基于BiLSTM-CRF模型的分词、词性标注、信息抽取任务的详解,侧重模型推导细化以及LAC分词实践
1.GRU简介
GRU(Gate Recurrent Unit)门控循环单元,是[循环神经网络](RNN)的变种种,与 LSTM 类似通过门控单元解决 RNN 中不能长期记忆和反向传播中的梯度等问题。与 LSTM 相比,GRU 内部的网络架构较为简单。
- GRU 内部结构
RU 网络内部包含两个门使用了更新门(update gate)与重置门(reset gate)。重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 [RNN]模型。这两个门控向量决定了哪些信息最终能作为门控循环单元的输出。这两个门控机制的特殊之处在于,它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。 GRU 门控结构如下图所示:
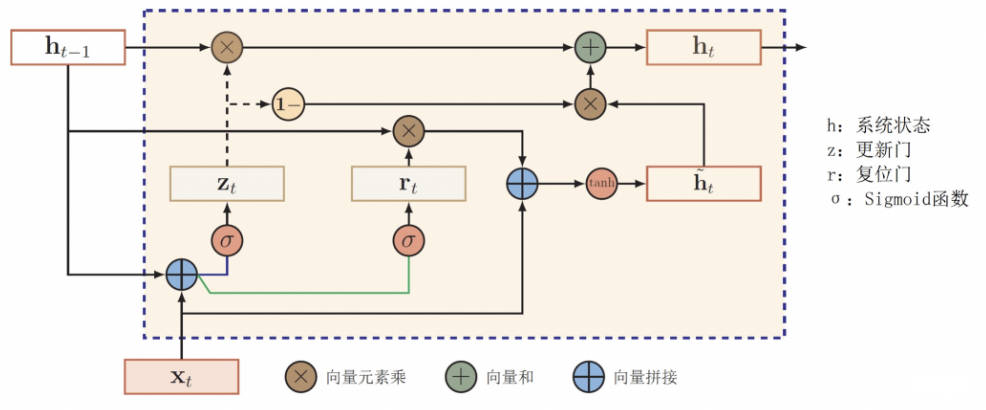
- 更新门
更新门帮助模型决定到底要将多少过去的信息传递到未来,或到底前一时间步和当前时间步的信息有多少是需要继续传递的。
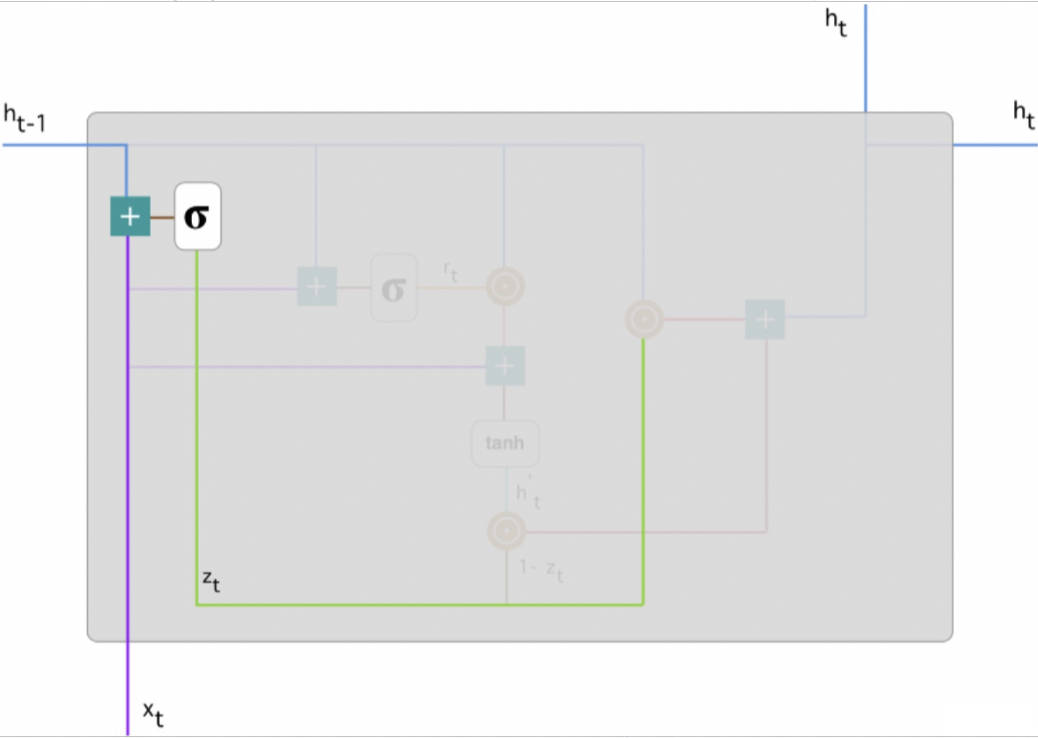
其中 Xt 为第 t 个时间步的输入向量,即输入序列 X 的第 t 个分量,它会经过一个线性变换(与权重矩阵 W(z) 相乘)。h(t-1) 保存的是前一个时间步 t-1 的信息,它同样也会经过一个线性变换。更新门将这两部分信息相加并投入到 Sigmoid 激活函数中,因此将激活结果压缩到 0 到 1 之间。以下是更新门的计算公式:
$$z_t=\sigma\left(W^{(z)} x_t+U^{(z)} h_{t-1}\right)$$
- 重置门
重置门主要决定了到底有多少过去的信息需要遗忘。
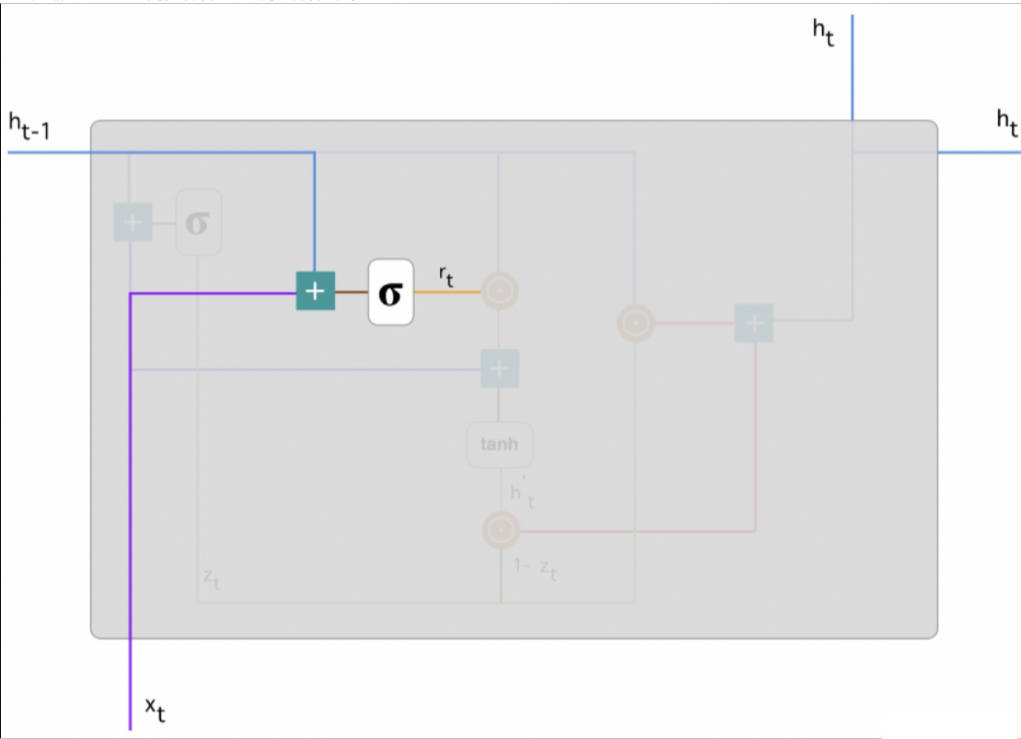
h(t-1) 和 xt 先经过一个线性变换,再相加投入 Sigmoid 激活函数以输出激活值。
$$r_t=\sigma\left(W^{(r)} x_t+U^{(r)} h_{t-1}\right)$$
- 当前记忆内容
在重置门的使用中,新的记忆内容将使用重置门储存过去相关的信息。
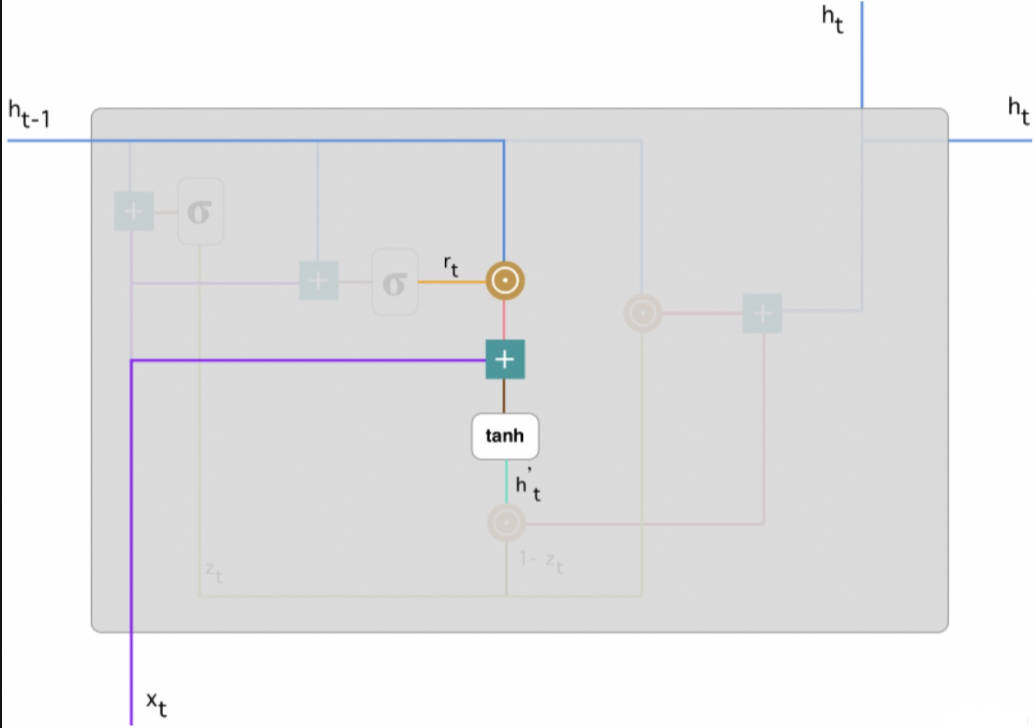
计算重置门 rt 与 Uh(t-1) 的 Hadamard 乘积,即 rt 与 Uh(t-1) 的对应元素乘积。因为前面计算的重置门是一个由 0 到 1 组成的向量,它会衡量门控开启的大小。例如某个元素对应的门控值为 0,那么它就代表这个元素的信息完全被遗忘掉。该 Hadamard 乘积将确定所要保留与遗忘的以前信息。
$$h_t^{\prime}=\tanh \left(W x_t+r_t \odot U h_{t-1}\right)$$
- 当前时间步的最终记忆
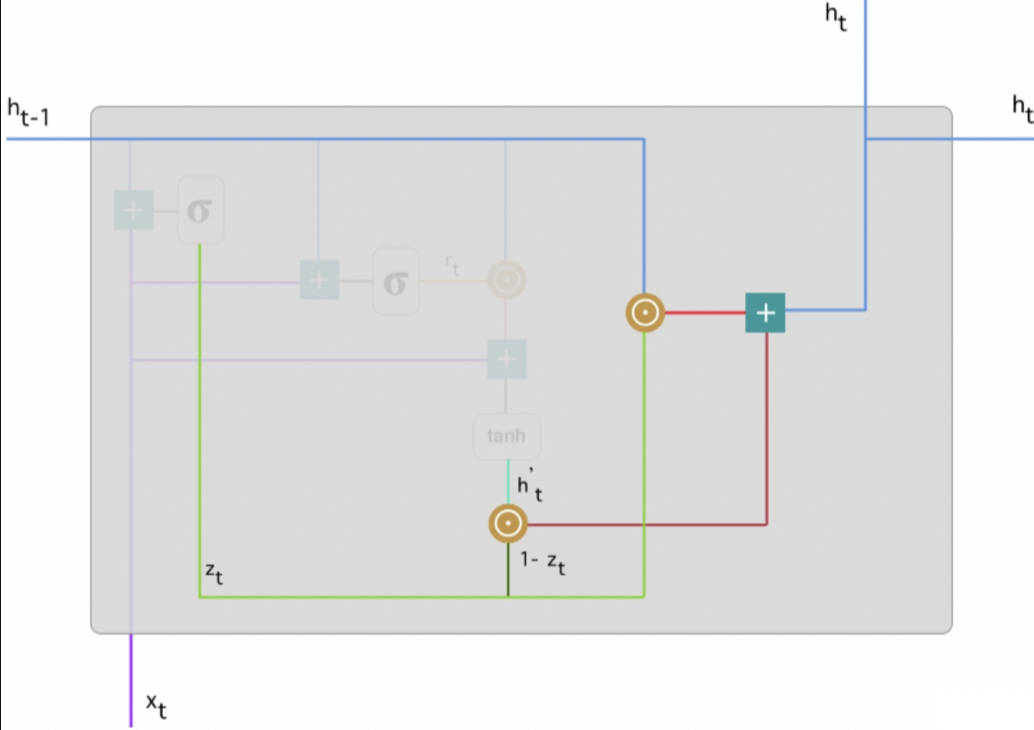
