达前我已经截至了!”)。
- RPC 取消
- 客户端或服务器可以随时取消 RPC。RPC会立即响应取消操作而终止,以便不再进行进一步的工作。
3.8 gRPC设置超时
3.9 gRPC问题解决
- io.grpc.StatusRuntimeException: UNIMPLEMENTED
- 这个错误网上很多,大部分情况下 是由于方法找不到,即客户端与服务端proto的内容或者版本不一致,这里只需要改成一致,一般问题都能解决
- DEADLINE_EXCEEDED: deadline exceeded after 149944644ns
- 这种错误明细我这里就不打印了,这里一般是读取数据超时,
- 问题原因:一般是grpc超时时间设置短了,或者下游服务响应超时。
- 解决方案:修改grpc超时时间,或者检查grpc服务端是否有问题
- Exception: NAVAILABLE: upstream request timeout
- 问题原因:这里可以理解为连接超时,这里说明健康检查也超时
- 解决方案:检查grpc服务端是否有问题。
- INTERNAL: Received unexpected EOS on DATA frame from server
- 问题原因:这里可翻译为收到了空消息,这里可能是服务端没响应
- 解决方案:检查端口是否对应上,服务是否正常,特别是docker中的端口映射配置是否正确。
- io.grpc.StatusRuntimeException: UNKNOWN
- 问题原因: 从字面意思是未知错误,这个是服务端反馈,主要是服务端报了一些未知异常,比如说参数传的有问题等
- 解决方案: 检查客户端传参是否有个别异常,打印出有问题参数
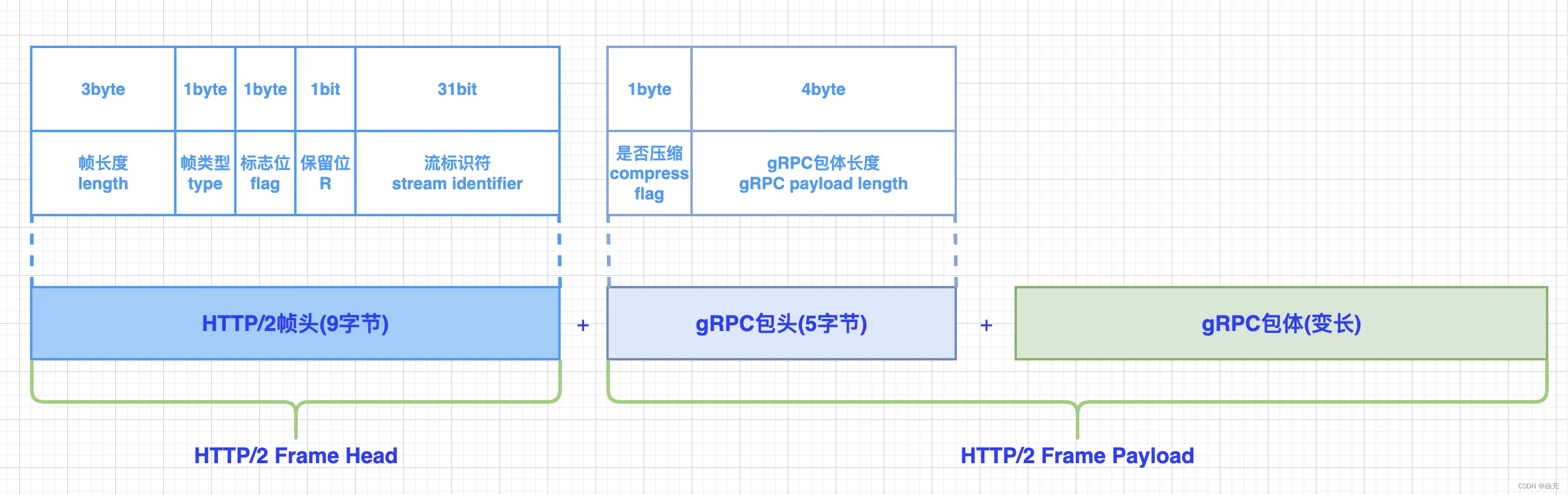
3.10 理解gRPC协议
- gRPC基于HTTP/2/协议进行通信,使用ProtoBuf组织二进制数据流,gRPC的协议格式如下图:
- gRPC协议在HTTP协议的基础上,对HTTP/2的帧的有效包体(Frame Payload)做了进一步编码:gRPC包头(5字节)+gRPC变长包头,其中:
- 5字节的gRPC包头由:1字节的压缩标志(compress flag)和4字节的gRPC包头长度组成;
- gRPC包体长度是变长的,其是这样的一串二进制流:使用指定序列化方式(通常是ProtoBuf)序列化成字节流,再使用指定的压缩算法对序列化的字节流压缩而成的。如果对序列化字节流进行了压缩,gRPC包头的压缩标志为1。
04.gRPC通信实践
4.1 gRPC通信技术点
- gRPC一些关键技术点
- 服务定义:使用Protocol Buffers语言定义服务接口和消息类型。通过定义.proto文件,指定服务的方法、输入参数和返回类型。
- 代码生成:使用Protocol Buffers编译器将.proto文件生成对应的客户端和服务器端代码。生成的代码提供了类型安全的API,用于在客户端和服务器端之间进行通信。
- 传输协议:gRPC默认使用HTTP/2作为传输协议,提供了双向流、多路复用和头部压缩等特性,以提高性能和效率。
- 序列化和反序列化:gRPC使用Protocol Buffers作为默认的序列化和反序列化机制,将结构化数据转换为二进制格式进行传输。
- 服务端实现:在服务器端,通过实现定义的服务接口,处理客户端发起的请求并返回相应的结果。可以使用各种编程语言(如Java、C++、Python等)来实现服务器端逻辑。
- 客户端调用:客户端通过生成的代码调用服务器端提供的方法,将请求参数传递给服务器,并接收服务器返回的结果。
- 拦截器和中间件:gRPC提供了拦截器和中间件机制,可以在请求和响应的处理过程中添加自定义的逻辑,例如身份验证、日志记录等。
- 错误处理:gRPC定义了一套错误码和状态码,用于标识和处理不同类型的错误和异常情况。
