Abstract
本文提出了一个多行为自监督学习框架,以及一种自适应优化方法。具体而言,我们设计了一个行为感知的图神经网络,结合自注意力机制来捕捉行为的多样性和依赖关系。为了增强对目标行为下的数据稀疏性和辅助行为的嘈杂交互的鲁棒性,我们提出了一种新的自监督学习范式,以在行为间和行为内进行节点自我区分。此外我们通过对梯度进行混合操作开发了一种定制的优化策略,以自适应地平衡自监督学习任务和主要的有监督推荐任务。
Introduction
目前多行为推荐面临的挑战有:
对数据稀疏性和交互噪声的鲁棒性
尽管辅助行为的交互数据可以为目标行为的推荐提供非常互补的信息,但是目标行为下的数据稀疏性仍然是一个问题。CML提出了通过在每个辅助行为和目标行为对之间进行对比学习,充分利用了来自辅助行为的监督信号。然而辅助行为可能包含有害于目标任务的噪声交互。因此简单的采用CML中的对比学习范式可能会加剧对辅助行为中噪声分布的负面传递,严重削弱目标行为的真实语义。所以综合和自适应地理由交互数据的方法在性能提升中起着至关重要的作用。
辅助行为和目标任务之间的优化不平衡
现有的多行为推荐解决方案基本上采用多任务学习(MTL)范式来共同优化辅助任务和目标任务。然而忽视每个任务对优化目标的贡献可能会导致严重的优化不平衡问题,其中辅助任务可能主导网络圈子,从而导致目标任务的性能下降。此外,现有的多任务学习方法不适用于将自监督学习任务视为辅助任务的情况,因为SSL任务对目标任务有干扰效应。因此多行为推荐中的另一个关键问题是优化方法的设计,以减轻辅助任务和目标任务之间的优化不平衡。
为了实现这个目标,我们提出了一种名为MBSSL的多行为自监督学习解决方案,以确保多行为推荐的性能
具体而言,我们首先设计了一个行为感知的图神经网络,增加了行为表示学习和自注意力机制,共同建模行为内部上下文和行为间的依赖关系。为了处理目标行为下的稀疏监督信号,我们引入了一个全面的自监督学习范式,分别总行为间和行为内层面对节点进行对比,行为间的自监督学习通过构建负节点对,将信息丰富的语义从辅助行为传递到目标行为。为了进一步增强对噪声交互的鲁棒性,行为内的自监督学习在目标行为中巩固自监督信息,以抵消行为间自监督学习可能带来的负面传递。此外,基于SSL任务相对于目标任务呈现任意优化趋势的观察,我们设计了一种多行为优化方法,通过混合修正梯度的方向和大小,在优化中平衡SSL任务和目标任务。
本文的主要贡献如下:
- 在多行为推荐推荐中开发了一个名为MBSSL的新的自监督学习的框架,它包含了一个行为感知的图神经网络,用于揭示潜在的跨行为依赖关系,并且在行为间和行为内层面上采用了全面的自监督学习范式以减轻数据稀疏性和交互噪声的问题。
- 第一个研究SSL任务和目标推荐任务之间优化不平衡问题,提出了一种混合梯度操作方法,同时调整梯度的大小和方向,以调整优化趋势
Methodology
MBSSL的总体结构如下:
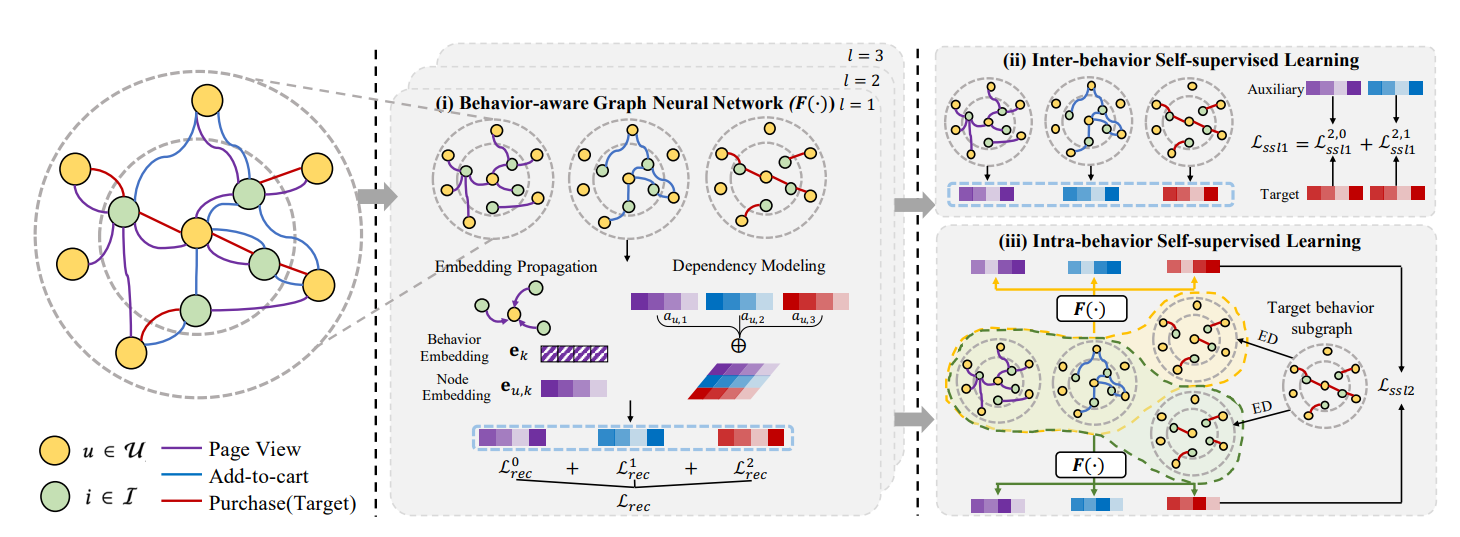
MBSSL的框架包含三个关键部分
- 行为感知的图神经网络,共同捕捉行为上下文和依赖关系
- 行为间自监督学习,促进知识传递
- 行为内自监督学习,对抗噪声交互
行为感知的图神经网络
