展望Flink各版本及新特性
展望Flink各版本及新特性
- 一 Flink 1.9 版本
- 1.1 细粒度批作业恢复
- 1.2 State Processor API
- 1.3 Stop-with-Savepoint
- 1.4 新 Blink SQL 查询处理器预览
- 1.5 Table API / SQL 的其他改进
- 二 Flink 1.10 [重要版本 : Blink 整合完成]
- 2.1 内存管理及配置优化
- 2.2 统一的作业提交逻辑
- 2.3 原生 Kubernetes 集成(Beta)
- 2.4 Table API/SQL: 生产可用的 Hive 集成
- 2.5 其他 Table API/SQL 优化
- 三 Flink 1.11 [重要版本]
- 3.1 非对齐的 Checkpoints (Beta 版本)
- 3.2 统一的 Watermark 生成器
- 3.3 新的 Source 接口(Beta)
- 3.3 Application 部署模式
- 3.4 Table API/SQL:支持 CDC(Change Data Capture)
- 3.5 Hive 实时数仓
- 其它重要优化
- 四 Flink 1.12 [重要版本]
- 4.1 DataStream API 支持批执行模式
- 4.2 新的 Data Sink API (Beta)
- 4.3 基于 Kubernetes 的高可用 (HA) 方案
- 4.4 Table API/SQL改动
- SQL Connectors 中的 Metadata 处理
- Upsert Kafka Connector
- SQL 中 支持 Temporal Table Join
- 其他改进
- 五 Flink 1.13
- 5.1 被动扩缩容
- 5.2 分析应用的性能
- 5.2.1 瓶颈检测与反压监控
- 5.2.2 Web UI 中的 CPU 火焰图
- 5.2.3 State 访问延迟指标
- 5.3 通过 Savepoint 来切换 State Backend
- 5.4 K8s 部署时使用用户指定的 Pod 模式
- 5.5 生产可用的 Unaligned Checkpoint
- 5.6 SQL / Table API 进展
- 5.6.1 通过 Table-valued 函数来定义时间窗口
- 5.6.2 提高 DataStream API 与 Table API / SQL 的互操作能力
- 5.6.3 SQL Client: 初始化脚本和语句集合 (Statement Sets)
- 5.6.4 Hive 查询语法兼容性
- 5.6.5 优化的 SQL 时间函数
- 5.7 其它优化
- 参考原文
- 六 Flink 1.14
- 6.1 批流一体
- 6.2 运维改进
- 6.2.1 缓冲区去膨胀
- 6.2.2 细粒度资源管理
- 参考原文
- 七 Flink 1.15
- 总结
- 参考原文
- 八 Flink 1.16
- 九 Flink 1.17
- 参考原文
- Flink 2.0 规划
一 Flink 1.9 版本
阿里内部版本Blink首次合并入Flink,并于2019年8月22日,正式发布Apache Flink 1.9.0 版本。
此次版本更新带来的重大功能包括批处理作业的批式恢复,以及 Table API 和 SQL 的基于 Blink 的新查询引擎(预览版)。同时,这一版本还推出了 State Processor API,这是社区最迫切需求的功能之一,该 API 使用户能够用 Flink DataSet 作业灵活地读写保存点。此外,Flink 1.9 还包括一个重新设计的 WebUI 和新的 Python Table API (预览版)以及与 Apache Hive 生态系统的集成(预览版)。
新功能和改进
- 细粒度批作业恢复 (FLIP-1)
- State Processor API (FLIP-43)
- Stop-with-Savepoint (FLIP-34)
- 重构 Flink WebUI
- 预览新的 Blink SQL 查询处理器
- Table API / SQL 的其他改进
- 预览 Hive 集成 (FLINK-10556)
- 预览新的 Python Table API (FLIP-38)
1.1 细粒度批作业恢复
批作业(DataSet、Table API 和 SQL)从 task 失败中恢复的时间被显著缩短了。在 Flink 1.9 之前,批处理作业中的 task 失败是通过取消所有 task 并重新启动整个作业来恢复的,即作业从头开始,所有进度都会废弃。在此版本中,Flink 将中间结果保留在网络 shuffle 的边缘,并使用此数据去恢复那些仅受故障影响的 task。所谓 task 的 “failover regions” (故障区)是指通过 pipelined 方式连接的数据交换方式,定义了 task 受故障影响的边界。
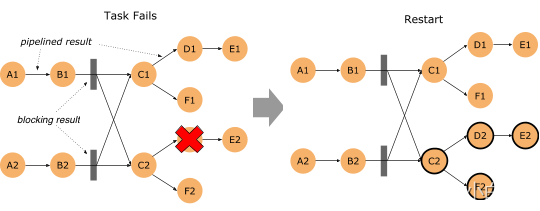
要使用这个新的故障策略,需要确保 flink-conf.yaml 中有 jobmanager.execution.failover-strategy: region 的配置。
注意:1.9 发布包中默认就已经包含了该配置项,不过当从之前版本升级上来时,如果要复用之前的配置的话,需要手动加上该配置。
“Region” 的故障策略也能同时提升 “embarrassingly parallel” 类型的流作业的恢复速度,也就是没有任何像 keyBy() 和 rebalance 的 shuffle 的作业。当这种作业在恢复时,只有受影响的故障区的 task 需要重启。对于其他类型的流作业,故障恢复行为与之前的版本一样。
1.2 State Processor API
直到 Flink 1.9,从外部访问作业的状态仅局限于:Queryable State(可查询状态)实验性功能。此版本中引入了一种新的、强大的类库,基于 DataSet 支持读取、写入、和修改状态快照。在实践上,这意味着:
Flink 作业的状态可以自主构建了,可以通过读取外部系统的数据(例如外部数据库),然后转换成 savepoint。
Savepoint 中的状态可以使用任意的 Flink 批处理 API 查询(DataSet、Table、SQL)。例如,分析相关的状态模式或检查状态差异以支持应用程序审核或故障排查。
Savepoint 中的状态 schema 可以离线迁移了,而之前的方案只能在访问状态时进行,是一种在线迁移。
Savepoint 中的无效数据可以被识别出来并纠正。
新的 State Processor API 覆盖了所有类型的快照:savepoint,full checkpoint 和 incremental checkpoint。
1.3 Stop-with-Savepoint
“Cancel-with-savepoint” 是停止、重启、fork、或升级 Flink 作业的一个常用操作。然而,当前的实现并没有保证输出到 exactly-once sink 的外部存储的数据持久化。为了改进停止作业时的端到端语义,Flink 1.9 引入了一种新的 SUSPEND 模式,可以带 savepoint 停止作业,保证了输出数据的一致性。你可以使用 Flink CLI 来 suspend 一个作业
1.4 新 Blink SQL 查询处理器预览
在 Blink 捐赠给 Apache Flink 之后,社区就致力于为 Table API 和 SQL 集成 Blink 的查询优化器和 runtime。第一步,我们将 flink-table 单模块重构成了多个小模块(FLIP-32)。这对于 Java 和 Scala API 模块、优化器、以及 runtime 模块来说,有了一个更清晰的分层和定义明确的接口。

紧接着,我们扩展了 Blink 的 planner 以实现新的优化器接口,所以现在有两个插件化的查询处理器来执行 Table API 和 SQL:1.9 以前的 Flink 处理器和新的基于 Blink 的处理器。基于 Blink 的查询处理器提供了更好地 SQL 覆盖率(1.9 完整支持 TPC-H,TPC-DS 的支持在下一个版本的计划中)并通过更广泛的查询优化(基于成本的执行计划选择和更多的优化规则)、改进的代码生成机制、和调优过的算子实现来提升批处理查询的性能。除此之外,基于 Blink 的查询处理器还提供了更强大的流处理能力,包括一些社区期待已久的新功能(如维表 Join,TopN,去重)和聚合场景缓解数据倾斜的优化,以及内置更多常用的函数。
注:两个查询处理器之间的语义和功能大部分是一致的,但并未完全对齐。具体请查看发布日志。
不过, Blink 的查询处理器的集成还没有完全完成。因此,1.9 之前的 Flink 处理器仍然是1.9 版本的默认处理器,建议用于生产设置。你可以在创建 TableEnvironment 时通过 EnvironmentSettings 配置启用 Blink 处理器。被选择的处理器必须要在正在执行的 Java 进程的类路径中。对于集群设置,默认两个查询处理器都会自动地加载到类路径中。当从 IDE 中运行一个查询时,需要在项目中显式地增加一个处理器的依赖。
1.5 Table API / SQL 的其他改进
除了围绕 Blink Planner 令人兴奋的进展外,社区还做了一系列的改进,包括:
为 Table API / SQL 的 Java 用户去除 Scala 依赖 (FLIP-32)
作为重构和拆分 flink-table 模块工作的一部分,我们为 Java 和 Scala 创建了两个单独的 API 模块。对于 Scala 用户来说,没有什么改变。不过现在 Java 用户在使用 Table API 和 SQL 时,可以不用引入一堆 Scala 依赖了。
重构 Table API / SQL 的类型系统(FLIP-37)
我们实现了一个新的数据类型系统,以便从 Table API 中移除对 Flink TypeInformation 的依赖,并提高其对 SQL 标准的遵从性。不过还在进行中,预计将在下一版本完工,在 Flink 1.9 中,UDF 尚未移植到新的类型系统上。
Table API 的多行多列转换(FLIP-29)
Table API 扩展了一组支持多行和多列、输入和输出的转换的功能。这些转换显著简化了处理逻辑的实现,同样的逻辑使用关系运算符来实现是比较麻烦的。
崭新的统一的 Catalog API
Catalog 已有的一些接口被重构和(某些)被替换了,从而统一了内部和外部 catalog 的处理。这项工作主要是为了 Hive 集成(见下文)而启动的,不过也改进了 Flink 在管理 catalog 元数据的整体便利性。
SQL API 中的 DDL 支持 (FLINK-10232)
到目前为止,Flink SQL 已经支持 DML 语句(如 SELECT,INSERT)。但是外部表(table source 和 table sink)必须通过 Java/Scala 代码的方式或配置文件的方式注册。1.9 版本中,我们支持 SQL DDL 语句的方式注册和删除表(CREATE TABLE,DROP TABLE)。然而,我们还没有增加流特定的语法扩展来定义时间戳抽取和 watermark 生成策略等。流式的需求将会在下一版本完整支持
官方原文:
https://flink.apache.org/news/2019/08/22/release-1.9.0.html
二 Flink 1.10 [重要版本 : Blink 整合完成]
作为 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成(beta 版本)以及对 Python 支持(PyFlink)的重大优化。
Flink 1.10 同时还标志着对 Blink[1] 的整合宣告完成,随着对 Hive 的生产级别集成及对 TPC-DS 的全面覆盖,Flink 在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。
2.1 内存管理及配置优化
Flink 目前的 TaskExecutor 内存模型存在着一些缺陷,导致优化资源利用率比较困难,例如:
流和批处理内存占用的配置模型不同;
流处理中的 RocksDB state backend 需要依赖用户进行复杂的配置。
为了让内存配置变的对于用户更加清晰、直观,Flink 1.10 对 TaskExecutor 的内存模型和配置逻辑进行了较大的改动 。这些改动使得 Flink 能够更好地适配所有部署环境(例如 Kubernetes, Yarn, Mesos),让用户能够更加严格的控制其内存开销。
■ Managed 内存扩展
Managed 内存的范围有所扩展,还涵盖了 RocksDB state backend 使用的内存。尽管批处理作业既可以使用堆内内存也可以使用堆外内存,使用 RocksDB state backend 的流处理作业却只能利用堆外内存。因此为了让用户执行流和批处理作业时无需更改集群的配置,我们规定从现在起 managed 内存只能在堆外。
■ 简化 RocksDB 配置
此前,配置像 RocksDB 这样的堆外 state backend 需要进行大量的手动调试,例如减小 JVM 堆空间、设置 Flink 使用堆外内存等。现在,Flink 的开箱配置即可支持这一切,且只需要简单地改变 managed 内存的大小即可调整 RocksDB state backend 的内存预算。
另一个重要的优化是,Flink 现在可以限制 RocksDB 的 native 内存占用,以避免超过总的内存预算——这对于 Kubernetes 等容器化部署环境尤为重要。关于如何开启、调试该特性,请参考 RocksDB
2.2 统一的作业提交逻辑
在此之前,提交作业是由执行环境负责的,且与不同的部署目标(例如 Yarn, Kubernetes, Mesos)紧密相关。这导致用户需要针对不同环境保留多套配置,增加了管理的成本。
在 Flink 1.10 中,作业提交逻辑被抽象到了通用的 Executor 接口。新增加的 ExecutorCLI 引入了为任意执行目标指定配置参数的统一方法。此外,随着引入 JobClient负责获取 JobExecutionResult,获取作业执行结果的逻辑也得以与作业提交解耦
2.3 原生 Kubernetes 集成(Beta)
对于想要在容器化环境中尝试 Flink 的用户来说,想要在 Kubernetes 上部署和管理一个 Flink standalone 集群,首先需要对容器、算子及像 kubectl 这样的环境工具有所了解。
在 Flink 1.10 中,我们推出了初步的支持 session 模式的主动 Kubernetes 集成(FLINK-9953 [15])。其中,“主动”指 Flink ResourceManager (K8sResMngr) 原生地与 Kubernetes 通信,像 Flink 在 Yarn 和 Mesos 上一样按需申请 pod。用户可以利用 namespace,在多租户环境中以较少的资源开销启动 Flink。这需要用户提前配置好 RBAC 角色和有足够权限的服务账号。

正如在统一的作业提交逻辑一节中提到的,Flink 1.10 将命令行参数映射到了统一的配置。因此,用户可以参阅 Kubernetes 配置选项,在命令行中使用以下命令向 Kubernetes 提交 Flink 作业。
./bin/flink run -d -e kubernetes-session -Dkubernetes.cluster-id=<ClusterId> examples/streaming/WindowJoin.jar
2.4 Table API/SQL: 生产可用的 Hive 集成
Flink 1.9 推出了预览版的 Hive 集成。该版本允许用户使用 SQL DDL 将 Flink 特有的元数据持久化到 Hive Metastore、调用 Hive 中定义的 UDF 以及读、写 Hive 中的表。Flink 1.10 进一步开发和完善了这一特性,带来了全面兼容 Hive 主要版本[17]的生产可用的 Hive 集成。
■ Batch SQL 原生分区支持
此前,Flink 只支持写入未分区的 Hive 表。在 Flink 1.10 中,Flink SQL 扩展支持了 INSERT OVERWRITE 和 PARTITION 的语法(FLIP-63 [18]),允许用户写入 Hive 中的静态和动态分区。
写入静态分区
INSERT { INTO | OVERWRITE } TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
写入动态分区
INSERT { INTO | OVERWRITE } TABLE tablename1 select_statement1 FROM from_statement;
对分区表的全面支持,使得用户在读取数据时能够受益于分区剪枝,减少了需要扫描的数据量,从而大幅提升了这些操作的性能。
■ 其他优化
除了分区剪枝,Flink 1.10 的 Hive 集成还引入了许多数据读取[19]方面的优化,例如:
投影下推:Flink 采用了投影下推技术,通过在扫描表时忽略不必要的域,最小化 Flink 和 Hive 表之间的数据传输量。这一优化在表的列数较多时尤为有效。
LIMIT 下推:对于包含 LIMIT 语句的查询,Flink 在所有可能的地方限制返回的数据条数,以降低通过网络传输的数据量。
读取数据时的 ORC 向量化: 为了提高读取 ORC 文件的性能,对于 Hive 2.0.0 及以上版本以及非复合数据类型的列,Flink 现在默认使用原生的 ORC 向量化读取器。
■ 将可插拔模块作为 Flink 内置对象(Beta)
Flink 1.10 在 Flink table 核心引入了通用的可插拔模块机制,目前主要应用于系统内置函数(FLIP-68 [20])。通过模块,用户可以扩展 Flink 的系统对象,例如像使用 Flink 系统函数一样使用 Hive 内置函数。新版本中包含一个预先实现好的 HiveModule,能够支持多个 Hive 版本,当然用户也可以选择编写自己的可插拔模块 [21]。
2.5 其他 Table API/SQL 优化
■ SQL DDL 中的 watermark 和计算列
Flink 1.10 在 SQL DDL 中增加了针对流处理定义时间属性及产生 watermark 的语法扩展。这使得用户可以在用 DDL 语句创建的表上进行基于时间的操作(例如窗口)以及定义 watermark 策略。
CREATE TABLE table_name (WATERMARK FOR columnName AS <watermark_strategy_expression>) WITH (
...
