类加载
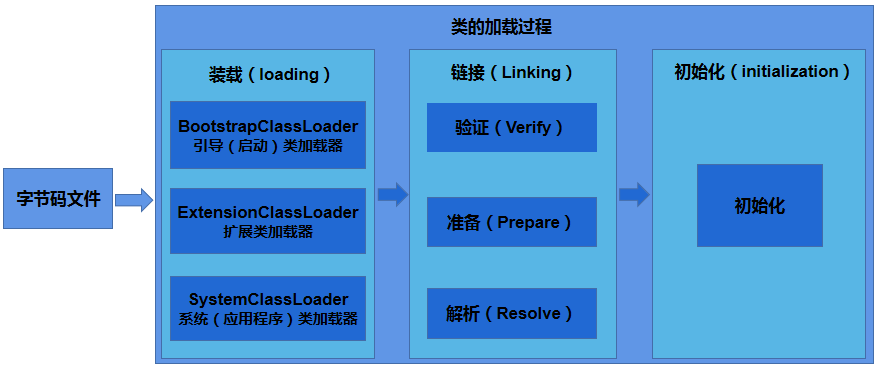
系统加载字节码文件主要有三步:装载 -> 连接 -> 初始化。
类加载时机
-
类加载时机
简单理解:字节码文件什么时候会被加载到内存中?
有以下的几种情况:
- 创建类的实例(对象)
- 调用类的类方法
- 访问类或者接口的类变量,或者为该类变量赋值
- 使用反射方式来强制创建某个类或接口对应的java.lang.Class对象
- 初始化某个类的子类
- 直接使用java.exe命令来运行某个主类
总结而言:用到了就加载,不用不加载
类加载过程
装载 loading
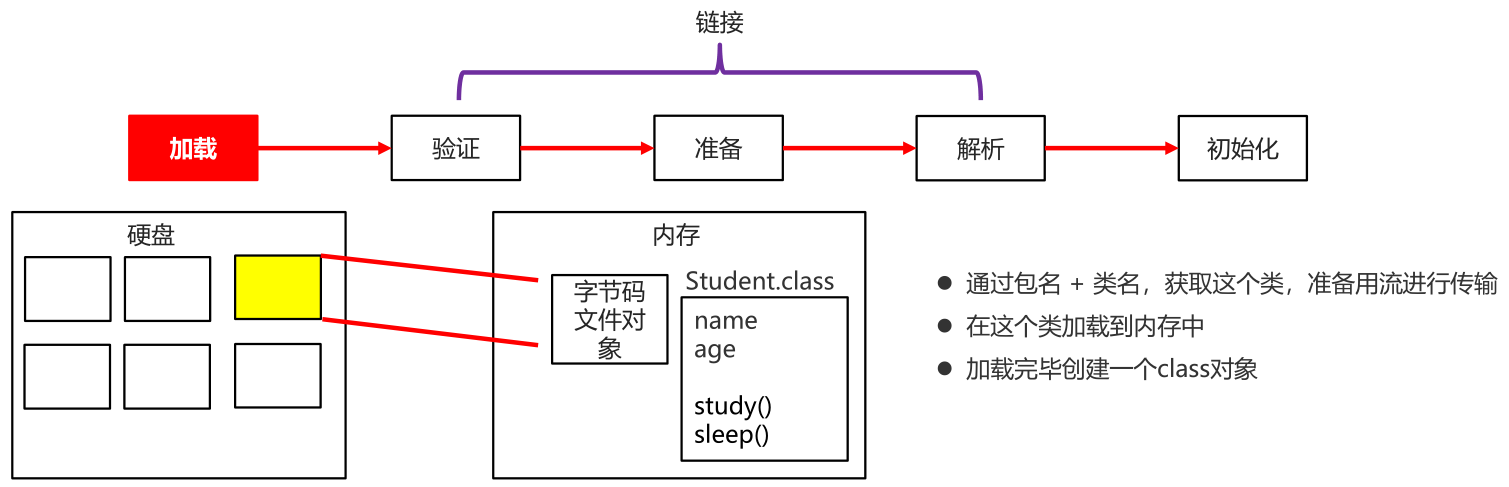
过一个类的全限定名来获取定义此类的二进制字节流,将这个字节流所代表的静态存储结构转化为运行时数据结构。
装载完毕内存中生成代表这个类的java.lang.Class对象
- 确定了将来对象的大小和是否需要补齐
连接 linking
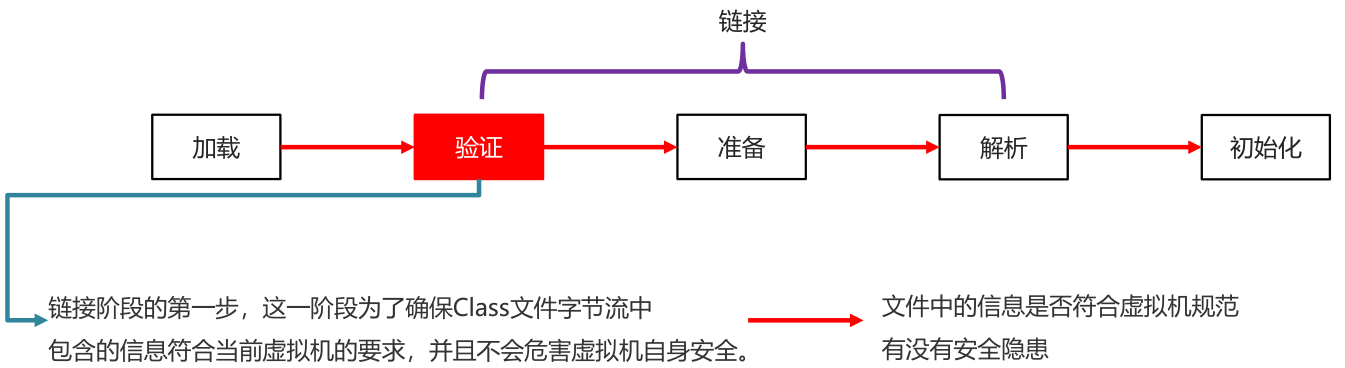
验证 verify
确保Class文件字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身安全
确保加载类的信息符合JVM规范,例如:以0xcafebabe开头,就没有安全问题(在notepad++安装HEX-Editor查看验证)。
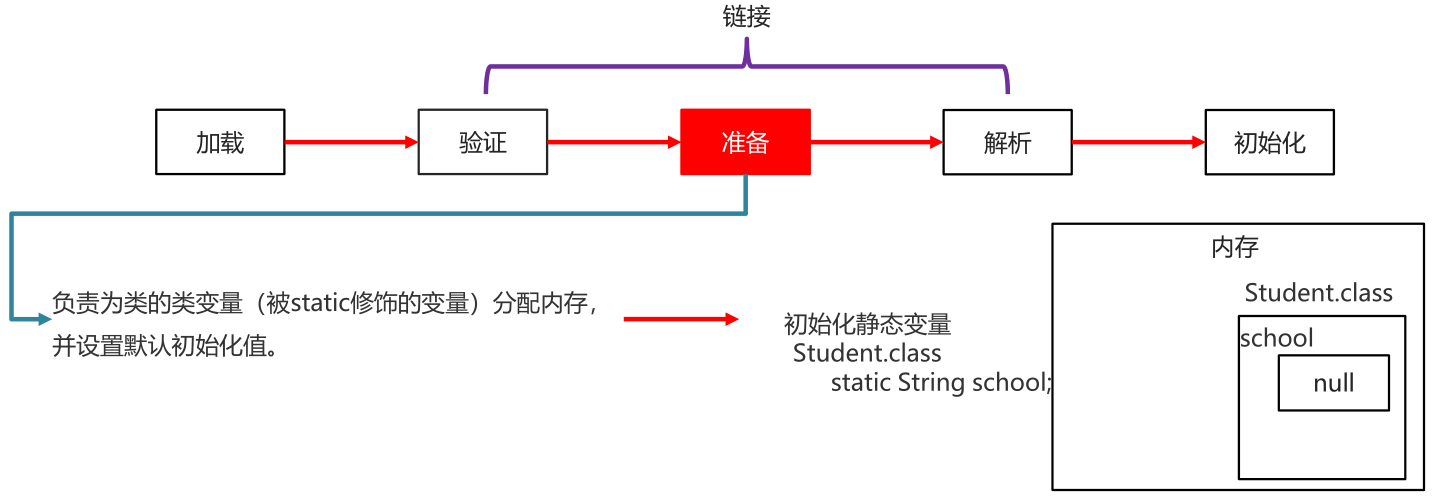
准备 prepare
正式为静态变量在方法区中开辟存储空间并设置默认值。这里“通常情况”是设置静态变量的默认值,比如我们定义了public static int value = 11,那么value变量在准备阶段设置的初始值就是0,而不是11(初始化阶段才会显示赋值)。
特殊情况:比如给value变量加上了fianl关键字public static final int value = 11,那么准备阶段value的值就被赋值为11。
解析 resolve
将虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程(在IDEA安装Jclasslib插件查看)。
将类的二进制数据流中的符号引用替换为直接引用
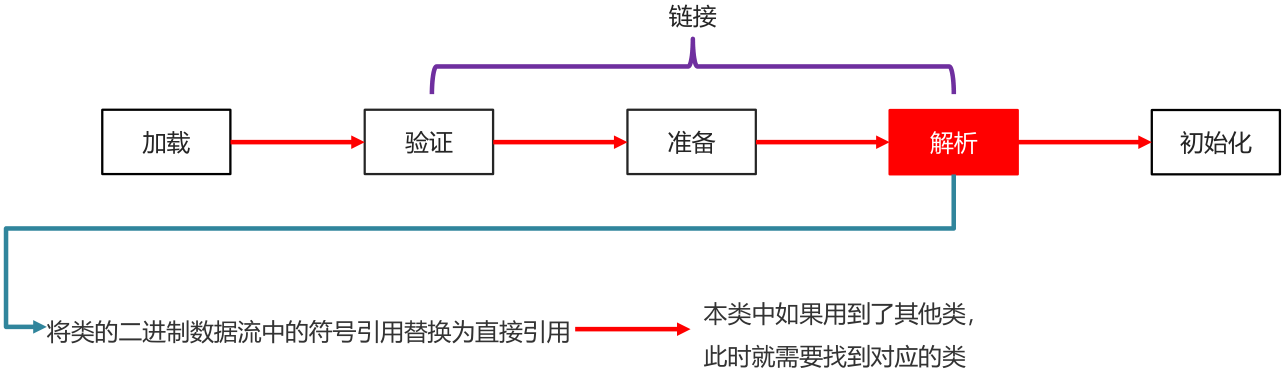
例如成员变量位置定义了String类型的name,在加载本类的时候String类是否加载这是虚拟机不知道的,此时的String其实是用符号替代的;在解析阶段会将临时的符号变为String的引用(如0x0002)并找到String类。
- JVM针对类或接口、字段、方法等内容进行解析,方法信息会形成虚方法表 vtable
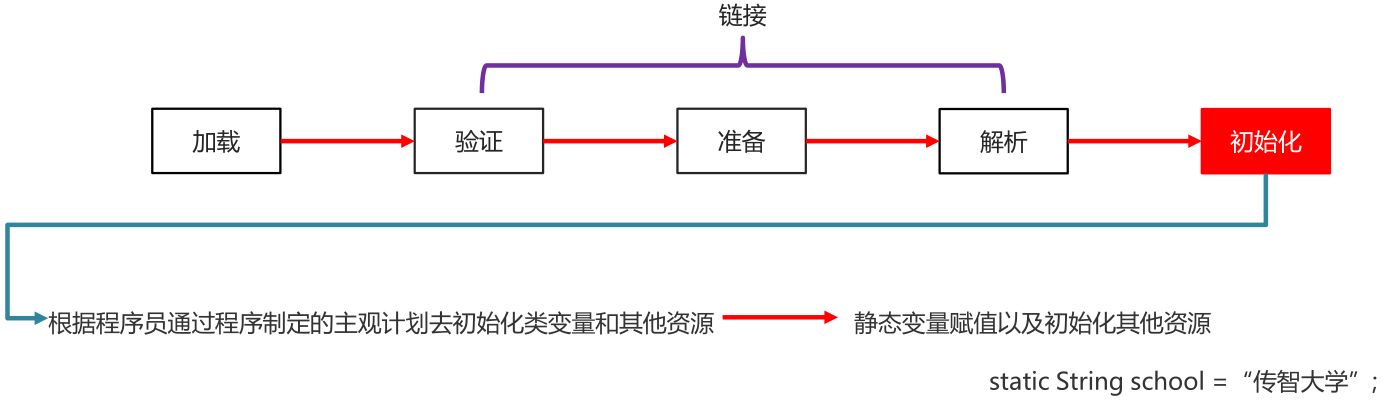
初始化(initialization)
执行类构造器 <clinit>() 方法的过程,也就是把编译时期自动收集类中所有静态变量的赋值动作和静态代码块中的赋值语句合并。
<clinit> () 方法对于类或接口来说并不是必须的,如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成clinit()方法。
类加载器
类加载器的作用
Java程序被编译器编译之后成为字节码文件(.class文件),当程序第一次需要使用某个类时,虚拟机便会将对应的字节码文件进行加载,从而创建出对应的Class对象。而这个将字节码文件加载到虚拟机内存的过程,这个就是由类加载器(ClassLoader)来完成的。
类加载器的分类
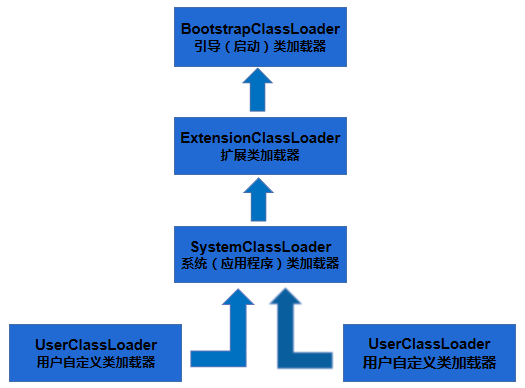
虚拟机内部提供了三种类加载器(JDK1.8):
- Bootstrap class loader: 启动类加载器,虚拟机的内置类加载器,通常表示为null ,并且没有父null;底层C++实现,随着虚拟机启动。
- Extension class loader:平台类加载器,负责加载JDK中一些特殊的模块。
- System class loader:系统类加载器,负责加载用户类路径上所指定的类库(默认从类的根路径下加载)
