Large Language Model 模型对比
对于LLM模型框架主要如下3类[1]:1、autoregressive,2、autoencoding,3、encoder-decoder。主要对3类结构以及部分细节进行阐述。(对于框架分类其实多种,在此论文中[2]采用的是双向/单向结构)
| 模型 | 参数量 | 模型结构 |
|---|---|---|
| BERT | ||
| GLM | ||
| XLNet | ||
| SpanBERT | ||
| GPTv1 | Decoder-Only | |
| GPTv2 | ||
| GPTv3 |
TODO List:
\[\max_\theta\quad\log p_\theta(\mathbf{x})=\sum_{t=1}^T\log p_\theta(x_t\mid\mathbf{x}_{<t})=\sum_{t=1}^T\log\frac{\exp\left(h_\theta(\mathbf{x}_{1:t-1})^\top e(x_t)\right)}{\sum_{x^{\prime}}\exp\left(h_\theta(\mathbf{x}_{1:t-1})^\top e(x^{\prime})\right)} \]对于自回归以及自编码采用此论文[1:1]中数学描述。
自回归在逻辑:通过前面\(t\)段文字内容去对\(t+1\)的内容进行预测,数学上表述如下:
\[\max_\theta\quad\log p_\theta(\bar{\mathbf{x}}\mid\hat{\mathbf{x}})\approx\sum_{t=1}^Tm_t\log p_\theta(x_t\mid\hat{\mathbf{x}})=\sum_{t=1}^Tm_t\log\frac{\exp\left(H_\theta(\hat{\mathbf{x}})_t^\top e(x_t)\right)}{\sum_{x^{\prime}}\exp\left(H_\theta(\hat{\mathbf{x}})_t^\top e(x^{\prime})\right)} \]自编码结构主要是首先对文本进行"挖空"(
[MASK]去对文本进行标记),而后去对"挖空"内容进行预测,数学表述为:
公式中\(\approx\)在BERT模型中对于概率公式\(p(\overline{x}|\hat{x})\)是基于独立性假设的:所有的被[MASK]标记内容都被单独重构(all masked tokens \(\overline{x}\) are separately reconstructed)
其中:\(x_{<t}\)代表前\(t\)段文本,\(x_t\)代表预测的\(t\)位置文本,\(h_{\theta}(x_{1:t-1})\)代表神经网络模型(RNN/Transformer),\(e(x)\)代表\(x\)的编码内容,\(\overline{x}\)代表
[MASK]内容
因为
BERT此类模型是双向结构,那么对于文本的处理上存在天然优势(更好的去理解上下文),因此在后续的自回归的模型框架上,都在尝试加入 "双向" 结构,去让模型更加好的理解文本的内容。
1、Autoregressive
1.1 Generative Pre-Training
- Generative Pre-Training v1**
对于大部分的深度学习任务,需要大量的标记数据(labeled data),但是如果使用大量的标记数据就会导致一个问题:构建得到的模型缺少适用性(可以理解为模型的泛化性能可能不佳)。那么就尝试使用非标记的数据(unlabelled data)但是这样一来又会有一个新的问题:时间消费大(time-consuming and expensive)。所以目前学者提出:使用预训练的词嵌入来提高任务性能。使用 未标注的文本信息(word-level information from unlabelled text)可能会:1、不清楚那种优化目标(optimization objective)在学习对迁移有用的文本表示时最有效;2、如何将这些学习到的表征有效的迁移到目标任务(target task)中。