最终记忆的计算过程中,需要使用更新门,它决定了当前记忆内容 ht' 和前一时间步 h(t-1) 中需要收集的信息。这一过程可以表示为zt 为更新门的激活结果,它同样以门控的形式控制了信息的流入。zt 与 h(t-1) 的 Hadamard乘积表示前一时间步保留到最终记忆的信息,该信息加上当前记忆保留至最终记忆的信息就等于最终门控循环单元输出的内容。
$$h_t=z_t \odot h_{t-1}+\left(1-z_t\right) \odot h_t^{\prime}$$
门控循环单元不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元,因此它利用全部信息而避免了梯度消失问题。
1.1 基于双向BiLstm神经网络的中文分词讲解
双向LSTM(长短时记忆网络),双向LSTM是LSTM的改进版,LSTM是RNN的改进版。因此,首先需要理解RNN。
RNN的意思是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。
STM对RNN做了改进,使得能够捕捉更长距离的信息。但是不管是LSTM还是RNN,都有一个问题,它是从左往右推进的,因此后面的词会比前面的词更重要,但是对于分词这个任务来说是不妥的,因为句子各个字应该是平权的。因此出现了双向LSTM,它从左到右做一次LSTM,然后从右到左做一次LSTM,然后把两次结果组合起来。
在分词中,LSTM可以根据输入序列输出一个序列,这个序列考虑了上下文的联系,因此,可以给每个输出序列接一个softmax分类器,来预测每个标签的概率。基于这个序列到序列的思路,我们就可以直接预测句子的标签。假设每次输入$y_1-y_n$由下图所示每个输入所对应的标签为$x_1-x_n$。再抽象一点用$ x_{ij}$ 表示状态$x_i$的第j个可能值。
2. 基于字的 BiLSTM-CRF 模型
2.1 BiLSTM详解
使用基于字的 BiLSTM-CRF,主要参考的是文献 [4][5]。使用 Bakeoff-3 评测中所采用的的 BIO 标注集,即 B-PER、I-PER 代表人名首字、人名非首字,B-LOC、I-LOC 代表地名首字、地名非首字,B-ORG、I-ORG 代表组织机构名首字、组织机构名非首字,O 代表该字不属于命名实体的一部分。如:

这里当然也可以采用更复杂的 BIOSE 标注集。
以句子为单位,将一个含有 $n$个字的句子(字的序列)记作 $x=(x_{1},x_{2},...,x_{n})$,
其中 $x_{i}$表示句子的第 $i$个字在字典中的 id,进而可以得到每个字的 one-hot 向量,维数是字典大小。
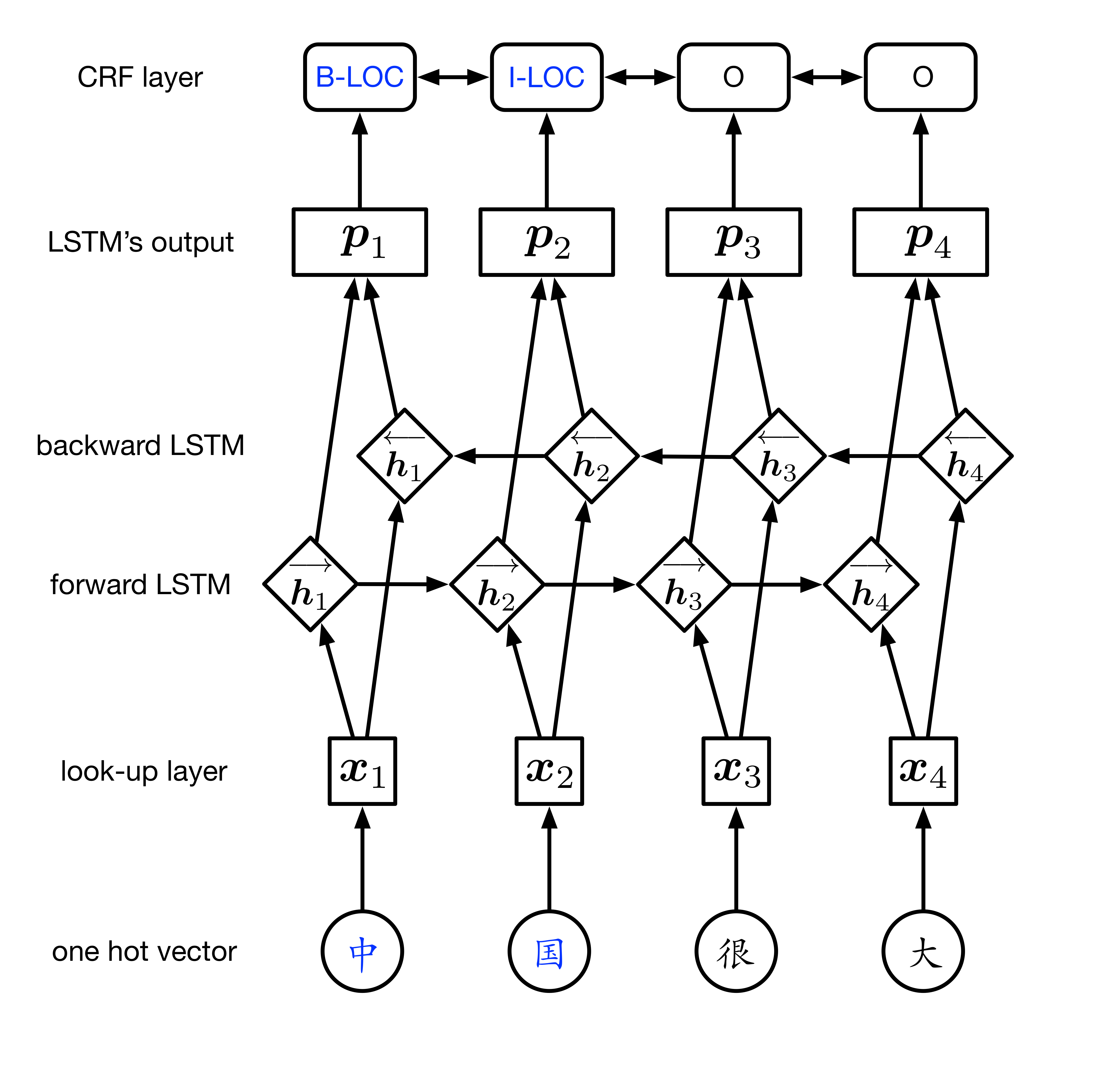
模型的第一层是 look-up 层,利用预训练或随机初始化的 embedding 矩阵将句子 $x_{i}$中的每个字由 one-hot 向量映射为低维稠密的字向量(character embedding) $x_{i}\epsilon \mathbb{R}^{d}$,$d$ 是 embedding 的维度。在输入下一层之前,设置 dropout 以缓解过拟合。