)
其他 SQL DDL 扩展
Flink 现在严格区分临时/持久、系统/目录函数。这不仅消除了函数引用中的歧义,还带来了确定的函数解析顺序(例如,当存在命名冲突时,比起目录函数、持久函数 Flink 会优先使用系统函数、临时函数)。
我们扩展了 SQL DDL 的语法,支持创建目录函数、临时函数以及临时系统函数.
CREATE [TEMPORARY|TEMPORARY SYSTEM] FUNCTION[IF NOT EXISTS] [catalog_name.][db_name.]function_nameAS identifier [LANGUAGE JAVA|SCALA]
注:为了今后正确地处理和保证元对象(表、视图、函数)上的行为一致性,Flink 废弃了 Table API 中的部分对象申明方法,以使留下的方法更加接近标准的 SQL DDL。
官方原文:
https://flink-learning.org.cn/article/detail/1a25092968e7575caf5d7a057039fc44
三 Flink 1.11 [重要版本]
Apache Flink 社区很荣幸的宣布 Flink 1.11.0 版本正式发布!超过 200 名贡献者参与了 Flink 1.11.0 的开发,提交了超过 1300 个修复或优化。这些修改极大的提高了 Flink 的可用性,并且增强了各个 API 栈的功能。其中一些比较重要的修改包括:
-
核心引擎部分引入了非对齐的 Checkpoint 机制。这一机制是对 Flink 容错机制的一个重要改进,它可以提高严重反压作业的 Checkpoint 速度。
-
实现了一套新的 Source 接口。通过统一流和批作业 Source 的运行机制,提供常用的内部实现如事件时间处理,watermark 生成和空闲并发检测,这套新的 Source 接口可以极大的降低实现新的 Source 时的开发复杂度。
-
Flink SQL 引入了对 CDC(Change Data Capture,变动数据捕获)的支持,它使 Flink 可以方便的通过像 Debezium 这类工具来翻译和消费数据库的变动日志。Table API 和 SQL 也扩展了文件系统连接器对更多用户场景和格式的支持,从而可以支持将流式数据从 Kafka 写入 Hive 等场景。
-
PyFlink 优化了多个部分的性能,包括对向量化的用户自定义函数(Python UDF)的支持。这些改动使 Flink Python 接口可以与常用的 Python 库(如 Pandas 和 NumPy)进行互操作,从而使 Flink 更适合数据处理与机器学习的场景。
3.1 非对齐的 Checkpoints (Beta 版本)
当 Flink 发起一次 Checkpoint 时, Checkpoint Barrier 会从整个拓扑的 Source 出发一直流动到 Sink。对于超过一个输入的算子,来自各个输入的 Barrier 首先需要对齐,然后这个算子才能进行 state 的快照操作以及将 Barrier 发布给后续的算子。一般情况下对齐可以在几毫秒内完成,但是当反压时,对齐可能成为一个瓶颈:
1.Checkpoint Barrier 在有反压的输入通道中传播的速度非常慢(需要等待前面的数据处理完成),这将会阻塞对其它输入通道的数据处理并最终进一步反压上游的算子
2. Checkpoint Barrier 传播慢还会导致 Checkpoint 时间过长甚至超时,在最坏的情况下,这可能导致整个作业进度无法更新。
为了提高 Checkpoint 在反压情况下的性能,Flink 社区在 1.11.0 版本中初步实现了非对齐的 Checkpoint 机制。与对齐的 Checkpoint相比,这种方式下算子不需要等待来自各个输入通道的 Barrier 对齐,相反,这种方式允许 Barrier 越过前面的待处理的数据(即在输出和输入 Buffer 中的数据)并且直接触发 Checkpoint 的同步阶段。

图为:非对齐的Checkpoint
由于被越过的传播中的数据必须作为快照的一部分被持久化,非对齐的 Checkpoint 机制会增加 Checkpoint 的大小。但是,好的方面是它可以极大的减少 Checkpoint 需要的时间,因此即使在非稳定的环境中,用户也可以看到更多的作业进度。这是由于非对齐的 Checkpoint 可以减少 Recovery 的负载。
和其它 Beta 版本的特性一样,我们非常期待和感谢您试用之后和社区分享您的感受。
注意:开启这一特征需要通过 Chekpoint 选项配置 enableUnalignedCheckpoints 参数。需要注意的是,非对齐的 Checkpoint 只有在 CheckpointMode 被设置为 CheckpointMode.EXACTLY_ONCE 的时候才有效。
3.2 统一的 Watermark 生成器
统一的 Watermark 生成器
目前 Flink 的 Watermark 生成(也叫做分配)依赖于两个接口:AssignerWithPunctuatedWatermarks 与 AssignerWithPeriodicWatermarks,这两个接口与记录时间戳提取的关系也比较混乱,从而使 Flink 难以实现一些用户急需的功能,如支持空闲检测;此外,这还会导致代码重复且难以维护。通过 FLIP-126,现有的 watermark 生成接口被统一为一个单独的接口,即 WatermarkGenerator,并且它和 TimestampAssigner 独立。
这一修改使用户可以更好的控制 watermark 的发送逻辑,并且简化实现支持watermark 生成和时间戳提取的 Source 的难度(可以参考新的 Source 接口)。基于这一接口,Flink 1.11 中还提供了许多内置的 Watermark 生成策略(例如 forBoundedOutOfOrderness, forMonotonousTimestamps),并且用户可以使用自己的实现。
■ 支持 Watermark 空闲检测
WatermarkStrategy.withIdleness()方法允许用户在配置的时间内(即超时时间内)没有记录到达时将一个流标记为空闲,从而进一步支持 Flink 正确处理多个并发之间的事件时间倾斜的问题,并且避免了空闲的并发延迟整个系统的事件时间。通过将 Kafka 连接器迁移至新的接口(FLINK-17669),用户可以受益于针对单个并发的空闲检测。
注意:这一 FLIP 的修改目前不会影响现有程序,但是我们推荐用户后续尽量使用新的 Watermark 生成接口,避免后续版本禁用之前的 Watermark 生成器带来的影响.