类加载器的继承关系(这里的继承关系不是Extends,而是逻辑上的继承)
-
System的父加载器为Extension
-
Extension的父加载器为Bootstrap
-
代码演示
//系统/应用类加载器 ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader(); //平台/扩展类加载器 ClassLoader platformClassLoader = systemClassLoader.getParent(); //启动类加载器 ClassLoader bootstrapClassLoader = platformClassLoader.getParent(); System.out.println(systemClassLoader); //jdk.internal.loader.ClassLoaders$AppClassLoader@63947c6b System.out.println(platformClassLoader); //jdk.internal.loader.ClassLoaders$PlatformClassLoader@378bf509 System.out.println(bootstrapClassLoader); //null
- 引导类加载器 BootStrapClassLoader
这个类加载器使用C/C++语言实现的,嵌套在JVM内部,通过Java代码无法获得。
用来加载Java核心库(JAVA_HOME/jre/lib/rt.jar或sun.boot.class.path路径下的内容),用于提供JVM自身需要的类
并不继承java.lang.ClassLoader,没有父加载器
处于安全考虑,Bootstrap启动类加载器值加载包名为java、javax、sun开头的类
扩展类加载器和应用程序加载器,并指定他们的父类加载器
使用-XX:+TraceClassLoading参数查看类加载情况
- 扩展类加载器 Extension class loader
由java语言编写,继承于ClassLoader类,sun.misc.Launcher$ExtClassLoader
父类加载器为启动类加载器
从java.ext.dirs系统属性所指定的目录中加载类库,或从JDK的安装目录的jre/lib/ext子目录下加载类库,如果用户创建jra放在此目录下,也会由扩展类加载器加载
- 系统类加载器 System class loader
java语言编写,继承于ClassLoader类,sun.smisc.Launcher$AppClassLoader
父加载器为扩展类加载器
负责加载环境变量classpath或系统属性java.class.path指定路径下的类(加载自定义类)
通过ClassLoader的getSystemClassLoader()方法获取获取到该类加载器
用户类加载器 User class loader
在Java的日常引用程序开发中,类加载器几乎由上述三种类加器相互配合执行的。在必要的时候,开发人员可以自定义类加载器,来制定类的加载方法
体现java语言强大生命力和魅力的关键因素之一,便是java开发者可以自定义类加载器来实现类库的动态加载,可以是本地的jar,也可以是网络上的资源
通过类加载器可以实现非常绝妙的插件机制。类加载器为应用程序提供类一种动态增加新功能的机制。
自定义类加载器能够实现应用隔离和字节码加密等功能。
自定义类加载通过需要继承于ClassLoader,其父类加载器为系统加载器。
- 示例:加载不同的类时,采用的加载类
ClassLoader classLoader1 = String.class.getClassLoader();
System.out.println(classLoader1); // 输出:null --> 启动类加载器
ClassLoader classLoader2 = DNSNameService.class.getClassLoader();
System.out.println(classLoader2); // 输出:sun.misc.Launcher$ExtClassLoader@2503dbd3