模型的第二层是双向 LSTM 层,自动提取句子特征。将一个句子的各个字的 char embedding 序列 $(x_{1},x_{2},...,x_{n})$作为双向 LSTM 各个时间步的输入,再将正向 LSTM 输出的隐状态序列 $\left ( \underset{h_{1}}{\rightarrow},\underset{h_{2}}{\rightarrow},...,\underset{h_{n}}{\rightarrow} \right )$与反向 LSTM 的 $\left ( \underset{h_{1}}{\leftarrow},\underset{h_{2}}{\leftarrow},...,\underset{h_{n}}{\leftarrow} \right )$ 在各个位置输出的隐状态进行按位置拼接 $ht = \left [ \underset{h_{t}}{\rightarrow};\underset{h_{t}}{\leftarrow} \right ]\epsilon \mathbb{R}^m$,得到完整的隐状态序列
$$({\boldsymbol h_1},{\boldsymbol h_2},...,{\boldsymbol h_n})\in\mathbb R^{n\times m}$$
在设置 dropout 后,接入一个线性层,将隐状态向量从 $m$ 维映射到 $k$维,$k$ 是标注集的标签数,从而得到自动提取的句子特征,记作矩阵 $P=({\boldsymbol p_1},{\boldsymbol p_2},...,{\boldsymbol p_n})\in\mathbb R^{n\times k}$。可以把 $\boldsymbol p_i\in\mathbb R^{k}$的每一维 $p_{ij}$都视作将字 $x_{i}$分类到第 $j$ 个标签的打分值,如果再对 $p$进行 Softmax 的话,就相当于对各个位置独立进行 $k$类分类。但是这样对各个位置进行标注时无法利用已经标注过的信息,所以接下来将接入一个 CRF 层来进行标注。
模型的第三层是 CRF 层,进行句子级的序列标注。CRF 层的参数是一个 $\mathbf{}$$\mathbf{(k+2) \times (k+2)}$的矩阵 A ,$A_{ij}$表示的是从第 $i$个标签到第 $j$个标签的转移得分,进而在为一个位置进行标注的时候可以利用此前已经标注过的标签,之所以要加 2 是因为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态。如果记一个长度等于句子长度的标签序列 $y=(y_1,y_2,...,y_n)$,那么模型对于句子 $x$的标签等于 $y$的打分为
$$\mathbf{score(x,y)=\sum_{i=1}{n}P_{i,y_{i}}+\sum_{i=1}A_{y_{i-1},y_{i}}}$$
可以看出整个序列的打分等于各个位置的打分之和,而每个位置的打分由两部分得到,一部分是由 LSTM 输出的 $\boldsymbol p_i$决定,另一部分则由 CRF 的转移矩阵 $A$决定。进而可以利用 Softmax 得到归一化后的概率:
$$\mathbf{P(y|x)=\frac{\exp(score(x,y))}{\sum_{y'}\exp(score(x,y'))}}$$
模型训练时通过最大化对数似然函数,下式给出了对一个训练样本 $(x,y^{x})$ 的对数似然:
$$\log P(y{x}|x)=score(x,y)-\log(\sum_{y'}\exp(score(x,y')))$$
如果这个算法要自己实现的话,需要注意的是指数的和的对数要转换成 $\log\sum_i\exp(x_i) = a + \log\sum_i\exp(x_i - a)$, 在 CRF 中上式的第二项使用前向后向算法来高效计算。
模型在预测过程(解码)时使用动态规划的 Viterbi 算法来求解最优路径:$y^{*}=\arg\max_{y'}score(x,y')$
2.1 CRF 层详解
我们重点关注一下 CRF 层:
回顾一下整个模型,我们将 embedding 的字(或词或字和词的拼接)。(anyway,这些 embeddings 在训练的时候都会 fine-tuned 的),数据经过模型处理,得到所有词的 labels。
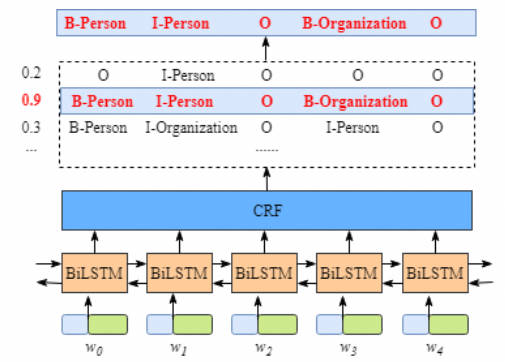
其中,数据在经过 biLSTM 后的形式如下图所示:
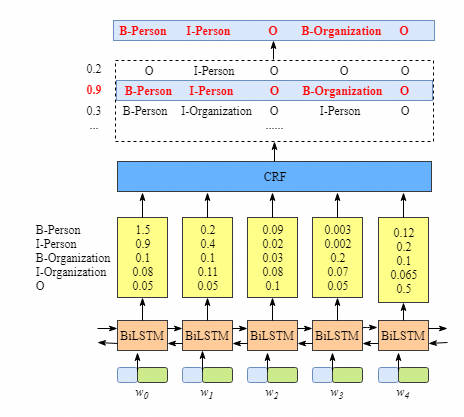
比如 $W_0$,BiLSTM 对应的输出是 1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O). 接着输入 CRF layer, .CRF layer 将选出最大分值的 labels 序列作为输出结果。
表面上,经过 BILSTM, 我们已经获得了各个词在不同 label 上的得分。比如 $w_{0}$对应 “B-Person”, 得分 (1.5), 我们仅需要选择每个词对应的最高得分的 label 最为输出就可以了,但这样得到的并非是好的结果。这也是为什么要接入 CRFlayer 的原因。
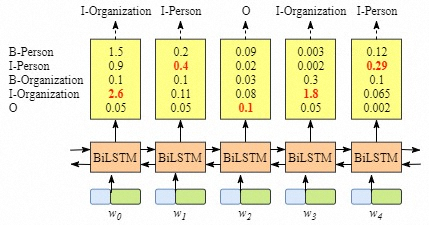
比如上图中,我们得到的结果: “I-Organization I-Person” 和 “B-Organization I-Person”. 显然是不合理的。
CRF 层可以为输出的预测标签添加一些约束以确保它们有效。 在训练过程中,CRF 层可以自动从训练数据集中学习这些约束。从而提升 labels 的准确性。
这些约束可能是:
- 句子中第一个单词的标签应以 “B-” 或“O”开头,而不是“I-”
- “B-label1 I-label2 I-label3 I- ...”,这样的输出中,label1,label2,label3 ...... 应该是相同的命名实体标签。 例如,“B-Person I-Person”是有效的,但 “B-Person I-Organization” 这样的预测无效。
- “O I-label”是无效的。 一个命名实体的第一个标签应以 “B-” 而非 “I-” 开头,有效的输出模式应为“O B-label”
- ...
