面向程序员的 FastAI 和 PyTorch 深度学习(八)
原文:Deep Learning for Coders With Fastai and Pytorch
译者:飞龙
第三部分:深度学习的基础。
第十二章:从头开始的语言模型
我们现在准备深入…深入深度学习!您已经学会了如何训练基本的神经网络,但是如何从那里创建最先进的模型呢?在本书的这一部分,我们将揭开所有的神秘,从语言模型开始。
您在第十章中看到了如何微调预训练的语言模型以构建文本分类器。在本章中,我们将解释该模型的内部结构以及 RNN 是什么。首先,让我们收集一些数据,这些数据将允许我们快速原型化各种模型。
数据
每当我们开始处理一个新问题时,我们总是首先尝试想出一个最简单的数据集,这样可以让我们快速轻松地尝试方法并解释结果。几年前我们开始进行语言建模时,我们没有找到任何可以快速原型的数据集,所以我们自己制作了一个。我们称之为Human Numbers,它简单地包含了用英语写出的前 10000 个数字。
Jeremy 说
我在高度经验丰富的从业者中经常看到的一个常见实际错误是在分析过程中未能在适当的时间使用适当的数据集。特别是,大多数人倾向于从太大、太复杂的数据集开始。
我们可以按照通常的方式下载、提取并查看我们的数据集:
from fastai.text.all import *
path = untar_data(URLs.HUMAN_NUMBERS)
path.ls()
(#2) [Path('train.txt'),Path('valid.txt')]
让我们打开这两个文件,看看里面有什么。首先,我们将把所有文本连接在一起,忽略数据集给出的训练/验证拆分(我们稍后会回到这一点):
lines = L()
with open(path/'train.txt') as f: lines += L(*f.readlines())
with open(path/'valid.txt') as f: lines += L(*f.readlines())
lines
(#9998) ['one \n','two \n','three \n','four \n','five \n','six \n','seven
> \n','eight \n','nine \n','ten \n'...]
我们将所有这些行连接在一个大流中。为了标记我们从一个数字到下一个数字的转变,我们使用.作为分隔符:
text = ' . '.join([l.strip() for l in lines])
text[:100]
'one . two . three . four . five . six . seven . eight . nine . ten . eleven .
> twelve . thirteen . fo'
我们可以通过在空格上拆分来对这个数据集进行标记化:
tokens = text.split(' ')
tokens[:10]
['one', '.', 'two', '.', 'three', '.', 'four', '.', 'five', '.']
为了数值化,我们必须创建一个包含所有唯一标记(我们的词汇表)的列表:
vocab = L(*tokens).unique()
vocab
(#30) ['one','.','two','three','four','five','six','seven','eight','nine'...]
然后,我们可以通过查找每个词在词汇表中的索引,将我们的标记转换为数字:
word2idx = {w:i for i,w in enumerate(vocab)}
nums = L(word2idx[i] for i in tokens)
nums
(#63095) [0,1,2,1,3,1,4,1,5,1...]
现在我们有了一个小数据集,语言建模应该是一个简单的任务,我们可以构建我们的第一个模型。
我们的第一个从头开始的语言模型
将这转换为神经网络的一个简单方法是指定我们将基于前三个单词预测每个单词。我们可以创建一个包含每个三个单词序列的列表作为我们的自变量,以及每个序列后面的下一个单词作为因变量。
我们可以用普通的 Python 来做到这一点。首先让我们用标记来确认它是什么样子的:
L((tokens[i:i+3], tokens[i+3]) for i in range(0,len(tokens)-4,3))
(#21031) [(['one', '.', 'two'], '.'),(['.', 'three', '.'], 'four'),(['four',
> '.', 'five'], '.'),(['.', 'six', '.'], 'seven'),(['seven', '.', 'eight'],
> '.'),(['.', 'nine', '.'], 'ten'),(['ten', '.', 'eleven'], '.'),(['.',
> 'twelve', '.'], 'thirteen'),(['thirteen', '.', 'fourteen'], '.'),(['.',
> 'fifteen', '.'], 'sixteen')...]
现在我们将使用数值化值的张量来做到这一点,这正是模型实际使用的:
seqs = L((tensor(nums[i:i+3]), nums[i+3]) for i in range(0,len(nums)-4,3))
seqs
(#21031) [(tensor([0, 1, 2]), 1),(tensor([1, 3, 1]), 4),(tensor([4, 1, 5]),
> 1),(tensor([1, 6, 1]), 7),(tensor([7, 1, 8]), 1),(tensor([1, 9, 1]),
> 10),(tensor([10, 1, 11]), 1),(tensor([ 1, 12, 1]), 13),(tensor([13, 1,
> 14]), 1),(tensor([ 1, 15, 1]), 16)...]
我们可以使用DataLoader类轻松地对这些进行批处理。现在,我们将随机拆分序列:
bs = 64
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:], bs=64, shuffle=False)
现在我们可以创建一个神经网络架构,它以三个单词作为输入,并返回词汇表中每个可能的下一个单词的概率预测。我们将使用三个标准线性层,但有两个调整。
第一个调整是,第一个线性层将仅使用第一个词的嵌入作为激活,第二层将使用第二个词的嵌入加上第一层的输出激活,第三层将使用第三个词的嵌入加上第二层的输出激活。关键效果是每个词都在其前面的任何单词的信息上下文中被解释。
第二个调整是,这三个层中的每一个将使用相同的权重矩阵。一个词对来自前面单词的激活的影响方式不应该取决于单词的位置。换句话说,激活值会随着数据通过层移动而改变,但是层权重本身不会从一层到另一层改变。因此,一个层不会学习一个序列位置;它必须学会处理所有位置。
由于层权重不会改变,您可能会认为顺序层是“重复的相同层”。事实上,PyTorch 使这一点具体化;我们可以创建一个层并多次使用它。
我们的 PyTorch 语言模型
我们现在可以创建我们之前描述的语言模型模块:
class LMModel1(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = F.relu(self.h_h(self.i_h(x[:,0])))
h = h + self.i_h(x[:,1])
h = F.relu(self.h_h(h))
h = h + self.i_h(x[:,2])
h = F.relu(self.h_h(h))
return self.h_o(h)
正如您所看到的,我们已经创建了三个层:
-
嵌入层(
i_h,表示 输入 到 隐藏) -
线性层用于创建下一个单词的激活(
h_h,表示 隐藏 到 隐藏) -
一个最终的线性层来预测第四个单词(
h_o,表示 隐藏 到 输出)
这可能更容易以图示形式表示,因此让我们定义一个基本神经网络的简单图示表示。图 12-1 显示了我们将如何用一个隐藏层表示神经网络。
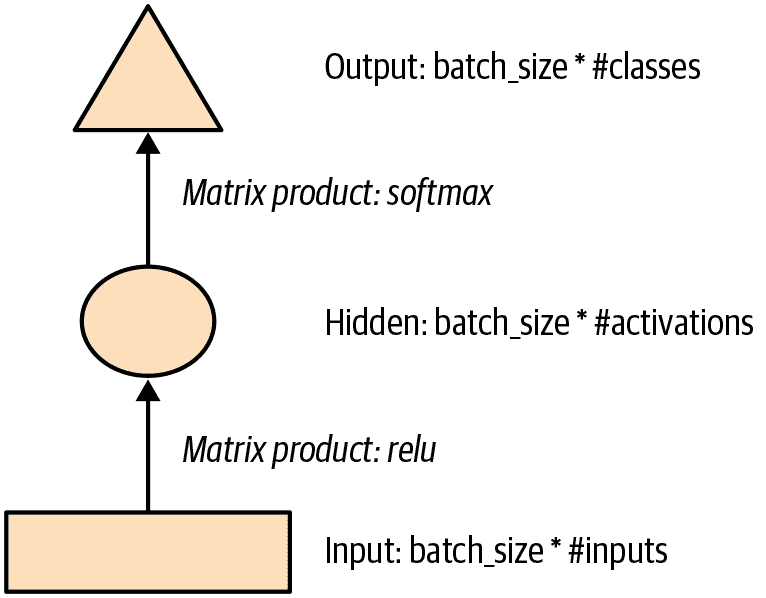
图 12-1。简单神经网络的图示表示
每个形状代表激活:矩形代表输入,圆圈代表隐藏(内部)层激活,三角形代表输出激活。我们将在本章中的所有图表中使用这些形状(在 图 12-2 中总结)。
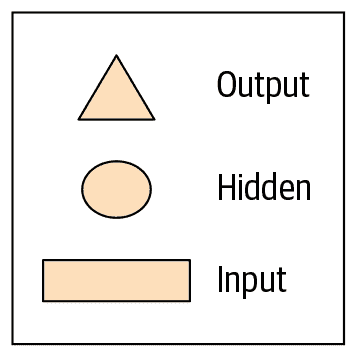
图 12-2。我们图示表示中使用的形状
箭头代表实际的层计算——即线性层后跟激活函数。使用这种符号,图 12-3 显示了我们简单语言模型的外观。
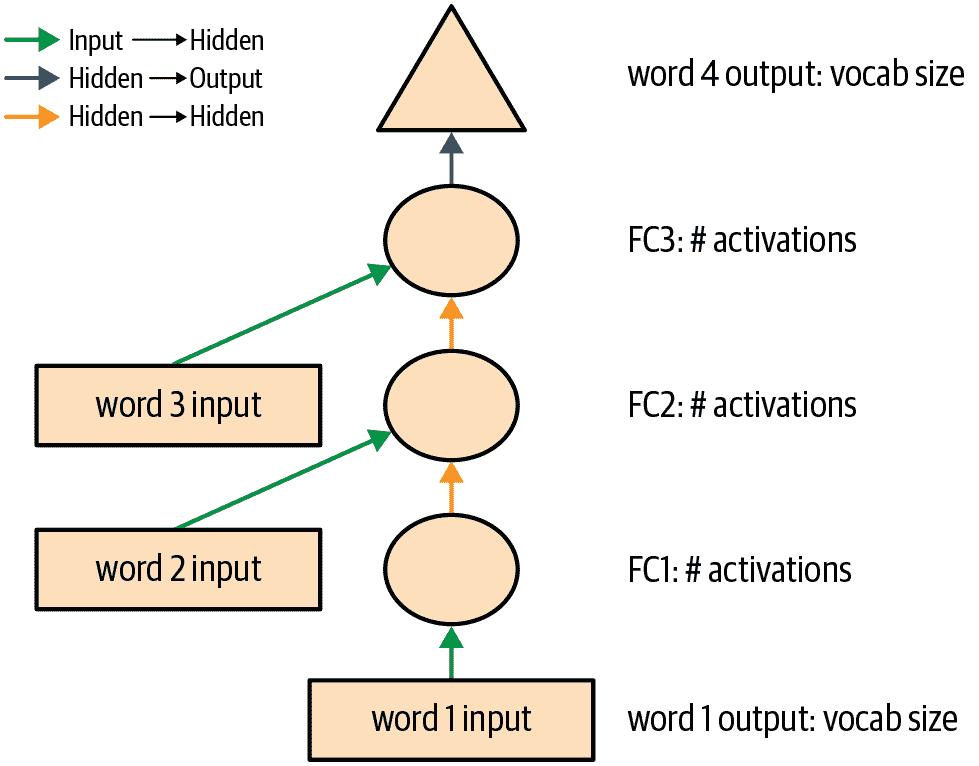
图 12-3。我们基本语言模型的表示
为了简化事情,我们已经从每个箭头中删除了层计算的细节。我们还对箭头进行了颜色编码,使所有具有相同颜色的箭头具有相同的权重矩阵。例如,所有输入层使用相同的嵌入矩阵,因此它们都具有相同的颜色(绿色)。
让我们尝试训练这个模型,看看效果如何:
learn = Learner(dls, LMModel1(len(vocab), 64), loss_func=F.cross_entropy,
metrics=accuracy)
learn.fit_one_cycle(4, 1e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.824297 | 1.970941 | 0.467554 | 00:02 |
| 1 | 1.386973 | 1.823242 | 0.467554 | 00:02 |
| 2 | 1.417556 | 1.654497 | 0.494414 | 00:02 |
| 3 | 1.376440 | 1.650849 | 0.494414 | 00:02 |
要查看这是否有效,请查看一个非常简单的模型会给我们什么结果。在这种情况下,我们总是可以预测最常见的标记,因此让我们找出在我们的验证集中最常见的目标是哪个标记:
n,counts = 0,torch.zeros(len(vocab))
for x,y in dls.valid:
n += y.shape[0]
for i in range_of(vocab): counts[i] += (y==i).long().sum()
idx = torch.argmax(counts)
idx, vocab[idx.item()], counts[idx].item()/n
(tensor(29), 'thousand', 0.15165200855716662)
最常见的标记的索引是 29,对应于标记 thousand。总是预测这个标记将给我们大约 15% 的准确率,所以我们表现得更好!
Alexis 说
我的第一个猜测是分隔符会是最常见的标记,因为每个数字都有一个分隔符。但查看 tokens 提醒我,大数字用许多单词写成,所以在通往 10,000 的路上,你会经常写“thousand”:five thousand, five thousand and one, five thousand and two 等等。糟糕!查看数据对于注意到微妙特征以及尴尬明显的特征都很有帮助。
这是一个不错的第一个基线。让我们看看如何用循环重构它。
我们的第一个循环神经网络
查看我们模块的代码,我们可以通过用 for 循环替换调用层的重复代码来简化它。除了使我们的代码更简单外,这样做的好处是我们将能够同样适用于不同长度的标记序列——我们不会被限制在长度为三的标记列表上:
class LMModel2(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = 0
for i in range(3):
h = h + self.i_h(x[:,i])
h = F.relu(self.h_h(h))
return self.h_o(h)
让我们检查一下,看看我们使用这种重构是否得到相同的结果:
learn = Learner(dls, LMModel2(len(vocab), 64), loss_func=F.cross_entropy,
metrics=accuracy)
learn.fit_one_cycle(4, 1e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.816274 | 1.964143 | 0.460185 | 00:02 |
| 1 | 1.423805 | 1.739964 | 0.473259 | 00:02 |
| 2 | 1.430327 | 1.685172 | 0.485382 | 00:02 |
| 3 | 1.388390 | 1.657033 | 0.470406 | 00:02 |
我们还可以以完全相同的方式重构我们的图示表示,如图 12-4 所示(这里我们也删除了激活大小的细节,并使用与图 12-3 相同的箭头颜色)。
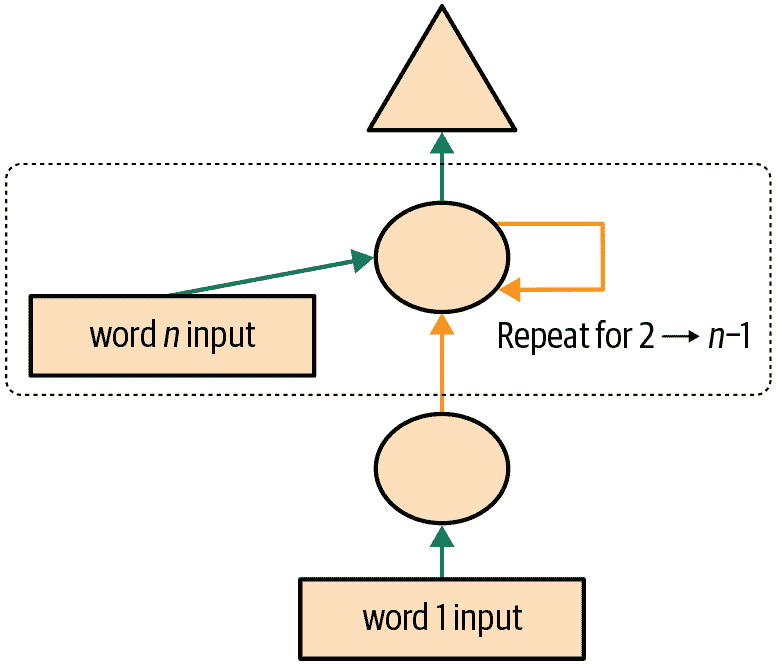
图 12-4. 基本循环神经网络
您将看到一组激活在每次循环中被更新,存储在变量h中—这被称为隐藏状态。
术语:隐藏状态
在循环神经网络的每一步中更新的激活。
使用这样的循环定义的神经网络称为循环神经网络(RNN)。重要的是要意识到 RNN 并不是一个复杂的新架构,而只是使用for循环对多层神经网络进行重构。
Alexis 说
我的真实看法:如果它们被称为“循环神经网络”或 LNNs,它们看起来会少恐怖 50%!
现在我们知道了什么是 RNN,让我们试着让它变得更好一点。
改进 RNN
观察我们的 RNN 代码,有一个看起来有问题的地方是,我们为每个新的输入序列将隐藏状态初始化为零。为什么这是个问题呢?我们将样本序列设置得很短,以便它们可以轻松地适应批处理。但是,如果我们正确地对这些样本进行排序,模型将按顺序读取样本序列,使模型暴露于原始序列的长时间段。
我们还可以考虑增加更多信号:为什么只预测第四个单词,而不使用中间预测来预测第二和第三个单词呢?让我们看看如何实现这些变化,首先从添加一些状态开始。
维护 RNN 的状态
因为我们为每个新样本将模型的隐藏状态初始化为零,这样我们就丢失了关于迄今为止看到的句子的所有信息,这意味着我们的模型实际上不知道我们在整体计数序列中的进度。这很容易修复;我们只需将隐藏状态的初始化移动到__init__中。
但是,这种修复方法将产生自己微妙但重要的问题。它实际上使我们的神经网络变得和文档中的令牌数量一样多。例如,如果我们的数据集中有 10,000 个令牌,我们将创建一个有 10,000 层的神经网络。
要了解为什么会出现这种情况,请考虑我们循环神经网络的原始图示表示,即在图 12-3 中,在使用for循环重构之前。您可以看到每个层对应一个令牌输入。当我们谈论使用for循环重构之前的循环神经网络的表示时,我们称之为展开表示。在尝试理解 RNN 时,考虑展开表示通常是有帮助的。
10,000 层神经网络的问题在于,当您到达数据集的第 10,000 个单词时,您仍然需要计算直到第一层的所有导数。这将非常缓慢,且占用内存。您可能无法在 GPU 上存储一个小批量。
解决这个问题的方法是告诉 PyTorch 我们不希望通过整个隐式神经网络反向传播导数。相反,我们将保留梯度的最后三层。为了在 PyTorch 中删除所有梯度历史,我们使用detach方法。
这是我们 RNN 的新版本。现在它是有状态的,因为它在不同调用forward时记住了其激活,这代表了它在批处理中用于不同样本的情况:
class LMModel3(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
self.h = 0
def forward(self, x):
for i in range(3):
self.h = self.h + self.i_h(x[:,i])
self.h = F.relu(self.h_h(self.h))
out = self.h_o(self.h)
self.h = self.h.detach()
return out
def reset(self): self.h = 0
无论我们选择什么序列长度,这个模型将具有相同的激活,因为隐藏状态将记住上一批次的最后激活。唯一不同的是在每一步计算的梯度:它们将仅在过去的序列长度标记上计算,而不是整个流。这种方法称为时间穿梭反向传播(BPTT)。
术语:时间穿梭反向传播
将一个神经网络有效地视为每个时间步长一个层(通常使用循环重构),并以通常的方式在其上计算梯度。为了避免内存和时间不足,我们通常使用截断 BPTT,每隔几个时间步“分离”隐藏状态的计算历史。
要使用LMModel3,我们需要确保样本按照一定顺序进行查看。正如我们在第十章中看到的,如果第一批的第一行是我们的dset[0],那么第二批应该将dset[1]作为第一行,以便模型看到文本流动。
LMDataLoader在第十章中为我们做到了这一点。这次我们要自己做。
为此,我们将重新排列我们的数据集。首先,我们将样本分成m = len(dset) // bs组(这相当于将整个连接数据集分成,例如,64 个大小相等的部分,因为我们在这里使用bs=64)。m是每个这些部分的长度。例如,如果我们使用整个数据集(尽管我们实际上将在一会儿将其分成训练和验证),我们有:
m = len(seqs)//bs
m,bs,len(seqs)
(328, 64, 21031)
第一批将由样本组成
(0, m, 2*m, ..., (bs-1)*m)
样本的第二批
(1, m+1, 2*m+1, ..., (bs-1)*m+1)
等等。这样,每个时期,模型将在每批次的每行上看到大小为3*m的连续文本块(因为每个文本的大小为 3)。
以下函数执行重新索引:
def group_chunks(ds, bs):
m = len(ds) // bs
new_ds = L()
for i in range(m): new_ds += L(ds[i + m*j] for j in range(bs))
return new_ds
然后,我们在构建DataLoaders时只需传递drop_last=True来删除最后一个形状不为bs的批次。我们还传递shuffle=False以确保文本按顺序阅读:
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(
group_chunks(seqs[:cut], bs),
group_chunks(seqs[cut:], bs),
bs=bs, drop_last=True, shuffle=False)
我们添加的最后一件事是通过Callback对训练循环进行微调。我们将在第十六章中更多地讨论回调;这个回调将在每个时期的开始和每个验证阶段之前调用我们模型的reset方法。由于我们实现了该方法来将模型的隐藏状态设置为零,这将确保我们在阅读这些连续文本块之前以干净的状态开始。我们也可以开始训练更长一点:
learn = Learner(dls, LMModel3(len(vocab), 64), loss_func=F.cross_entropy,
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(10, 3e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.677074 | 1.827367 | 0.467548 | 00:02 |
| 1 | 1.282722 | 1.870913 | 0.388942 | 00:02 |
| 2 | 1.090705 | 1.651793 | 0.462500 | 00:02 |
| 3 | 1.005092 | 1.613794 | 0.516587 | 00:02 |
| 4 | 0.965975 | 1.560775 | 0.551202 | 00:02 |
| 5 | 0.916182 | 1.595857 | 0.560577 | 00:02 |
| 6 | 0.897657 | 1.539733 | 0.574279 | 00:02 |
| 7 | 0.836274 | 1.585141 | 0.583173 | 00:02 |
| 8 | 0.805877 | 1.629808 | 0.586779 | 00:02 |
| 9 | 0.795096 | 1.651267 | 0.588942 | 00:02 |
这已经更好了!下一步是使用更多目标并将它们与中间预测进行比较。
创建更多信号
我们当前方法的另一个问题是,我们仅为每三个输入单词预测一个输出单词。因此,我们反馈以更新权重的信号量不如可能的那么大。如果我们在每个单词后预测下一个单词,而不是每三个单词,将会更好,如图 12-5 所示。
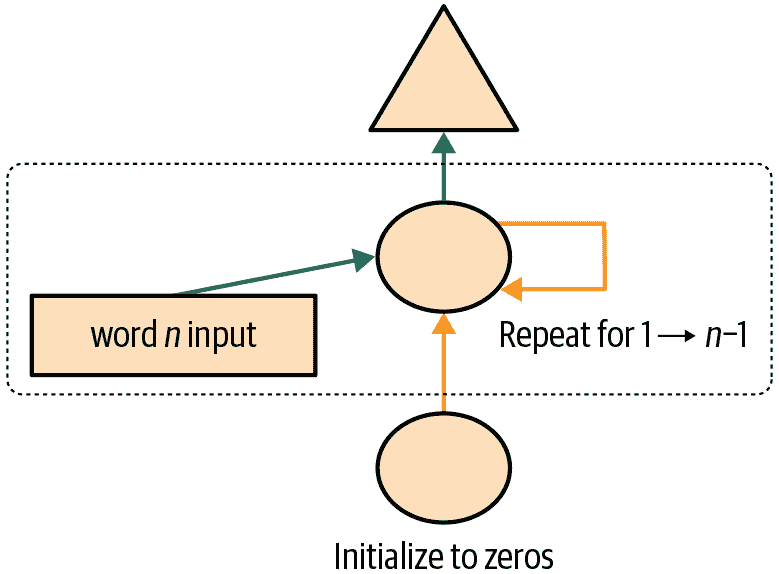
图 12-5。RNN 在每个标记后进行预测
这很容易添加。我们需要首先改变我们的数据,使得因变量在每个三个输入词后的每个三个词中都有。我们使用一个属性sl(用于序列长度),并使其稍微变大:
sl = 16
seqs = L((tensor(nums[i:i+sl]), tensor(nums[i+1:i+sl+1]))
for i in range(0,len(nums)-sl-1,sl))
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(group_chunks(seqs[:cut], bs),
group_chunks(seqs[cut:], bs),
bs=bs, drop_last=True, shuffle=False)
查看seqs的第一个元素,我们可以看到它包含两个相同大小的列表。第二个列表与第一个相同,但偏移了一个元素:
[L(vocab[o] for o in s) for s in seqs[0]]
[(#16) ['one','.','two','.','three','.','four','.','five','.'...],
(#16) ['.','two','.','three','.','four','.','five','.','six'...]]
现在我们需要修改我们的模型,使其在每个单词之后输出一个预测,而不仅仅是在一个三个词序列的末尾:
class LMModel4(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
self.h = 0
def forward(self, x):
outs = []
for i in range(sl):
self.h = self.h + self.i_h(x[:,i])
self.h = F.relu(self.h_h(self.h))
outs.append(self.h_o(self.h))
self.h = self.h.detach()
return torch.stack(outs, dim=1)
def reset(self): self.h = 0
这个模型将返回形状为bs x sl x vocab_sz的输出(因为我们在dim=1上堆叠)。我们的目标的形状是bs x sl,所以在使用F.cross_entropy之前,我们需要将它们展平:
def loss_func(inp, targ):
return F.cross_entropy(inp.view(-1, len(vocab)), targ.view(-1))
我们现在可以使用这个损失函数来训练模型:
learn = Learner(dls, LMModel4(len(vocab), 64), loss_func=loss_func,
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 3e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.103298 | 2.874341 | 0.212565 | 00:01 |
| 1 | 2.231964 | 1.971280 | 0.462158 | 00:01 |
| 2 | 1.711358 | 1.813547 | 0.461182 | 00:01 |
| 3 | 1.448516 | 1.828176 | 0.483236 | 00:01 |
| 4 | 1.288630 | 1.659564 | 0.520671 | 00:01 |
| 5 | 1.161470 | 1.714023 | 0.554932 | 00:01 |
| 6 | 1.055568 | 1.660916 | 0.575033 | 00:01 |
| 7 | 0.960765 | 1.719624 | 0.591064 | 00:01 |
| 8 | 0.870153 | 1.839560 | 0.614665 | 00:01 |
| 9 | 0.808545 | 1.770278 | 0.624349 | 00:01 |
| 10 | 0.758084 | 1.842931 | 0.610758 | 00:01 |
| 11 | 0.719320 | 1.799527 | 0.646566 | 00:01 |
| 12 | 0.683439 | 1.917928 | 0.649821 | 00:01 |
| 13 | 0.660283 | 1.874712 | 0.628581 | 00:01 |
| 14 | 0.646154 | 1.877519 | 0.640055 | 00:01 |
我们需要训练更长时间,因为任务有点变化,现在更加复杂。但我们最终得到了一个好结果...至少有时候是这样。如果你多次运行它,你会发现在不同的运行中可以得到非常不同的结果。这是因为实际上我们在这里有一个非常深的网络,这可能导致非常大或非常小的梯度。我们将在本章的下一部分看到如何处理这个问题。
现在,获得更好模型的明显方法是加深:在我们基本的 RNN 中,隐藏状态和输出激活之间只有一个线性层,所以也许我们用更多的线性层会得到更好的结果。
多层 RNNs
在多层 RNN 中,我们将来自我们递归神经网络的激活传递到第二个递归神经网络中,就像图 12-6 中所示。
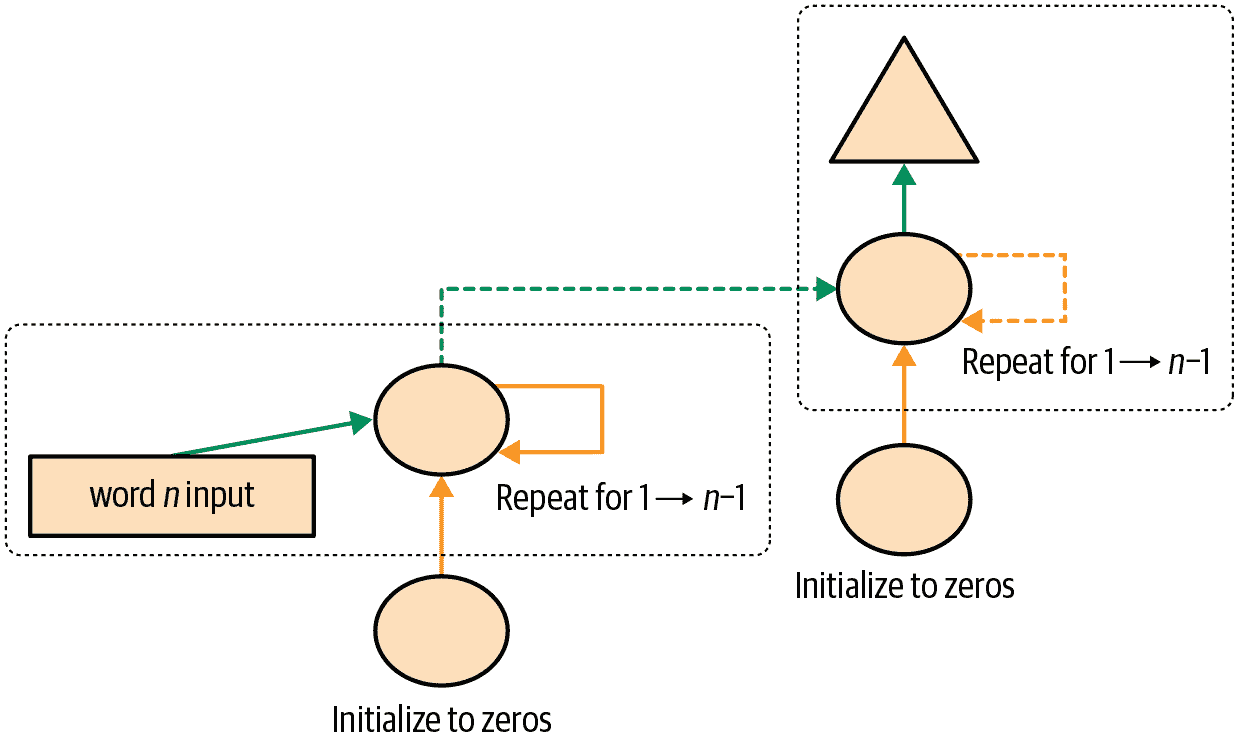
图 12-6. 2 层 RNN
展开的表示在图 12-7 中显示(类似于图 12-3)。
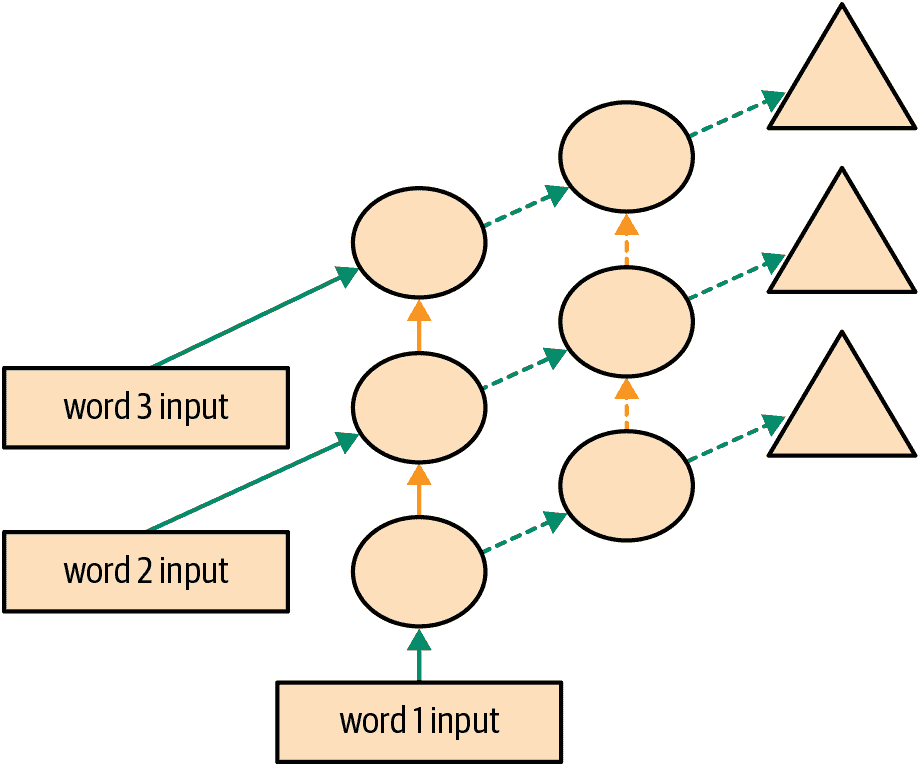
图 12-7. 2 层展开的 RNN
让我们看看如何在实践中实现这一点。
模型
我们可以通过使用 PyTorch 的RNN类来节省一些时间,该类实现了我们之前创建的内容,但也给了我们堆叠多个 RNN 的选项,正如我们之前讨论的那样:
class LMModel5(Module):
def __init__(self, vocab_sz, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.RNN(n_hidden, n_hidden, n_layers, batch_first=True)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = torch.zeros(n_layers, bs, n_hidden)
def forward(self, x):
res,h = self.rnn(self.i_h(x), self.h)
self.h = h.detach()
return self.h_o(res)
def reset(self): self.h.zero_()
learn = Learner(dls, LMModel5(len(vocab), 64, 2),
loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 3e-3)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.055853 | 2.591640 | 0.437907 | 00:01 |
| 1 | 2.162359 | 1.787310 | 0.471598 | 00:01 |
| 2 | 1.710663 | 1.941807 | 0.321777 | 00:01 |
| 3 | 1.520783 | 1.999726 | 0.312012 | 00:01 |
| 4 | 1.330846 | 2.012902 | 0.413249 | 00:01 |
| 5 | 1.163297 | 1.896192 | 0.450684 | 00:01 |
| 6 | 1.033813 | 2.005209 | 0.434814 | 00:01 |
| 7 | 0.919090 | 2.047083 | 0.456706 | 00:01 |
| 8 | 0.822939 | 2.068031 | 0.468831 | 00:01 |
| 9 | 0.750180 | 2.136064 | 0.475098 | 00:01 |
| 10 | 0.695120 | 2.139140 | 0.485433 | 00:01 |
| 11 | 0.655752 | 2.155081 | 0.493652 | 00:01 |
| 12 | 0.629650 | 2.162583 | 0.498535 | 00:01 |
| 13 | 0.613583 | 2.171649 | 0.491048 | 00:01 |
| 14 | 0.604309 | 2.180355 | 0.487874 | 00:01 |
现在这令人失望...我们之前的单层 RNN 表现更好。为什么?原因是我们有一个更深的模型,导致激活爆炸或消失。
激活爆炸或消失
在实践中,从这种类型的 RNN 创建准确的模型是困难的。如果我们调用detach的频率较少,并且有更多的层,我们将获得更好的结果 - 这使得我们的 RNN 有更长的时间跨度来学习和创建更丰富的特征。但这也意味着我们有一个更深的模型要训练。深度学习发展中的关键挑战是如何训练这种类型的模型。
这是具有挑战性的,因为当您多次乘以一个矩阵时会发生什么。想想当您多次乘以一个数字时会发生什么。例如,如果您从 1 开始乘以 2,您会得到序列 1、2、4、8,...在 32 步之后,您已经达到 4,294,967,296。如果您乘以 0.5,类似的问题会发生:您会得到 0.5、0.25、0.125,...在 32 步之后,它是 0.00000000023。正如您所看到的,即使是比 1 稍高或稍低的数字,经过几次重复乘法后,我们的起始数字就会爆炸或消失。
因为矩阵乘法只是将数字相乘并将它们相加,重复矩阵乘法会发生完全相同的事情。这就是深度神经网络的全部内容 - 每一层都是另一个矩阵乘法。这意味着深度神经网络很容易最终得到极大或极小的数字。
这是一个问题,因为计算机存储数字的方式(称为浮点数)意味着随着数字远离零点,它们变得越来越不准确。来自优秀文章“关于浮点数你从未想知道但却被迫了解”的图 12-8 中的图表显示了浮点数的精度如何随着数字线变化。

