MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度。在大语言模型时代被广泛使用,很多LLM都采用了MQA,如Falcon、PaLM、StarCoder等。
在介绍MQA 之前,我们先回顾一下传统的多头注意力
Multi-Head Attention(MHA)
多头注意力是transformer 模型的默认注意力机制,如下图所示:
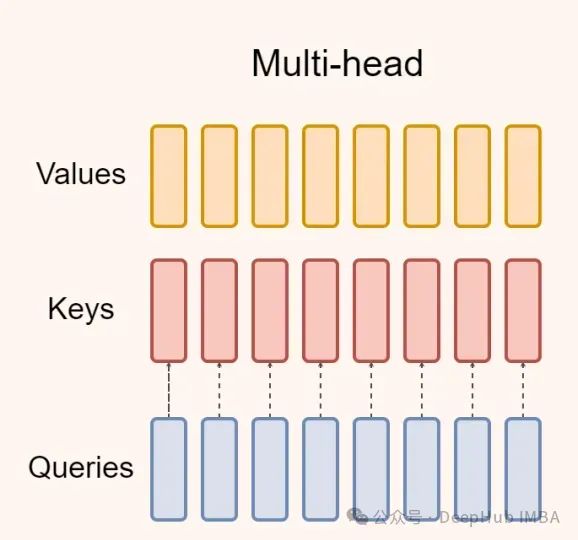
在文本生成方面,基于transformer 的自回归语言模型存在一个问题。在训练过程中可以获得真实的目标序列,并且可以有效地实现并行化。
https://avoid.overfit.cn/post/877de0f5a56d478d8133d75a05064e7e
标签:MQA,transformer,Attention,模型,Muti,LLM From: https://www.cnblogs.com/deephub/p/18058213