CRF 层的 loss function 包含两个重要的 score,Emission score 和 Transition score。
Emission score
Emission score 通过 biLSTM 层的输出计算。
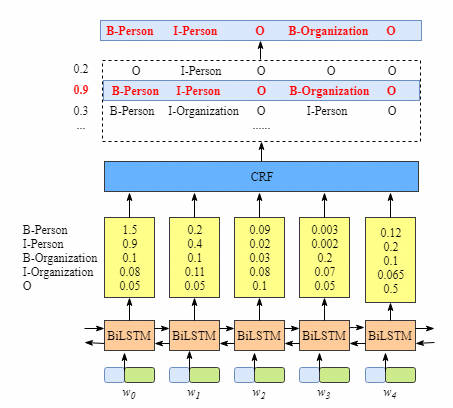
按照上图所示的输出逻辑,我们定义 label 对应的对应的 index 如下表:

定义 emission score 符号为 $\mathbf{x_{iy_j}}$ ,其中单词 $i$ 对应的输出 label 为 $y_j$ ,如上图所示,$x_{i=1,y_j=2} = x_{w_1,B-Organization} = 0.1$,表示 $w_1$的 emission score 为 0.1。
Transition score
定义 Transition score 符号为 $\mathbf{ t_{y_iy_j}}$, 表示 label 之间的转移关系,如上图所示,$t_{B-Person, I-Person} = 0.9$,表示 $B-Person \rightarrow I-Person$的 label transition 为 0.9. 我们建立 transition score matrix 来表示所有标签之间的转移关系。另外为了让 transition score matrix 是稳定的,我们额外加入 START 和 END 标签,他们分别表示句子的开始和结束。transition score matrix 示例如下表:
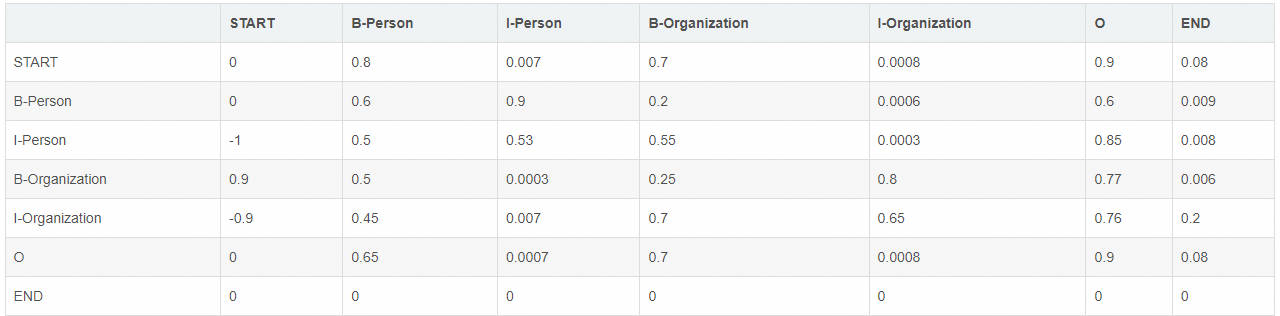
从上表可以看出:
- 句子中第一个单词的标签应以 “B-” 或“O”开头,而不是 “I-”(从“START” 到“I-Person 或 I-Organization”的转换分数非常低。)
- “B-label1 I-label2 I-label3 I- ...”,的输出标签序列中,label1,label2,label3 ...... 应该是相同的命名实体标签。 例如,“B-Person I-Person”有效,若是 “B-Person I-Organization” 则不合理。 (从 “B-Organization” 到“I-Person”的得分仅为 0.0003,远低于其他值。)
- “O I-label”也是无效的。 一个命名实体的第一个标签应该以 “B-” 而不是 “I-” 开头,换句话说,有效的输出模式应该是“O B-label”(我们可以看到 $t_{O,I-Person}$都非常小)
- ....
transition score matrix 不是人为给的,它本身是模型的参数,一开始他是随机值,在模型的训练过程中,完成 fine-tuning.
CRF loss function
定义最优的 label 序列为 real path,其得分 score 为 real path score ,其他可能的 label 序列为 possible paths。
损失函数由 real path score 和其他 possible paths score 来构建。real path score 表示最优的 label 序列得分。该分数应该是所有 path 中的最高分。
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
| START | 5 |
| END | 6 |
比如我们由 5 个 words 组成的 sentence,可能的路径:
-
- START B-Person B-Person B-Person B-Person B-Person END
-
- START B-Person I-Person B-Person B-Person B-Person END
- …
- 10) START B-Person I-Person O B-Organization O END
- …
- N) O O O O O O O
如果 $N$条 possible paths 分别有 score $p_{i}$, 那么所有 paths 的所有 score 为 $P_{total} = P_1 + P_2 +...+ P_N = e^{S_1} + e^{S_2} +... + e^{S_N}$。假设训练集得出第 10 条 path 是 real path,$P$_ 应该在 所有 score ($P_1,P_2,...,P_N$)中占比最大。
因此损失函数可以定义为:
$$\mathbf{Loss Function = \frac{P_{RealPath}}{P_1 + P_2 +... + P_N}}$$
也许您会问,$P_{total} = P_1 + P_2 +...+ P_N = e^{S_1} + e^{S_2} +... + e^{S_N}$ 中,$s_N$是什么?换句话说,我们的 score 怎么求?