图 12-8。浮点数的精度
这种不准确性意味着通常为更新权重计算的梯度最终会变为零或无穷大。这通常被称为消失梯度或爆炸梯度问题。这意味着在 SGD 中,权重要么根本不更新,要么跳到无穷大。无论哪种方式,它们都不会随着训练而改善。
研究人员已经开发出了解决这个问题的方法,我们将在本书后面讨论。一种选择是改变层的定义方式,使其不太可能出现激活爆炸。当我们讨论批量归一化时,我们将在第十三章中看到这是如何完成的,当我们讨论 ResNets 时,我们将在第十四章中看到,尽管这些细节通常在实践中并不重要(除非您是一个研究人员,正在创造解决这个问题的新方法)。另一种处理这个问题的策略是谨慎初始化,这是我们将在第十七章中调查的一个主题。
为了避免激活爆炸,RNN 经常使用两种类型的层:门控循环单元(GRUs)和长短期记忆(LSTM)层。这两种都在 PyTorch 中可用,并且可以直接替换 RNN 层。在本书中,我们只会涵盖 LSTMs;在线上有很多好的教程解释 GRUs,它们是 LSTM 设计的一个小变体。
LSTM
LSTM 是由 Jürgen Schmidhuber 和 Sepp Hochreiter 于 1997 年引入的一种架构。在这种架构中,不是一个,而是两个隐藏状态。在我们的基本 RNN 中,隐藏状态是 RNN 在上一个时间步的输出。那个隐藏状态负责两件事:
-
拥有正确的信息来预测正确的下一个标记的输出层
-
保留句子中发生的一切记忆
例如,考虑句子“Henry has a dog and he likes his dog very much”和“Sophie has a dog and she likes her dog very much。”很明显,RNN 需要记住句子开头的名字才能预测he/she或his/her。
在实践中,RNN 在保留句子中较早发生的记忆方面表现非常糟糕,这就是在 LSTM 中有另一个隐藏状态(称为cell state)的动机。cell state 将负责保持长期短期记忆,而隐藏状态将专注于预测下一个标记。让我们更仔细地看看如何实现这一点,并从头开始构建一个 LSTM。
从头开始构建一个 LSTM
为了构建一个 LSTM,我们首先必须了解其架构。图 12-9 显示了其内部结构。
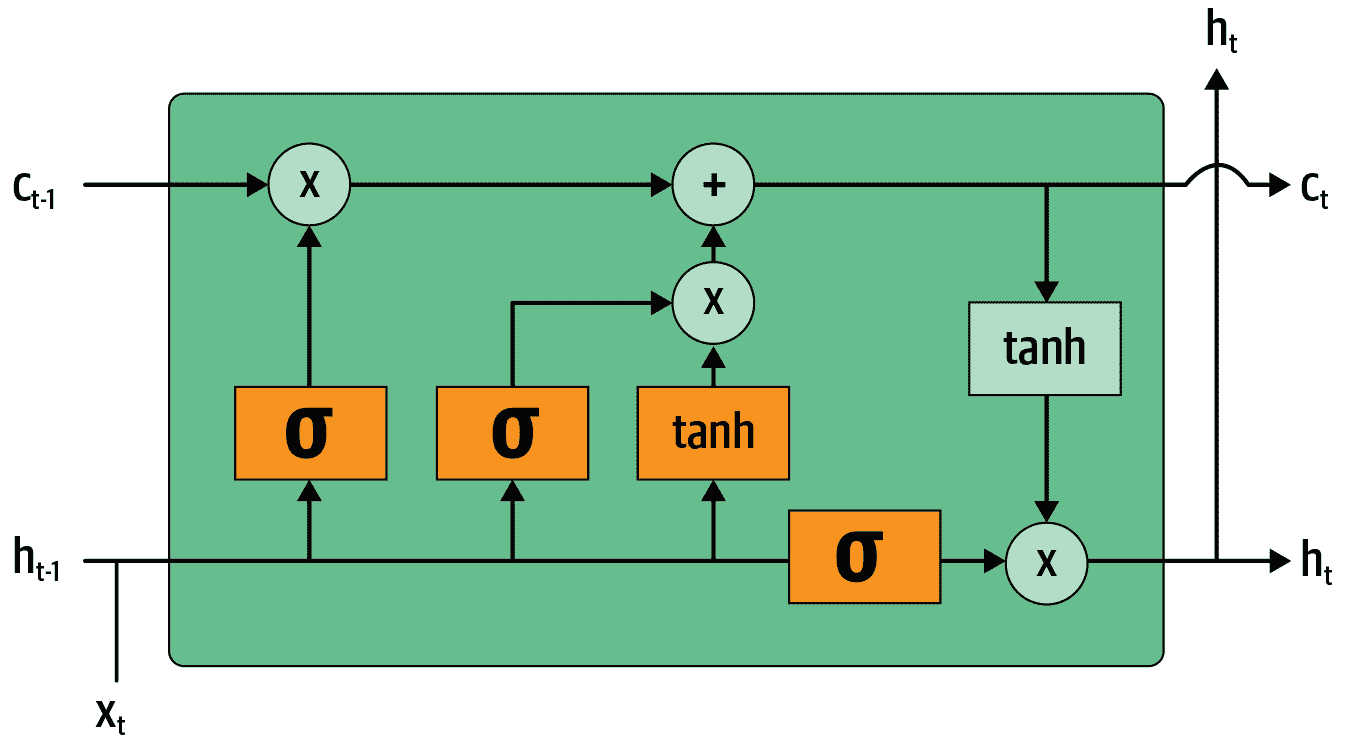
图 12-9. LSTM 的架构
在这张图片中,我们的输入从左侧进入,带有先前的隐藏状态()和 cell state()。四个橙色框代表四个层(我们的神经网络),激活函数可以是 sigmoid()或 tanh。tanh 只是一个重新缩放到范围-1 到 1 的 sigmoid 函数。它的数学表达式可以写成这样:
其中是 sigmoid 函数。图中的绿色圆圈是逐元素操作。右侧输出的是新的隐藏状态()和新的 cell state(),准备接受我们的下一个输入。新的隐藏状态也被用作输出,这就是为什么箭头分开向上移动。
让我们逐一查看四个神经网络(称为门)并解释图表——但在此之前,请注意 cell state(顶部)几乎没有改变。它甚至没有直接通过神经网络!这正是为什么它将继续保持较长期的状态。
首先,将输入和旧隐藏状态的箭头连接在一起。在本章前面编写的 RNN 中,我们将它们相加。在 LSTM 中,我们将它们堆叠在一个大张量中。这意味着我们的嵌入的维度(即的维度)可以与隐藏状态的维度不同。如果我们将它们称为n_in和n_hid,底部的箭头大小为n_in + n_hid;因此所有的神经网络(橙色框)都是具有n_in + n_hid输入和n_hid输出的线性层。
第一个门(从左到右看)称为遗忘门。由于它是一个线性层后面跟着一个 sigmoid,它的输出将由 0 到 1 之间的标量组成。我们将这个结果乘以细胞状态,以确定要保留哪些信息,要丢弃哪些信息:接近 0 的值被丢弃,接近 1 的值被保留。这使得 LSTM 有能力忘记关于其长期状态的事情。例如,当穿过一个句号或一个xxbos标记时,我们期望它(已经学会)重置其细胞状态。
第二个门称为输入门。它与第三个门(没有真正的名称,但有时被称为细胞门)一起更新细胞状态。例如,我们可能看到一个新的性别代词,这时我们需要替换遗忘门删除的关于性别的信息。与遗忘门类似,输入门决定要更新的细胞状态元素(接近 1 的值)或不更新(接近 0 的值)。第三个门确定这些更新值是什么,范围在-1 到 1 之间(由于 tanh 函数)。结果被添加到细胞状态中。
最后一个门是输出门。它确定从细胞状态中使用哪些信息来生成输出。细胞状态经过 tanh 后与输出门的 sigmoid 输出结合,结果就是新的隐藏状态。在代码方面,我们可以这样写相同的步骤:
class LSTMCell(Module):
def __init__(self, ni, nh):
self.forget_gate = nn.Linear(ni + nh, nh)
self.input_gate = nn.Linear(ni + nh, nh)
self.cell_gate = nn.Linear(ni + nh, nh)
self.output_gate = nn.Linear(ni + nh, nh)
def forward(self, input, state):
h,c = state
h = torch.stack([h, input], dim=1)
forget = torch.sigmoid(self.forget_gate(h))
c = c * forget
inp = torch.sigmoid(self.input_gate(h))
cell = torch.tanh(self.cell_gate(h))
c = c + inp * cell
out = torch.sigmoid(self.output_gate(h))
h = outgate * torch.tanh(c)
return h, (h,c)
实际上,我们可以重构代码。此外,就性能而言,做一次大矩阵乘法比做四次小矩阵乘法更好(因为我们只在 GPU 上启动一次特殊的快速内核,这样可以让 GPU 并行处理更多工作)。堆叠需要一点时间(因为我们必须在 GPU 上移动一个张量,使其全部在一个连续的数组中),所以我们为输入和隐藏状态使用两个单独的层。优化和重构后的代码如下:
class LSTMCell(Module):
def __init__(self, ni, nh):
self.ih = nn.Linear(ni,4*nh)
self.hh = nn.Linear(nh,4*nh)
def forward(self, input, state):
h,c = state
# One big multiplication for all the gates is better than 4 smaller ones
gates = (self.ih(input) + self.hh(h)).chunk(4, 1)
ingate,forgetgate,outgate = map(torch.sigmoid, gates[:3])
cellgate = gates[3].tanh()
c = (forgetgate*c) + (ingate*cellgate)
h = outgate * c.tanh()
return h, (h,c)
在这里,我们使用 PyTorch 的chunk方法将张量分成四部分。它的工作原理如下:
t = torch.arange(0,10); t
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
t.chunk(2)
(tensor([0, 1, 2, 3, 4]), tensor([5, 6, 7, 8, 9]))
现在让我们使用这个架构来训练一个语言模型!
使用 LSTMs 训练语言模型
这是与LMModel5相同的网络,使用了两层 LSTM。我们可以以更高的学习率进行训练,时间更短,获得更好的准确性:
class LMModel6(Module):
def __init__(self, vocab_sz, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]
def forward(self, x):
res,h = self.rnn(self.i_h(x), self.h)
self.h = [h_.detach() for h_ in h]
return self.h_o(res)
def reset(self):
for h in self.h: h.zero_()
learn = Learner(dls, LMModel6(len(vocab), 64, 2),
loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 1e-2)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 3.000821 | 2.663942 | 0.438314 | 00:02 |
| 1 | 2.139642 | 2.184780 | 0.240479 | 00:02 |
| 2 | 1.607275 | 1.812682 | 0.439779 | 00:02 |
| 3 | 1.347711 | 1.830982 | 0.497477 | 00:02 |
| 4 | 1.123113 | 1.937766 | 0.594401 | 00:02 |
| 5 | 0.852042 | 2.012127 | 0.631592 | 00:02 |
| 6 | 0.565494 | 1.312742 | 0.725749 | 00:02 |
| 7 | 0.347445 | 1.297934 | 0.711263 | 00:02 |
| 8 | 0.208191 | 1.441269 | 0.731201 | 00:02 |
| 9 | 0.126335 | 1.569952 | 0.737305 | 00:02 |
| 10 | 0.079761 | 1.427187 | 0.754150 | 00:02 |
| 11 | 0.052990 | 1.494990 | 0.745117 | 00:02 |
| 12 | 0.039008 | 1.393731 | 0.757894 | 00:02 |
| 13 | 0.031502 | 1.373210 | 0.758464 | 00:02 |
| 14 | 0.028068 | 1.368083 | 0.758464 | 00:02 |
现在这比多层 RNN 好多了!然而,我们仍然可以看到有一点过拟合,这表明一点正则化可能会有所帮助。
正则化 LSTM
循环神经网络总体上很难训练,因为我们之前看到的激活和梯度消失问题。使用 LSTM(或 GRU)单元比使用普通 RNN 更容易训练,但它们仍然很容易过拟合。数据增强虽然是一种可能性,但在文本数据中使用得比图像数据少,因为在大多数情况下,它需要另一个模型来生成随机增强(例如,将文本翻译成另一种语言,然后再翻译回原始语言)。总的来说,目前文本数据的数据增强并不是一个被充分探索的领域。
然而,我们可以使用其他正则化技术来减少过拟合,这些技术在与 LSTMs 一起使用时进行了深入研究,如 Stephen Merity 等人的论文“正则化和优化 LSTM 语言模型”。这篇论文展示了如何有效地使用 dropout、激活正则化和时间激活正则化可以使一个 LSTM 击败以前需要更复杂模型的最新结果。作者将使用这些技术的 LSTM 称为AWD-LSTM。我们将依次看看这些技术。
Dropout
Dropout是由 Geoffrey Hinton 等人在“通过防止特征探测器的共适应来改进神经网络”中引入的一种正则化技术。基本思想是在训练时随机将一些激活变为零。这确保所有神经元都积极地朝着输出工作,如图 12-10 所示(来自 Nitish Srivastava 等人的“Dropout:防止神经网络过拟合的简单方法”)。
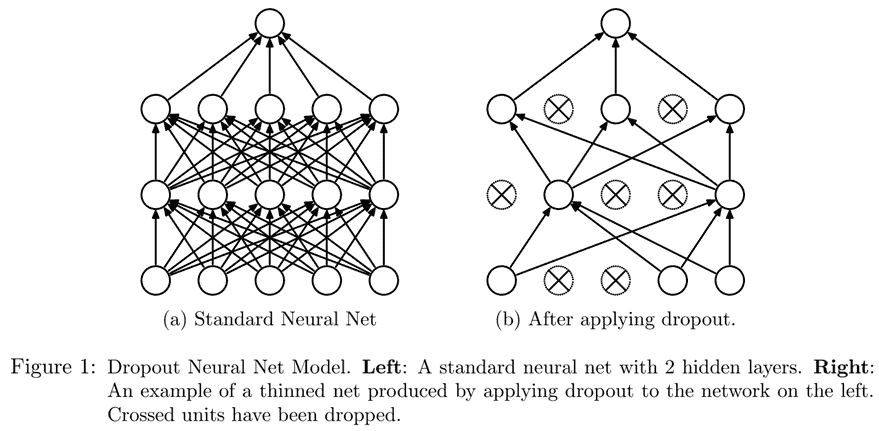
图 12-10。在神经网络中应用 dropout(由 Nitish Srivastava 等人提供)
Hinton 在一次采访中解释了 dropout 的灵感时使用了一个很好的比喻:
我去了我的银行。出纳员不断变换,我问其中一个原因。他说他不知道,但他们经常被调动。我想这一定是因为需要员工之间的合作才能成功欺诈银行。这让我意识到,随机在每个示例中删除不同的神经元子集将防止阴谋,从而减少过拟合。
在同一次采访中,他还解释了神经科学提供了额外的灵感:
我们并不真正知道为什么神经元会突触。有一种理论是它们想要变得嘈杂以进行正则化,因为我们的参数比数据点多得多。dropout 的想法是,如果你有嘈杂的激活,你可以承担使用一个更大的模型。
这解释了为什么 dropout 有助于泛化的想法:首先它帮助神经元更好地合作;然后它使激活更嘈杂,从而使模型更健壮。
然而,我们可以看到,如果我们只是将这些激活置零而不做其他任何操作,我们的模型将会训练出问题:如果我们从五个激活的总和(由于我们应用了 ReLU,它们都是正数)变为只有两个,这不会有相同的规模。因此,如果我们以概率p应用 dropout,我们通过将所有激活除以1-p来重新缩放它们(平均p将被置零,所以剩下1-p),如图 12-11 所示。
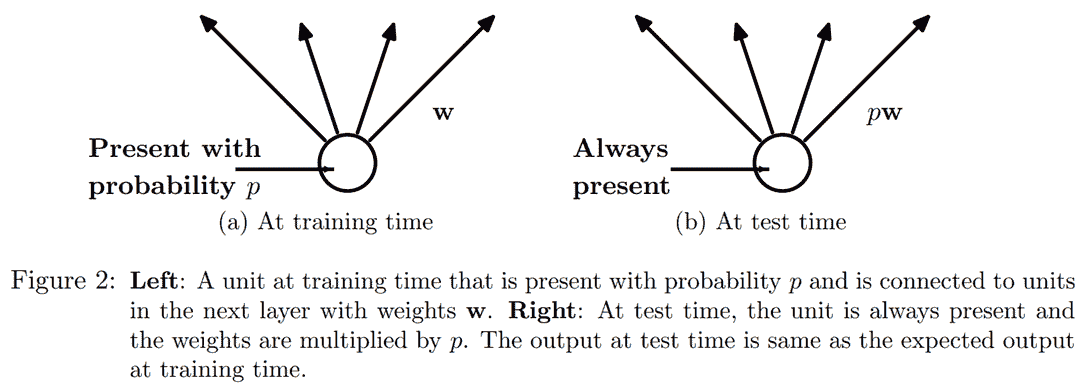
图 12-11。应用 dropout 时为什么要缩放激活(由 Nitish Srivastava 等人提供)
这是 PyTorch 中 dropout 层的完整实现(尽管 PyTorch 的原生层实际上是用 C 而不是 Python 编写的):
class Dropout(Module):
def __init__(self, p): self.p = p
def forward(self, x):
if not self.training: return x
mask = x.new(*x.shape).bernoulli_(1-p)
return x * mask.div_(1-p)
bernoulli_方法创建一个随机零(概率为p)和一(概率为1-p)的张量,然后将其乘以我们的输入,再除以1-p。注意training属性的使用,它在任何 PyTorch nn.Module中都可用,并告诉我们是否在训练或推理。
做你自己的实验
在本书的前几章中,我们会在这里添加一个bernoulli_的代码示例,这样您就可以看到它的确切工作原理。但是现在您已经了解足够多,可以自己做这个,我们将为您提供越来越少的示例,而是期望您自己进行实验以了解事物是如何工作的。在这种情况下,您将在章节末尾的问卷中看到,我们要求您尝试使用bernoulli_,但不要等到我们要求您进行实验才开发您对我们正在研究的代码的理解;无论如何都可以开始做。
在将我们的 LSTM 的输出传递到最终层之前使用 dropout 将有助于减少过拟合。在许多其他模型中也使用了 dropout,包括fastai.vision中使用的默认 CNN 头部,并且通过传递ps参数(其中每个“p”都传递给每个添加的Dropout层)在fastai.tabular中也可用,正如我们将在第十五章中看到的。
在训练和验证模式下,dropout 的行为不同,我们使用Dropout中的training属性进行指定。在Module上调用train方法会将training设置为True(对于您调用该方法的模块以及递归包含的每个模块),而eval将其设置为False。在调用Learner的方法时会自动执行此操作,但如果您没有使用该类,请记住根据需要在两者之间切换。
激活正则化和时间激活正则化
激活正则化(AR)和时间激活正则化(TAR)是两种与权重衰减非常相似的正则化方法,在第八章中讨论过。在应用权重衰减时,我们会对损失添加一个小的惩罚,旨在使权重尽可能小。对于激活正则化,我们将尝试使 LSTM 生成的最终激活尽可能小,而不是权重。
为了对最终激活进行正则化,我们必须将它们存储在某个地方,然后将它们的平方的平均值添加到损失中(以及一个乘数alpha,就像权重衰减的wd一样):
loss += alpha * activations.pow(2).mean()
时间激活正则化与我们在句子中预测标记有关。这意味着当我们按顺序阅读它们时,我们的 LSTM 的输出应该在某种程度上是有意义的。TAR 通过向损失添加惩罚来鼓励这种行为,使两个连续激活之间的差异尽可能小:我们的激活张量的形状为bs x sl x n_hid,我们在序列长度轴上(中间维度)读取连续激活。有了这个,TAR 可以表示如下:
loss += beta * (activations[:,1:] - activations[:,:-1]).pow(2).mean()
然后,alpha和beta是要调整的两个超参数。为了使这项工作成功,我们需要让我们的带有 dropout 的模型返回三个东西:正确的输出,LSTM 在 dropout 之前的激活以及 LSTM 在 dropout 之后的激活。通常在 dropout 后的激活上应用 AR(以免惩罚我们之后转换为零的激活),而 TAR 应用在未经 dropout 的激活上(因为这些零会在两个连续时间步之间产生很大的差异)。然后,一个名为RNNRegularizer的回调将为我们应用这种正则化。
训练带有权重绑定的正则化 LSTM
我们可以将 dropout(应用在我们进入输出层之前)与 AR 和 TAR 相结合,以训练我们之前的 LSTM。我们只需要返回三个东西而不是一个:我们的 LSTM 的正常输出,dropout 后的激活以及我们的 LSTM 的激活。最后两个将由回调RNNRegularization捕获,以便为其对损失的贡献做出贡献。
我们可以从AWD-LSTM 论文中添加另一个有用的技巧是权重绑定。在语言模型中,输入嵌入表示从英语单词到激活的映射,输出隐藏层表示从激活到英语单词的映射。直觉上,我们可能会期望这些映射是相同的。我们可以通过将相同的权重矩阵分配给这些层来在 PyTorch 中表示这一点:
self.h_o.weight = self.i_h.weight
在LMMModel7中,我们包括了这些最终的调整:
class LMModel7(Module):
def __init__(self, vocab_sz, n_hidden, n_layers, p):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)
self.drop = nn.Dropout(p)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h_o.weight = self.i_h.weight
self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]
def forward(self, x):
raw,h = self.rnn(self.i_h(x), self.h)
out = self.drop(raw)
self.h = [h_.detach() for h_ in h]
return self.h_o(out),raw,out
def reset(self):
for h in self.h: h.zero_()
我们可以使用RNNRegularizer回调函数创建一个正则化的Learner:
learn = Learner(dls, LMModel7(len(vocab), 64, 2, 0.5),
loss_func=CrossEntropyLossFlat(), metrics=accuracy,
cbs=[ModelResetter, RNNRegularizer(alpha=2, beta=1)])
TextLearner会自动为我们添加这两个回调函数(使用alpha和beta的默认值),因此我们可以简化前面的行:
learn = TextLearner(dls, LMModel7(len(vocab), 64, 2, 0.4),
loss_func=CrossEntropyLossFlat(), metrics=accuracy)
然后我们可以训练模型,并通过增加权重衰减到0.1来添加额外的正则化:
learn.fit_one_cycle(15, 1e-2, wd=0.1)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.693885 | 2.013484 | 0.466634 | 00:02 |
| 1 | 1.685549 | 1.187310 | 0.629313 | 00:02 |
| 2 | 0.973307 | 0.791398 | 0.745605 | 00:02 |
| 3 | 0.555823 | 0.640412 | 0.794108 | 00:02 |
| 4 | 0.351802 | 0.557247 | 0.836100 | 00:02 |
| 5 | 0.244986 | 0.594977 | 0.807292 | 00:02 |
| 6 | 0.192231 | 0.511690 | 0.846761 | 00:02 |
| 7 | 0.162456 | 0.520370 | 0.858073 | 00:02 |
| 8 | 0.142664 | 0.525918 | 0.842285 | 00:02 |
| 9 | 0.128493 | 0.495029 | 0.858073 | 00:02 |
| 10 | 0.117589 | 0.464236 | 0.867188 | 00:02 |
| 11 | 0.109808 | 0.466550 | 0.869303 | 00:02 |
| 12 | 0.104216 | 0.455151 | 0.871826 | 00:02 |
| 13 | 0.100271 | 0.452659 | 0.873617 | 00:02 |
| 14 | 0.098121 | 0.458372 | 0.869385 | 00:02 |
现在这比我们之前的模型好多了!
结论
您现在已经看到了我们在第十章中用于文本分类的 AWD-LSTM 架构内部的所有内容。它在更多地方使用了丢失:
-
嵌入丢失(就在嵌入层之后)
-
输入丢失(在嵌入层之后)
-
权重丢失(应用于每个训练步骤中 LSTM 的权重)
-
隐藏丢失(应用于两个层之间的隐藏状态)
这使得它更加规范化。由于微调这五个丢失值(包括输出层之前的丢失)很复杂,我们已经确定了良好的默认值,并允许通过您在该章节中看到的drop_mult参数来整体调整丢失的大小。
另一个非常强大的架构,特别适用于“序列到序列”问题(依赖变量本身是一个变长序列的问题,例如语言翻译),是 Transformer 架构。您可以在书籍网站的额外章节中找到它。
问卷
-
如果您的项目数据集非常庞大且复杂,处理它需要大量时间,您应该怎么做?
-
为什么在创建语言模型之前我们要将数据集中的文档连接起来?
-
要使用标准的全连接网络来预测前三个单词给出的第四个单词,我们需要对模型进行哪两个调整?
-
我们如何在 PyTorch 中跨多个层共享权重矩阵?
-
编写一个模块,预测句子前两个单词给出的第三个单词,而不偷看。
-
什么是循环神经网络?
-
隐藏状态是什么?
-
LMModel1中隐藏状态的等价物是什么? -
为了在 RNN 中保持状态,为什么按顺序将文本传递给模型很重要?
-
什么是 RNN 的“展开”表示?
-
为什么在 RNN 中保持隐藏状态会导致内存和性能问题?我们如何解决这个问题?
-
什么是 BPTT?
-
编写代码打印出验证集的前几个批次,包括将标记 ID 转换回英文字符串,就像我们在第十章中展示的 IMDb 数据批次一样。
-
ModelResetter回调函数的作用是什么?我们为什么需要它? -
为每三个输入词预测一个输出词的缺点是什么?
-
为什么我们需要为
LMModel4设计一个自定义损失函数? -
为什么
LMModel4的训练不稳定? -
在展开表示中,我们可以看到递归神经网络有许多层。那么为什么我们需要堆叠 RNN 以获得更好的结果?
-
绘制一个堆叠(多层)RNN 的表示。
-
如果我们不经常调用
detach,为什么在 RNN 中应该获得更好的结果?为什么在实践中可能不会发生这种情况? -
为什么深度网络可能导致非常大或非常小的激活?这为什么重要?
-
在计算机的浮点数表示中,哪些数字是最精确的?
-
为什么消失的梯度会阻止训练?
-
在 LSTM 架构中有两个隐藏状态为什么有帮助?每个的目的是什么?
-
在 LSTM 中这两个状态被称为什么?
-
tanh 是什么,它与 sigmoid 有什么关系?
-
LSTMCell中这段代码的目的是什么:h = torch.stack([h, input], dim=1) -
在 PyTorch 中
chunk是做什么的? -
仔细研究
LSTMCell的重构版本,确保你理解它如何以及为什么与未重构版本执行相同的操作。 -
为什么我们可以为
LMModel6使用更高的学习率? -
AWD-LSTM 模型中使用的三种正则化技术是什么?
-
什么是 dropout?
-
为什么我们要用 dropout 来缩放权重?这是在训练期间、推理期间还是两者都应用?
-
Dropout中这行代码的目的是什么:if not self.training: return x -
尝试使用
bernoulli_来了解它的工作原理。 -
如何在 PyTorch 中将模型设置为训练模式?在评估模式下呢?
-
写出激活正则化的方程(数学或代码,任你选择)。它与权重衰减有什么不同?
-
写出时间激活正则化的方程(数学或代码,任你选择)。为什么我们不会在计算机视觉问题中使用这个?
-
语言模型中的权重绑定是什么?
进一步研究
-
在
LMModel2中,为什么forward可以从h=0开始?为什么我们不需要写h=torch.zeros(...)? -
从头开始编写一个 LSTM 的代码(你可以参考图 12-9)。
-
搜索互联网了解 GRU 架构并从头开始实现它,尝试训练一个模型。看看能否获得类似于本章中看到的结果。将你的结果与 PyTorch 内置的
GRU模块的结果进行比较。 -
查看 fastai 中 AWD-LSTM 的源代码,并尝试将每行代码映射到本章中展示的概念。
第十三章:卷积神经网络
在第四章中,我们学习了如何创建一个识别图像的神经网络。我们能够在区分 3 和 7 方面达到 98%以上的准确率,但我们也看到 fastai 内置的类能够接近 100%。让我们开始尝试缩小这个差距。
在本章中,我们将首先深入研究卷积是什么,并从头开始构建一个 CNN。然后,我们将研究一系列技术来改善训练稳定性,并学习库通常为我们应用的所有调整,以获得出色的结果。
卷积的魔力
机器学习从业者手中最强大的工具之一是特征工程。特征是数据的一种转换,旨在使其更容易建模。例如,我们在第九章中用于我们表格数据集预处理的add_datepart函数向 Bulldozers 数据集添加了日期特征。我们能够从图像中创建哪些特征呢?
术语:特征工程
创建输入数据的新转换,以使其更容易建模。
在图像的背景下,特征是一种视觉上独特的属性。例如,数字 7 的特征是在数字的顶部附近有一个水平边缘,以及在其下方有一个从右上到左下的对角边缘。另一方面,数字 3 的特征是在数字的左上角和右下角有一个方向的对角边缘,在左下角和右上角有相反的对角边缘,在中间、顶部和底部有水平边缘等等。那么,如果我们能够提取关于每个图像中边缘出现位置的信息,然后将该信息用作我们的特征,而不是原始像素呢?
事实证明,在图像中找到边缘是计算机视觉中非常常见的任务,而且非常简单。为了做到这一点,我们使用一种称为卷积的东西。卷积只需要乘法和加法——这两种操作是我们将在本书中看到的每个深度学习模型中绝大部分工作的原因!
卷积将一个卷积核应用于图像。卷积核是一个小矩阵,例如图 13-1 右上角的 3×3 矩阵。
应用卷积到一个位置
图 13-1。将卷积应用到一个位置
左侧的 7×7 网格是我们将应用卷积核的图像。卷积操作将卷积核的每个元素与图像的一个 3×3 块的每个元素相乘。然后将这些乘积的结果相加。图 13-1 中的图示显示了将卷积核应用于图像中单个位置的示例,即围绕 18 单元格的 3×3 块。
让我们用代码来做这个。首先,我们创建一个小的 3×3 矩阵如下:
top_edge = tensor([[-1,-1,-1],
[ 0, 0, 0],
[ 1, 1, 1]]).float()
我们将称之为卷积核(因为这是时髦的计算机视觉研究人员称呼的)。当然,我们还需要一张图片:
path = untar_data(URLs.MNIST_SAMPLE)
im3 = Image.open(path/'train'/'3'/'12.png')
show_image(im3);
现在我们将取图像的顶部 3×3 像素正方形,并将这些值中的每一个与我们的卷积核中的每个项目相乘。然后我们将它们加在一起,就像这样:
im3_t = tensor(im3)
im3_t[0:3,0:3] * top_edge
tensor([[-0., -0., -0.],
[0., 0., 0.],
[0., 0., 0.]])
(im3_t[0:3,0:3] * top_edge).sum()
tensor(0.)
到目前为止并不是很有趣——左上角的所有像素都是白色的。但让我们选择一些更有趣的地方:
df = pd.DataFrame(im3_t[:10,:20])
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')
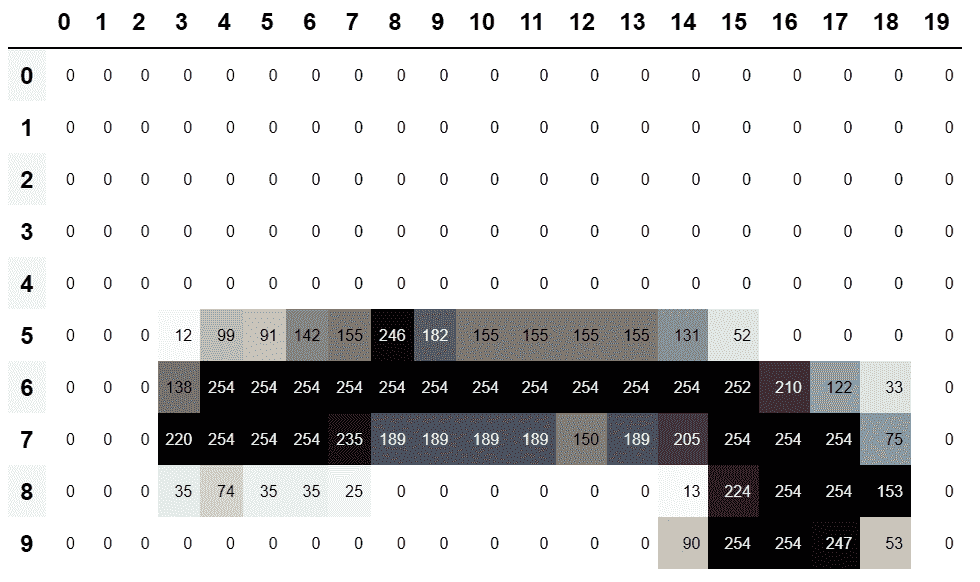
在 5,7 单元格处有一个顶边。让我们在那里重复我们的计算:
(im3_t[4:7,6:9] * top_edge).sum()
tensor(762.)
在 8,18 单元格处有一个右边缘。这给我们带来了什么?
(im3_t[7:10,17:20] * top_edge).sum()
tensor(-29.)
正如您所看到的,这个小计算返回了一个高数字,其中 3×3 像素的正方形代表顶边(即,在正方形顶部有低值,紧接着是高值)。这是因为我们的卷积核中的-1值在这种情况下影响很小,但1值影响很大。
让我们稍微看一下数学。过滤器将在我们的图像中取任意大小为 3×3 的窗口,如果我们像这样命名像素值
它将返回。如果我们在图像的某个部分,其中,和加起来等于,和,那么这些项将互相抵消,我们将得到 0。然而,如果大于,大于,大于,我们将得到一个更大的数字作为结果。因此,这个过滤器检测水平边缘,更准确地说,我们从图像顶部的亮部到底部的暗部。
将我们的过滤器更改为顶部为1,底部为-1的行将检测从暗到亮的水平边缘。将1和-1放在列而不是行中会给我们检测垂直边缘的过滤器。每组权重将产生不同类型的结果。
让我们创建一个函数来为一个位置执行此操作,并检查它是否与之前的结果匹配:
def apply_kernel(row, col, kernel):
return (im3_t[row-1:row+2,col-1:col+2] * kernel).sum()
apply_kernel(5,7,top_edge)
tensor(762.)
但请注意,我们不能将其应用于角落(例如,位置 0,0),因为那里没有完整的 3×3 正方形。
映射卷积核
我们可以在坐标网格上映射apply_kernel()。也就是说,我们将取我们的 3×3 卷积核,并将其应用于图像的每个 3×3 部分。例如,图 13-2 显示了 3×3 卷积核可以应用于 5×5 图像第一行的位置。