- 安全性:gRPC支持使用Transport Layer Security(TLS)进行通信加密,确保数据的安全性和完整性。
- 反向代理:gRPC可以与反向代理(如Envoy)结合使用,以提供负载均衡、流量控制和故障恢复等功能。
4.2 Channel创建和复用
4.3 如何添加公参
- 可以通过自定义消息类型来添加公共参数。
- 可以在请求和响应消息中定义公共参数,并在每次通信时将其包含在消息中。
- 第一步:使用Protocol Buffers定义公共参数:在.proto文件中,定义一个消息类型,用于表示公共参数。
- 可以创建一个名为CommonParams的消息类型,并在其中定义公共参数字段,如userId、timestamp等。
message CommonParams {
string userId = 1;
int64 timestamp = 2;
}
- 第二步:在请求和响应消息中包含公共参数。请求和响应消息中,将公共参数消息类型作为一个字段包含进去。
- 可以在请求消息中添加一个commonParams字段,并将CommonParams消息类型作为其类型。
message MyRequest {
CommonParams commonParams = 1;
// 其他请求参数...
}
- 第三步:在客户端和服务器端设置公共参数:在每次通信之前,可以在客户端和服务器端设置公共参数的值。
- 在客户端中,可以创建一个CommonParams对象,并将其设置为请求消息的commonParams字段。
CommonParams commonParams = CommonParams.newBuilder()
.setUserId("user123")
.setTimestamp(System.currentTimeMillis())
.build();
MyRequest request = MyRequest.newBuilder()
.setCommonParams(commonParams)
// 设置其他请求参数...
.build();
4.4 请求/响应的读写操作
- 请求和响应的读写是通过客户端和服务器端的Stub对象进行的。
- Stub对象是由gRPC编译器生成的,用于在客户端和服务器端之间进行通信。如何在gRPC中进行请求和响应的读写操作,如下所示:
- 客户端请求的写入
- 创建了一个请求消息对象request,并使用Stub对象的方法myMethod发送请求。该方法会返回一个响应消息对象response。
// 创建请求消息对象
MyRequest request = MyRequest.newBuilder()
.setName("打工充")
.setAge(30)
.build();
// 调用Stub对象的方法发送请求并获取响应
MyResponse response = stub.myMethod(request);
- 服务器端请求的读取
- 在服务器端的方法中接收请求消息request,并从中读取字段的值。然后创建一个响应消息对象response,并使用responseObserver对象将响应消息发送给客户端。
@Override
public void myMethod(MyRequest request, StreamObserver<MyResponse> responseObserver) {
// 从请求消息中读取字段的值
String name = request.getName();
int age = request.getAge();
// 创建响应消息对象
MyResponse response = MyResponse.newBuilder()
.setMessage("Hello, " + name + "! You are " + age + " years old.")