3.3 新的 Source 接口(Beta)
1.11 以编写一个生产可用的 Flink Source 连接器并不是一个简单的任务,它需要用户对 Flink 内部实现有一定的了解,并且需要在连接器中自行实现事件时间提取、Watermark 生成和空闲检测等功能。针对这一问题,Flink 1.11 引入了一套新的Source 接口 FLIP-27 来解决上述问题,并且同时解决了需要为批作业和流作业编写两套 Source 实现的问题。

通过将分区发现和实现消费每一个分区的数据分成不同的组件(即 SplitEnumerator 和 SourceReader),新的 Source 接口允许将不同的分区发现策略和分区消费的具体实现任意组合。
例如,现有的 Kafka 连接器提供了多种不同的分区发现策略,这些策略的实现和其实代码的实现耦合在一起。如果迁移到新的接口,Kafka Source 将可以使用相同的分区消费的实现(即 SourceReader),并且针对不同的分区发现策略编写单独的 SplitEnumerator 的实现。
■ 流批统一
使用新版 Source 接口的 Source 连接器将可以同时用于有限数据(批)作业和无限数据(流)作业。这两种场景仅有一个很小的区别:在有限数据的情况下,分区发现策略将返回一个固定大小的分区并且每一个分区的数据都是有限的;在无限数据的情况下,要么每个分区的数据量是无限的,要么分区发现策略可以不断的产生新的分区。
■ 内置的 Watermark 和事务时间处理
在新版 Source 接口中,TimestampAssigner 和 WatermarkGenerator 将透明的作为分区消费具体实现(SourceReader)的一部分,因此用户不需要实现任何时间戳提取和 Watermark 生成的代码。
注意:现有的 Source 连接器尚未基于新的 Source 接口重新实现,这将在后续版本中逐渐完成。如果想要基于新的 Source 接口实现自己的 Source,可以参考 Data Source 文档和 Source 开发的一些建议。
3.3 Application 部署模式
在1.11之前,Flink 的作业有两种部署模式,其中 Session 模式是将作业提交到一个长期运行的 Flink Session 集群,Job 模式是为每个作业启动一个专门的 Flink 作业集群。这两种模式下用户作业的 main 方法都是客户端执行的,但是这种方式存在一定的问题:如果客户端是更大程序的一部分的话,生成 JobGraph 容易成为系统的瓶颈;其次,这种方式也不能很好的适应像 Docker 和 K8s 这样的容器环境。
Flink 1.11 引入了一种新的部署模式,即 Application 模式(FLIP-85)。这种模式下用户程序的 main 方法将在集群中而不是客户端运行。这样,作业提交就会变得非常简单:用户将程序逻辑和依赖打包进一人可执行的 jar 包里,集群的入口程序(ApplicationClusterEntryPoint)负责调用其中的 main 方法来生成 JobGraph。
Flink 1.11 已经可以支持基于 K8s 的 Application 模式.
3.4 Table API/SQL:支持 CDC(Change Data Capture)
CDC 是数据库中一种常用的模式,它捕获数据库提交的修改并且将这些修改广播给其它的下游消费者。CDC 可以用于像同步多个数据存储和避免双写导致的问题等场景。长期以来 Flink 的用户都希望能够将 CDC 数据通过 Table API/SQL 导入到作业中,而 Flink 1.11 实现了这一点。
为了能够在 Table API / SQL 中使用 CDC,Flink 1.11 更新了 Table Source 与 Sink 的接口来支持 changelog 模式(参考新的 Table Source 与 Sink 接口)并且支持了 Debezium 与 Canal 格式。这一改动使动态 Table Source 不再只支持 append-only 的操作,而且可以导入外部的修改日志(插入事件)将它们翻译为对应的修改操作(插入,修改和删除)并将这些操作与操作的类型发送到后续的流中。
为了消费 CDC 数据,用户需要在使用 SQL DDL 创建表时指指定“format=debezium-json“或者“format=canal-json”:
CREATE TABLE my_table (...
) WITH ('connector'='...', -- e.g. 'kafka''format'='debezium-json','debezium-json.schema-include'='true' -- default: false (Debezium can be configured to include or exclude the message schema)'debezium-json.ignore-parse-errors'='true' -- default: false
);
Flink 1.11 仅支持 Kafka 作为修改日志的数据源以及 JSON 编码格式的修改日志;后续 Flink 将进一步支持 Avro(Debezium)和 Protobuf(Canal)格式。Flink 还计划在未来支持 UDF MySQL 的 Binlog 以及 Kafka 的 Compact Topic 作为数据源,并且将对修改日志的支持扩展到批作业。
注意:目前有一个已知的 BUG(FLINK-18461)会导致使用修改日志的 Source 无法写入到 Upsert Sink 中(例如,MySQL,HBase,ElasticSearch)。这个问题会在下一个版本(即 1.11.1)中修复。
3.5 Hive 实时数仓
从 1.9.0 版本开始 Flink 从生态角度致力于集成 Hive,目标打造批流一体的 Hive 数仓。经过前两个版本的迭代,已经达到了 batch 兼容且生产可用,在 TPC-DS 10T benchmark 下性能达到 Hive 3.0 的 7 倍以上。
1.11.0 在 Hive 生态中重点实现了实时数仓方案,改善了端到端流式 ETL 的用户体验,达到了批流一体 Hive 数仓的目标。同时在兼容性、性能、易用性方面也进一步进行了加强。
在实时数仓的解决方案中,凭借 Flink 的流式处理优势做到实时读写 Hive:
Hive 写入:FLIP-115 完善扩展了 FileSystem connector 的基础能力和实现,Table/SQL 层的 sink 可以支持各种格式(CSV、Json、Avro、Parquet、ORC),而且支持 Hive table 的所有格式。
Partition 支持:数据导入 Hive 引入 partition 提交机制来控制可见性,通过sink.partition-commit.trigger 控制 partition 提交的时机,通过 sink.partition-commit.policy.kind 选择提交策略,支持 SUCCESS 文件和 metastore 提交。
Hive 读取:实时化的流式读取 Hive,通过监控 partition 生成增量读取新 partition,或者监控文件夹内新文件生成来增量读取新文件。
在 Hive 可用性方面的提升:
Hive Dialect 为用户提供语法兼容,这样用户无需在 Flink 和 Hive 的 CLI 之间切换,可以直接迁移 Hive 脚本到 Flink 中执行。
提供 Hive 相关依赖的内置支持,避免用户自己下载所需的相关依赖。现在只需要单独下载一个包,配置 HADOOP_CLASSPATH 就可以运行。
在 Hive 性能方面,1.10.0 中已经支持了 ORC(Hive 2+)的向量化读取,1.11.0 中我们补全了所有版本的 Parquet 和 ORC 向量化支持来提升性能。
其它重要优化
-
从1.11开始,Blink Planner 将变为 Table API/SQL 的默认 Planner。实际上,在1.10中 SQL Client 的默认 Planner 已经变为 Blink Planner。老的 Planner 仍然将会支持,但是后续不会再有大的变更。
[FLINK-5763] Savepoints 将所有的状态写入到单个目录下(包括元数据和程序状态)。这使得用户可以容易的看出每个 Savepoint 的 State 包含哪些文件,并且允许用户直接通过移动目录来实现 Savepoint 的重定位。 -
为了减少 JVM 元数据空间的压力,Flink 1.11 中对于单个 TaskExecutor 只要上面还有某个作业的 Slot,该作业的 ClassLoader 就会被复用。这一改动会改变 Flink 错误恢复的行为,因为 static 字段不会被重新初始化。
-