图 13-2. 在网格上应用卷积核
要获得坐标网格,我们可以使用嵌套列表推导,如下所示:
[[(i,j) for j in range(1,5)] for i in range(1,5)]
[[(1, 1), (1, 2), (1, 3), (1, 4)],
[(2, 1), (2, 2), (2, 3), (2, 4)],
[(3, 1), (3, 2), (3, 3), (3, 4)],
[(4, 1), (4, 2), (4, 3), (4, 4)]]
嵌套列表推导
在 Python 中经常使用嵌套列表推导,所以如果你以前没有见过它们,请花几分钟确保你理解这里发生了什么,并尝试编写自己的嵌套列表推导。
这是将我们的卷积核应用于坐标网格的结果:
rng = range(1,27)
top_edge3 = tensor([[apply_kernel(i,j,top_edge) for j in rng] for i in rng])
show_image(top_edge3);
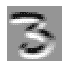
看起来不错!我们的顶部边缘是黑色的,底部边缘是白色的(因为它们是顶部边缘的相反)。现在我们的图像中也包含负数,matplotlib已自动更改了我们的颜色,使得白色是图像中最小的数字,黑色是最高的,零显示为灰色。
我们也可以尝试同样的方法来处理左边缘:
left_edge = tensor([[-1,1,0],
[-1,1,0],
[-1,1,0]]).float()
left_edge3 = tensor([[apply_kernel(i,j,left_edge) for j in rng] for i in rng])
show_image(left_edge3);