Real path score
我们之前的公式中,定义了 $e^{s_i}$表示第 $i$个 path 的 score. 那么对于第 10 个 path(the real path)“START B-Person I-Person O B-Organization O END”,我们这样计算 $s_i$ :
原句子包含 7 个词:$w_0,w_1,w_2,w_3,w_4,w_5,w_6$。其中,$w_0,w_6$分别表示句子的开始标记 START 和结束标记 END。
$S_i = EmissionScore + TransitionScore$
其中,$EmissionScore=x_{0,START}+x_{1,B-Person}+x_{2,I-Person}+x_{3,O}+x_{4,B-Organization}+x_{5,O}+x_{6,END}$。正如之前介绍的,EmissionScore 是根据 bilstm layer 的输出来统计的。例如,在我们的示意图中,$x_{1,B-Person} = 0.2$。我们可以设定 $x_{0,START}$和 $x_{6,END}$为 0。
$$TransitionScore=t_{START\rightarrow B-Person} + t_{B-Person\rightarrow I-Person} + t_{I-Person\rightarrow O} + t_{0\rightarrow B-Organization} + t_{B-Organization\rightarrow O} + t_{O\rightarrow END}$$正如之前介绍的,$t_{START\rightarrow B-Person}$ 即表示从 label $START$ 到 $B-Person$ 的 TransitionScore, 他们的值在模型训练的时候得到。
The total score of all the paths
对于一个 NER 识别任务,BILSTM 层输出的 label 有很多种,假设每一个 $w_i$ 输出的 $\mathbf{x_{iy_j}}$ 对应 $L$ 个 $y_i$。那么可能的 path 有 $L^{(i)}$个,这么多的可能,如果考虑累加来求所有 possible paths 的 $P_{total}$ 显然是不太实际的。
我们将损失函数变为 log loss function:$$LogLossFunction = \log \frac{P_{RealPath}}{P_1 + P_2 + ... + P_N}$$
因为我们的 train 目标是最小化 loss,所以我们加一个负号(目标变为最大化该函数):$$Log Loss Function = - \log \frac{P_{RealPath}}{P_1 + P_2 + ...+ P_N}$$
$$= - \log \frac{e{S_{RealPath}}}{e + e^{S_2} + ... + e^{S_N}}$$
$$= - (\log(e^{S_{RealPath}}) - \log(e^{S_1} + e^{S_2} + ... + e^{S_N}))$$
$$= - (S_{RealPath} - \log(e^{S_1} + e^{S_2} + ... + e^{S_N}))$$
$$= - ( \sum_{i=1}^{N} x_{iy_i} + \sum_{i=1}^{N-1} t_{y_iy_{i+1}} - \log(e^{S_1} + e^{S_2} + ... + e^{S_N}))$$
上式中,前两项我们已经知道如何求得,我们要解决的是
$log(e^{S_1} + e^{S_2} + ... + e^{S_N})$
假设我们的训练数据是一个只有 3 个 word 的句子:$\mathbf{x} = [w_0, w_1, w_2]$,输出 2 个 label:$LabelSet = {l_1,l_2}$,Emission scores 对应如下表:

CRF Layer 中, Transition scores 对应如下表:

我们的计算过程应该是这样的,先计算到 $w_0$的所有 possible paths(也就是 $p_0$), 在此基础上计算 $w_0 \rightarrow w_1$的 possible paths,最后计算 $w_0 \rightarrow w_1\rightarrow w_2$ 的 possible paths。
设 previous 为上一步的结果 result,obs 为当前 word 对应的的信息。我们开始计算 $$log(e^{S_1} + e^{S_2} + ... + e^{S_N})$$
$w_0$
$$obs = [x_{01}, x_{02}] \ \ previous = None$$
$w_0$ 前面没有产生 result,故 previous 为 None,$w_0$ 对应的观测值有 $x_{01}, x_{02}$,我们看到,每一个此时没有 Transition scores,只有 EmissionScore,因此 $w_0$ 的所有 possible paths score:
$$TotalScore(w_0)=\log (e^{s_{START\rightarrow 1}} + e^{s_{START\rightarrow 2}})=\log (e^{x_{01}} + e^{x_{02}})$$
$$w_0 \rightarrow w_1$$
$$obs = [x_{11}, x_{12}]\previous=[\log(e{x_{01}}),\log(e{x_{02}})] = [x_{01}, x_{02}]$$
- 展开 previous:
$previous = \begin{pmatrix} x&x_{01}\ x_{02}&x_{02} \end{pmatrix}$_
- 展开 obs:
$obs = \begin{pmatrix} x&x_{12}\ x_{11}&x_{12} \end{pmatrix}$_
- 将前一步($w_0$)的 result 当前的 EmissionScore,TransitionScore 相加:
$$scores = \begin{pmatrix} x_{01}&x_{01}\ x_{02}&x_{02} \end{pmatrix} + \begin{pmatrix} x_{11}&x_{12}\ x_{11}&x_{12} \end{pmatrix} + \begin{pmatrix} t_{11}&t_{12}\ t_{21}&t_{22} \end{pmatrix}$$
$$= \begin{pmatrix} x_{01}+x_{11}+t_{11}&x_{01}+x_{12}+t_{12}\ x_{02}+x_{11}+t_{21}&x_{02}+x_{12}+t_{22} \end{pmatrix}$$
- 构建下一步的 previous:
$$previous=[\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}), \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})]$$
- 依照前计算 $w_0$的 totalScore,我们有:
$$TotalScore(w_0 \rightarrow w_1)=\log (e^{previous[0]} + e^{previous[1]})\=\log (e{\log(e+x_{11}+t_{11}} + e{x_{02}+x_{11}+t_{21}})}+e+x_{12}+t_{12}} + e{x_{02}+x_{12}+t_{22}})}\=\log(e+x_{11}+t_{11}}+e{x_{02}+x_{11}+t_{21}}+e+x_{12}+t_{12}}+e^{x_{02}+x_{12}+t_{22}})$$
我们可以看出上式中, S 与 path 的对应关系:
$$S_1 = x_{01}+x_{11}+t_{11} \ ($label_1\rightarrow label_1$)\ S_2 = x_{02}+x_{11}+t_{21} \ ($label_2\rightarrow label_1$)\ S_3 = x_{01}+x_{12}+t_{12} \ ($label_1\rightarrow label_2$)\ S_4 = x_{02}+x_{12}+t_{22} \ ($label_2\rightarrow label_2$)\$$
$$w_0 \rightarrow w_1\rightarrow w_2$$
$$obs = [x_{21}, x_{22}]\previous=[\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}), \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})]$$
- 展开 previous:
$$previous = \begin{pmatrix} \log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})&\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})\ \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})&\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) \end{pmatrix}$$