用在特定行为下的项目嵌入和该行为的嵌入乘积来进行聚合,得到下一层的该行为下的用户嵌入。行为的嵌入通过上一层的行为嵌入来进行更新。
因为不同的行为会以一种隐式的方式相互交织,且行为之间的相关性因用户而异,我们利用自注意力机制来建模交叉行为依赖
我们将节点u在所有行为下的嵌入进行连接,然后计算反映用户u行为k与其他行为之间的依赖性系数\(a_{u,k}\)
\(\mathbf{a}_{u,k}=\text{softmax}((\mathbf{W}_2^k)^T\mathrm{tanh}((\boldsymbol{e}_u\mathbf{W}_1^k)^T))\)
在行为k下,节点u的增强嵌入可以计算为:
\(e_{u,k}=a_{u,k}e_u\)
最后进行平均池化操作
多行为的自监督学习
行为间的自监督学习
由于辅助行为中的自监督信号比目标行为中的自监督信号丰富的多,所以我们对辅助行为与目标行为进行选择性对比学习,以实现知识转移,从而缓解第一步数据的稀疏性
特别是将每个辅助行为与目标行为进行对比,以提供不同的语义。通常将同一节点的视图视为正对,将不同节点的视图视为负对。然而在封装各种交互的推荐设置中,相同的两个主题将有一些共同之处。在这种情况下,按照创建的做法来构建负对可能会产生很多假阴性,即高度相似的节点,这会丢弃真正的语义信息,因此我们提出使用swing算法基于计算出的相似度评分来寻找潜在的假阴性,并在对比节点对时消除它们
使用swing算法计算子图中的两用户u,v之间的相似度为:
最终的相似度得分为每个子图中得分的平均值
然后我们将u的假阴性定义为具有top-N相似度得分的用户,因为目标行为K与辅助行为k之间的行为对比损失计算时需要去掉假阴性用户,定义为:
\(\mathcal{L}_{ss\boldsymbol{l}_1}^{K,k}=\mathcal{L}_{ss\boldsymbol{l}_1,\boldsymbol{u}\boldsymbol{s}\boldsymbol{e}\boldsymbol{r}}^{K,k}+\mathcal{L}_{\boldsymbol{s}\boldsymbol{l}_1,\boldsymbol{i}\boldsymbol{t}\boldsymbol{e}\boldsymbol{m}}^{K,\boldsymbol{k}}.\)
\(\mathcal{L}_{ssl1}=\mathcal{L}_{ssl_1}^{K,1}+...+\mathcal{L}_{ssl_1}^{K,k}+...+\mathcal{L}_{ssl_1}^{K,K-1}\)
行为内的自监督学习
为了缓解不同行为间的数据分布,行为间自监督学习鼓励目标行为和辅助行为下节点表示的相似性。然而由于辅助行为下噪声交互的比例较高,更多的噪声也会隐式地转移到目标行为中,使学习到的表征由辅助信号主导,而失去了目标行为下的内在语义。因此我们设计了一个行为内的自监督学习来生成和对比目标行为子图的结构增强视图,通过这种方式,我们巩固和放大目标行为本身内监督信号的影响,以抵消辅助行为中对噪声分布的负转移。具体来说,我们首先执行边缘退出,从目标行为子图中生成两个增强视图