.build();
// 发送响应消息给客户端
responseObserver.onNext(response);
responseObserver.onCompleted();
}
4.5 网络日志打印
- 在Java中使用gRPC时,您可以通过拦截器来实现日志记录。
- 拦截器可以在gRPC调用的不同阶段插入自定义逻辑,包括请求发送前、响应接收后等。
- 创建拦截器的步骤如下所示:
- 创建拦截器类:创建一个实现ServerInterceptor或ClientInterceptor接口的拦截器类。
- 实现拦截逻辑:在拦截器类中,实现interceptCall方法,该方法会在每次gRPC调用时被调用。您可以在该方法中添加日志记录的逻辑。
- 注册拦截器:在服务器端或客户端的gRPC配置中,注册拦截器。具体的注册方式取决于您使用的gRPC框架和版本。
- 创建拦截器和使用拦截器代码如下所示:
//构建Channel中,添加拦截器
channel = ManagedChannelBuilder.forAddress(host, port).usePlaintext()
//添加拦截器
.intercept(new LoggingInterceptor())
.build();
//创建拦截器
public class LoggingInterceptor implements ServerInterceptor, ClientInterceptor {
private static final String TAG = "gRPC-yc";
@Override
public <ReqT, RespT> ClientCall<ReqT, RespT> interceptCall(
MethodDescriptor<ReqT, RespT> method, CallOptions callOptions, Channel next) {
// 在请求发送前记录日志
Log.d(TAG,"Sending request: " + method.getFullMethodName());
// 调用下一个拦截器或服务实现
return next.newCall(method,callOptions);
}
@Override
public <ReqT, RespT> ServerCall.Listener<ReqT> interceptCall(
ServerCall<ReqT, RespT> call, Metadata headers, ServerCallHandler<ReqT, RespT> next) {
// 在请求接收前记录日志
Log.d(TAG,"Received request: " + call.getMethodDescriptor().getFullMethodName());
// 调用下一个拦截器或服务实现
return next.startCall(call,headers);
}
}
- 思考一下,如何监听请求状态操作。其实这里可以借鉴日志拦截!
- 通过使用拦截器(Interceptor)来监听和处理请求的状态。拦截器是一种机制,允许您在 gRPC 调用的不同阶段插入自定义的逻辑。
- 创建一个实现 ClientInterceptor 接口的拦截器类,用于监听客户端请求状态。然后在interceptCall方法中创建一个自定义的 ClientCall 实现类,用于监听请求状态
4.6 如何做网络缓存
- gRPC 并没有内置的网络缓存机制
- 如果需要做缓存操作,则需要借助代理服务器或其他缓存方案来实现网络缓存。
- 可以使用代理服务器来缓存 gRPC 的网络请求和响应。
- 代理服务器位于客户端和服务器之间,拦截并缓存 gRPC 请求和响应。当客户端发送请求时,代理服务器首先检查是否有缓存的响应可用。
- 如果有,代理服务器直接返回缓存的响应,而不需要将请求发送到服务器。这样可以减少网络传输和服务器负载。
- 考虑缓存一致性的问题是很有必要的
- 需要考虑缓存一致性的问题。由于 gRPC 的请求和响应可能包含动态的数据,缓存的数据可能会过时。
- 因此,需要在缓存中实施一些机制来处理缓存一致性,如使用缓存标记(cache tags)或版本号来标识缓存的数据,并在数据更新时更新缓存。
4.7 如何请求域名
4.8 如何处理错误和异常
4.9 设置CA证书校验
- 可以使用CA证书来进行TLS/SSL连接的校验,以确保通信的安全性。
- 在客户端,需要加载CA证书,并配置TLS/SSL连接。使用gRPC提供的ManagedChannelBuilder来配置客户端的TLS/SSL连接。