ClassLoader classLoader3 = Test01.class.getClassLoader();
System.out.println(classLoader3); // 输出:sun.misc.Launcher$AppClassLoader@18b4aac2
- 注意:手动调用classLoad.loadClass()方法不会进行初始化 initiallization
双亲委派模型
如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
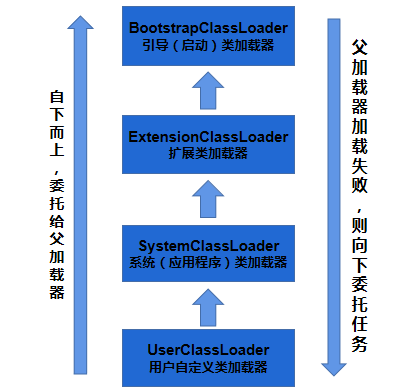
加载范围:
- 启动类加载器
jre -> lib -> rt.jar - 扩展类加载器
jre -> lib -> ext -> *.jar - 应用类加载器 加载
classpath中的jar包/文件:系统类加载器默认从类的根路径下(也就是src路径下加载),这样也可以加载根路径下的某些资源文件。
双亲委派机制的好处,避免类的俯冲加载,确保类的全局唯一性,同时保护程序安全,防止核心API被随意篡改。
例如:如果自己写了一个java.lang.String类就会因为双亲委派机制不能被加载,不会破坏原生的String类的加载。
ClassLoader 中的两个方法
- 方法介绍
| 方法名 | 说明 |
|---|---|
| public static ClassLoader getSystemClassLoader() | 获取系统类加载器 |
| public InputStream getResourceAsStream(String name) | 加载某一个资源文件 |
从类的根路径下加载某一个资源文件,类的根路径是src文件夹
-
示例代码
public class ClassLoaderDemo2 { public static void main(String[] args) throws IOException { //static ClassLoader getSystemClassLoader() 获取系统类加载器 //InputStream getResourceAsStream(String name) 加载某一个资源文件 //获取系统类加载器 ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader(); //利用加载器去加载一个指定的文件 //参数:文件的路径(放在src的根目录下,默认去那里加载) //返回值:字节流。 InputStream is = systemClassLoader.getResourceAsStream("prop.properties"); Properties prop = new Properties(); prop.load(is); System.out.println(prop); is.close(); } }
获取当前的工作路径
System.out.println(System.getProperty("user.dir"));
可以根据这个路径获取某些文件
XML
作为配置文件:用来保存程序在运行时需要的一些参数
比如IDEA:保存背景图片、字体信息、字号信息、主题信息
常见的配置文件:
- .txt
如果要保存IDEA 的配置信息:
\idea\background.png
微软雅黑
23
Windows 10 Light
但是只看配置文件,不知道每个值表达的意思,所以会有properties文件:
- .properties
background=\idea\background.png
fontfamily=微软雅黑
fontsize=23
theme=Windows 10 Light
如果要配置的信息比较复杂,properties就比较麻烦了
例如拼图游戏的信息,如果有多个用户的配置:
user=zhangsan,lisi
进度=50%,70%
游戏图片=Animal1,Animal2
游戏背景色=白色,白色
这样读取时非常不方便,找每个用户都要对,切割,只有在配置信息比较简单时可以使用properties
- .xml
