原作:伊格纳西奥·德格雷戈里奥
引言:文本到视频的新境界

著名商学教授斯科特·加洛韦 (Scott Galloway) 打赌,2024 年将是谷歌的人工智能年。
现在看起来似乎正在成为现实。
今天,谷歌推出了 Lumiere,这是文本到视频领域的巨大突破,是当今生成人工智能中最艰巨的任务之一。而且就其实现的影响而言,可能是迄今为止尚未达到的最重要里程碑,因为一旦实现,它将永久改变像好莱坞、YouTube或CGI 这样的行业。
现在,谷歌已经让我们更进一步,因为它对于人工智能视频合成的方法不仅是革命性的,而且展示了令人难以置信的视频质量和各种令人惊叹的技巧,如视频修补、图像动画和视频风格化,使其成为该领域的新标准。
但它是如何生成视频的呢?
看起来像魔法,但事实并非如此。让我们揭开它的秘密。
永恒的难题
在所有数据模式中,视频无疑是最难用人工智能生成的。
然而,考虑到视频只是图像(称为帧)的串联,以每秒一定的帧速率显示(fps 越高,视频越平滑),构建文本到视频(T2V)系统的合理路径是从一个文本到图像模型(T2I)出发,比如DALL-e或Stable Diffusion。
然而,T2V增加了一个额外的复杂维度:时间。
也就是说,仅仅生成多个帧还不够(你可以使用T2I模型生成所需数量的帧),它们必须随着时间的推移保持一致。
换一种说法,如果您要生成有关狮子的视频,则必须确保狮子在所有帧上看起来都相似。
事实证明,这是一个巨大的难题,因为在多个帧之间保持结构的复杂性使得人工智能视频变得非常短,并且它们往往会展示出瑕疵,例如下面这个由人工智能生成的视频中突然出现的橙色斑点。

这些不一致的原因在于这些模型的构建方式,我们很快将解释Lumiere如何彻底改变这种方法。
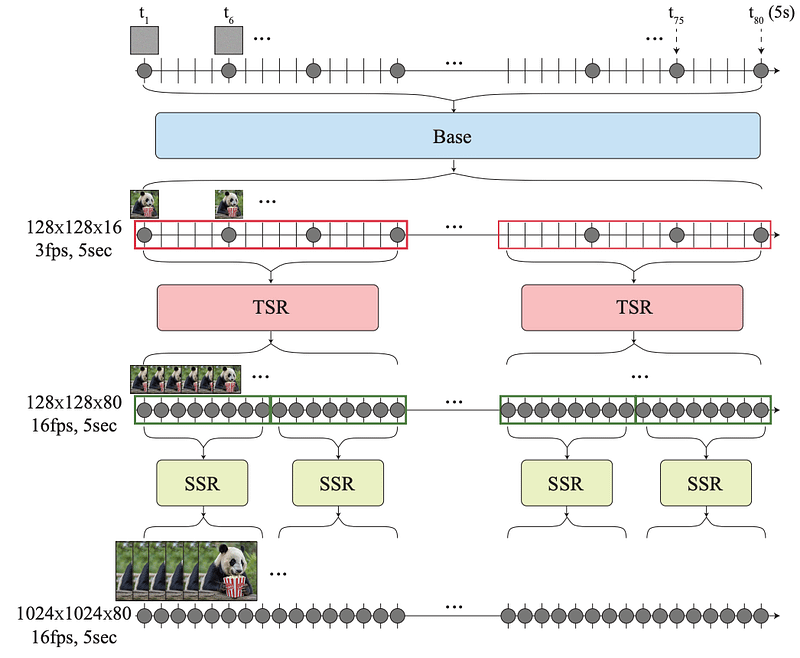
最初,视频合成过程涉及三个步骤:
- 文本到图像(T2I)模型生成了一组关键帧,这些帧覆盖了整个视频的完整持续时间。
- 接下来,几个 TSR(时间超分辨率)模型用一组新帧“填充”了关键帧之间的间隙。例如,如果两个关键帧分别是一个认真的人和同一个人微笑着,那么TSR模型将生成完整的中间帧,产生微笑的动作。
- 然后,一组 SSR(空间超分辨率)将获取低分辨率帧并对其进行升级以提高视频质量,因为大多数文本到视频模型在低分辨率像素空间(或者在某些情况下,在矢量空间,如Stable Diffusion)中工作,这样可以实现更高效和更便宜的处理过程。
- 最后,将SSR的输出进行“拼接”,从而得到视频。
最重要的是,人工智能视频只是采用图像生成器并对其进行训练,使其随时间批量生成某种程度一致的图像,并将它们拼凑在一起。
这确实有效……但也存在一些问题。
就像在拍摄一个演员的片段过程中,他突然脱离角色,你试图通过强迫他保持特定的姿势来完成剩下的片段,避免失去前半部分一样,无论你如何编辑,裁剪是会可见的。
此外,由于该过程涉及使用几种不同类型的模型,这些模型并不总是共享相同的经验和表征(即它们对概念的理解方式),这使得它极易出错。
考虑到这些限制,视频生成似乎还不够完善。但是通过谷歌的Lumiere项目,我们可能正在见证一项重大进展的开始。
空间、时间和多重扩散
就像图像生成器一样,文本到视频(T2V)模型主要是扩散模型。
扩散模型是一种通过去噪过程学习将嘈杂的数据分布映射到目标分布的AI系统。
通俗地说,他们采用噪声图像和文本条件(即你期望的最终结果),然后逐渐去除图像中的噪声,直到得到所需的结果。