- caCertFile是CA证书文件的路径。通过调用useTransportSecurity方法和sslContext方法,您可以配置客户端使用TLS/SSL连接,并加载CA证书。
// 创建 SSLContext
SSLContext sc = SSLContext.getInstance("TLSv1.2");
sc.init(null, getTrustManagers(isCa), null);
// 创建 SSLSocketFactory
Tls12SocketFactory socketFactory = new Tls12SocketFactory(sc.getSocketFactory());
// 通过 channel 设置 sslSocketFactory做ssl安全处理
((OkHttpChannelBuilder) channelBuilder).sslSocketFactory(socketFactory);
4.10 如何保证安全性
- 在 gRPC 中,可以采取以下措施来确保通信的安全性:
- 使用 TLS/SSL:使用 TLS/SSL 来加密和保护通信。通过配置服务器和客户端的 TLS/SSL 连接,可以确保数据在传输过程中的机密性和完整性。
- 使用安全的认证和授权机制:在 gRPC 中,可以使用安全的认证和授权机制来限制对服务的访问。例如,可以使用基于令牌的认证机制(如 OAuth)来验证客户端的身份,有点类似OkHttp请求中token令牌。
- 安全地处理和传输敏感数据:确保在处理和传输敏感数据时采取适当的安全措施,如加密、哈希和脱敏等。避免在不安全的环境中传输敏感数据,如明文密码或敏感个人信息。
- 监控和日志记录:实施监控和日志记录机制,以便及时检测和响应安全事件。记录关键事件和异常。
4.11 如何兼容OkHttp
05.ProtoBuf核心原理
5.1 ProtoBuf数据结构
- Protocol Buffers(ProtoBuf)是一种用于序列化结构化数据的语言无关、平台无关、可扩展的数据交换格式。
- ProtoBuf 使用 .proto 文件定义数据结构,然后使用编译器生成相应的代码,以便在不同的编程语言中使用。
- ProtoBuf 数据结构由以下几个主要元素组成:
- 消息(Message):消息是 ProtoBuf 中的基本数据单元,用于表示结构化的数据。消息由一个或多个字段组成,每个字段都有一个唯一的标识符和一个数据类型。消息可以嵌套在其他消息中,形成复杂的数据结构。
- 字段(Field):字段是消息中的数据项,用于存储具体的数据。每个字段都有一个唯一的标识符和一个数据类型。常见的数据类型包括整数、浮点数、布尔值、字符串等。字段还可以具有可选性、重复性和默认值等属性。
- 枚举(Enum):枚举用于定义一组有限的取值列表。每个枚举值都有一个唯一的名称和一个关联的整数值。枚举可以作为消息的字段类型,用于表示一组预定义的取值。
- 服务(Service):服务用于定义一组远程过程调用(RPC)方法。每个方法都有一个唯一的名称、输入消息类型和输出消息类型。服务定义了客户端和服务器之间的通信接口。
5.2 ProtoBuf编码方式
- Protocol Buffers(ProtoBuf)提供了多种编码方式来序列化和反序列化数据。
- Binary 编码:Binary 编码是默认的编码方式,将数据序列化为紧凑的二进制格式。Binary 编码具有高效的序列化和反序列化性能,以及较小的数据体积。这种编码方式适用于网络传输和持久化存储。
- JSON 编码:ProtoBuf 还支持将数据序列化为 JSON 格式。JSON 编码使得数据更易于阅读和调试,同时也方便与其他系统进行交互。但相比 Binary 编码,JSON 编码会产生更大的数据体积,并且序列化和反序列化的性能较低。
- XML 编码:ProtoBuf 还支持将数据序列化为 XML 格式。XML 编码使得数据更易于阅读和处理,特别适用于与现有 XML 数据格式集成的场景。但与 JSON 编码相比,XML 编码通常会产生更大的数据体积,并且性能较低。
- Text 编码:ProtoBuf 还支持将数据序列化为可读的文本格式。Text 编码使得数据更易于阅读和调试,但相比 Binary 编码,它会产生更大的数据体积,并且序列化和反序列化的性能较低。
- Binary 编码通常是最常用和推荐的方式
- 因为它具有最高的性能和最小的数据体积。这里思考一下,如何是你,你会如何设计编码方式来减少数据的体积,又不影响性能?