Flink 现在可以支持 Hadoop 3.0.0 以上的版本。注意 Flink 项目并未提供任何更新的“flink-shaded-hadoop-*”的 jar 包,而是需要用户自己将相应的 Hadoop 依赖加入 HADOOP_CLASSPATH 环境变量- (推荐的方式)或者将 Hadoop 依赖加入到 lib/目录下。
-
所有 Flink 内置的 Metric Report 现在被修改为 Flink 的插件。如果要使用它们,不应该放置到 lib/目录下(会导致类冲突),而是要放置到 plugins/目录下。
社区正在对 Flink 文档进行重构,从1.11开始,您可能会注意到文档的导航和内容组织发生了一些变化。
官方原文:
https://flink-learning.org.cn/article/detail/8da6b02d2c42eef004e3d0fdd55eb941
四 Flink 1.12 [重要版本]
- 在 DataStream API 上添加了高效的批执行模式的支持。这是批处理和流处理实现真正统一的运行时的一个重要里程碑。
- 实现了基于Kubernetes的高可用性(HA)方案,作为生产环境中,ZooKeeper方案之外的另外一种选择。
- 扩展了 Kafka SQL connector,使其可以在 upsert 模式下工作,并且支持在 SQL DDL 中处理 connector 的 metadata。现在,时态表 Join 可以完全用 SQL 来表示,不再依赖于 Table API 了。
- PyFlink 中添加了对于 DataStream API 的支持,将 PyFlink 扩展到了更复杂的场景,比如需要对状态或者定时器 timer 进行细粒度控制的场景。除此之外,现在原生支持将 PyFlink 作业部署到 Kubernetes上。
4.1 DataStream API 支持批执行模式
Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
- 可复用性:作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
- 维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景。
考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
■ 有限流上的批处理
您已经可以使用 DataStream API 来处理有限流(例如文件)了,但需要注意的是,运行时并不“知道”作业的输入是有限的。为了优化在有限流情况下运行时的执行性能,新的 BATCH 执行模式,对于聚合操作,全部在内存中进行,且使用 sort-based shuffle(FLIP-140)和优化过的调度策略(请参见 Pipelined Region Scheduling 了解更多详细信息)。因此,DataStream API 中的 BATCH 执行模式已经非常接近 Flink 1.12 中 DataSet API 的性能。

在 Flink 1.12 中,默认执行模式为 STREAMING,要将作业配置为以 BATCH 模式运行,可以在提交作业的时候,设置参数 execution.runtime-mode:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
或者通过编程的方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeMode.BATCH);
注意:尽管 DataSet API 尚未被弃用,但我们建议用户优先使用具有 BATCH 执行模式的 DataStream API 来开发新的批作业,并考虑迁移现有的 DataSet 作业。
4.2 新的 Data Sink API (Beta)
之前发布的 Flink 版本中[1],已经支持了 source connector 工作在流批两种模式下,因此在 Flink 1.12 中,社区着重实现了统一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit 协议和一个更加模块化的接口。Sink 的实现者只需要定义 what 和 how:SinkWriter,用于写数据,并输出需要 commit 的内容(例如,committables);Committer 和 GlobalCommitter,封装了如何处理 committables。框架会负责 when 和 where:即在什么时间,以及在哪些机器或进程中 commit。

这种模块化的抽象允许为 BATCH 和 STREAMING 两种执行模式,实现不同的运行时策略,以达到仅使用一种 sink 实现,也可以使两种模式都可以高效执行。Flink 1.12 中,提供了统一的 FileSink connector,以替换现有的 StreamingFileSink connector (FLINK-19758)。其它的 connector 也将逐步迁移到新的接口。
4.3 基于 Kubernetes 的高可用 (HA) 方案
Flink 可以利用 Kubernetes 提供的内置功能来实现 JobManager 的 failover,而不用依赖 ZooKeeper。为了实现不依赖于 ZooKeeper 的高可用方案,社区在 Flink 1.12(FLIP-144)中实现了基于 Kubernetes 的高可用方案。该方案与 ZooKeeper 方案基于相同的接口[3],并使用 Kubernetes 的 ConfigMap[4] 对象来处理从 JobManager 的故障中恢复所需的所有元数据。关于如何配置高可用的 standalone 或原生 Kubernetes 集群的更多详细信息和示例,请查阅文档[5]。
注意:需要注意的是,这并不意味着 ZooKeeper 将被删除,这只是为 Kubernetes 上的 Flink 用户提供了另外一种选择。
4.4 Table API/SQL改动
SQL Connectors 中的 Metadata 处理
如果可以将某些 source(和 format)的元数据作为额外字段暴露给用户,对于需要将元数据与记录数据一起处理的用户来说很有意义。一个常见的例子是 Kafka,用户可能需要访问 offset、partition 或 topic 信息、读写 kafka 消息中的 key 或 使用消息 metadata中的时间戳进行时间相关的操作。
在 Flink 1.12 中,Flink SQL 支持了元数据列用来读取和写入每行数据中 connector 或 format 相关的列。这些列在 CREATE TABLE 语句中使用 METADATA(保留)关键字来声明。
CREATE TABLE kafka_table (
id BIGINT,
name STRING,
event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata
headers MAP<STRING, BYTES> METADATA -- access Kafka 'headers' metadata
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'format' = 'avro'
);
在 Flink 1.12 中,已经支持 Kafka 和 Kinesis connector 的元数据,并且 FileSystem connector 上的相关工作也已经在计划中。由于 Kafka record 的结构比较复杂,社区还专门为 Kafka connector 实现了新的属性,以控制如何处理键/值对。关于 Flink SQL 中元数据支持的完整描述,请查看每个 connector 的文档以及中描述的用例。
Upsert Kafka Connector
在某些场景中,例如读取 compacted topic 或者输出(更新)聚合结果的时候,需要将 Kafka 消息记录的 key 当成主键处理,用来确定一条数据是应该作为插入、删除还是更新记录来处理。为了实现该功能,社区为 Kafka 专门新增了一个 upsert connector(upsert-kafka),该 connector 扩展自现有的 Kafka connector,工作在 upsert 模式(FLIP-149)下。新的 upsert-kafka connector 既可以作为 source 使用,也可以作为 sink 使用,并且提供了与现有的 kafka connector 相同的基本功能和持久性保证,因为两者之间复用了大部分代码。
要使用 upsert-kafka connector,必须在创建表时定义主键,并为键(key.format)和值(value.format)指定序列化反序列化格式。完整的示例,请查看最新的文档.