正如我们之前提到的,卷积是将这样的内核应用于网格的操作。Vincent Dumoulin 和 Francesco Visin 的论文“深度学习卷积算术指南”中有许多出色的图表,展示了如何应用图像内核。图 13-3 是论文中的一个示例,显示了(底部)一个浅蓝色的 4×4 图像,应用了一个深蓝色的 3×3 内核,创建了一个顶部的 2×2 绿色输出激活图。
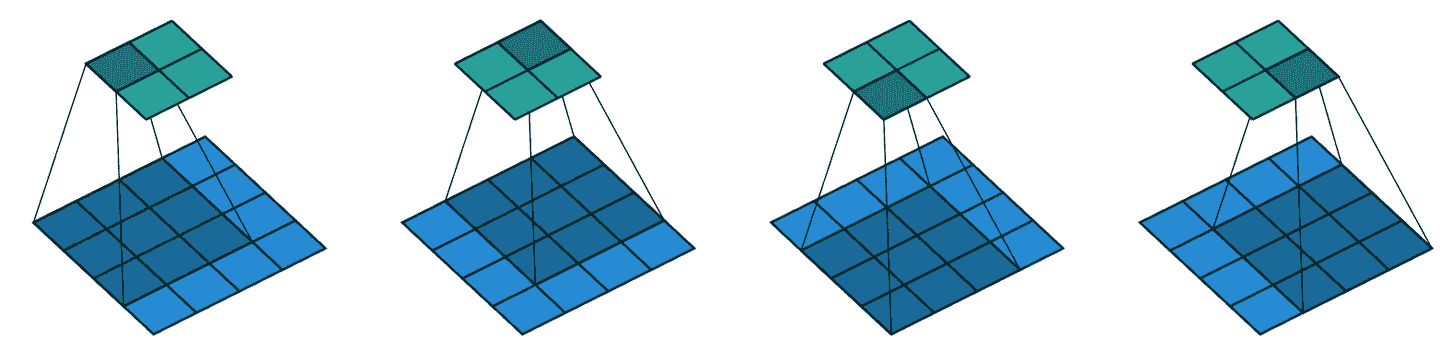
图 13-3。将 3×3 内核应用于 4×4 图像的结果(由 Vincent Dumoulin 和 Francesco Visin 提供)
看一下结果的形状。如果原始图像的高度为h,宽度为w,我们可以找到多少个 3×3 窗口?正如您从示例中看到的,有h-2乘以w-2个窗口,因此我们得到的结果图像的高度为h-2,宽度为w-2。
我们不会从头开始实现这个卷积函数,而是使用 PyTorch 的实现(它比我们在 Python 中能做的任何事情都要快)。
PyTorch 中的卷积
卷积是一个如此重要且广泛使用的操作,PyTorch 已经内置了它。它被称为F.conv2d(回想一下,F是从torch.nn.functional中导入的 fastai,正如 PyTorch 建议的)。PyTorch 文档告诉我们它包括这些参数:
input
形状为(minibatch, in_channels, iH, iW)的输入张量
weight
形状为(out_channels, in_channels, kH, kW)的滤波器
这里iH,iW是图像的高度和宽度(即28,28),kH,kW是我们内核的高度和宽度(3,3)。但显然 PyTorch 期望这两个参数都是秩为 4 的张量,而当前我们只有秩为 2 的张量(即矩阵,或具有两个轴的数组)。
这些额外轴的原因是 PyTorch 有一些技巧。第一个技巧是 PyTorch 可以同时将卷积应用于多个图像。这意味着我们可以一次在批次中的每个项目上调用它!
第二个技巧是 PyTorch 可以同时应用多个内核。因此,让我们也创建对角边缘内核,然后将我们的四个边缘内核堆叠成一个单个张量:
diag1_edge = tensor([[ 0,-1, 1],
[-1, 1, 0],
[ 1, 0, 0]]).float()
diag2_edge = tensor([[ 1,-1, 0],
[ 0, 1,-1],
[ 0, 0, 1]]).float()
edge_kernels = torch.stack([left_edge, top_edge, diag1_edge, diag2_edge])
edge_kernels.shape
torch.Size([4, 3, 3])
为了测试这个,我们需要一个DataLoader和一个样本小批量。让我们使用数据块 API:
mnist = DataBlock((ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter(),
get_y=parent_label)
dls = mnist.dataloaders(path)
xb,yb = first(dls.valid)
xb.shape
torch.Size([64, 1, 28, 28])
默认情况下,fastai 在使用数据块时会将数据放在 GPU 上。让我们将其移动到 CPU 用于我们的示例:
xb,yb = to_cpu(xb),to_cpu(yb)
一个批次包含 64 张图片,每张图片有 1 个通道,每个通道有 28×28 个像素。F.conv2d也可以处理多通道(彩色)图像。通道是图像中的单个基本颜色——对于常规全彩图像,有三个通道,红色、绿色和蓝色。PyTorch 将图像表示为一个秩为 3 的张量,具有以下维度:
[*channels*, *rows*, *columns*]
我们将在本章后面看到如何处理多个通道。传递给F.conv2d的内核需要是秩为 4 的张量:
[*channels_in*, *features_out*, *rows*, *columns*]
edge_kernels目前缺少其中一个:我们需要告诉 PyTorch 内核中的输入通道数是 1,我们可以通过在第一个位置插入一个大小为 1 的轴来实现(这称为单位轴),PyTorch 文档显示in_channels应该是预期的。要在张量中插入一个单位轴,我们使用unsqueeze方法:
edge_kernels.shape,edge_kernels.unsqueeze(1).shape
(torch.Size([4, 3, 3]), torch.Size([4, 1, 3, 3]))
现在这是edge_kernels的正确形状。让我们将所有这些传递给conv2d:
edge_kernels = edge_kernels.unsqueeze(1)
batch_features = F.conv2d(xb, edge_kernels)
batch_features.shape
torch.Size([64, 4, 26, 26])
输出形状显示我们有 64 个图像在小批量中,4 个内核,以及 26×26 的边缘映射(我们从前面讨论中开始是 28×28 的图像,但每边丢失一个像素)。我们可以看到我们得到了与手动操作时相同的结果:
show_image(batch_features[0,0]);
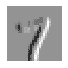
PyTorch 最重要的技巧是它可以使用 GPU 并行地完成所有这些工作-将多个核应用于多个图像,跨多个通道。并行进行大量工作对于使 GPU 高效工作至关重要;如果我们一次执行每个操作,通常会慢几百倍(如果我们使用前一节中的手动卷积循环,将慢数百万倍!)。因此,要成为一名优秀的深度学习从业者,一个需要练习的技能是让 GPU 一次处理大量工作。
不要在每个轴上丢失这两个像素会很好。我们这样做的方法是添加填充,简单地在图像周围添加额外的像素。最常见的是添加零像素。
步幅和填充
通过适当的填充,我们可以确保输出激活图与原始图像的大小相同,这在构建架构时可以使事情变得简单得多。图 13-4 显示了添加填充如何允许我们在图像角落应用核。