优点:易于阅读,可以配置成组出现的数据
缺点:解析比较复杂
XML概述
-
万维网联盟(W3C)
万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。
建立者: Tim Berners-Lee (蒂姆·伯纳斯·李)。
是Web技术领域最具权威和影响力的国际中立性技术标准机构。
到目前为止,W3C已发布了200多项影响深远的Web技术标准及实施指南,-
如广为业界采用的超文本标记语言HTML(标准通用标记语言下的一个应用)
-
可扩展标记语言XML(标准通用标记语言下的一个子集)
-
以及帮助残障人士有效获得Web信息的无障碍指南(WCAG)等
-
单元测试
测试阶段分为:单元测试、集成测试、系统测试、验收测试

测试方法可以分为:白盒测试、黑盒测试、灰盒测试
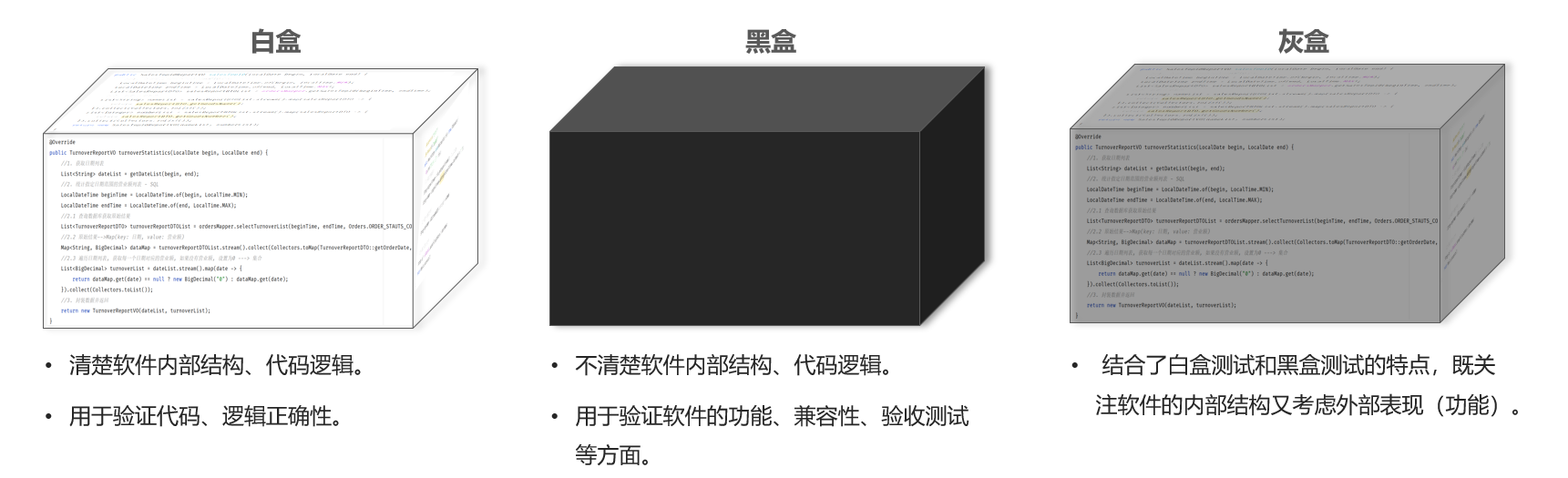
对应的测试阶段:

Junit
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.9.3</version>
<scope>test</scope>
</dependency>
单元测试类名为XxxTest,测试方法为public void testXxx(){}
常见注解

@ParamterizedTest //参数化测试,测试方法可以指定入参,不需要再写@Test
@ValueSource //为测试方法的入参提供参数
@ParameterizedTest
@ValueSource(strings = {"412302201909137037","412302201909137017","412302201909137027"})
@DisplayName("获取性别测试")
public void getGender2Test(String id) {
String gender = userService.getGender(id);
System.out.println(gender);
}
会按照参数中数组的数据依次调用测试方法并传递入参
但是这种方式只能为一个入参的方法传递参数,如果有多个入参就需要使用@CsvSource:
@ParameterizedTest
@CsvSource({"admin,123456","zhangsan,123","lisi,123"})
public void test01(String username, String password){
}
会将参数以 , 分割并传递给方法的入参
断言
在上文中,测试方法只能调用得到结果后输出到控制台,测试方法应该提供的功能是计算方法的返回值和预期值是否相等,Junit提供了断言:

注意:入参最后的msg代表不相等时的提示信息,可以不指定。
日志体系
记录程序运行过程中的所有信息,并且可以永久存储
- 可以将系统执行的信息选择性的记录到指定的位置
- 随时以开关的形式控制是否记录日志
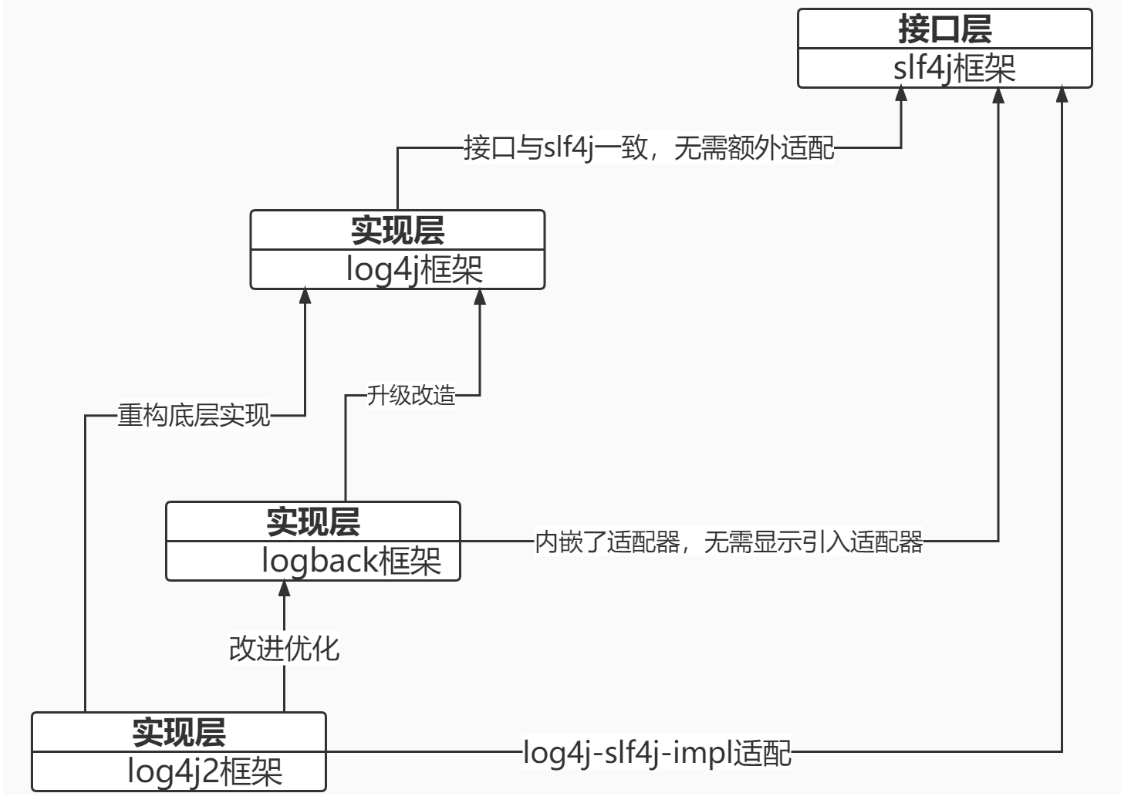
日志框架的体系:Commons Logging接口设计的不尽人意,后来设计了Simple Logging Facade for Java,slf4j是接口层,Ceki Gülcü团队最先开发了log4j,并基于log4j优化改进出了logback,最后采用全新的disruptor框架重构log4j的底层并且取logback之精华重新搭建了log4j2框架。log4j2推翻了log4j和logback所有的底层实现,但是复用了log4j的几大模块和接口
logback
logback主要分为三个技术模块:
-
logback-core:其他两个模块的基础代码
-
logback-classic:完整实现了slf4j API的模块
-
logback-access:模块与Tomcat和Jetty等Servlet容器集成,以提供HTTP访问日志的功能
首先导入jar包,然后将核心配置文件logback.xml拷贝到src目录下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
CONSOLE :表示当前的日志信息是可以输出到控制台的。