\(G_{K}^{1}=(\mathcal{V}_{K},\mathbf{M}_{1}\odot\mathcal{E}_{K}),\quad\mathcal{G}_{K}^{2}=(\mathcal{V}_{K},\mathbf{M}_{2}\odot\mathcal{E}_{K})\)
M是随机掩码向量
分别将两个增强视图与辅助行为子图进行编码后,得到了增强视图的节点表示,然后我们使用InfoNCE损失来进行对比
自适应的多行为优化
这里损失函数没有采用传统的BPR Loss,而是采用了非抽样目标来进行推荐,非抽样损失为:
\[\begin{aligned}\mathcal{L}_{rec}^k&=\sum_{u\in\mathcal{B}}\sum_{i\in I_u^{k+}}\left((c_i^{k+}-c_i^{k-})(\hat{x}_{u,i}^k)^2-2c_i^{k+}\hat{x}_{u,i}^k\right)\\&+\sum_{m=1}^d\sum_{n=1}^d\left((\mathbf{e}_k^{(m)}\mathbf{e}_k^{(n)})(\sum_{u\in\mathcal{B}}\mathbf{e}_{u,k}^{(m)}\mathbf{e}_{u,k}^{(n)})(\sum_{i\in I}\mathbf{e}_{i,k}^{(m)}\mathbf{e}_{i,k}^{(n)})\right)\end{aligned} \]\(\hat{x}_{u,i}^k\)表示用户u在行为k下与项目i交互的估计概率。\(I_{u}^{k+}\)表示用户u在行为k下的交互项,两个c是超参数,主推荐任务的损失是每个行为下推荐损失的加权和
\(\mathcal{L}_{rec}=\sum_{k=1}^K\lambda_k\mathcal{L}_{rec}^k.\)
最后的总体损失函数为:
接下来就是比较有意思的部分,在梯度上的混合操作
梯度混合操作
目前的SSL任务有两个限制,一方面是忽略了任务间显著优化不平衡的可能性,可能会恶化目标任务的性能,因为手动设计的方式下,SSL的任务几乎不能与目标任务完全一致,另一方面,调整多个辅助任务是很耗时的,而且固定的权重不适用于整个动态训练过程中的所有批次。所以我们开发了一种自适应优化的SSL推荐模型的方法,并对梯度的大小和方向进行了混合操作
后面就是在讲,我们怎么动态改变辅助任务优化时的梯度,使得其比目标任务优化时的梯度小,从而减少对目标任务优化时的影响
算法的具体流程如下:

Conclusion
在这项工作中,我们开发了一个新的自监督学习框架,配合自适应优化方法,以增强多行为推荐。我们的框架通过结合自注意力机制的图神经网络有效地捕捉行为语义和相关性。为了减轻数据稀疏性和嘈杂交互问题,我们分别通过行为间自监督学习和行为内自监督学习对节点进行对比。此外我们首次研究了自监督学习任务和推荐任务之间的优化不平衡,并相应地设计了梯度的混合操作方法。
标签:Multi,mathbf,Self,boldsymbol,任务,监督,Learning,mathcal,行为 From: https://www.cnblogs.com/anewpro-techshare/p/18025553