SQL 中 支持 Temporal Table Join
在之前的版本中,用户需要通过创建时态表函数(temporal table function) 来支持时态表 join(temporal table join) ,而在 Flink 1.12 中,用户可以使用标准的 SQL 语句 FOR SYSTEM_TIME AS OF(SQL:2011)来支持 join。此外,现在任意包含时间列和主键的表,都可以作为时态表,而不仅仅是 append-only 表。这带来了一些新的应用场景,比如将 Kafka compacted topic 或数据库变更日志(来自 Debezium 等)作为时态表。
CREATE TABLE orders (order_id STRING,currency STRING,amount INT, order_time TIMESTAMP(3), WATERMARK FOR order_time AS order_time - INTERVAL '30' SECOND
) WITH (…
);-- Table backed by a Kafka compacted topic
CREATE TABLE latest_rates ( currency STRING,rate DECIMAL(38, 10),currency_time TIMESTAMP(3),WATERMARK FOR currency_time AS currency_time - INTERVAL ‘5’ SECOND,PRIMARY KEY (currency) NOT ENFORCED
) WITH ('connector' = 'upsert-kafka',…
);-- Event-time temporal table join
SELECT o.order_id,o.order_time,o.amount * r.rate AS amount,r.currency
FROM orders AS o, latest_rates FOR SYSTEM_TIME AS OF o.order_time r
ON o.currency = r.currency;
上面的示例同时也展示了如何在 temporal table join 中使用 Flink 1.12 中新增的 upsert-kafka connector。
■ 使用 Hive 表进行 Temporal Table Join
用户也可以将 Hive 表作为时态表来使用,Flink 既支持自动读取 Hive 表的最新分区作为时态表(FLINK-19644),也支持在作业执行时追踪整个 Hive 表的最新版本作为时态表。请参阅文档,了解更多关于如何在 temporal table join 中使用 Hive 表的示例。
其他改进
Kinesis Flink SQL Connector (FLINK-18858) ** 从 Flink 1.12 开始,Table API / SQL 原生支持将 Amazon Kinesis Data Streams(KDS)作为 source 和 sink 使用。新的 Kinesis SQL connector 提供了对于增强的Fan-Out(EFO)以及 Sink Partition 的支持。如需了解 Kinesis SQL connector 所有支持的功能、配置选项以及对外暴露的元数据信息,请查看最新的文档。
**■ 在 FileSystem/Hive connector 的流式写入中支持小文件合并 (FLINK-19345) ** 很多 bulk format,例如 Parquet,只有当写入的文件比较大时,才比较高效。当 checkpoint 的间隔比较小时,这会成为一个很大的问题,因为会创建大量的小文件。在 Flink 1.12 中,File Sink 增加了小文件合并功能,从而使得即使作业 checkpoint 间隔比较小时,也不会产生大量的文件。要开启小文件合并,可以按照文档[11]中的说明在 FileSystem connector 中设置 auto-compaction = true 属性。
■ Kafka Connector 支持 Watermark 下推 (FLINK-20041)
为了确保使用 Kafka 的作业的结果的正确性,通常来说,最好基于分区来生成 watermark,因为分区内数据的乱序程度通常来说比分区之间数据的乱序程度要低很多。Flink 现在允许将 watermark 策略下推到 Kafka connector 里面,从而支持在 Kafka connector 内部构造基于分区的 watermark[12]。一个 Kafka source 节点最终所产生的 watermark 由该节点所读取的所有分区中的 watermark 的最小值决定,从而使整个系统可以获得更好的(即更接近真实情况)的 watermark。该功能也允许用户配置基于分区的空闲检测策略,以防止空闲分区阻碍整个作业的 event time 增长。
■ 新增的 Formats

■ 利用 Multi-input 算子进行 Join 优化 (FLINK-19621)
Shuffling 是一个 Flink 作业中最耗时的操作之一。为了消除不必要的序列化反序列化开销、数据 spilling 开销,提升 Table API / SQL 上批作业和流作业的性能, planner 当前会利用上一个版本中已经引入的N元算子(FLIP-92),将由 forward 边所连接的多个算子合并到一个 Task 里执行。
■ Type Inference for Table API UDAFs (FLIP-65)
Flink 1.12 完成了从 Flink 1.9 开始的,针对 Table API 上的新的类型系统[2]的工作,并在聚合函数(UDAF)上支持了新的类型系统。从 Flink 1.12 开始,与标量函数和表函数类似,聚合函数也支持了所有的数据类型。
PyFlink: Python DataStream API
为了扩展 PyFlink 的可用性,Flink 1.12 提供了对于 Python DataStream API(FLIP-130)的初步支持,该版本支持了无状态类型的操作(例如 Map,FlatMap,Filter,KeyBy 等)。如果需要尝试 Python DataStream API,可以安装PyFlink,然后按照该文档[14]进行操作,文档中描述了如何使用 Python DataStream API 构建一个简单的流应用程序。
from pyflink.common.typeinfo import Types
from pyflink.datastream import MapFunction, StreamExecutionEnvironment
class MyMapFunction(MapFunction):def map(self, value):return value + 1
env = StreamExecutionEnvironment.get_execution_environment()
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())
mapped_stream.print()
env.execute("datastream job")
PyFlink 中的其它改进
**■ PyFlink Jobs on Kubernetes (FLINK-17480) ** 除了 standalone 部署和 YARN 部署之外,现在也原生支持将 PyFlink 作业部署在 Kubernetes 上。最新的文档中详细描述了如何在 Kubernetes 上启动 session 或 application 集群。
**■ 用户自定义聚合函数 (UDAFs) ** 从 Flink 1.12 开始,您可以在 PyFlink 作业中定义和使用 Python UDAF 了(FLIP-139)。普通的 UDF(标量函数)每次只能处理一行数据,而 UDAF(聚合函数)则可以处理多行数据,用于计算多行数据的聚合值。您也可以使用 Pandas UDAF[15](FLIP-137),来进行向量化计算(通常来说,比普通 Python UDAF 快10倍以上)。
注意: 普通 Python UDAF,当前仅支持在 group aggregations 以及流模式下使用。如果需要在批模式或者窗口聚合中使用,建议使用 Pandas UDAF。
官方原文:
https://flink-learning.org.cn/article/detail/bdac3583f60a3a6a460b204eacaf3a0c
五 Flink 1.13
这一版本中,Flink 的一个主要目标取得了重要进展,即让流处理应用的使用和普通应用一样简单和自然。Flink 1.13 新引入的被动扩缩容使得流作业的扩缩容和其它应用一样简单,用户仅需要修改并发度即可。
这个版本还包括一系列重要改动使用户可以更好的理解流作业的性能。当流作业的性能不及预期的时候,这些改动可以使用户可以更好的分析原因。这些改动包括用于识别瓶颈节点的负载和反压可视化、分析算子热点代码的 CPU 火焰图和分析 State Backend 状态的 State 访问性能指标。
除了这些特性外,Flink 社区还添加了大量的其它优化,我们会在本文后续讨论其中的一些。我们希望用户可以享受新的版本和特性带来的便利,在本文最后,我们还会介绍升级Flink版本需要注意的一些变化。
5.1 被动扩缩容
Flink 项目的一个初始目标,就是希望流处理应用可以像普通应用一样简单和自然,被动扩缩容是 Flink 针对这一目标上的最新进展。
当考虑资源管理和部分的时候,Flink 有两种可能的模式。用户可以将 Flink 应用部署到 k8s、yarn 等资源管理系统之上,并且由 Flink 主动的来管理资源并按需分配和释放资源。这一模式对于经常改变资源需求的作业和应用非常有用,比如批作业和实时 SQL 查询。在这种模式下,Flink 所启动的 Worker 数量是由应用设置的并发度决定的。在 Flink 中我们将这一模式叫做主动扩缩容。
对于长时间运行的流处理应用,一种更适合的模型是用户只需要将作业像其它的长期运行的服务一样启动起来,而不需要考虑是部署在 k8s、yarn 还是其它的资源管理平台上,并且不需要考虑需要申请的资源的数量。相反,它的规模是由所分配的 worker 数量来决定的。当 worker 数量发生变化时,Flink 自动的改动应用的并发度。在 Flink 中我们将这一模式叫做被动扩缩容。
Flink 的 Application 部署模式开启了使 Flink 作业更接近普通应用(即启动 Flink 作业不需要执行两个独立的步骤来启动集群和提交应用)的努力,而被动扩缩容完成了这一目标:用户不再需要使用额外的工具(如脚本、K8s 算子)来让 worker 的数量与应用并发度设置保持一致。
用户现在可以将自动扩缩容的工具应用到 Flink 应用之上,就像普通的应用程序一样,只要用户了解扩缩容的代价:有状态的流应用在扩缩容的时候需要将状态重新分发。
如果想要尝试被动扩缩容,用户可以增加 scheduler-mode: reactive 这一配置项,然后启动一个应用集群(Standalone 或者 K8s)。更多细节见 被动扩缩容的文档 。
5.2 分析应用的性能
对所有应用程序来说,能够简单的分析和理解应用的性能是非常关键的功能。这一功能对 Flink 更加重要,因为 Flink 应用一般是数据密集的(即需要处理大量的数据)并且需要在(近)实时的延迟内给出结果。
当 Flink 应用处理的速度跟不上数据输入的速度时,或者当一个应用占用的资源超过预期,下文介绍的这些工具可以帮你分析原因。
5.2.1 瓶颈检测与反压监控
Flink 性能分析首先要解决的问题经常是:哪个算子是瓶颈?