- 字段编码:对于每个字段,Binary 编码使用变长编码来表示字段的标识符和值。标识符由字段的编号和类型组成,以便在解码时能够正确地识别字段。
- 消息编码:对于消息,Binary 编码将消息的字段按照编号的顺序进行编码。每个字段都使用字段编码的方式进行编码,并按照字段的编号进行排序。
- 可选性和重复性:对于可选字段,Binary 编码使用一个特殊的标记来表示字段是否存在。如果字段存在,则按照正常的字段编码方式进行编码;如果字段不存在,则不进行编码。
- 压缩:Binary 编码使用一些压缩技术来减小数据的体积。
5.3 充分理解TLV设计
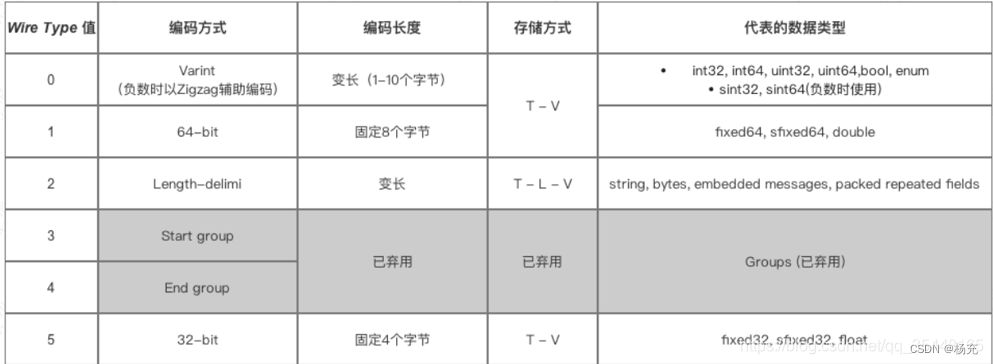
5.4 TLV设计中Type原理
-
- 在 ProtoBuf 中,每个字段的类型都有一个对应的编码值,用于表示字段的类型信息。例如,以下是一些常见的字段类型和对应的编码值:
- Varint 类型(包括 int32、int64、uint32、uint64、sint32、sint64、bool、enum)的编码值为 0。
- 64 位固定长度类型(如 fixed64、sfixed64、double)的编码值为 1。
- 字符串类型(如 string)的编码值为 2。
- 嵌套消息类型(如 message)的编码值为 2。
- 32 位固定长度类型(如 fixed32、sfixed32、float)的编码值为 5。
- 例如,假设有一个字段的编号为 1,类型为 int32,那么计算得到的 Type 值为:
- Type = (1 << 3) | 0 = 8 这样就可以将 Type 值与 Length 和 Value 一起构成 TLV 编码格式的数据。
5.5 TLV设计中Length原理
- Varints(Variable-Length Integers)是 Protocol Buffers(ProtoBuf)中一种用于编码整数的变长编码方式。
- Varints 可以有效地压缩整数的表示,并且适用于表示小整数和大整数。
- 为什么会有Varints编码算法
- 对于不包含length字段的编码格式,如何确定value的长度以对各个数据进行分割?
- 一种方法是根据type类型确定value域长度,这种方法的问题在于会浪费一定的存储空间,例如存储数字1,也需要int32的类型,若增加type的数量,则存储type占用的空间也会相应增加;
- 第二种方法则是protobuf采用的Varint类型。
- Varints 的编码规则如下:
- 对于非负整数(包括 0),Varints 使用 7 个比特位来表示每个字节的数据,其中最高位(第 8 位)用于指示是否还有后续字节。如果最高位为 1,则表示后续字节仍然属于该整数;如果最高位为 0,则表示该字节是整数的最后一个字节。
- 对于负整数,Varints 使用 ZigZag 编码来表示。ZigZag 编码将有符号整数转换为无符号整数,通过将最低有效位(LSB)移动到最高有效位(MSB),并使用 Varints 进行编码。这样可以减小负整数的表示范围,从而减小编码的长度。
- 下面是一个示例,展示了几个整数的 Varints 编码:
- 整数 300 的二进制表示: 00000000 00000000 00000001 00101100
- 整数 300 Varints 编码: 10100110 00000010
- 那么如何读取整数 300 Varints 编码呢
- Varints 的本质实际上是每个字节都牺牲一个 bit 位(msb)来表示是否已经结束
- msb 实际上就起到了 length 的作用,正因为有了 msb(length),所以可以根据数字大小动态调整需要的字节数量。
- 通过varints我们可以让小的数字用更少的字节表示,从而提高了空间利用和效率。
06.gRPC核心设计思想
6.1 Channel核心设计思想
- gRPC 的 Channel 层是其核心设计思想
- 连接管理:
- Channel 层负责管理与远程服务器的连接。它维护一个连接池,可以重用现有的连接,避免频繁地创建和销毁连接。这样可以提高性能并减少资源消耗。
- 流控制:
- Channel 层使用 HTTP/2 协议作为底层的传输协议,利用其流控制机制来控制数据的传输速率。这样可以避免发送方过载或接收方无法处理的情况,保证通信的稳定性和可靠性。
- 消息压缩:
- Channel 层支持消息的压缩和解压缩,以减少数据的传输量。它使用基于 HTTP/2 的头部压缩机制来压缩请求和响应的元数据,以及使用可选的消息压缩算法来压缩消息体。这样可以提高网络传输的效率。
- 超时和重试:
- Channel 层支持设置请求的超时时间,并提供重试机制来处理请求失败的情况。当请求超时或失败时,Channel 层可以自动重试请求,以增加请求的可靠性和稳定性。
6.2 Stub核心设计思想
- gRPC 的 Stub 是其核心设计思想
- 用于在客户端和服务器之间进行远程过程调用(RPC)。
- 接口定义语言(IDL):
- gRPC 使用 Protocol Buffers(protobuf)作为接口定义语言,用于定义服务接口和消息格式。Stub 根据接口定义生成客户端和服务器端的代码,使得开发人员可以方便地定义和实现远程服务。
