
这意味着运行Spark就需要新建一个笔记本。

加载数据
下一步是上传用于学习Spark的一些数据。只需点击主页选项卡上的“导入并查看数据”。
本文末尾会使用多个数据集来说明,但现在先从一些非常简单的东西开始。
添加shakespeare.txt文件,下载传送门:https://github.com/MLWhiz/spark_post
可以看到文件加载到/FileStore/tables/shakespeare.txt这个位置了。
第一个Spark程序
本文倾向通过示例学习,所以让我们完成分布式计算的“Hello World”: WordCount 程序。
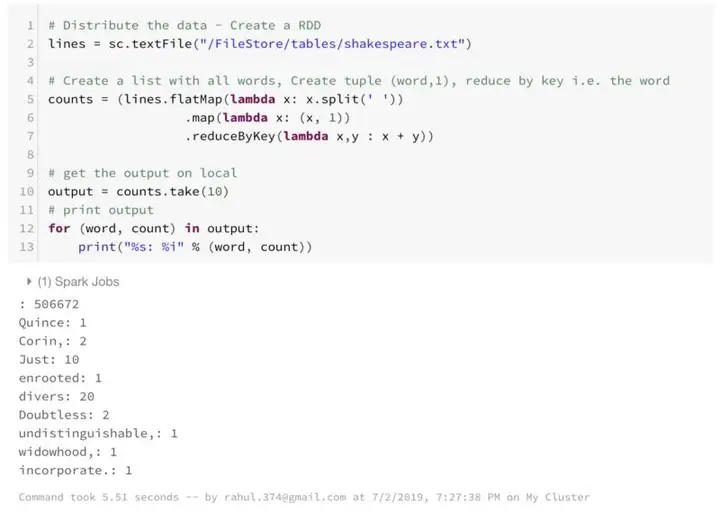
这是一个小例子,其统计了文档字数并输出了其中的10。
大多数工作是在第二指令中完成的。
如果目前还是跟不上,也别担心,你的任务就是运行Spark。
但是在讨论Spark的基础知识之前,先了解一下Python基础知识。如果使用过Python的函数式编程,那么理解Spark将变得容易得多。
对于没有使用过Python的人,以下是一个简短介绍。
Python中编程的函数方法

1. 映射
map用于将函数映射到数组或列表中。如果想应用某函数到列表中的各元素中,只需通过使用for循环来实现,但是python lambda函数可允许在python的单行中实现这一点。
my_list = [1,2,3,4,5,6,7,8,9,10]
# Lets say I want to square each term in my_list.
squared_list = map(lambda x:x**2,my_list)
print(list(squared_list))
------------------------------------------------------------
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
在上面的例子中,可将map看作一个函数,该函数输入两个参数—一个函数和一个列表。
然后,其将该函数应用于列表中各元素,而lambda则可供编写内联函数使用。在这里lambda x:x**2定义了一个函数,将x输入,返回x²。
也可以用另外一个合适的函数来代替lambda。例如:
def squared(x):
return x**2
my_list = [1,2,3,4,5,6,7,8,9,10]
# Lets say I want to square each term in my_list.
squared_list = map(squared,my_list)
print(list(squared_list))
------------------------------------------------------------
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
同样的结果,但是lambda表达式使代码更紧凑,可读性更强。
2. 筛选
另一个广泛使用的函数是filter函数。此函数输入两个参数—一个条件和一个筛选列表。
如果想使用条件筛选列表,请使用filter函数。
my_list = [1,2,3,4,5,6,7,8,9,10]
# Lets say I want only the even numbers in my list.
filtered_list = filter(lambda x:x%2==0,my_list)
print(list(filtered_list))
---------------------------------------------------------------
[2, 4, 6, 8, 10]
3. 约归
下面介绍的函数是reduce函数。这个函数将是Spark中的主力部分。
这个函数输入两个参数——一个归约函数,该函数输入两个参数,以及一个应用约归函数的列表。
import functools
my_list = [1,2,3,4,5]
# Lets say I want to sum all elements in my list.
sum_list = functools.reduce(lambda x,y:x+y,my_list)
print(sum_list)
在python2中,约归曾经是Python的一部分,现在我们必须使用reduce,使其作为函数工具的一部分。
在这里,lambda函数输入两个值x和y,返回它们的和。直观地,可以认为约归函数的工作原理如下:
Reduce function first sends 1,2 ; the lambda function returns 3
Reduce function then sends 3,3 ; the lambda function returns 6
Reduce function then sends 6,4 ; the lambda function returns 10
Reduce function finally sends 10,5 ; the lambda function returns 15
在约归中使用的lambda函数的一个条件是它必须是:
· 交换律 a + b = b + a 和
· 结合律 (a + b) + c == a + (b + c).
在上面的例子中,使用了交换律和结合律。另外还可以使用的其他函数:max, min, *等等。
再次回到Spark
既然已经掌握了Python函数式编程的基本知识,现在开始了解Spark。
首先深入研究一下spark是如何工作的。Spark实际上由驱动和工作单元两部分组成。
工作单元通常执行这些需要完成的任务,而驱动则是发布任务指令的。
弹性分布式数据集
RDD(弹性分布式数据集)是一种并行的数据结构,分布在工作单元节点之间。RDD是Spark编程的基本单元。
在wordcount示例中,其第一行
lines = sc.textFile("/FileStore/tables/shakespeare.txt")
获取一个文本文件,将其分布到工作单元节点上,这样RDD就可以并行地处理此文件。还可以使用sc.parallelize函数并行计算列表。
例如:
data = [1,2,3,4,5,6,7,8,9,10]
new_rdd = sc.parallelize(data,4)
new_rdd
---------------------------------------------------------------
ParallelCollectionRDD[22] at parallelize at PythonRDD.scala:267
在Spark中,可以对RDD执行两种不同类型的操作:转换和操作。
1. 转换:从现有的RDD中创建新的数据集
2. 操作:从Spark中获取结果的机制
转换基础

假设已经以RDD的形式获取了数据。
目前可以通过访问工作机器来重报数据。现在想对数据进行一些转换。
比如你可能想要筛选、应用某个功能等等。
在Spark中,这可以由Transformation函数完成。
Spark提供了很多转换函数。
标签:总结,10,函数,list,今日,Spark,my,lambda From: https://www.cnblogs.com/zhaoyueheng/p/18010453