-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
<!-- File是输出的方向通向文件的 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>C:/code/itheima-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--日志文件输出的文件名,%i表示序号-->
<fileNamePattern>C:/code/itheima-data2-%d{yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--最大文件大小,超过这个大小会触发滚动到新文件,默认为10MB-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF
, 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
-->
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE" />
</root>
</configuration>
然后就可以在代码中获取日志的对象了:
public static final Logger LOGGER = LoggerFactory.getLogger("类对象");
//登录操作
Scanner sc = new Scanner(System.in);
System.out.print("请输入用户名:");
String username = sc.nextLine();
System.out.print("请输入密码:");
String password = sc.nextLine();
if ("zhangsan".equals(username) && "123".equals(password)){
System.out.println("登录成功");
LOGGER.info("用户于此时登录成功,用户名为 " + username + " 密码为 " + password);
}else {
System.out.println("登录失败");
LOGGER.info("用户于此时登录失败,用户名为 " + username + " 密码为 " + password);
}
此时保存的日志文件a.txt:
2023-04-16 13:58:11.891 [main] INFO LogDemo.LogTest01 - 用户于此时登录失败,用户名为 zhangsna 密码为 123
2023-04-16 13:58:37.325 [main] INFO LogDemo.LogTest01 - 用户于此时登录成功,用户名为 zhangsan 密码为 123
配置文件详解
Logback日志系统的特性都是通过核心配置文件logback.xml控制的
logback日志输出位置、格式设置:
-
通过
<appender>标签可以设置输出位置和日志信息的详细格式 -
通常可以设置2个日志输出位置:控制台和系统文件
输出到控制台的配置标志:
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%c 当前类名
%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
输出到系统文件的配置标志:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
class中指定的就是做完整操作的类
<!-- File是输出的方向通向文件的 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>C:/code/itheima-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>C:/code/itheima-data2-%d{yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