- 强类型接口:
- Stub 生成的代码提供了强类型的接口,使得客户端可以直接调用远程服务的方法,就像调用本地方法一样。这种强类型接口提供了更好的类型安全性和编译时检查,减少了错误和调试的复杂性。
- 序列化和反序列化:
- Stub 使用 Protocol Buffers(protobuf)作为默认的序列化和反序列化机制。它将请求和响应消息序列化为二进制格式进行传输,以及将二进制数据反序列化为消息对象。这种序列化机制使得数据传输更紧凑和高效。
- 异步和流式通信:
- Stub 支持异步和流式通信,使得客户端和服务器可以以非阻塞的方式进行通信。客户端可以发送异步请求并接收异步响应,或者使用流式请求和响应来处理流式数据。这种能力使得 gRPC 在实时应用、流式处理等场景中非常有用。
6.3 NameResolver核心设计思想
- gRPC 的 NameResolver 是其核心设计思想
- 服务名称解析:NameResolver 负责将服务名称解析为对应的服务器地址。
- 它可以根据不同的解析策略,如 DNS 解析、配置文件解析、服务发现等,将服务名称映射到一个或多个服务器地址。
- 动态更新:NameResolver 支持动态更新服务器地址。
- 它可以监听服务地址的变化,并在地址发生变化时及时更新客户端的连接。这样可以实现服务的动态发现和负载均衡。
- 负载均衡:NameResolver 支持负载均衡,可以在多个服务器实例之间分配请求。
- 它可以根据预定义的负载均衡策略选择合适的服务器,并将请求发送到相应的服务器上。这样可以实现高可用性和扩展性。
- 缓存和重试:NameResolver 可以缓存解析的服务器地址
- 在需要时使用缓存的地址。它还支持重试机制,以处理解析失败或超时的情况。这样可以提高解析的效率和可靠性。
6.4 gRPC网络框架设计层次
- 应用层:应用层是最高层,包含了实际的业务逻辑和应用程序代码。
- 在 gRPC 中,应用层使用 Protocol Buffers(ProtoBuf)定义服务和消息,并通过 gRPC 提供的代码生成工具生成相应的客户端和服务器代码。
- gRPC Stub/Client
- gRPC Stub(或称为 gRPC Client)是客户端代码的一部分,它提供了与服务器进行通信的接口。客户端使用 Stub 来调用服务器端的方法,并发送请求消息。
- gRPC Channel通信通道
- gRPC Channel 是客户端与服务器之间的通信通道。客户端使用 Channel 来与服务器建立连接,并发送请求消息。Channel 提供了负载均衡、连接管理和错误处理等功能。
- gRPC Core核心引擎
- gRPC Core 是 gRPC 的核心引擎,提供了底层的网络通信和协议处理功能。它实现了 gRPC 的协议规范,处理请求和响应的序列化、反序列化、压缩、安全性等方面的功能。
- 传输层:传输层负责在客户端和服务器之间传输数据。
- gRPC 支持多种传输层协议,如 HTTP/2、TCP、gRPC-over-HTTP/1.1 等。HTTP/2 是 gRPC 的默认传输层协议,它提供了高效的多路复用、流控制和头部压缩等特性。
07.gRPC核心原理
7.1 gRPC核心设计思路
- gRpc源码核心设计说明
- 类库有三个不同的层: Stub/桩, Channel/通道 & Transport/传输。
- Stub
- Stub层暴露给大多数开发者,并提供类型安全的绑定到正在适应(adapting)的数据模型/IDL/接口。
- gRPC带有一个protocol-buffer编译器的 插件用来从.proto 文件中生成Stub接口。当然,到其他数据模型/IDL的绑定应该是容易添加并欢迎的。
- Channel
- Channel层是传输处理之上的抽象,适合拦截器/装饰器,并比Stub层暴露更多行为给应用。
- 它想让应用框架可以简单的使用这个层来定位横切关注点(address cross-cutting concerns)如日志,监控,认证等。
- 流程控制也在这个层上暴露,容许更多复杂的应用来直接使用它交互。
- Transport
- Transport层承担在线上放置和获取字节的繁重工作。它的接口被抽象到恰好刚刚够容许插入不同的实现。Transport被建模为Stream工厂。gRPC带有三个Transport实现:
- 基于Netty 的transport是主要的transport实现,基于Netty. 可同时用于客户端和服务器端。
- 基于OkHttp 的transport是轻量级的transport,基于OkHttp. 主要用于Android并只作为客户端。
- inProcess transport 是当服务器和客户端在同一个进程内使用使用。用于测试。
7.3 域名解析流程
- NameResolver 是可拔插的组件,用于解析目标 URI 并返回地址给调用者。
- NameResolver 使用 URI 的 scheme 来检测是否可以解析它, 再使用 scheme 后面的组件来做实际处理。
- 域名解析涉及到的核心类
- NameResolver是一个抽象类。抽象方法start()和shutdown()分别是开始解析和停止解析。通过Factory工厂类调用newNameResolver()方法创建对象。