可以将扩散过程类比为将一个大理石块,就像米开朗基罗一样,逐渐雕刻出多余的大理石,从而“挖掘”出雕像。
将扩散过程想象为取出一块大理石块,就像米开朗基罗一样,雕刻出多余的大理石以“挖掘”雕像。
然而,Google 没有遵循我们之前描述的标准程序,而是通过创建 STUnet 找到了替代方案。
那么STUnet是什么呢?
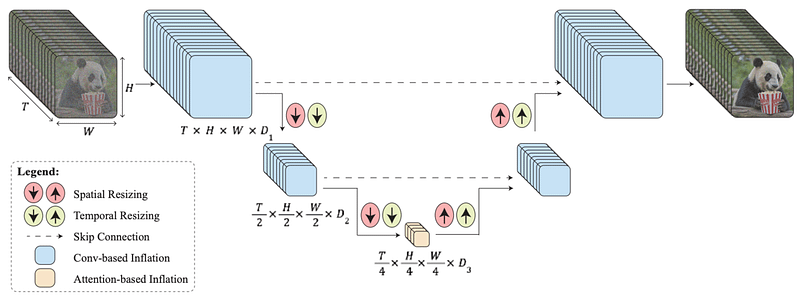
UNet是一种架构,它对图像进行下采样、处理并生成一组新的图像。
换句话说,它接收一组噪声样本(如上图中显示的模糊图像)并生成一组新的高质量图像,这些图像也彼此一致连贯以生成视频。
为了做到这一点,在处理图像时应用卷积(以理解图像所见内容)的同时,还能对图像进行下采样(使其变小)。
一旦压缩足够,就会对其应用注意力机制(就像ChatGPT在文本序列上应用注意力那样,但是应用在图像的压缩表示上,以更好地把握图像中出现的概念,比如熊猫),然后将它们恢复成像素空间,从而得到期望的图像。
然而,STUnet还包括时间卷积和注意力机制,这意味着它压缩了时间。
换句话说,虽然空间卷积和注意力机制专注于处理和确保生成的图像符合用户的要求,但是时间卷积和注意力机制确保整个图像集在时间上是一致的。
这听起来很抽象,但STUnet基本上不仅理解每帧代表什么,而且还理解不同帧之间的关系。
换句话说,不仅要捕捉画面中描绘的熊猫,还要捕捉熊猫随着时间的推移应该做什么动作。
事实上,生成过程是“时间感知”的,Lumiere 可以一次性创建视频中的所有帧(而不是我们之前讨论的通常的关键帧 + 级联帧填充),因此STUnet只需要专注于捕捉帧的语义并将其放大到实际的视频中。
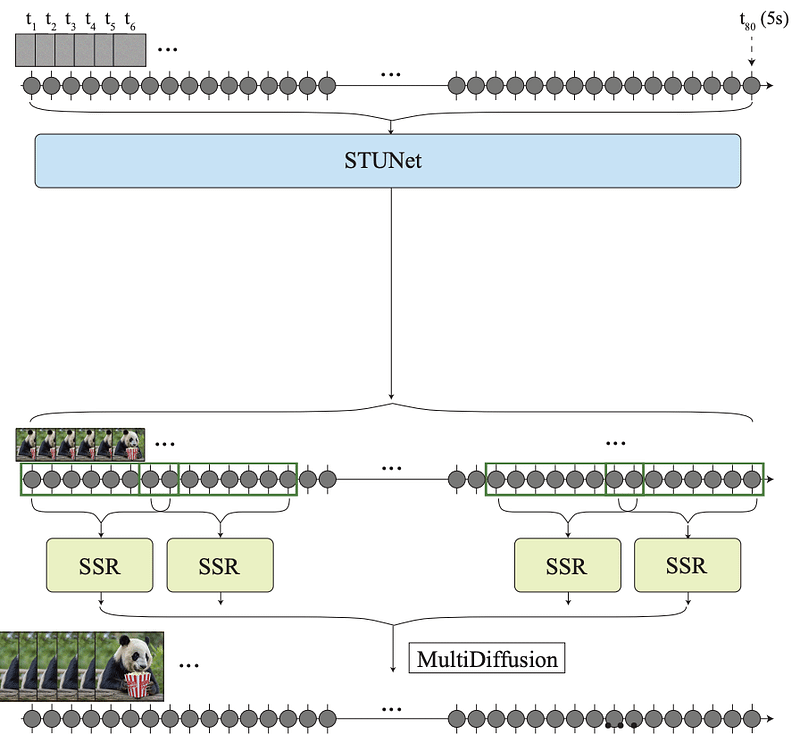
然而,由于内存限制,您仍然需要许多 SSR 模型来放大图像,这意味着最后仍然需要进行一些“拼接”。
因此,为了避免每个 SSR 的放大输出之间的不一致,他们应用了 MultiDiffusion(Bar-Tal 等人,2023)。
这样做的目的是通过使用MultiDiffuser确保在不同生成的帧批次之间的一致性。
简而言之,MultiDiffuser允许同时在一帧上进行多个图像生成过程。
例如,您可以创建一个“模糊图像”,同时对图像的某些区域应用并行生成,比如在图像的特定部分绘制“一只老鼠”或“一堆书”。