为了回答这一问题,Flink 引入了描述作业繁忙(即在处理数据)与反压(由于下游算子不能及时处理结果而无法继续输出)程度的指标。应用中可能的瓶颈是那些繁忙并且上游被反压的算子。
Flink 1.13 优化了反压检测的逻辑(使用基于任务 Mailbox 计时,而不在再于堆栈采样),并且重新实现了作业图的 UI 展示:Flink 现在在 UI 上通过颜色和数值来展示繁忙和反压的程度。

5.2.2 Web UI 中的 CPU 火焰图
Flink 关于性能另一个经常需要回答的问题:瓶颈算子中的哪部分计算逻辑消耗巨大?
针对这一问题,一个有效的可视化工具是火焰图。它可以帮助回答以下问题:
哪个方法调现在在占用 CPU?
不同方法占用 CPU 的比例如何?
一个方法被调用的栈是什么样子的?
火焰图是通过重复采样线程的堆栈来构建的。在火焰图中,每个方法调用被表示为一个矩形,矩形的长度与这个方法出现在采样中的次数成正比。火焰图在 UI 上的一个例子如下图所示。

火焰图的文档 包括启用这一功能的更多细节和指令。
5.2.3 State 访问延迟指标
另一个可能的性能瓶颈是 state backend,尤其是当作业的 state 超过内存容量而必须使用 RocksDB state backend 时。
这里并不是想说 RocksDB 性能不够好(我们非常喜欢 RocksDB!),但是它需要满足一些条件才能达到最好的性能。例如,用户可能很容易遇到非故意的在云上由于使用了错误的磁盘资源类型而不能满足 RockDB 的 IO 性能需求的问题。
基于 CPU 火焰图,新的 State Backend 的延迟指标可以帮助用户更好的判断性能不符合预期是否是由 State Backend 导致的。例如,如果用户发现 RocksDB 的单次访问需要几毫秒的时间,那么就需要查看内存和 I/O 的配置。这些指标可以通过设置 state.backend.rocksdb.latency-track-enabled 这一选项来启用。这些指标是通过采样的方式来监控性能的,所以它们对 RocksDB State Backend 的性能影响是微不足道的。
5.3 通过 Savepoint 来切换 State Backend
用户现在可以在从一个 Savepoint 重启时切换一个 Flink 应用的 State Backend。这使得 Flink 应用不再被限制只能使用应用首次运行时选择的 State Backend。
基于这一功能,用户现在可以首先使用一个 HashMap State Backend(纯内存的 State Backend),如果后续状态变得过大的话,就切换到 RocksDB State Backend 中。
在实现层,Flink 现在统一了所有 State Backend 的 Savepoint 格式来实现这一功能。
5.4 K8s 部署时使用用户指定的 Pod 模式
原生 kubernetes 部署(Flink 主动要求 K8s 来启动 Pod)中,现在可以使用自定义的 Pod 模板。
使用这些模板,用户可以使用一种更符合 K8s 的方式来设置 JM 和 TM 的 Pod,这种方式比 Flink K8s 集成内置的配置项更加灵活。
5.5 生产可用的 Unaligned Checkpoint
Unaligned Checkpoint 目前已达到了生产可用的状态,我们鼓励用户在存在反压的情况下试用这一功能。
具体来说,Flink 1.13 中引入的这些功能使 Unaligned Checkpoint 更容易使用:
- 用户现在使用 Unaligned Checkpoint 时也可以扩缩容应用。如果用户需要因为性能原因不能使用 Savepoint而必须使用 Retained checkpoint 时,这一功能会非常方便。
- 对于没有反压的应用,启用 Unaligned Checkpoint 现在代价更小。Unaligned Checkpoint 现在可以通过超时来自动触发,即一个应用默认会使用 Aligned Checkpoint(不存储传输中的数据),而只在对齐超过一定时间范围时自动切换到 Unaligned Checkpoint(存储传输中的数据)。
关于如何启用 Unaligned Checkpoint 可以参考相关文档。
5.6 SQL / Table API 进展
与之前的版本类似,SQL 和 Table API 仍然在所有开发中占用很大的比例
5.6.1 通过 Table-valued 函数来定义时间窗口
在流式 SQL 查询中,一个最经常使用的是定义时间窗口。Flink 1.13 中引入了一种新的定义窗口的方式:通过 Table-valued 函数。这一方式不仅有更强的表达能力(允许用户定义新的窗口类型),并且与 SQL 标准更加一致。
Flink 1.13 在新的语法中支持 TUMBLE 和 HOP 窗口,在后续版本中也会支持 SESSION 窗口。我们通过以下两个例子来展示这一方法的表达能力:
- 例 1:一个新引入的 CUMULATE 窗口函数,它可以支持按特定步长扩展的窗口,直到达到最大窗口大小:
SELECT window_time, window_start, window_end, SUM(price) AS total_price FROM TABLE(CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end, window_time;- 例 2:用户在 table-valued 窗口函数中可以访问窗口的起始和终止时间,从而使用户可以实现新的功能。例如,除了常规的基于窗口的聚合和 Join 之外,用户现在也可以实现基于窗口的 Top-K 聚合:
SELECT window_time, ...FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY total_price DESC) as rank FROM t) WHERE rank <= 100;
5.6.2 提高 DataStream API 与 Table API / SQL 的互操作能力
这一版本极大的简化了 DataStream API 与 Table API 混合的程序。
Table API 是一种非常方便的应用开发接口,因为这经支持表达式的程序编写并提供了大量的内置函数。但是有时候用户也需要切换回 DataStream,例如当用户存在表达能力、灵活性或者 State 访问的需求时。
Flink 新引入的 StreamTableEnvironment.toDataStream()/.fromDataStream() 可以将一个 DataStream API 声明的 Source 或者 Sink 当作 Table 的 Source 或者 Sink 来使用。主要的优化包括:
- DataStream 与 Table API 类型系统的自动转换。
- Event Time 配置的无缝集成,Watermark 行为的高度一致性。
- Row 类型(即 Table API 中数据的表示)有了极大的增强,包括 toString() / hashCode() 和 equals() 方法的优化,按名称访问字段值的支持与稀疏表示的支持。
Table table = tableEnv.fromDataStream(dataStream,Schema.newBuilder().columnByMetadata("rowtime", "TIMESTAMP(3)").watermark("rowtime", "SOURCE_WATERMARK()").build());DataStream<Row> dataStream = tableEnv.toDataStream(table).keyBy(r -> r.getField("user")).window(...);