日志级别:级别程度依次是: TRACE < DEBUG < INFO < WARN < ERROR;默认级别是debug(忽略大小写)

-
作用:用于控制系统中哪些日志级别是可以输出的,只输出级别不低于设定级别的日志信息
-
ALL和OFF的作用分别是打开全部日志信息,关闭全部日志信息
在<root level = "INFO">标签的level属性中设置日志级别
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE" />
</root>
使用了Lombok之后,使用@Slf4j就可以直接使用log对象
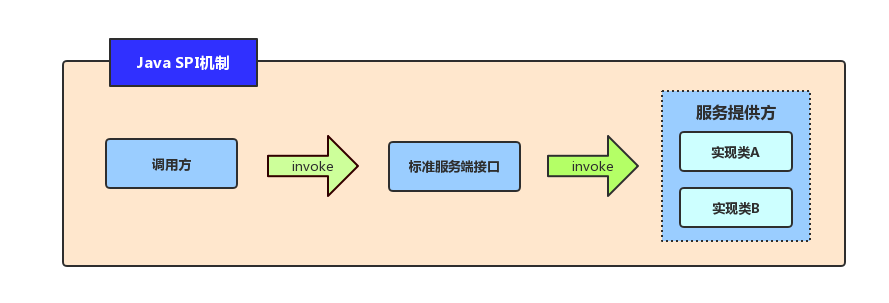
SPI
简介
SPI机制:Service Provider Interface,JDK内置的一种服务提供发现机制,使得程序的扩展(切换实现)可以轻松实现,以实现接口和实现类之间的解耦。
为什么需要SPI
基于OCP和依赖倒置原则,模块之间的通信一般基于接口进行,通常情况下调用者模块并不知道被调用者模块内部的具体实现。
为了实现模块装配时不必在程序中指明(分层解耦),这就需要一种服务发现机制,Java SPI就是提供了这样的机制:为某个接口寻找服务实现的机制,类似于IoC的思想,将装配的控制权放在程序之外。
重新理解SPI
SPI是专门给服务提供者或扩展框架功能的开发者使用的一个接口,SPI将服务接口和具体的服务分离开来,将服务调用方和服务实现者解耦,修改或替换服务的实现并不需要修改调用方。这也是Java提供的轻量级插件化机制。
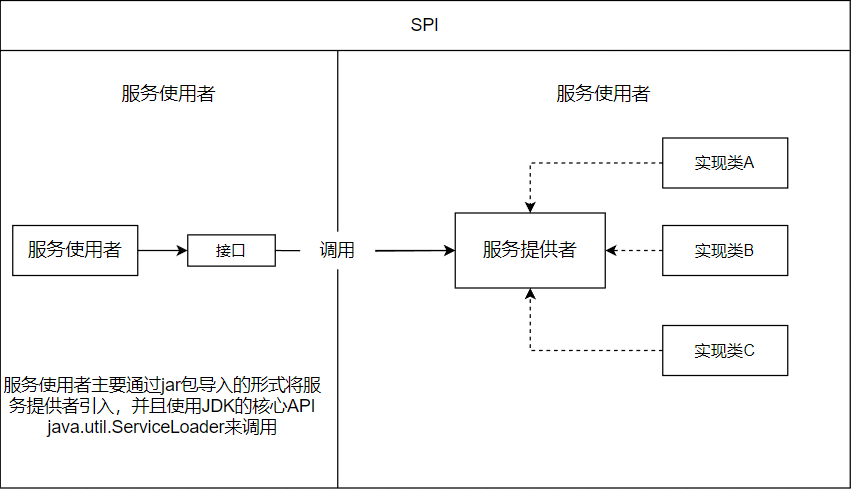
SPI的简单案例
搜索接口的定义:
public interface ResourceSearchService {
/**
* 根据资源类型批量获取资源数据
* @param resourceTypeAndIdDTO
* @return
*/ List<ResourceVO> getResourceDetail(ResourceTypeAndIdDTO resourceTypeAndIdDTO);
}
视频搜索实现
public class VideoResourceServiceImpl implements ResourceSearchService {
@Override
public List<ResourceVO> getResourceDetail(ResourceTypeAndIdDTO resourceTypeAndIdDTO) {
System.out.println("Search Video");
return null;
}
}
文献搜索实现
public class PaperResourceServiceImpl implements ResourceSearchService {
@Override
public List<ResourceVO> getResourceDetail(ResourceTypeAndIdDTO resourceTypeAndIdDTO) {
System.out.println("Search Paper");
return null;
}
}
在根目录下META-INF/service中定义.txt文件,文件类名为接口类全名,内容为实现类全名
//com.euneir.spi.core.ResourceSearchService.txt
com.euneir.spi.core.impl.PaperResourceServiceImpl
com.euneir.spi.core.impl.VideoResourceServiceImpl
测试类:
public class TestCase {
public static void main(String[] args) {
ServiceLoader<ResourceSearchService> service = ServiceLoader.load(ResourceSearchService.class);
Iterator<ResourceSearchService> iterator = service.iterator();