关键的直觉是,MultiDiffuser确保无论你通过单独的扩散过程在图像的那些片段中生成什么,它们都与整体作品一致。
技术提示:这是通过在标准一代“之上”应用额外的生成步骤来实现的,并且这些生成步骤必须符合一个额外的目标函数,该函数测量了并行生成的数据分布之间的“差异”。
换句话说,MultiDiffuser 允许您在原始内容上“绘制”新内容,同时尽可能保留原始结构。
因此,该组件确保对于需要拼接的视频的多个帧批次,您可以重新创建不同SSR模型输出之间的边界,以使它们保持一致,从而确保片段之间的平滑过渡。

您可以将MultiDiffuser想象成使用Photoshop在SSR模型放大的不同补丁之间“平滑处理”边界,就像视频编辑器希望确保在批次之间不会出现任何切割一样。
它可以使图像的某些部分动起来,
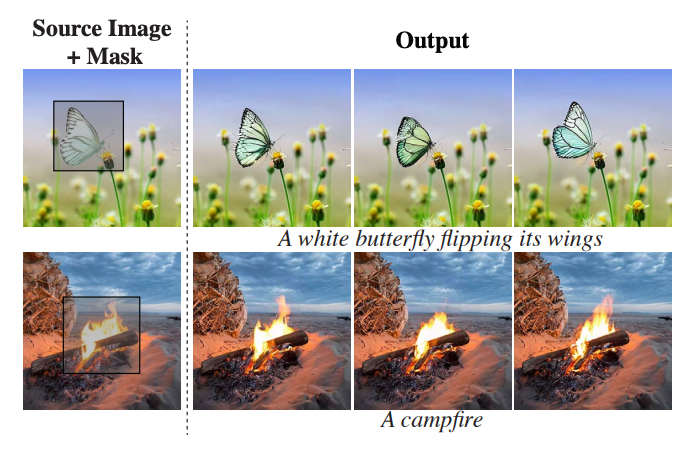
修复新的对象和概念:

除此之外,您还可以在这里查看其他令人惊叹的功能:查看由Lumiere生成的视频。
视频新时代
借助 Lumiere,我们可以清楚地看到视频生成、编辑和动画等领域的未来方向。
很快,任何人都能够在短时间内从零开始创建令人印象深刻的视频,从而创造一个充满可能性的新世界。
尽管取得了令人印象深刻的成果,但感觉我们只看到了冰山一角。
标签:视频,令人惊叹,模型,谷歌,生成,Lumiere,图像,文本 From: https://www.cnblogs.com/Leap-abead/p/18015836