作者提出:1、无监督的预训练(unsupervised pre-training);2、监督的微调(supervised fine-tuning)
1、Unsupervised pre-training
给定一些列的的 无标签的 token:\(U=\{u_1,...,u_n\}\),构建自回归的模型:\(L_1(U)= \sum_{i}logP(u_i|u_{i-k},...,u_{i-1}; \theta)\),其中\(\theta\)为模型的参数。作者在模型中使用Transformer作为decoder,在最后的模型上作者构建得到为:
其中\(n\)代表神经网路层的数目,\(W_e\)代表token embedding matrix,\(W_p\)代表position embedding matrix。对于无监督下的预训练:通过构建的数据集,去对模型的参数进行训练,得到模型的参数。
2、Supervised fine-tunning
作者在此部分提到:通过第一步得到的模型参数去对监督任务进行训练(采用的模型结构是没有变化的)。给定标签数据集\(C\),给定输入:\(\{x^1,...,x^m \}\)以及其标签\(y\)。将数据投入到预训练得到的模型参数里面得到:\(h_l^m\),然后添加一个线性输出层(参数为:\(W_y\))去对\(y\)进行预测。
\[P(y|x^1,...,x^m)=softmax(h_l^wW_y) \]对于上述两部分步骤直观上理解:人首先从外界获取大量信息:网络,书本等,把这些信息了解之后,然后去写作文或者去回答问题。
模型结构:
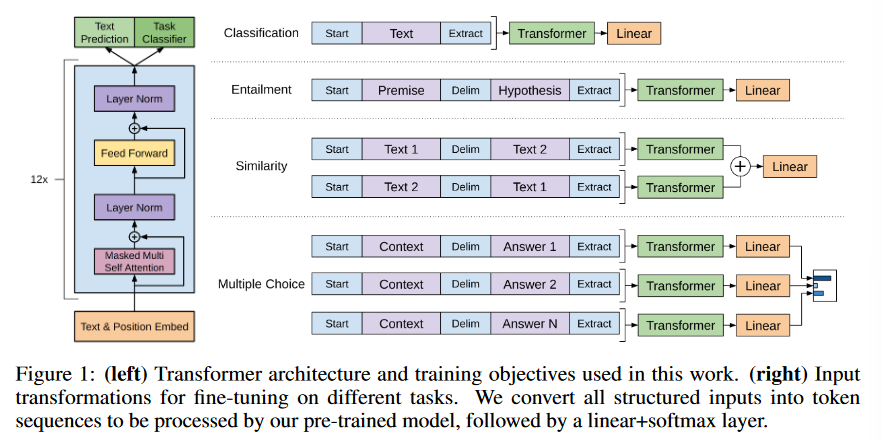
- GPTv2
1.2 XLNet[3]
模型创新点
- 1、对"排序"进行打乱(
all possible permutations of the factorization order)
注:对"排序"打乱不是指将文本里面文字随机打乱,而是将
Masked Attention中MASK进行打乱,如下图最右侧描述
模型框架如下:
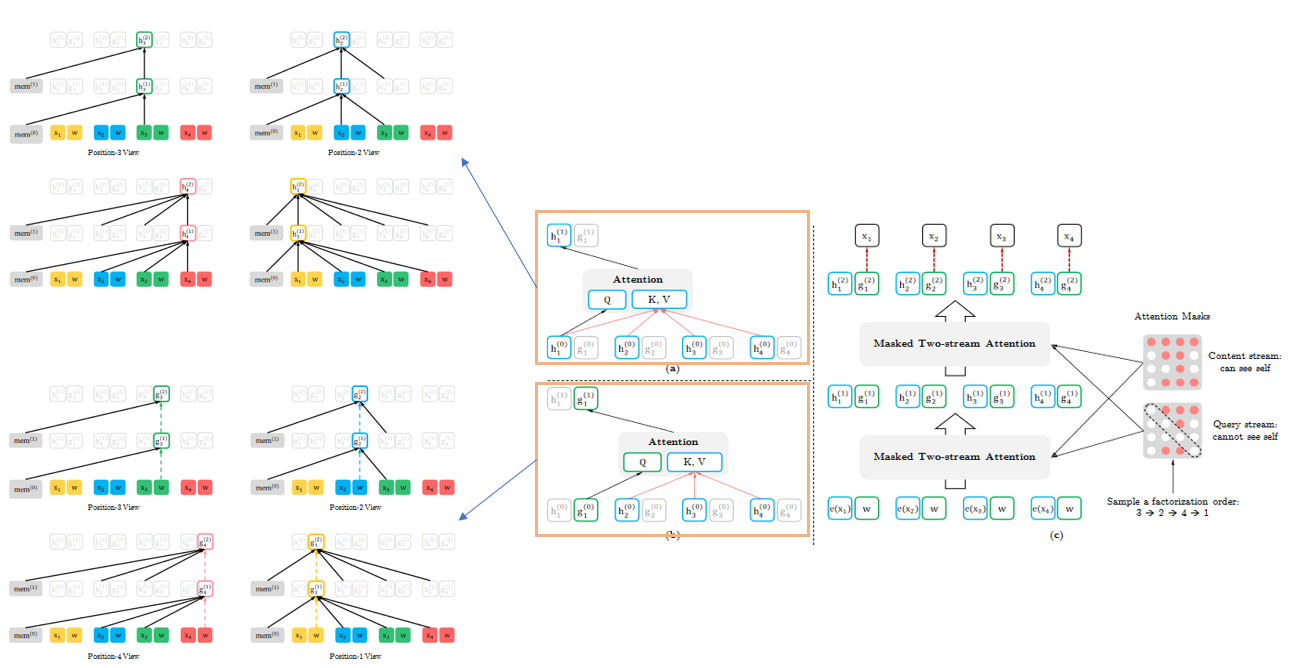
在结构上作者认为标准的语言模型在置换目标时效果不佳,比如说:对于两段文本AC和AB在自回归中模型都获取到A的信息,而后去对后续的B/C进行预测,效果显然会差强人意。因此作者提出两部分表示并且对预测目标进行改进:
- 预测目标
- 两部分表示(上图最左侧内容表示,上述内容都是\(3\rightarrow 2\rightarrow 4\rightarrow 1\),虚线代表获取不到信息)
1、The content represenation(\(h_{\theta}\)) || 内容表示:与传统的Transformer中的隐藏单元作用相同,同时对 内容 和 预测内容\(x_{z_t}\)进行编码
2、The query represenation(\(g_{\theta}\)) || 查询表示:只获取\(x_{z<t}\)内容以及预测内容位置\(z_t\)的信息 - 部分预测
对于减少模型的优化难度,作者对自回归的预测内容改进,原始的是“逐一”,而作者提出直接“部分”也就是说先获取\(z_{<c}\)的内容而后去对\(z{>c}\)的内容进行预测。设置超参数\(K\)用来设置文本的长度
1.3 General Language Model[1:2]
国产大模型,对于GLM模型在整体思路上还是自回归的思路,不过在文本预训练上提出俩部分改进:1、Span shuffling;2、2D positional encoding。对于NLU(natural language understanding)有意思的将他们比作“完形填空”(cloze question)。模型的框架:
1、Auto-regressive blank infilling
2、Multi-Task Pretraining