- DnsNameResolver是一个实现类。包级私有,通过DnsNameResolverFactory类来创建。其dns解析核心逻辑在这个类中。
- DnsNameResolver中解析域名流程
- DnsNameResolver#构造函数,传入一些参数,将参数简单保存起来。
- DnsNameResolver#start(),开始解析,传入 listener 用于接收目标的更新。
- DnsNameResolver#resolve(),开始做实际的解析,这里通过线程池创建一个任务,然后看Resolve类
- DnsNameResolver#Resolve#run(),主要做3步。第一步解析地址,第二步包装格式,第三步通知listener。注意这个工作是在异步线程中进行的,只能通过listener。
- DnsNameResolver#shutdown(),将停止解析,同时更新 listener 将会停止。
- DnsNameResolver中解析地址失败的流程
- DnsNameResolver#Resolve#run(),以此为入口,然后调用doResolve解析返回一个result结果,这里面判断result.error如果不为空,则执行解析失败处理逻辑。
- NameResolver#Listener2#onError(),回调这个方法,是一个抽象类,看具体的实现类,可以定位到NameResolverListener
- ManagedChannelImpl#NameResolverListener#onError(),这里面处理解析异常逻辑。开启一个线程做任务
- NameResolverListener#NameResolverErrorHandler#run(),然后继续往下看scheduleExponentialBackOffInSyncContext()方法
- ManagedChannelImpl#scheduleExponentialBackOffInSyncContext(),通过线程池发送一个延迟1分钟的DelayedNameResolverRefresh刷新任务,在这个任务里调用nameResolver.refresh()刷新
- nameResolver.refresh(),将会再次调用解析地址操作。只是在每次解析失败时,一旦解析成功,就会跳出循环。
7.4 Channel层设计原理
- 如何理解Channel层设计
- Channel 到概念上的端点的虚拟连接,用于执行RPC。 通道可以根据配置,负载等自由地实现与端点零或多个实际连接。
- 通道也可以自由地确定要使用的实际端点,并且可以在每次 RPC 上进行更改,从而允许客户端负载平衡。应用程序通常期望使用存根(stub),而不是直接调用这个类。
- Channel抽象类的设计
- 抽象newCall()方法,构建一个用于远程操作的 ClientCall 对象,返回的 ClientCall 对象不会触发任何远程行为,直到 ClientCall.start() 方法被调用。
- 抽象authority()方法,这个 Channel 连接到的目的地的 authority。通常是以 “host:port” 格式。
- ManagedChannel抽象类的设计
- 类ManagedChannel 在 Channel 的基础上提供生命周期管理的功能。
- shutdown()/shutdownNow() 方法用于关闭 Channel。shutdown方法发起一个有组织的关闭,期间已经存在的调用将继续,而新的调用将被立即取消。
- isShutdown()/isTerminated() 方法用于检测 Channel 状态。isShutdown返回channel是否是关闭。关闭的channel立即取消任何新的调用,但是将继续有一些正在处理的调用。
- awaitTermination() 方法用于等待关闭操作完成。该方法是等待 channel 变成结束,如果超时时间达到则放弃。
- ManagedChannelImpl实现类的设计
- exitIdleMode()方法,让 Channel 退出空闲模式,如果它处于空闲模式中。返回一个新的可以用于处理新请求的 LoadBalancer。如果 Channel 被关闭则返回null。
- ManagedChannelImpl - InUseStateAggregator,空闲模式的进入和退出是由它来进行控制。实现原理是每个要使用这个聚合器的调用者都要存进来一个对象,然后用完之后再取出来,这样可以通过保存对象的数量变化判断开始使用(从无到有)或者已经不再使用(从有到无)。
- ManagedChannelImpl - Name Resolver,name resolver 的 start() 方法,也就是 name resolver 要开始解析name的这个工作,只有两种情况下开始:
- 第一次RPC请求: 此时要调用Channel的 newCall() 方法得到ClientCall的实例,然后调 ClientCall 的 start()方法,期间获取ClientTransport时激发一次 name resolver 的 start()