图 13-4。带填充的卷积
使用 5×5 输入,4×4 核和 2 像素填充,我们最终得到一个 6×6 的激活图,如我们在图 13-5 中所看到的。
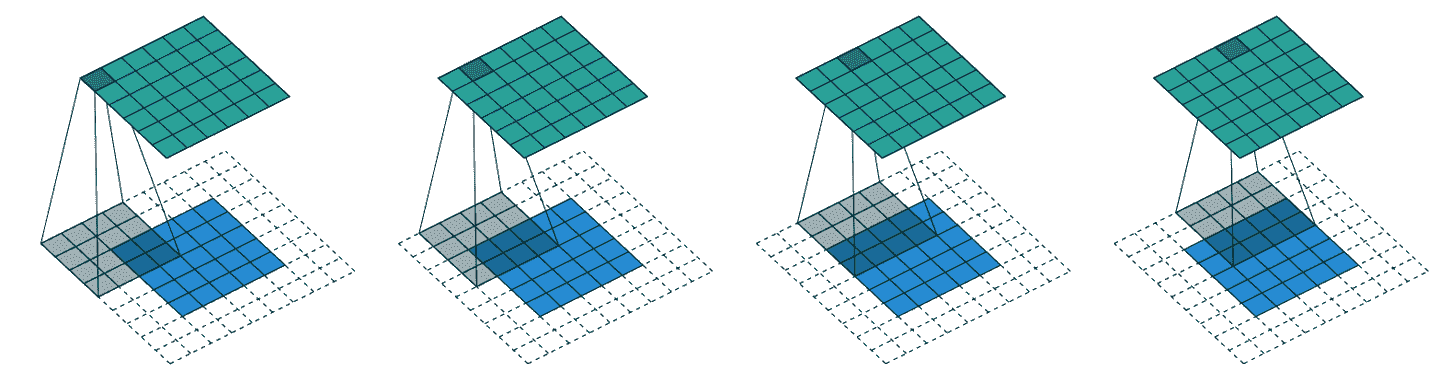
图 13-5。一个 4×4 的核与 5×5 的输入和 2 像素的填充(由 Vincent Dumoulin 和 Francesco Visin 提供)
如果我们添加一个大小为ks乘以ks的核(其中ks是一个奇数),为了保持相同的形状,每一侧所需的填充是ks//2。对于ks的偶数,需要在上/下和左/右两侧填充不同数量,但实际上我们几乎从不使用偶数滤波器大小。
到目前为止,当我们将核应用于网格时,我们每次将其移动一个像素。但我们可以跳得更远;例如,我们可以在每次核应用后移动两个像素,就像图 13-6 中所示。这被称为步幅-2卷积。实践中最常见的核大小是 3×3,最常见的填充是 1。正如您将看到的,步幅-2 卷积对于减小输出大小很有用,而步幅-1 卷积对于添加层而不改变输出大小也很有用。
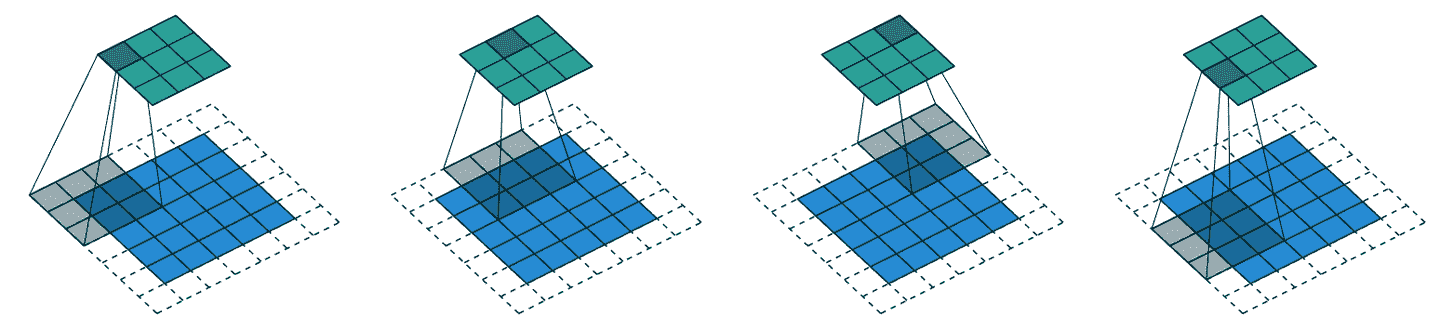
图 13-6。一个 3×3 的核与 5×5 的输入,步幅 2 卷积和 1 像素填充(由 Vincent Dumoulin 和 Francesco Visin 提供)
在大小为h乘以w的图像中,使用填充 1 和步幅 2 将给出大小为(h+1)//2乘以(w+1)//2的结果。每个维度的一般公式是
(n + 2*pad - ks) // stride + 1
其中pad是填充,ks是我们核的大小,stride是步幅。
现在让我们看看如何计算我们卷积结果的像素值。
理解卷积方程
为了解释卷积背后的数学,fast.ai 学生 Matt Kleinsmith 提出了一个非常聪明的想法,展示了不同视角的 CNNs。事实上,这个想法非常聪明,非常有帮助,我们也会在这里展示!
这是我们的 3×3 像素图像,每个像素都用字母标记:

这是我们的核,每个权重都用希腊字母标记:

由于滤波器适合图像四次,我们有四个结果:

图 13-7 显示了我们如何将核应用于图像的每个部分以产生每个结果。
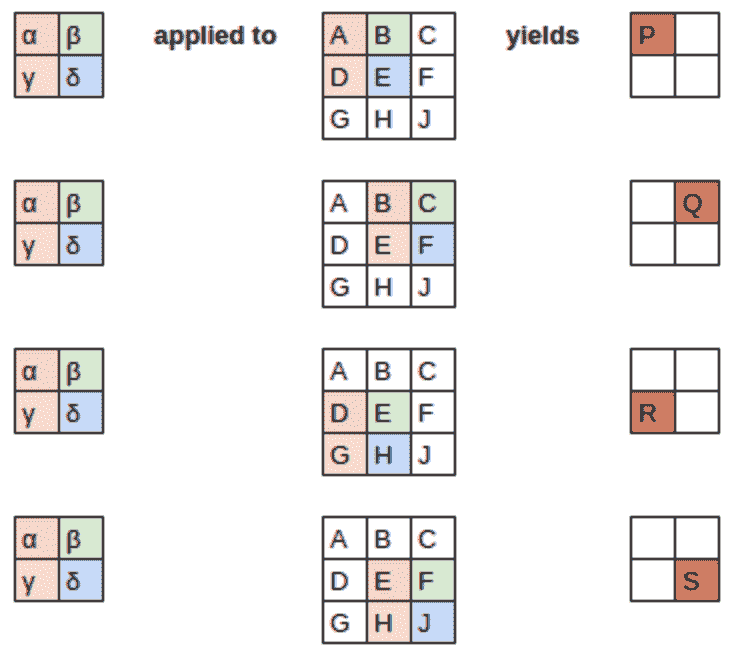
图 13-7。应用核
方程视图在图 13-8 中。
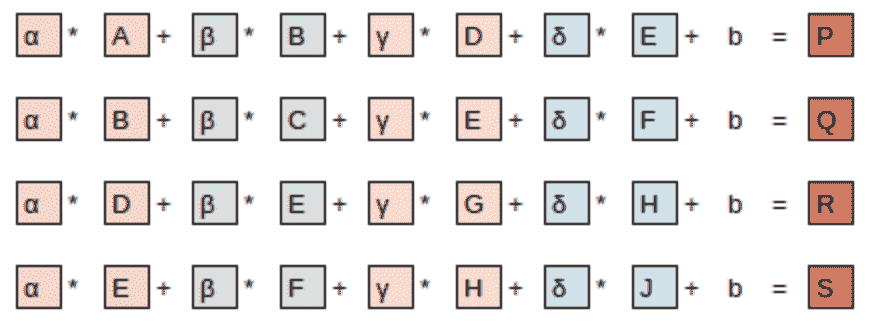
图 13-8。方程
请注意,偏置项b对于图像的每个部分都是相同的。您可以将偏置视为滤波器的一部分,就像权重(α、β、γ、δ)是滤波器的一部分一样。
这里有一个有趣的见解——卷积可以被表示为一种特殊类型的矩阵乘法,如图 13-9 所示。权重矩阵就像传统神经网络中的那些一样。但是,这个权重矩阵具有两个特殊属性:
-
灰色显示的零是不可训练的。这意味着它们在优化过程中将保持为零。
-
一些权重是相等的,虽然它们是可训练的(即可更改的),但它们必须保持相等。这些被称为共享权重。
零对应于滤波器无法触及的像素。权重矩阵的每一行对应于滤波器的一次应用。
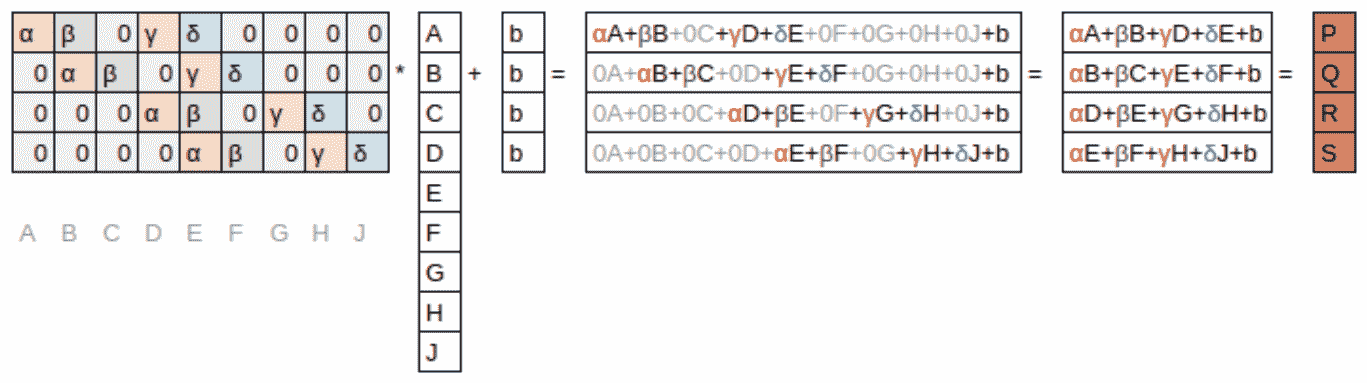
图 13-9。卷积作为矩阵乘法
现在我们了解了卷积是什么,让我们使用它们来构建一个神经网络。
我们的第一个卷积神经网络
没有理由相信某些特定的边缘滤波器是图像识别最有用的卷积核。此外,我们已经看到在后续层中,卷积核变成了来自较低层特征的复杂转换,但我们不知道如何手动构建这些转换。
相反,最好学习卷积核的值。我们已经知道如何做到这一点——SGD!实际上,模型将学习对分类有用的特征。当我们使用卷积而不是(或者除了)常规线性层时,我们创建了一个卷积神经网络(CNN)。
创建 CNN
让我们回到第四章中的基本神经网络。它的定义如下:
simple_net = nn.Sequential(
nn.Linear(28*28,30),
nn.ReLU(),
nn.Linear(30,1)
)
我们可以查看模型的定义:
simple_net
Sequential(
(0): Linear(in_features=784, out_features=30, bias=True)
(1): ReLU()
(2): Linear(in_features=30, out_features=1, bias=True)
)
现在我们想要创建一个类似于这个线性模型的架构,但是使用卷积层而不是线性层。nn.Conv2d是F.conv2d的模块等效物。在创建架构时,它比F.conv2d更方便,因为在实例化时会自动为我们创建权重矩阵。
这是一个可能的架构:
broken_cnn = sequential(
nn.Conv2d(1,30, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(30,1, kernel_size=3, padding=1)
)
这里需要注意的一点是,我们不需要指定28*28作为输入大小。这是因为线性层需要在权重矩阵中为每个像素设置一个权重,因此它需要知道有多少像素,但卷积会自动应用于每个像素。权重仅取决于输入和输出通道的数量以及核大小,正如我们在前一节中看到的。
想一想输出形状会是什么;然后让我们尝试一下:
broken_cnn(xb).shape
torch.Size([64, 1, 28, 28])
这不是我们可以用来进行分类的东西,因为我们需要每个图像一个单独的输出激活,而不是一个 28×28 的激活图。处理这个问题的一种方法是使用足够多的步幅为 2 的卷积,使得最终层的大小为 1。经过一次步幅为 2 的卷积后,大小将为 14×14;经过两次后,将为 7×7;然后是 4×4,2×2,最终大小为 1。
现在让我们尝试一下。首先,我们将定义一个函数,其中包含我们在每个卷积中将使用的基本参数:
def conv(ni, nf, ks=3, act=True):
res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU())
return res
重构
重构神经网络的部分,可以减少由于架构不一致而导致的错误,也可以更明显地向读者展示哪些层的部分实际上在改变。
当我们使用步幅为 2 的卷积时,通常会同时增加特征的数量。这是因为我们通过将激活图中的激活数量减少 4 倍来减少层的容量,我们不希望一次过多地减少层的容量。
术语:通道和特征
这两个术语通常可以互换使用,指的是权重矩阵的第二轴的大小,即卷积后每个网格单元的激活数量。特征从不用于指代输入数据,但通道可以指代输入数据(通常是颜色)或网络内部的激活。
以下是我们如何构建一个简单的 CNN:
simple_cnn = sequential(
conv(1 ,4), #14x14
conv(4 ,8), #7x7
conv(8 ,16), #4x4
conv(16,32), #2x2
conv(32,2, act=False), #1x1
Flatten(),
)
Jeremy 说
我喜欢在每个卷积后添加类似这里的注释,以显示每个层后激活图的大小。这些注释假定输入大小为 28×28。
现在网络输出两个激活,这对应于我们标签中的两个可能级别:
simple_cnn(xb).shape
torch.Size([64, 2])
我们现在可以创建我们的Learner:
learn = Learner(dls, simple_cnn, loss_func=F.cross_entropy, metrics=accuracy)
要查看模型中发生的情况,我们可以使用summary:
learn.summary()
Sequential (Input shape: ['64 x 1 x 28 x 28'])
================================================================
Layer (type) Output Shape Param # Trainable
================================================================
Conv2d 64 x 4 x 14 x 14 40 True
________________________________________________________________
ReLU 64 x 4 x 14 x 14 0 False
________________________________________________________________
Conv2d 64 x 8 x 7 x 7 296 True
________________________________________________________________
ReLU 64 x 8 x 7 x 7 0 False
________________________________________________________________
Conv2d 64 x 16 x 4 x 4 1,168 True
________________________________________________________________
ReLU 64 x 16 x 4 x 4 0 False
________________________________________________________________
Conv2d 64 x 32 x 2 x 2 4,640 True
________________________________________________________________
ReLU 64 x 32 x 2 x 2 0 False
________________________________________________________________
Conv2d 64 x 2 x 1 x 1 578 True
________________________________________________________________
Flatten 64 x 2 0 False
________________________________________________________________
Total params: 6,722
Total trainable params: 6,722
Total non-trainable params: 0
Optimizer used: <function Adam at 0x7fbc9c258cb0>
Loss function: <function cross_entropy at 0x7fbca9ba0170>
Callbacks:
- TrainEvalCallback
- Recorder
- ProgressCallback
请注意,最终的Conv2d层的输出是64x2x1x1。我们需要去除那些额外的1x1轴;这就是Flatten所做的。这基本上与 PyTorch 的squeeze方法相同,但作为一个模块。
让我们看看这是否训练!由于这是我们从头开始构建的比以前更深的网络,我们将使用更低的学习率和更多的时代:
learn.fit_one_cycle(2, 0.01)
| 时代 | 训练损失 | 验证损失 | 准确性 | 时间 |
|---|---|---|---|---|
| 0 | 0.072684 | 0.045110 | 0.990186 | 00:05 |
| 1 | 0.022580 | 0.030775 | 0.990186 | 00:05 |
成功!它越来越接近我们之前的resnet18结果,尽管还不完全达到,而且需要更多的时代,我们需要使用更低的学习率。我们还有一些技巧要学习,但我们越来越接近能够从头开始创建现代 CNN。
理解卷积算术
我们可以从总结中看到,我们有一个大小为64x1x28x28的输入。轴是批次、通道、高度、宽度。这通常表示为NCHW(其中N是批次大小)。另一方面,TensorFlow 使用NHWC轴顺序。这是第一层:
m = learn.model[0]
m
Sequential(
(0): Conv2d(1, 4, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
因此,我们有 1 个输入通道,4 个输出通道和一个 3×3 的内核。让我们检查第一个卷积的权重:
m[0].weight.shape
torch.Size([4, 1, 3, 3])
总结显示我们有 40 个参数,4*1*3*3是 36。其他四个参数是什么?让我们看看偏差包含什么:
m[0].bias.shape
torch.Size([4])
我们现在可以利用这些信息来澄清我们在上一节中的陈述:“当我们使用步幅为 2 的卷积时,我们经常增加特征的数量,因为我们通过 4 的因子减少了激活图中的激活数量;我们不希望一次性太多地减少层的容量。”
每个通道都有一个偏差。(有时通道被称为特征或滤波器,当它们不是输入通道时。) 输出形状是64x4x14x14,因此这将成为下一层的输入形状。根据summary,下一层有 296 个参数。让我们忽略批次轴,保持简单。因此,对于14*14=196个位置,我们正在乘以296-8=288个权重(为简单起见忽略偏差),因此在这一层有196*288=56,448次乘法。下一层将有7*7*(1168-16)=56,448次乘法。
这里发生的情况是,我们的步幅为 2 的卷积将网格大小从14x14减半到7x7,并且我们将滤波器数量从 8 增加到 16,导致总体计算量没有变化。如果我们在每个步幅为 2 的层中保持通道数量不变,那么网络中所做的计算量会随着深度增加而减少。但我们知道,更深层次必须计算语义丰富的特征(如眼睛或毛发),因此我们不会期望减少计算是有意义的。
另一种思考这个问题的方式是基于感受野。
感受野
接受域是参与层计算的图像区域。在书籍网站上,您会找到一个名为conv-example.xlsx的 Excel 电子表格,展示了使用 MNIST 数字计算两个步幅为 2 的卷积层的过程。每个层都有一个单独的核。图 13-10 展示了如果我们点击conv2部分中的一个单元格,显示第二个卷积层的输出,并点击trace precedents时看到的内容。
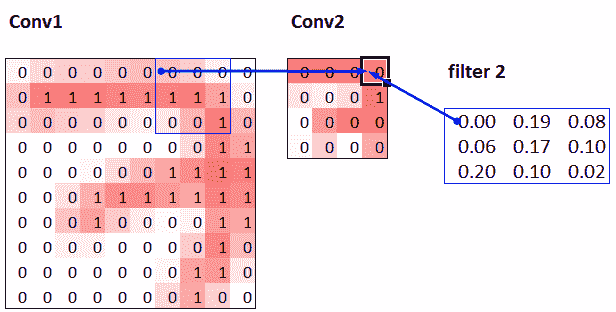
图 13-10. Conv2 层的直接前置
这里,有绿色边框的单元格是我们点击的单元格,蓝色高亮显示的单元格是它的前置——用于计算其值的单元格。这些单元格是输入层(左侧)的对应 3×3 区域单元格和滤波器(右侧)的单元格。现在让我们再次点击trace precedents,看看用于计算这些输入的单元格。图 13-11 展示了发生了什么。
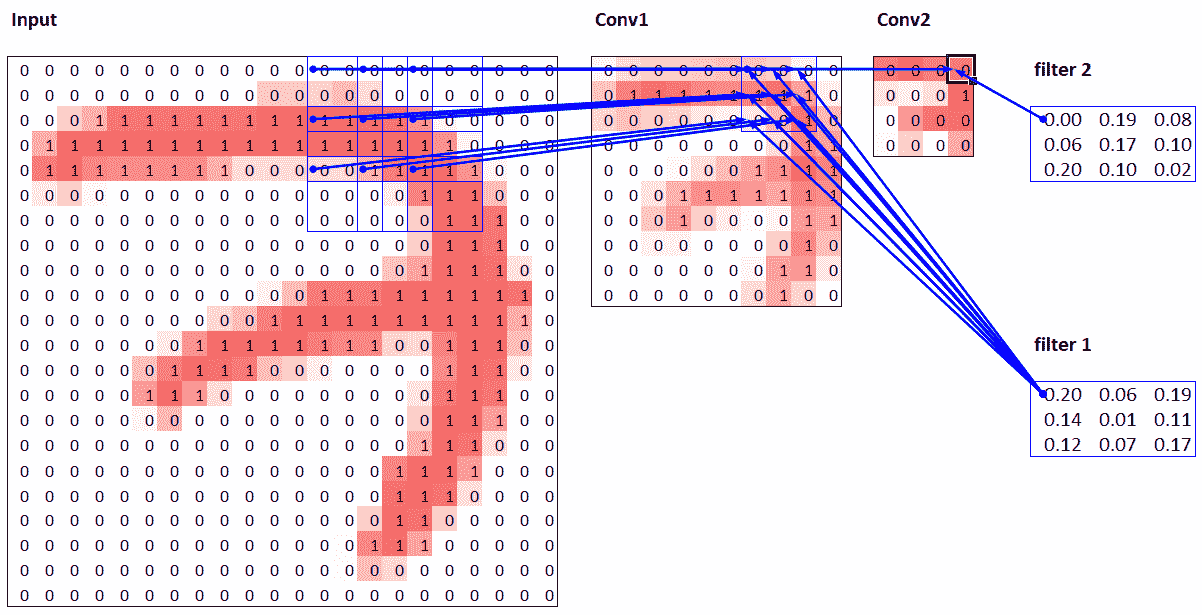
图 13-11. Conv2 层的次要前置
在这个例子中,我们只有两个步幅为 2 的卷积层,因此现在追溯到了输入图像。我们可以看到输入层中的一个 7×7 区域单元格用于计算 Conv2 层中的单个绿色单元格。这个 7×7 区域是 Conv2 中绿色激活的输入的接受域。我们还可以看到现在需要第二个滤波器核,因为我们有两个层。
从这个例子中可以看出,我们在网络中越深(特别是在一个层之前有更多步幅为 2 的卷积层时),该层中激活的接受域就越大。一个大的接受域意味着输入图像的大部分被用来计算该层中每个激活。我们现在知道,在网络的深层,我们有语义丰富的特征,对应着更大的接受域。因此,我们期望我们需要更多的权重来处理这种不断增加的复杂性。这是另一种说法,与我们在前一节提到的相同:当我们在网络中引入步幅为 2 的卷积时,我们也应该增加通道数。
在撰写这一特定章节时,我们有很多问题需要回答,以便尽可能好地向您解释 CNN。信不信由你,我们在 Twitter 上找到了大部分答案。在我们继续讨论彩色图像之前,我们将快速休息一下,与您谈谈这个问题。
关于 Twitter 的一点说明
总的来说,我们并不是社交网络的重度用户。但我们写这本书的目标是帮助您成为最优秀的深度学习从业者,我们不提及 Twitter 在我们自己的深度学习之旅中有多么重要是不合适的。
您看,Twitter 还有另一部分,远离唐纳德·特朗普和卡戴珊家族,深度学习研究人员和从业者每天都在这里交流。在我们撰写这一部分时,Jeremy 想要再次确认我们关于步幅为 2 的卷积的说法是否准确,所以他在 Twitter 上提问:

几分钟后,这个答案出现了:
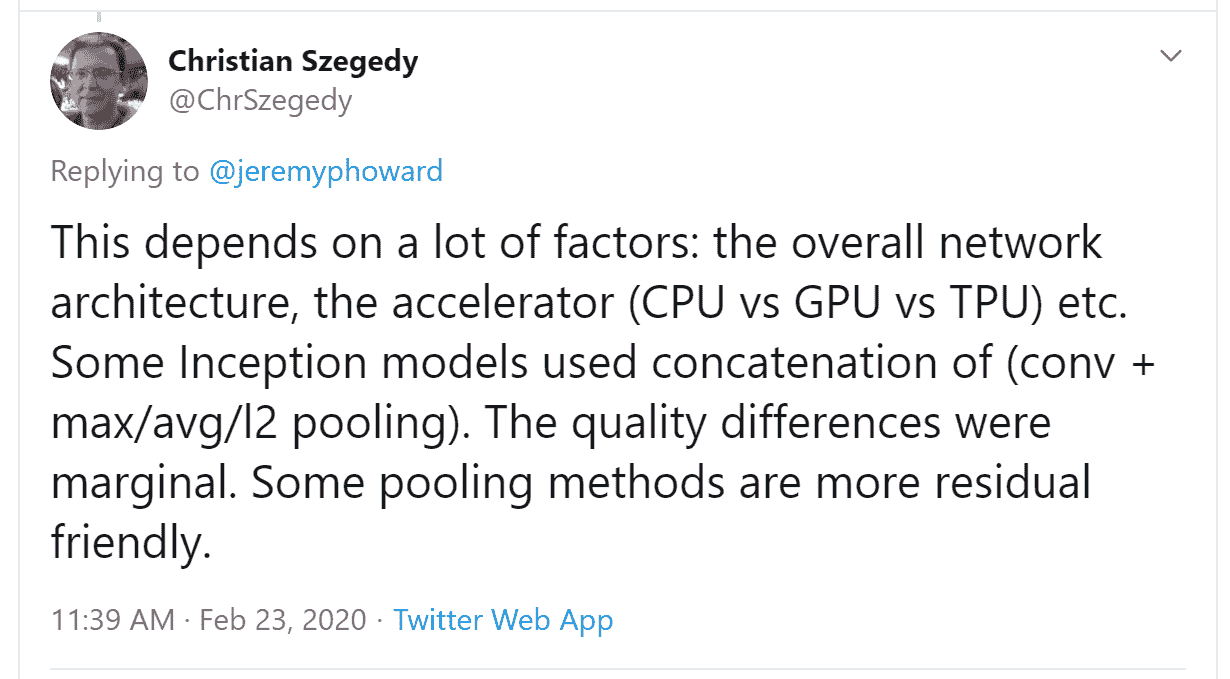
Christian Szegedy 是Inception的第一作者,这是 2014 年 ImageNet 的获奖作品,也是现代神经网络中许多关键见解的来源。两小时后,这个出现了:
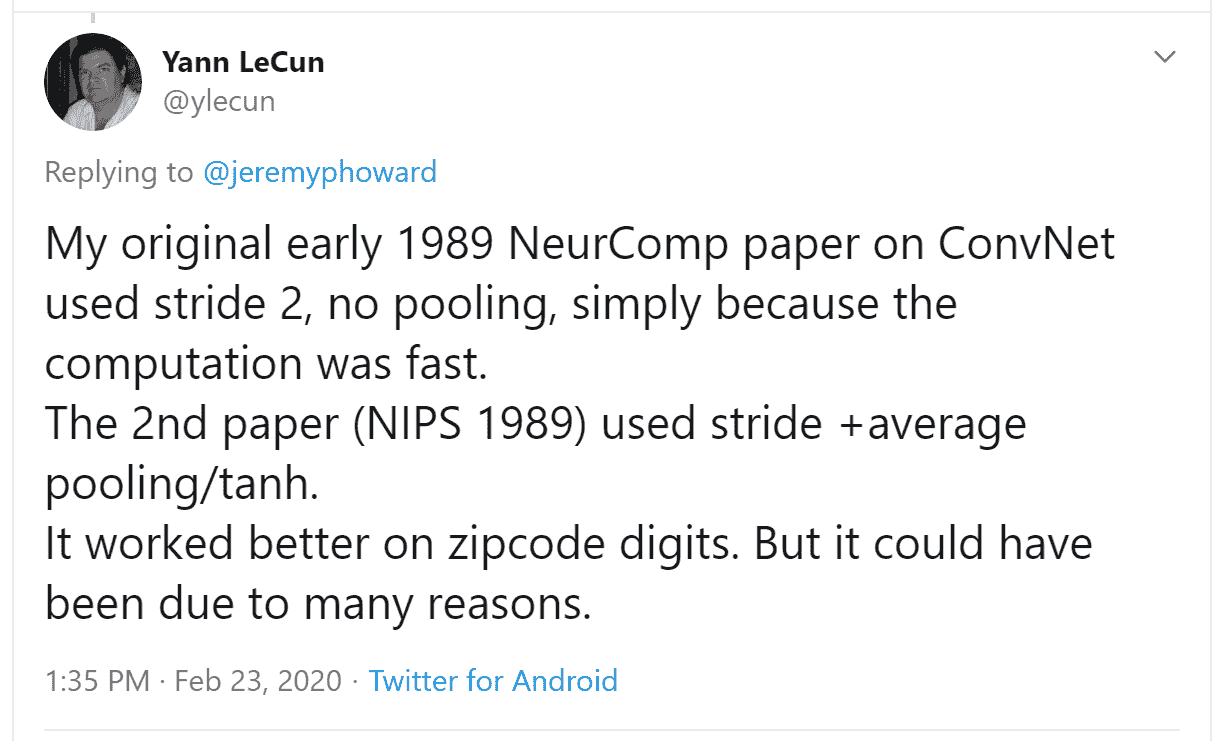
你认识那个名字吗?您在第二章中看到过,当时我们在谈论今天建立深度学习基础的图灵奖获得者!
Jeremy 还在 Twitter 上询问有关我们在第七章中描述的标签平滑是否准确,并再次直接从 Christian Szegedy(标签平滑最初是在 Inception 论文中引入的)那里得到了回应:
今天深度学习领域的许多顶尖人物经常在 Twitter 上活跃,并且非常乐意与更广泛的社区互动。一个好的开始方法是查看 Jeremy 的最近的 Twitter 点赞,或者Sylvain 的。这样,您可以看到我们认为有趣和有用的人发表的 Twitter 用户列表。
Twitter 是我们保持与有趣论文、软件发布和其他深度学习新闻最新的主要途径。为了与深度学习社区建立联系,我们建议在fast.ai 论坛和 Twitter 上都积极参与。
话虽如此,让我们回到本章的重点。到目前为止,我们只展示了黑白图片的示例,每个像素只有一个值。实际上,大多数彩色图像每个像素有三个值来定义它们的颜色。接下来我们将看看如何处理彩色图像。
彩色图像
彩色图片是一个三阶张量:
im = image2tensor(Image.open('images/grizzly.jpg'))
im.shape
torch.Size([3, 1000, 846])
show_image(im);