2、Autoencoding
2.1 BERT[2:1]
模型创新点
1、Masked LM(MLM)
2、Next Sentence Prediction(NSP)
- 缺点
1、BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy(忽略了屏蔽位置之间的依赖性,并遭受预训练微调差异的影响)[1:3]
这是因为在
BERT模型中,在预训练阶段会添加[MASK],但是在下游任务(downsteram tasks)中并不会使用[MASK]
- 优点
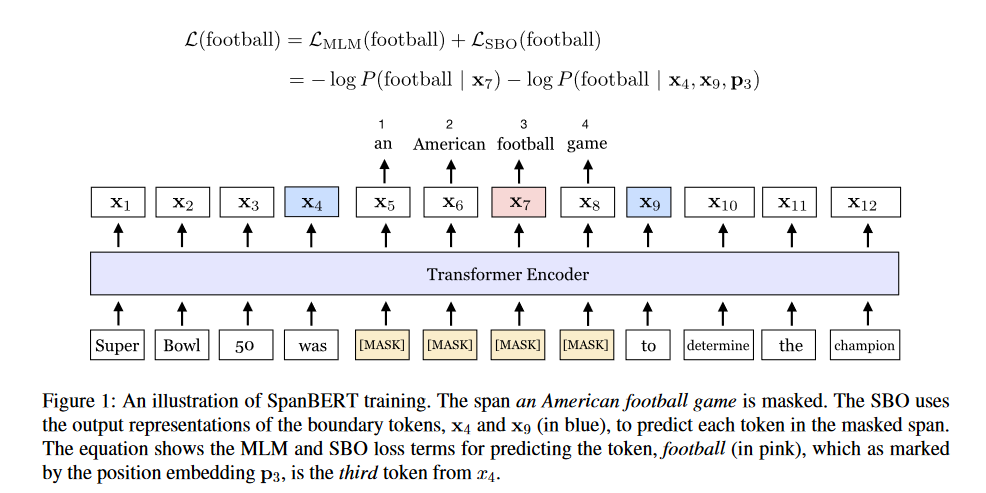
2.2 SpanBERT[4]
模型创新点
SpanBERT逻辑上还是和BERT相同,对BERT中MLM和NSP就行改进
- 1、使用随机连续的
Span(use a different random process to mask spans of tokens, rather than individual ones)保持和
BERT相同的[MASK]比例(80%的内容[MASK]标记,10%的内容随机替换,10%保持不变),不过在SpanBERT中MASK操作做出了改进:1、在确定比例之后,通过几何分布(geometric distribution | \(Geo(p) \ p=0.2\))来确定单词数量;2、然后随机的选择MASK要开始的位置。不过需要注意的是:在SpanBERT中MASK的内容是连续的,而BERT是不连续的。 - 2、设计
SBO(which tries to predict the entire masked span using only the representations of the tokens at the span’s boundary)
\[\begin{aligned} \mathcal{L}(x_{i})& =\mathcal{L}_{\mathbf{MLM}}(x_i)+\mathcal{L}_{\mathbf{SBO}}(x_i) \\ &=-\log P\left(x_i\mid\mathbf{x}_i\right)-\log P\left(x_i\mid\mathbf{y}_i\right) \end{aligned} \]
\[y_i=f(x_{s-1},x_{e+1},p_{i-s+1}) \]Span Boundary Objective原理:
假设一段输入文本:\(x_1,...,x_n\),通过第一步得到连续的MASK内容:\((x_s,...,x_e)\),那么对\(x_i\)的预测通过MASK外的内容(\(s-1,\ e+1\))来以及其所在位置(\(i-s+1\))对MASK内的内容就行预测:对于函数\(f\)使用的是2层的前馈神经网络:
\[h_0\ =\ [x_{s-1};x_{e+1},p_{i-s+1}] \\ h_1\ =\ LayerNorm(GeLU(W_1h_0))\\ y_i\ = \ LayerNorm(GeLU(W_2 h_1)) \]损失函数:交叉熵损失函数(
cross-entropy loss)。对所有损失函数进行相加: - 3、对样本随机采集连续文本作为样本,而非
BERT中的NSP(samples a single contiguous segment of text for each training example)
模型框架:
3、Encoder-Decoder
4、下游任务
4.1 General Language Understanding Evaluation
5、模型细节
5.1 高斯线性激活函数(GeLU)[5]
其在思想上结合ReLU(对输入有选择归零/保持不变)以及dropout(对输入随机归零)特点,函数定义为:
\[ 标签:BERT,mathbf,模型,MASK,各类,LLM,theta,文本 From: https://www.cnblogs.com/Big-Yellow/p/18031642