- 如果开启了空闲模式:则在每次 Channel 从空闲模式退出,进入使用状态时,再激发一次 name resolver 的 start()
- ManagedChannelBuilder抽象类的设计
- forAddress()和forTarget()这个是请求host和port的操作,必须调用该方法。
- directExecutor(),直接在传输的线程中执行应用代码。取决于底层传输,使用一个 direct executor 可能引发重大的性能提升。当然,它也要求应用在任何情况下不阻塞。
- executor(),如果在channel构建时没有提供executor,builder将使用一个静态缓存的线程池。
- intercept(),添加拦截器,被channel执行它的实际工作前被调用。
- userAgent(),这是一个可选参数。如果提供,给定的agent将使用grpc User-Agent作为前缀。
- overrideAuthority(),覆盖和TLS和HTTP 虚拟主机服务一起使用的authority。它不会改变实际连接到的主机。通常是以host:port的形式。应该仅用于测试。
- usePlaintext(),使用 plaintext 连接到服务器。默认将使用加密连接机制如 TLS 。应该仅用于测试或者用于那些API使用或者数据交换并不敏感的API。
- nameResolverFactory(),为channel提供一个定制的 NameResolver.Factory。如果这个方法没有被调用,builder将在全局解析器注册(global resolver registry)中为提供的目标寻找一个工厂。
- idleTimeout(),设置在进入空闲模式前的没有RPC的期限。在空闲模式中,channel会关闭所有连接,NameResolver 和 LoadBalancer 。新的RPC将把channel带出空闲模式。channel以空闲模式开始。
- build(),使用给定参数来构建一个channel
- ManagedChannelProvider抽象类的设计
- Channel Provider 的功能在于帮助创建合适的 ManagedChannelBuilder。目前有多套 Channel 的实现,典型如 netty 和 okhttp ,选择哪套实现就是一个需要特别考虑的问题。
- Channel Provider 的设计目标是解藕这个事情,不使用配置,hard code等方式,而是将细节交给 Channel Provider 的具体实现。
- 在 ManagedChannelBuilder 中这样调用 ManagedChannelProvider,其中 provider() 静态方法会根据实际情况选择一套可用的方案,然后 builderForAddress()方法和 forTarget() 方法会创建对应的ManagedChannelBuilder。
public abstract class ManagedChannelBuilder<T extends ManagedChannelBuilder<T>> {
public static ManagedChannelBuilder<?> forAddress(String name, int port) {
return ManagedChannelProvider.provider().builderForAddress(name, port);
}
public static ManagedChannelBuilder<?> forTarget(String target) {
return ManagedChannelProvider.provider().builderForTarget(target);
}
}
- 一个抽象基类 ManagedChannelProvider,然后 okhttp(OkHttpChannelProvider) 和 netty(NettyChannelProvider) 各实现了一个子类。
7.4 Stub层设计原理
- 生成类HelloWorldGrpc.HelloWorldStub介绍
- 这个类是通过grpc的proto编译器生成的类,它的package由.proto文件中的 java_package 选项指定。这个XxxStub类是继承AbstractStub抽象类。
- 类AbstractStub是stub实现的通用基类设计
- 类AbstractStub也是生成代码中的stub类的通用基类。这个类容许重定义,例如,添加拦截器到stub。
- AbstractStub()构造函数,类AbstractStub有两个属性:Channel channel,CallOptions callOptions
- build()抽象方法,定义了抽象方法build()方法来返回一个新的stub,使用给定的Channel和提供的方法配置。
- with方法族,定义有多个with×××()方法,通过创建新的 CallOptions 实例,然后调用上面的build()方法来返回一个新的stub。
标签:请求,
gRPC,
实践,
客户端,
使用,
序列化,
ProtoBuf
From: https://www.cnblogs.com/yc211/p/18083917