第一个轴包含红色、绿色和蓝色的通道:
_,axs = subplots(1,3)
for bear,ax,color in zip(im,axs,('Reds','Greens','Blues')):
show_image(255-bear, ax=ax, cmap=color)

我们看到卷积操作是针对图像的一个通道上的一个滤波器(我们的示例是在一个正方形上完成的)。卷积层将接受一个具有一定数量通道的图像(对于常规 RGB 彩色图像的第一层有三个通道),并输出一个具有不同数量通道的图像。与我们的隐藏大小代表线性层中神经元数量一样,我们可以决定有多少个滤波器,并且每个滤波器都可以专门化(一些用于检测水平边缘,其他用于检测垂直边缘等等),从而产生类似我们在第二章中学习的示例。
在一个滑动窗口中,我们有一定数量的通道,我们需要同样数量的滤波器(我们不对所有通道使用相同的核)。因此,我们的核不是 3×3 的大小,而是ch_in(通道数)乘以 3×3。在每个通道上,我们将窗口的元素乘以相应滤波器的元素,然后对结果求和(如前所述),并对所有滤波器求和。在图 13-12 中给出的示例中,我们在该窗口上的卷积层的结果是红色+绿色+蓝色。
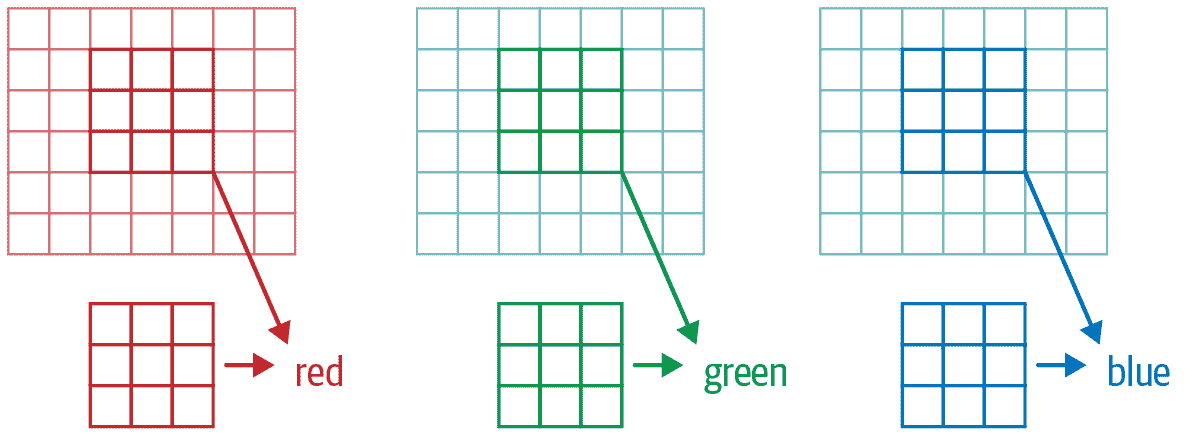
图 13-12. 在 RGB 图像上进行卷积
因此,为了将卷积应用于彩色图片,我们需要一个大小与第一个轴匹配的核张量。在每个位置,核和图像块的相应部分相乘。
然后,所有这些都相加在一起,为每个输出特征的每个网格位置产生一个单个数字,如图 13-13 所示。
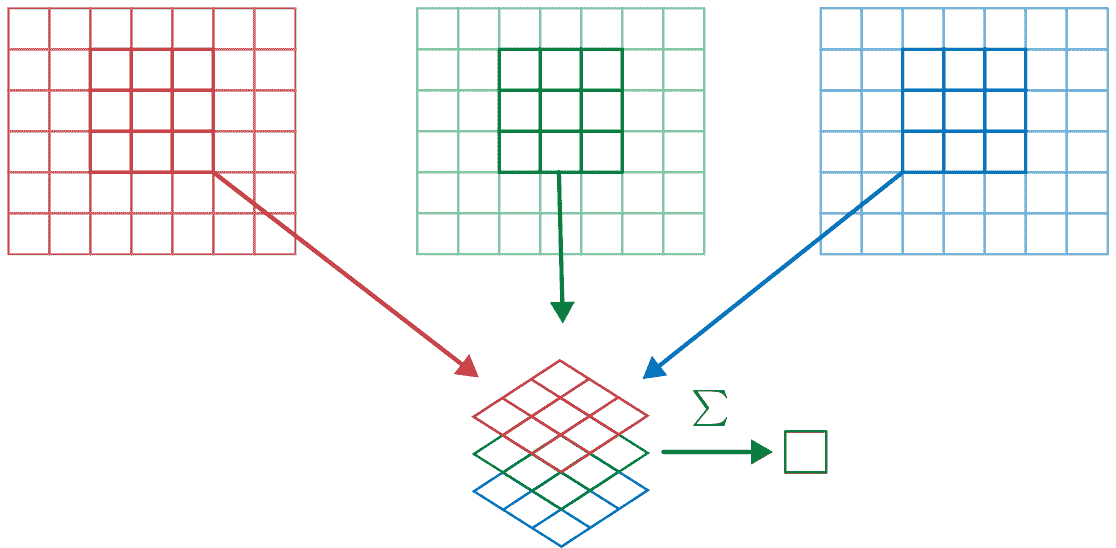
图 13-13. 添加 RGB 滤波器
然后我们有ch_out这样的滤波器,因此最终,我们的卷积层的结果将是一个具有ch_out通道的图像批次,高度和宽度由前面概述的公式给出。这给我们ch_out大小为ch_in x ks x ks的张量,我们将其表示为一个四维大张量。在 PyTorch 中,这些权重的维度顺序是ch_out x ch_in x ks x ks。
此外,我们可能希望为每个滤波器设置一个偏置。在前面的示例中,我们的卷积层的最终结果将是。就像在线性层中一样,我们有多少个卷积核就有多少个偏置,因此偏置是大小为ch_out的向量。
在使用彩色图像进行训练 CNN 时不需要特殊机制。只需确保您的第一层有三个输入。
有很多处理彩色图像的方法。例如,您可以将它们转换为黑白色,从 RGB 转换为 HSV(色调、饱和度和值)颜色空间等。一般来说,实验证明,改变颜色的编码不会对模型结果产生任何影响,只要在转换中不丢失信息。因此,转换为黑白色是一个坏主意,因为它完全删除了颜色信息(这可能是关键的;例如,宠物品种可能具有独特的颜色);但通常转换为 HSV 不会产生任何影响。
现在您知道了第一章中“神经网络学习到的内容”中的那些图片来自Zeiler 和 Fergus 的论文的含义!作为提醒,这是他们关于一些第 1 层权重的图片:

这是将卷积核的三个切片,对于每个输出特征,显示为图像。我们可以看到,即使神经网络的创建者从未明确创建用于查找边缘的卷积核,神经网络也会使用 SGD 自动发现这些特征。
现在让我们看看如何训练这些 CNN,并向您展示 fastai 在底层使用的所有技术,以实现高效的训练。
提高训练稳定性
由于我们在识别 3 和 7 方面做得很好,让我们转向更难的事情——识别所有 10 个数字。这意味着我们需要使用MNIST而不是MNIST_SAMPLE:
path = untar_data(URLs.MNIST)
path.ls()
(#2) [Path('testing'),Path('training')]
数据在两个名为training和testing的文件夹中,因此我们必须告诉GrandparentSplitter这一点(默认为train和valid)。我们在get_dls函数中执行此操作,该函数定义使得稍后更改批量大小变得容易:
def get_dls(bs=64):
return DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter('training','testing'),
get_y=parent_label,
batch_tfms=Normalize()
).dataloaders(path, bs=bs)
dls = get_dls()
记住,在使用数据之前先查看数据总是一个好主意:
dls.show_batch(max_n=9, figsize=(4,4))
现在我们的数据准备好了,我们可以在上面训练一个简单的模型。
一个简单的基线
在本章的前面,我们基于类似于conv函数构建了一个模型:
def conv(ni, nf, ks=3, act=True):
res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU())
return res
让我们从一个基本的 CNN 作为基线开始。我们将使用与之前相同的一个,但有一个调整:我们将使用更多的激活。由于我们有更多的数字需要区分,我们可能需要学习更多的滤波器。
正如我们讨论过的,通常我们希望每次有一个步幅为 2 的层时将滤波器数量加倍。在整个网络中增加滤波器数量的一种方法是在第一层中将激活数量加倍,然后每个之后的层也将比之前的版本大一倍。
但这会产生一个微妙的问题。考虑应用于每个像素的卷积核。默认情况下,我们使用一个 3×3 像素的卷积核。因此,在每个位置上,卷积核被应用到了总共 3×3=9 个像素。以前,我们的第一层有四个输出滤波器。因此,在每个位置上,从九个像素计算出四个值。想想如果我们将输出加倍到八个滤波器会发生什么。然后当我们应用我们的卷积核时,我们将使用九个像素来计算八个数字。这意味着它实际上并没有学到太多:输出大小几乎与输入大小相同。只有当神经网络被迫这样做时,即从操作的输出数量明显小于输入数量时,它们才会创建有用的特征。
为了解决这个问题,我们可以在第一层使用更大的卷积核。如果我们使用一个 5×5 像素的卷积核,每次卷积核应用时将使用 25 个像素。从中创建八个滤波器将意味着神经网络将不得不找到一些有用的特征:
def simple_cnn():
return sequential(
conv(1 ,8, ks=5), #14x14
conv(8 ,16), #7x7
conv(16,32), #4x4
conv(32,64), #2x2
conv(64,10, act=False), #1x1
Flatten(),
)
正如您将在接下来看到的,我们可以在模型训练时查看模型内部,以尝试找到使其训练更好的方法。为此,我们使用ActivationStats回调,记录每个可训练层的激活的均值、标准差和直方图(正如我们所见,回调用于向训练循环添加行为;我们将在第十六章中探讨它们的工作原理):
from fastai.callback.hook import *
我们希望快速训练,这意味着以较高的学习率进行训练。让我们看看在 0.06 时的效果如何:
def fit(epochs=1):
learn = Learner(dls, simple_cnn(), loss_func=F.cross_entropy,
metrics=accuracy, cbs=ActivationStats(with_hist=True))
learn.fit(epochs, 0.06)
return learn
learn = fit()
| 轮数 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 2.307071 | 2.305865 | 0.113500 | 00:16 |
这次训练效果不佳!让我们找出原因。
传递给Learner的回调的一个方便功能是它们会自动提供,名称与回调类相同,除了使用驼峰命名法。因此,我们的ActivationStats回调可以通过activation_stats访问。我相信你还记得learn.recorder...你能猜到它是如何实现的吗?没错,它是一个名为Recorder的回调!
ActivationStats包含一些方便的实用程序,用于绘制训练期间的激活。plot_layer_stats(*idx*)绘制第idx层激活的均值和标准差,以及接近零的激活百分比。这是第一层的图表:
learn.activation_stats.plot_layer_stats(0)
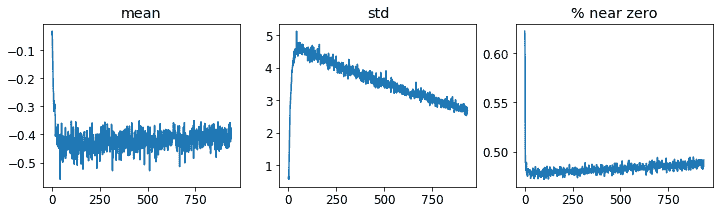
通常情况下,我们的模型在训练期间应该具有一致或至少平滑的层激活均值和标准差。接近零的激活值特别有问题,因为这意味着我们的模型中有一些计算根本没有做任何事情(因为乘以零得到零)。当一个层中有一些零时,它们通常会传递到下一层...然后创建更多的零。这是我们网络的倒数第二层:
learn.activation_stats.plot_layer_stats(-2)
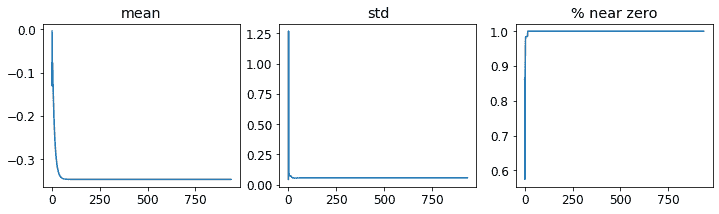
正如预期的那样,问题在网络末端变得更糟,因为不稳定性和零激活在层间累积。让我们看看如何使训练更稳定。
增加批量大小
使训练更稳定的一种方法是增加批量大小。较大的批次具有更准确的梯度,因为它们是从更多数据计算出来的。然而,较大的批量大小意味着每个轮数的批次更少,这意味着您的模型更新权重的机会更少。让我们看看批量大小为 512 是否有帮助:
dls = get_dls(512)
learn = fit()
| 轮数 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 2.309385 | 2.302744 | 0.113500 | 00:08 |
让我们看看倒数第二层是什么样的:
learn.activation_stats.plot_layer_stats(-2)
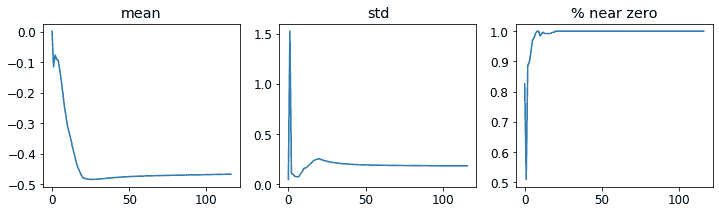
再次,我们的大多数激活值接近零。让我们看看我们可以做些什么来改善训练稳定性。
1cycle 训练
我们的初始权重不适合我们要解决的任务。因此,以高学习率开始训练是危险的:我们很可能会使训练立即发散,正如我们所见。我们可能也不想以高学习率结束训练,这样我们就不会跳过一个最小值。但我们希望在训练期间保持高学习率,因为这样我们可以更快地训练。因此,我们应该在训练过程中改变学习率,从低到高,然后再次降低到低。
莱斯利·史密斯(是的,就是发明学习率查找器的那个人!)在他的文章“超收敛:使用大学习率非常快速地训练神经网络”中发展了这个想法。他设计了一个学习率时间表,分为两个阶段:一个阶段学习率从最小值增长到最大值(预热),另一个阶段学习率再次降低到最小值(退火)。史密斯称这种方法的组合为1cycle 训练。
1cycle 训练允许我们使用比其他类型训练更高的最大学习率,这带来了两个好处:
-
通过使用更高的学习率进行训练,我们可以更快地训练——这种现象史密斯称之为超收敛。
-
通过使用更高的学习率进行训练,我们过拟合较少,因为我们跳过了尖锐的局部最小值,最终进入了更平滑(因此更具有泛化能力)的损失部分。
第二点是一个有趣而微妙的观察;它基于这样一个观察:一个泛化良好的模型,如果你稍微改变输入,它的损失不会发生很大变化。如果一个模型在较大的学习率下训练了相当长的时间,并且在这样做时能找到一个好的损失,那么它一定找到了一个泛化良好的区域,因为它在批次之间跳动很多(这基本上就是高学习率的定义)。问题在于,正如我们所讨论的,直接跳到高学习率更有可能导致损失发散,而不是看到损失改善。因此,我们不会直接跳到高学习率。相反,我们从低学习率开始,我们的损失不会发散,然后允许优化器逐渐找到参数的更平滑的区域,逐渐提高学习率。
然后,一旦我们找到了参数的一个良好平滑区域,我们希望找到该区域的最佳部分,这意味着我们必须再次降低学习率。这就是为什么 1cycle 训练有一个渐进的学习率预热和渐进的学习率冷却。许多研究人员发现,实践中这种方法导致更准确的模型和更快的训练。这就是为什么在 fastai 中fine_tune默认使用这种方法。
在第十六章中,我们将学习有关 SGD 中的动量。简而言之,动量是一种技术,优化器不仅朝着梯度的方向迈出一步,而且继续朝着以前的步骤的方向前进。 Leslie Smith 在“神经网络超参数的纪律方法:第 1 部分”中介绍了循环动量的概念。它建议动量与学习率的方向相反变化:当我们处于高学习率时,我们使用较少的动量,在退火阶段再次使用更多动量。
我们可以通过调用fit_one_cycle在 fastai 中使用 1cycle 训练:
def fit(epochs=1, lr=0.06):
learn = Learner(dls, simple_cnn(), loss_func=F.cross_entropy,
metrics=accuracy, cbs=ActivationStats(with_hist=True))
learn.fit_one_cycle(epochs, lr)
return learn
learn = fit()
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.210838 | 0.084827 | 0.974300 | 00:08 |
我们终于取得了一些进展!现在它给我们一个合理的准确率。
我们可以通过在learn.recorder上调用plot_sched来查看训练过程中的学习率和动量。learn.recorder(顾名思义)记录了训练过程中发生的一切,包括损失、指标和超参数,如学习率和动量:
learn.recorder.plot_sched()

Smith 的原始 1cycle 论文使用了线性热身和线性退火。正如您所看到的,我们通过将其与另一种流行方法——余弦退火相结合,在 fastai 中改进了这种方法。fit_one_cycle提供了以下您可以调整的参数:
lr_max
将使用的最高学习率(这也可以是每个层组的学习率列表,或包含第一个和最后一个层组学习率的 Python slice对象)
div
将lr_max除以多少以获得起始学习率
div_final
将lr_max除以多少以获得结束学习率
pct_start
用于热身的批次百分比
moms
一个元组(*mom1*,*mom2*,*mom3*),其中mom1是初始动量,mom2是最小动量,mom3是最终动量
让我们再次查看我们的层统计数据:
learn.activation_stats.plot_layer_stats(-2)