- 展开 obs:
$obs = \begin{pmatrix} x&x_{22}\ x_{21}&x_{22} \end{pmatrix}$_
- 将前一步的 result 当前的 EmissionScore,TransitionScore 相加:
$$scores = \begin{pmatrix} \log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})&\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}})\ \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}})&\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) \end{pmatrix} + \begin{pmatrix} x_{21}&x_{22}\ x_{21}&x_{22} \end{pmatrix} + \begin{pmatrix} t_{11}&t_{12}\ t_{21}&t_{22} \end{pmatrix}\= \begin{pmatrix} \log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{21} + t_{11} &\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{22} + t_{12}\ \log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{21} + t_{21} &\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{22} + t_{22} \end{pmatrix}$$
- 构建下一步的 previous:
$$previous =[\ log( e^{\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{21} + t_{11}} + e^{\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{21} + t_{21}}),\\log( e^{\log (e^{x_{01}+x_{11}+t_{11}} + e^{x_{02}+x_{11}+t_{21}}) + x_{22} + t_{12}} +e^{\log (e^{x_{01}+x_{12}+t_{12}} + e^{x_{02}+x_{12}+t_{22}}) + x_{22} + t_{22}})]\ \=[\log((e^{x_{01}+x_{11}+t_{11}} + e{x_{02}+x_{11}+t_{21}})e + t_{11}}+(e^{x_{01}+x_{12}+t_{12}} + e{x_{02}+x_{12}+t_{22}})e + t_{21}}),\\log(e^{x_{01}+x_{11}+t_{11}} + e{x_{02}+x_{11}+t_{21}})e + t_{12}}+(e^{x_{01}+x_{12}+t_{12}} + e{x_{02}+x_{12}+t_{22}})e + t_{22}})]$$
$$TotalScore(w_0 \rightarrow w_1 rightarrow w_2)= \ \log (e^{previous[0]} + e^{previous[1]})= \ \log (e{\log((e+x_{11}+t_{11}} + e{x_{02}+x_{11}+t_{21}})e + t_{11}}+(e^{x_{01}+x_{12}+t_{12}} + e{x_{02}+x_{12}+t_{22}})e + t_{21}})}+e{\log((e+x_{11}+t_{11}} + e{x_{02}+x_{11}+t_{21}})e + t_{12}}+(e^{x_{01}+x_{12}+t_{12}} + e{x_{02}+x_{12}+t_{22}})e + t_{22}})}) \=\log (e^{x_{01}+x_{11}+t_{11}+x_{21}+t_{11}}+ \e^{x_{02}+x_{11}+t_{21}+x_{21}+t_{11}}+ \e^{x_{01}+x_{12}+t_{12}+x_{21}+t_{21}}+ \e^{x_{02}+x_{12}+t_{22}+x_{21}+t_{21}}+ \e^{x_{01}+x_{11}+t_{11}+x_{22}+t_{12}}+ \e^{x_{02}+x_{11}+t_{21}+x_{22}+t_{12}}+ \e^{x_{01}+x_{12}+t_{12}+x_{22}+t_{22}}+ \e^{x_{02}+x_{12}+t_{22}+x_{22}+t_{22}})$$
class My_CRF():
def __init__():
#[Initialization]
'''
Randomly initialize transition scores
'''
def __call__(training_data_set):
#[Loss Function]
Total Cost = 0.0
#Compute CRF Loss
'''
for sentence in training_data_set:
1) The real path score of current sentence according the true labels
2) The log total score of all the possbile paths of current sentence
3) Compute the cost on this sentence using the results from 1) and 2)
4) Total Cost += Cost of this sentence
'''
return Total Cost
def argmax(new sentences):
#[Prediction]
'''
Predict labels for new sentences
'''
3.词法分析 LAC实战
词法分析任务的输入是一个字符串(我们后面使用『句子』来指代它),而输出是句子中的词边界和词性、实体类别。序列标注是词法分析的经典建模方式,我们使用基于 GRU 的网络结构学习特征,将学习到的特征接入 CRF 解码层完成序列标注。模型结构如下所示
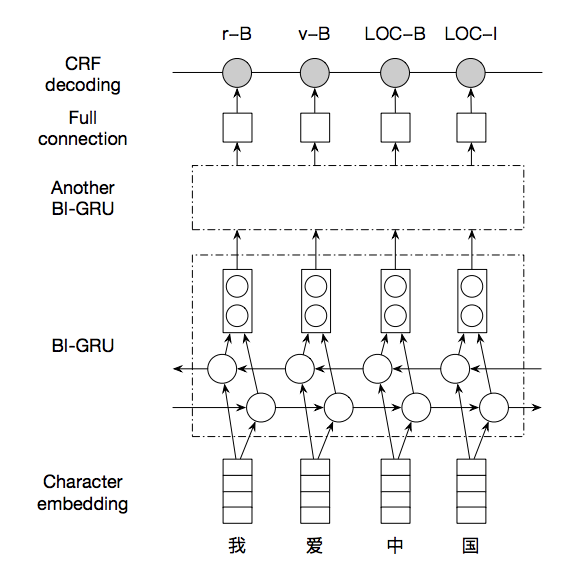
- 输入采用 one-hot 方式表示,每个字以一个 id 表示
- one-hot 序列通过字表,转换为实向量表示的字向量序列;
- 字向量序列作为双向 GRU 的输入,学习输入序列的特征表示,得到新的特性表示序列,我们堆叠了两层双向 GRU 以增加学习能力;
- CRF 以 GRU 学习到的特征为输入,以标记序列为监督信号,实现序列标注。
3.1 数据准备
提供了少数样本用以示例输入数据格式。执行以下命令,下载并解压示例数据集:
python download.py --data_dir ./
训练使用的数据可以由用户根据实际的应用场景,自己组织数据。除了第一行是 text_a\tlabel 固定的开头,后面的每行数据都是由两列组成,以制表符分隔,第一列是 utf-8 编码的中文文本,以 \002 分割,第二列是对应每个字的标注,以 \002 分隔。我们采用 IOB2 标注体系,即以 X-B 作为类型为 X 的词的开始,以 X-I 作为类型为 X 的词的持续,以 O 表示不关注的字(实际上,在词性、专名联合标注中,不存在 O )。示例如下:
除\002了\002他\002续\002任\002十\002二\002届\002政\002协\002委\002员\002,\002马\002化\002腾\002,\002雷\002军\002,\002李\002彦\002宏\002也\002被\002推\002选\002为\002新\002一\002届\002全\002国\002人\002大\002代\002表\002或\002全\002国\002政\002协\002委\002员 p-B\002p-I\002r-B\002v-B\002v-I\002m-B\002m-I\002m-I\002ORG-B\002ORG-I\002n-B\002n-I\002w-B\002PER-B\002PER-I\002PER-I\002w-B\002PER-B\002PER-I\002w-B\002PER-B\002PER-I\002PER-I\002d-B\002p-B\002v-B\002v-I\002v-B\002a-B\002m-B\002m-I\002ORG-B\002ORG-I\002ORG-I\002ORG-I\002n-B\002n-I\002c-B\002n-B\002n-I\002ORG-B\002ORG-I\002n-B\002n-I