while (iterator.hasNext()) {
ResourceSearchService searchService = iterator.next();
searchService.getResourceDetail(new ResourceTypeAndIdDTO());
}
}
}
//Search Video
//Search Paper
ServiceLoader
ServiceLoader是JDK提供的工具类,ServiceLoader.load(Class service)创建ServiceLoader实例,在classpath中寻找所有META-INF/services目录下是否存在以接口全限定名命名的文件,如果存在就读取文件内容,获取实现类的全限定名,通过Class.forName进行类加载
加载类后,并不会立刻进行实例化,在懒加载迭代器LazyClassPathLookupIterator遍历的时候才会反射创建每个实现类的实例。
ServiceLoader类中有内部类:private final class LazyClassPathLookupIterator:
private final class LazyClassPathLookupIterator<T>
implements Iterator<Provider<T>>{
static final String PREFIX = "META-INF/services/";
}
所以文件要配置在META-INF/services/下。
ServiceLoader内部的是LazyClassPathLookupIterator,也就是懒加载,只有遍历器遍历的时候才会初始化配置文件
迭代器中读取META-INF/services/下配置文件的核心代码:
private Class<?> nextProviderClass() {
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null) {
configs = ClassLoader.getSystemResources(fullName);
} else if (loader == ClassLoaders.platformClassLoader()) {
// The platform classloader doesn't have a class path,
// but the boot loader might. if (BootLoader.hasClassPath()) {
configs = BootLoader.findResources(fullName);
} else {
configs = Collections.emptyEnumeration();
}
} else {
configs = loader.getResources(fullName);
}
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) { //扫描jar包下的配置文件
if (!configs.hasMoreElements()) {
return null;
}
pending = parse(configs.nextElement());
}
String cn = pending.next();
try {
return Class.forName(cn, false, loader); //Class.forName()
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found");
return null;
}
}
SPI的应用
JDBC4.0之前,注册数据库驱动的时候,通常会使用Class.forName进行类加载,然后再获取Connection;但是JDBC4.0之后不需要使用Class.forName加载驱动,可以直接获取Connection,就是使用了Java的SPI扩展机制来实现。
- 在MySQL中的实现:META-INF/services/java.sql.Driver.txt com.mysql.cj.jdbc.Driver