非零权重的百分比正在得到很大的改善,尽管仍然相当高。通过使用color_dim并传递一个层索引,我们可以更多地了解我们的训练情况:
learn.activation_stats.color_dim(-2)

color_dim是由 fast.ai 与学生 Stefano Giomo 共同开发的。Giomo 将这个想法称为丰富多彩维度,并提供了一个深入解释这种方法背后的历史和细节。基本思想是创建一个层的激活直方图,我们希望它会遵循一个平滑的模式,如正态分布(图 13-14)。
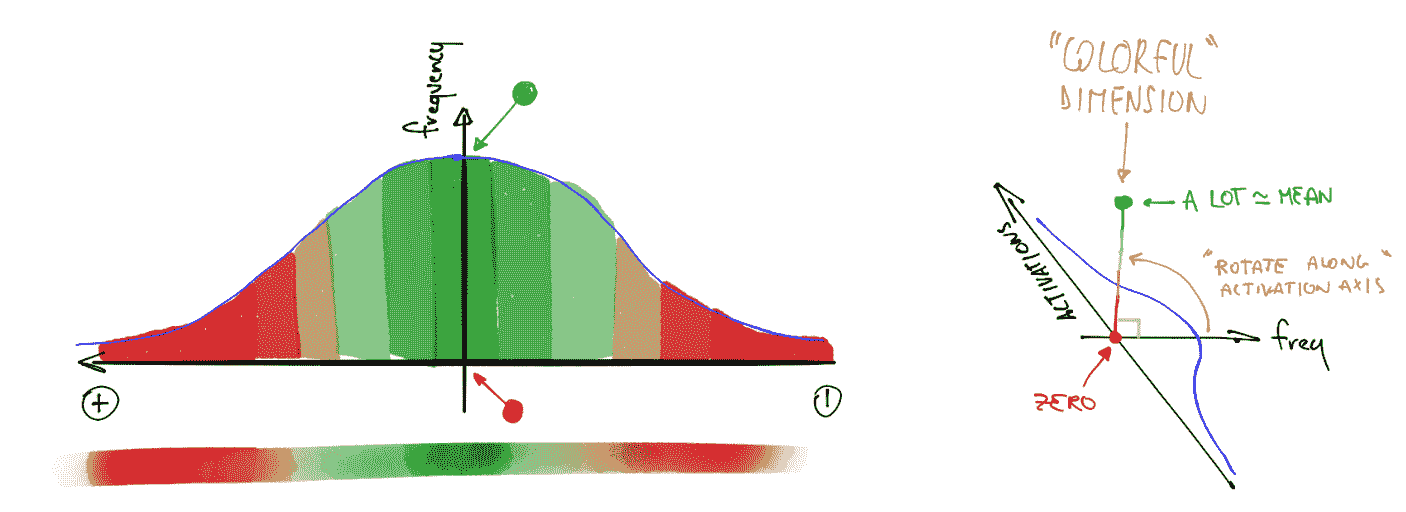
图 13-14。丰富多彩维度的直方图(由 Stefano Giomo 提供)
为了创建color_dim,我们将左侧显示的直方图转换为底部显示的彩色表示。然后,我们将其翻转,如右侧所示。我们发现,如果我们取直方图值的对数,分布会更清晰。然后,Giomo 描述:
每个层的最终图是通过将每批次的激活直方图沿水平轴堆叠而成的。因此,可视化中的每个垂直切片代表单个批次的激活直方图。颜色强度对应直方图的高度;换句话说,每个直方图柱中的激活数量。
图 13-15 展示了这一切是如何结合在一起的。
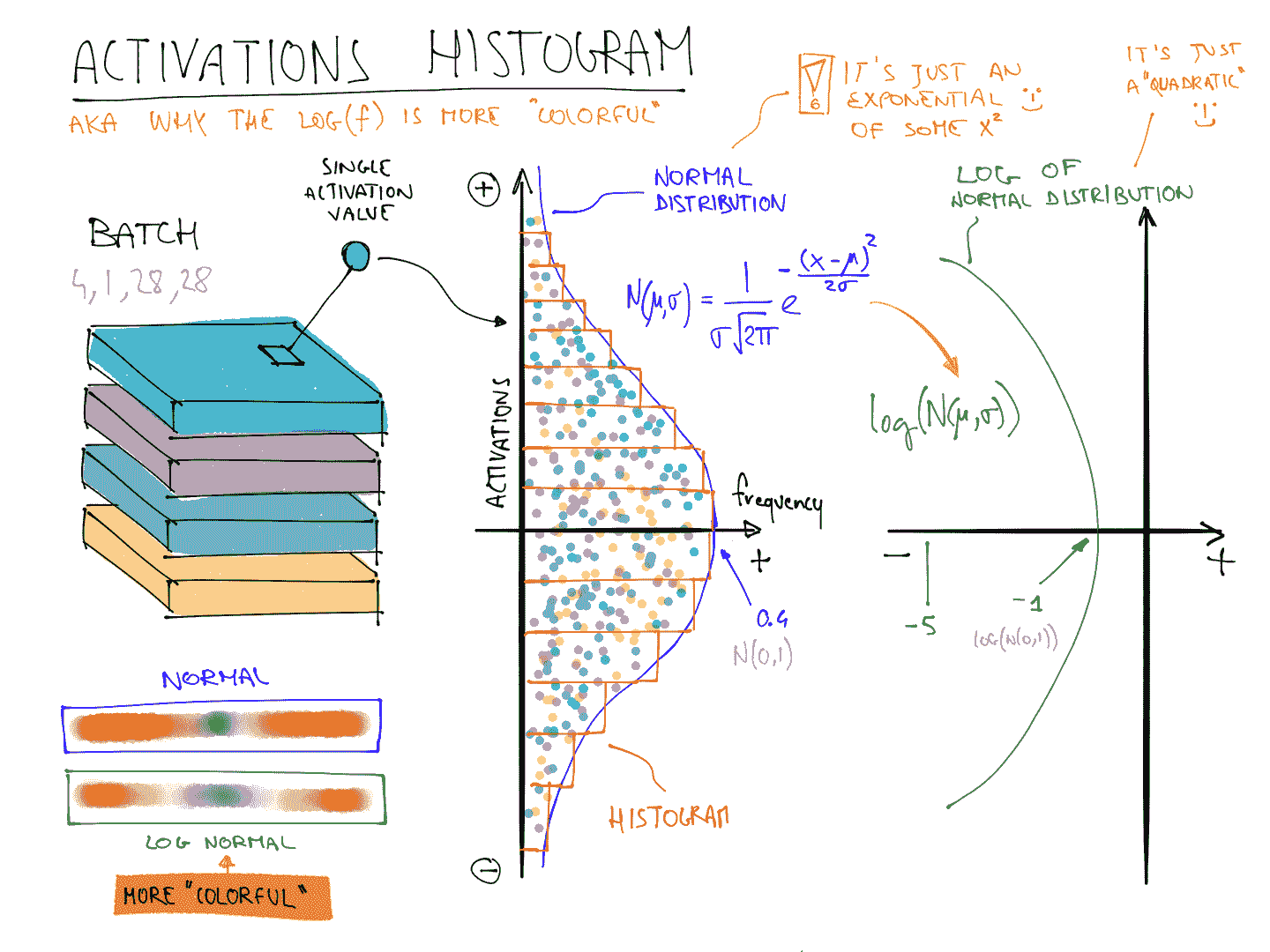
图 13-15。丰富多彩维度的总结(由 Stefano Giomo 提供)
这说明了为什么当f遵循正态分布时,log(f)比f更丰富多彩,因为取对数会将高斯曲线变成二次曲线,这样不会那么狭窄。
因此,让我们再次看看倒数第二层的结果:
learn.activation_stats.color_dim(-2)

这展示了一个经典的“糟糕训练”图片。我们从几乎所有激活都为零开始——这是我们在最左边看到的,所有的深蓝色。底部的明黄色代表接近零的激活。然后,在最初的几批中,我们看到非零激活数量呈指数增长。但它走得太远并崩溃了!我们看到深蓝色回来了,底部再次变成明黄色。它几乎看起来像是训练重新从头开始。然后我们看到激活再次增加并再次崩溃。重复几次后,最终我们看到激活在整个范围内分布。
如果训练一开始就能平稳进行会更好。指数增长然后崩溃的周期往往会导致大量接近零的激活,从而导致训练缓慢且最终结果不佳。解决这个问题的一种方法是使用批量归一化。
批量归一化
为了解决前一节中出现的训练缓慢和最终结果不佳的问题,我们需要解决初始大比例接近零的激活,并尝试在整个训练过程中保持良好的激活分布。
Sergey Ioffe 和 Christian Szegedy 在 2015 年的论文“Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”中提出了这个问题的解决方案。在摘要中,他们描述了我们所见过的问题:
训练深度神经网络的复杂性在于每一层输入的分布在训练过程中会发生变化,因为前一层的参数发生变化。这需要降低学习率和谨慎的参数初始化,从而减慢训练速度...我们将这种现象称为内部协变量转移,并通过对层输入进行归一化来解决这个问题。
他们说他们的解决方案如下:
将归一化作为模型架构的一部分,并对每个训练小批量进行归一化。批量归一化使我们能够使用更高的学习率,并且对初始化要求不那么严格。
这篇论文一经发布就引起了极大的兴奋,因为它包含了图 13-16 中的图表,清楚地表明批量归一化可以训练出比当前最先进技术(Inception架构)更准确且速度快约 5 倍的模型。
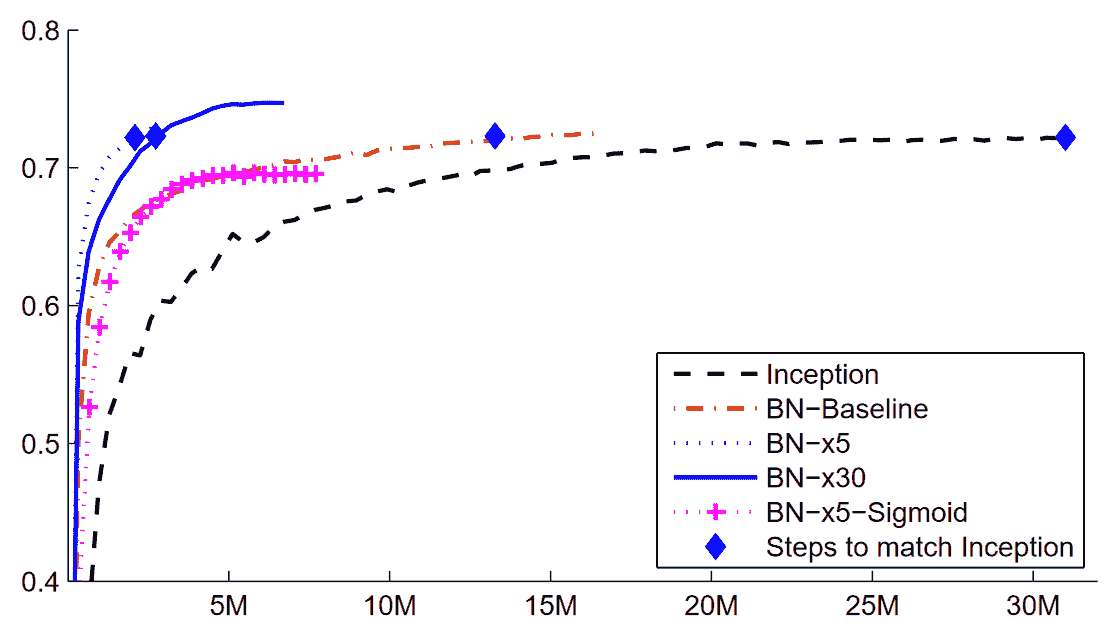
图 13-16. 批量归一化的影响(由 Sergey Ioffe 和 Christian Szegedy 提供)
批量归一化(通常称为batchnorm)通过取层激活的均值和标准差的平均值来归一化激活。然而,这可能会导致问题,因为网络可能希望某些激活非常高才能进行准确的预测。因此,他们还添加了两个可学习参数(意味着它们将在 SGD 步骤中更新),通常称为gamma和beta。在将激活归一化以获得一些新的激活向量y之后,批量归一化层返回gamma*y + beta。
这就是为什么我们的激活可以具有任何均值或方差,独立于前一层结果的均值和标准差。这些统计数据是分开学习的,使得我们的模型训练更容易。在训练和验证期间的行为是不同的:在训练期间,我们使用批次的均值和标准差来归一化数据,而在验证期间,我们使用训练期间计算的统计数据的运行均值。
让我们在conv中添加一个批量归一化层:
def conv(ni, nf, ks=3, act=True):
layers = [nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)]
layers.append(nn.BatchNorm2d(nf))
if act: layers.append(nn.ReLU())
return nn.Sequential(*layers)
并适应我们的模型:
learn = fit()
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.130036 | 0.055021 | 0.986400 | 00:10 |
这是一个很好的结果!让我们看看color_dim:
learn.activation_stats.color_dim(-4)

这正是我们希望看到的:激活的平稳发展,没有“崩溃”。Batchnorm 在这里真的兑现了承诺!事实上,批量归一化非常成功,我们几乎可以在所有现代神经网络中看到它(或类似的东西)。
关于包含批归一化层的模型的一个有趣观察是,它们往往比不包含批归一化层的模型更好地泛化。尽管我们尚未看到对这里发生的事情进行严格分析,但大多数研究人员认为原因是批归一化为训练过程添加了一些额外的随机性。每个小批次的均值和标准差都会与其他小批次有所不同。因此,激活每次都会被不同的值归一化。为了使模型能够做出准确的预测,它必须学会对这些变化变得稳健。通常,向训练过程添加额外的随机性通常有所帮助。
由于事情进展顺利,让我们再训练几个周期,看看情况如何。实际上,让我们增加学习率,因为批归一化论文的摘要声称我们应该能够“以更高的学习率训练”:
learn = fit(5, lr=0.1)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.191731 | 0.121738 | 0.960900 | 00:11 |
| 1 | 0.083739 | 0.055808 | 0.981800 | 00:10 |
| 2 | 0.053161 | 0.044485 | 0.987100 | 00:10 |
| 3 | 0.034433 | 0.030233 | 0.990200 | 00:10 |
| 4 | 0.017646 | 0.025407 | 0.991200 | 00:10 |
learn = fit(5, lr=0.1)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.183244 | 0.084025 | 0.975800 | 00:13 |
| 1 | 0.080774 | 0.067060 | 0.978800 | 00:12 |
| 2 | 0.050215 | 0.062595 | 0.981300 | 00:12 |
| 3 | 0.030020 | 0.030315 | 0.990700 | 00:12 |
| 4 | 0.015131 | 0.025148 | 0.992100 | 00:12 |
在这一点上,我认为我们知道如何识别数字了!是时候转向更难的东西了…
结论
我们已经看到,卷积只是一种矩阵乘法,对权重矩阵有两个约束:一些元素始终为零,一些元素被绑定(强制始终具有相同的值)。在第一章中,我们看到了 1986 年书籍并行分布式处理中的八个要求;其中之一是“单元之间的连接模式”。这正是这些约束所做的:它们强制执行一定的连接模式。
这些约束允许我们在不牺牲表示复杂视觉特征的能力的情况下,在模型中使用更少的参数。这意味着我们可以更快地训练更深的模型,减少过拟合。尽管普遍逼近定理表明在一个隐藏层中应该可能用全连接网络表示任何东西,但我们现在看到,通过深思熟虑网络架构,我们可以训练出更好的模型。
卷积是我们在神经网络中看到的最常见的连接模式(连同常规线性层,我们称之为全连接),但很可能会发现更多。
我们还看到了如何解释网络中各层的激活,以查看训练是否顺利,以及批归一化如何帮助规范训练并使其更加平滑。在下一章中,我们将使用这两个层来构建计算机视觉中最流行的架构:残差网络。
问卷
-
特征是什么?
-
为顶部边缘检测器编写卷积核矩阵。
-
写出 3×3 卷积核对图像中单个像素应用的数学运算。
-
应用于 3×3 零矩阵的卷积核的值是多少?
-
填充是什么?
-
步幅是什么?
-
创建一个嵌套列表推导来完成您选择的任何任务。
-
PyTorch 的 2D 卷积的
input和weight参数的形状是什么? -
通道是什么?
-
卷积和矩阵乘法之间的关系是什么?
-
卷积神经网络是什么?
-
重构神经网络定义的部分有什么好处?
-
什么是
Flatten?MNIST CNN 中需要包含在哪里?为什么? -
NCHW 是什么意思?
-
为什么 MNIST CNN 的第三层有
7*7*(1168-16)次乘法运算? -
什么是感受野?
-
经过两次步幅为 2 的卷积后,激活的感受野大小是多少?为什么?
-
自己运行conv-example.xlsx并尝试使用trace precedents进行实验。
-
看一下 Jeremy 或 Sylvain 最近的 Twitter“喜欢”列表,看看是否有任何有趣的资源或想法。
-
彩色图像如何表示为张量?
-
彩色输入下卷积是如何工作的?
-
我们可以使用什么方法来查看
DataLoaders中的数据? -
为什么我们在每次步幅为 2 的卷积后将滤波器数量加倍?
-
为什么在 MNIST 的第一个卷积中使用较大的内核(使用
simple_cnn)? -
ActivationStats为每个层保存了什么信息? -
在训练后如何访问学习者的回调?
-
plot_layer_stats绘制了哪三个统计数据?x 轴代表什么? -
为什么接近零的激活是有问题的?
-
使用更大的批量大小进行训练的优缺点是什么?
-
为什么我们应该避免在训练开始时使用高学习率?
-
什么是 1cycle 训练?
-
使用高学习率进行训练的好处是什么?
-
为什么我们希望在训练结束时使用较低的学习率?
-
什么是循环动量?
-
哪个回调在训练期间跟踪超参数值(以及其他信息)?
-
color_dim图中的一列像素代表什么? -
在
color_dim中,“坏训练”是什么样子?为什么? -
批规范化层包含哪些可训练参数?
-
在训练期间批规范化使用哪些统计数据进行规范化?验证期间呢?
-
为什么具有批规范化层的模型泛化能力更好?
进一步研究
-
除了边缘检测器,计算机视觉中还使用了哪些特征(尤其是在深度学习变得流行之前)?
-
PyTorch 中还有其他规范化层。尝试它们,看看哪种效果最好。了解其他规范化层的开发原因以及它们与批规范化的区别。
-
尝试将激活函数移动到
conv中的批规范化层后。这会有所不同吗?看看你能找到关于推荐顺序及原因的信息。