其中词性和专名类别标签集合如下表,包含词性标签 24 个(小写字母),专名类别标签 4 个(大写字母)。这里需要说明的是,人名、地名、机构名和时间四个类别,存在(PER / LOC / ORG / TIME 和 nr / ns / nt / t)两套标签,被标注为第二套标签的词,是模型判断为低置信度的人名、地名、机构名和时间词。开发者可以基于这两套标签,在四个类别的准确、召回之间做出自己的权衡。
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
3.2 模型训练
- 单卡训练
启动方式如下:
python train.py \
--data_dir ./lexical_analysis_dataset_tiny \
--model_save_dir ./save_dir \
--epochs 10 \
--batch_size 32 \
--device gpu \
# --init_checkpoint ./save_dir/final
其中参数释义如下:
data_dir: 数据集所在文件夹路径.model_save_dir: 训练期间模型保存路径。epochs: 模型训练迭代轮数。batch_size: 表示每次迭代每张卡上的样本数目。device: 训练使用的设备, 'gpu'表示使用GPU, 'xpu'表示使用百度昆仑卡, 'cpu'表示使用CPU。init_checkpoint: 模型加载路径,通过设置init_checkpoint可以启动增量训练。
- 多卡训练
启动方式如下:
python -m paddle.distributed.launch --gpus "0,1" train.py \
--data_dir ./lexical_analysis_dataset_tiny \
--model_save_dir ./save_dir \
--epochs 10 \
--batch_size 32 \
--device gpu \
# --init_checkpoint ./save_dir/final
3.3 模型评估
通过加载训练保存的模型,可以对测试集数据进行验证,启动方式如下:
python eval.py --data_dir ./lexical_analysis_dataset_tiny \
--init_checkpoint ./save_dir/model_100.pdparams \
--batch_size 32 \
--device gpu
其中./save_dir/model_100.pdparams是训练过程中保存的参数文件,请更换为实际得到的训练保存路径。
3.4模型导出
使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,具体代码见export_model.py。静态图参数保存在output_path指定路径中。
运行方式:
python export_model.py --data_dir=./lexical_analysis_dataset_tiny --params_path=./save_dir/model_100.pdparams --output_path=./infer_model/static_graph_params
其中./save_dir/model_100.pdparams是训练过程中保存的参数文件,请更换为实际得到的训练保存路径。
params_path是指动态图训练保存的参数路径output_path是指静态图参数导出路径。
导出模型之后,可以用于部署,deploy/predict.py文件提供了python部署预测示例。运行方式:
python deploy/predict.py --model_file=infer_model/static_graph_params.pdmodel --params_file=infer_model/static_graph_params.pdiparams --data_dir lexical_analysis_dataset_tiny
3.5 模型预测
对无标签数据可以启动模型预测:
python predict.py --data_dir ./lexical_analysis_dataset_tiny \
--init_checkpoint ./save_dir/model_100.pdparams \
--batch_size 32 \
--device gpu
得到类似以下输出:
(大学, n)(学籍, n)(证明, n)(怎么, r)(开, v)
(电车, n)(的, u)(英文, nz)
(什么, r)(是, v)(司法, n)(鉴定人, vn)
- Taskflow一键预测
可以使用PaddleNLP提供的Taskflow工具来对输入的文本进行一键分词,具体使用方法如下:
from paddlenlp import Taskflow
lac = Taskflow("lexical_analysis")
lac("LAC是个优秀的分词工具")
'''
[{'text': 'LAC是个优秀的分词工具', 'segs': ['LAC', '是', '个', '优秀', '的', '分词', '工具'], 'tags': ['nz', 'v', 'q', 'a', 'u', 'n', 'n']}]
'''
lac(["LAC是个优秀的分词工具", "三亚是一个美丽的城市"])
'''
[{'text': 'LAC是个优秀的分词工具', 'segs': ['LAC', '是', '个', '优秀', '的', '分词', '工具'], 'tags': ['nz', 'v', 'q', 'a', 'u', 'n', 'n']},
{'text': '三亚是一个美丽的城市', 'segs': ['三亚', '是', '一个', '美丽', '的', '城市'], 'tags': ['LOC', 'v', 'm', 'a', 'u', 'n']}
]
'''
任务的默认路径为$HOME/.paddlenlp/taskflow/lexical_analysis/lac/,默认路径下包含了执行该任务需要的所有文件。
如果希望得到定制化的分词及标注结果,用户也可以通过Taskflow来加载自定义的词法分析模型并进行预测。
通过task_path指定用户自定义路径,自定义路径下的文件需要和默认路径的文件一致。
自定义路径包含如下文件(用户自己的模型权重、标签字典):
custom_task_path/
├── model.pdparams
├── word.dic
├── tag.dic
└── q2b.dic
使用Taskflow加载自定义模型进行一键预测:
from paddlenlp import Taskflow
my_lac = Taskflow("lexical_analysis", model_path="./custom_task_path/")
参考链接:
GRU:https://blog.csdn.net/weixin_44750512/article/details/128856846
【NLP】命名实体识别(NER)的BiLSTM-CRF模型 https://blog.csdn.net/b285795298/article/details/100764066
从RNN到LSTM到GRU---crf---bilstm+crf如何命名实体识别的流程:https://blog.csdn.net/qq_34243930/article/details/88778681
基于双向BiLstm神经网络的中文分词详解及:https://www.cnblogs.com/vipyoumay/p/8608754.html
[2] 向晓雯. 基于条件随机场的中文命名实体识别 [D]. , 2006.
[3] 张祝玉, 任飞亮, 朱靖波. 基于条件随机场的中文命名实体识别特征比较研究 [C]// 第 4 届全国信息检索与内容安全学术会议论文集. 2008.
[4] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
[5] Lample G, Ballesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition[C]//Proceedings of NAACL-HLT. 2016: 260-270.
[6] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(Aug): 2493-2537.
[7] Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstm-cnns-crf[J]. arXiv preprint arXiv:1603.01354, 2016.
[8] Dong C, Zhang J, Zong C, et al. Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition[C]//International Conference on Computer Processing of Oriental Languages. Springer International Publishing, 2016: 239-250.
标签:11,02,词性,12,log,模型,002,01,分词 From: https://www.cnblogs.com/ting1/p/18008304