- 在postgresql中的实现:META-INF/services/java.sql.Driver.txt org.postgresql.Driver
MySQL加载过程的分析:
通过DriverManager调用getConnection方法时,会调用ensureDriversInitialized()方法,该方法核心代码:
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try {
while (driversIterator.hasNext()) {
driversIterator.next();
}
} catch (Throwable t) {
// Do nothing
}
return null;
}
});
if (drivers != null && !drivers.isEmpty()) {
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
用于加载各个数据库的驱动。
- 在Commons-Logging中的实现:Commons-Logging自带了日志实现类,但是功能比较简单,更多的是将Commons-Logging作为门面,底层实现依赖其他框架。Commons-Logging能够选择使用Log4j还是Logging,但是Commons-Logging并不依赖Log4j或Logging的API
抽象类LogFactory加载具体实现的步骤如下:
- SPI服务发现机制发现org.apache.commons.logging.LogFactory的实现
- 查看classpath根目录下的commons-logging.properties的org.apache.commons.logging.LogFactory属性是否指定factory实现
- 如果没有实现,就使用factory的默认实现org.apache.commons.logging.impl.LogFactoryImpl。如果有实现就构建实现类对象。
借助SPI就可以构建一个松耦合的日志系统。
SPI和API的区别
从效果上来看基本相同:
但是从结构上看略有区别:
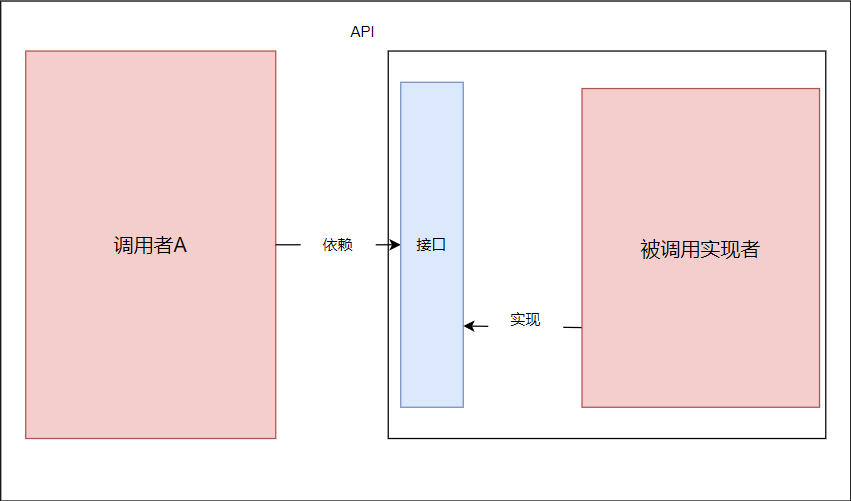
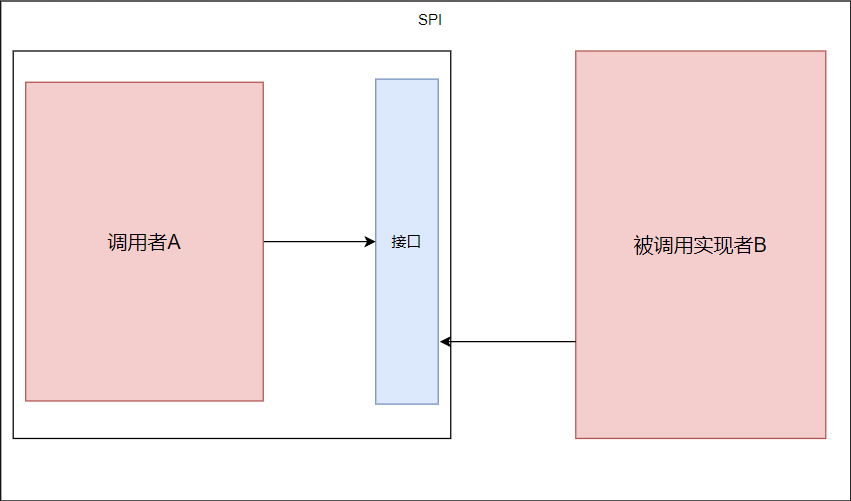
API依赖的接口位于实现者的包中,概念上更接近于实现方,组织上存在于实现者的包中,实现和接口同时存在在实现者的包中
SPI依赖的接口在调用方的包中,概念上更接近于调用方,组织上位于调用者的包中,实现逻辑的单独的包中,实现可插拔。
SPI的优点
- 松耦合:无需在编译时将实现类硬编码在Java代码中
- 扩展性
SPI的缺点
- 不能按需加载,需要遍历所有实现并且实例化,然后在循环中才能找到我们需要的实现。某些类实例化可能是非常耗时的。
- 获取某个实现类的方式不够灵活。只能通过Iterator的形式获取,不能根据某个参数获取(Spring的BeanFactory更高级)
- 多个线程并发时使用ServiceLoader类的实例是不安全的。
Spring的SPI机制在Java原生的SPI机制上进行了改造和扩展:
- 支持多个实现类:Spring的SPI允许为同一接口定义多个实现类,而Java的原生SPI机制只支持单个实现类,在应用程序中使用Spring的SPI机制更加灵活和可扩展
- 支持动态替换:Spring的SPI支持动态替换服务提供者,可以通过修改配置文件或其他方式来切换服务提供者,而Java原生的SPI机制只能在启动时加载一次服务提供者,并且无法在运行时动态替换。
- 提供更多扩展点:Spring的SPI提供了很多扩展点,例如BeanPostProcessor、BeanFactoryPostProcessor,可以在服务提供者的初始化和创建过程中进行自定义操作。
实现ServiceLoader
主要流程:
- 通过URL工具类从jar包的META-INF/services目录下找到对应的文件,读取这个文件的文件名找到对应的SPI接口。
- 读取文件内容,得到类全名,判断是否和SPI接口同一类型,如果是就反射构造相应的实例对象。
- 将构造出来的实例对象添加到Providers列表