5.6.3 SQL Client: 初始化脚本和语句集合 (Statement Sets)
SQL Client 是一种直接运行和部署 SQL 流或批作业的简便方式,用户不需要编写代码就可以从命令行调用 SQL,或者作为 CI / CD 流程的一部分。
这个版本极大的提高了 SQL Client 的功能。现在基于所有通过 Java 编程(即通过编程的方式调用 TableEnvironment 来发起查询)可以支持的语法,现在 SQL Client 和 SQL 脚本都可以支持。这意味着 SQL 用户不再需要添加胶水代码来部署他们的SQL作业。
3.1 配置简化和代码共享
Flink 后续将不再支持通过 Yaml 的方式来配置 SQL Client(注:目前还在支持,但是已经被标记为废弃)。作为替代,SQL Client 现在支持使用一个初始化脚本在主 SQL 脚本执行前来配置环境。
这些初始化脚本通常可以在不同团队/部署之间共享。它可以用来加载常用的 catalog,应用通用的配置或者定义标准的视图。
./sql-client.sh -i init1.sql init2.sql -f sqljob.sql
3.2 更多的配置项
通过增加配置项,优化 SET / RESET 命令,用户可以更方便的在 SQL Client 和 SQL 脚本内部来控制执行的流程。
3.3 通过语句集合来支持多查询
多查询允许用户在一个 Flink 作业中执行多个 SQL 查询(或者语句)。这对于长期运行的流式 SQL 查询非常有用。
语句集可以用来将一组查询合并为一组同时执行。
以下是一个可以通过 SQL Client 来执行的 SQL 脚本的例子。它初始化和配置了执行多查询的环境。这一脚本包括了所有的查询和所有的环境初始化和配置的工作,从而使它可以作为一个自包含的部署组件。
-- set up a catalog
CREATE CATALOG hive_catalog WITH ('type' = 'hive');
USE CATALOG hive_catalog;-- or use temporary objects
CREATE TEMPORARY TABLE clicks (user_id BIGINT,page_id BIGINT,viewtime TIMESTAMP
) WITH ('connector' = 'kafka','topic' = 'clicks','properties.bootstrap.servers' = '...','format' = 'avro'
);-- set the execution mode for jobs
SET execution.runtime-mode=streaming;-- set the sync/async mode for INSERT INTOs
SET table.dml-sync=false;-- set the job's parallelism
SET parallism.default=10;-- set the job name
SET pipeline.name = my_flink_job;-- restore state from the specific savepoint path
SET execution.savepoint.path=/tmp/flink-savepoints/savepoint-bb0dab;BEGIN STATEMENT SET;INSERT INTO pageview_pv_sink
SELECT page_id, count(1) FROM clicks GROUP BY page_id;INSERT INTO pageview_uv_sink
SELECT page_id, count(distinct user_id) FROM clicks GROUP BY page_id;END;
5.6.4 Hive 查询语法兼容性
用户现在在 Flink 上也可以使用 Hive SQL 语法。除了 Hive DDL 方言之外,Flink现在也支持常用的 Hive DML 和 DQL 方言。
为了使用 Hive SQL 方言,需要设置 table.sql-dialect 为 hive 并且加载 HiveModule。后者非常重要,因为必须要加载 Hive 的内置函数后才能正确实现对 Hive 语法和语义的兼容性。例子如下:
CREATE CATALOG myhive WITH ('type' = 'hive'); -- setup HiveCatalog
USE CATALOG myhive;
LOAD MODULE hive; -- setup HiveModule
USE MODULES hive,core;
SET table.sql-dialect = hive; -- enable Hive dialect
SELECT key, value FROM src CLUSTER BY key; -- run some Hive queries
需要注意的是, Hive 方言中不再支持 Flink 语法的 DML 和 DQL 语句。如果要使用 Flink 语法,需要切换回 default 的方言配置。
5.6.5 优化的 SQL 时间函数
在数据处理中时间处理是一个重要的任务。但是与此同时,处理不同的时区、日期和时间是一个日益复杂的任务。
在 Flink 1.13 中,我们投入了大量的精力来简化时间函数的使用。我们调整了时间相关函数的返回类型使其更加精确,例如 PROCTIME(),CURRENT_TIMESTAMP() 和 NOW()。
其次,用户现在还可以基于一个 TIMESTAMP_LTZ 类型的列来定义 Event Time 属性,从而可以优雅的在窗口处理中支持夏令时。
用户可以参考 Release Note 来查看该部分的完整变更。
5.7 其它优化
-
基于 Hugo 的 Flink 文档
Flink 文档从 JekyII 迁移到了 Hugo。如果您发现有问题,请务必通知我们,我们非常期待用户对新的界面的感受。 -
Web UI 支持历史异常
Flink Web UI 现在可以展示导致作业失败的 n 次历史异常,从而提升在一个异常导致多个后续异常的场景下的调试体验。用户可以在异常历史中找到根异常。 -
优化失败 Checkpoint 的异常和失败原因的汇报
Flink 现在提供了失败或被取消的 Checkpoint 的统计,从而使用户可以更简单的判断 Checkpoint 失败的原因,而不需要去查看日志。
Flink 之前的版本只有在 Checkpoint 成功的时候才会汇报指标(例如持久化数据的大小、触发时间等)。
- 提供『恰好一次』一致性的 JDBC Sink
从 1.13 开始,通过使用事务提交数据,JDBC Sink 可以对支持 XA 事务的数据库提供『恰好一次』的一致性支持。这一特性要求目标数据库必须有(或链接到)一个 XA 事务处理器。
这一 Sink 现在只能在 DataStream API 中使用。用户可以通过 JdbcSink.exactlyOnceSink(…) 来创建这一 Sink(或者通过显式初始化一个 JdbcXaSinkFunction)。
- PyFlink Table API 在 Group 窗口上支持用户自定义的聚合函数
PyFlink Table API 现在对 Group 窗口同时支持基于 Python 的用户自定义聚合函数(User-defined Aggregate Functions, UDAFs)以及 Pandas UDAFs。这些函数对许多数据分析或机器学习训练的程序非常重要。
在 Flink 1.13 之前,这些函数仅能在无限的 Group-by 聚合场景下使用。Flink 1.13 优化了这一限制。
- Batch 执行模式下 Sort-merge Shuffle 优化
Flink 1.13 优化了针对批处理程序的 Sort-merge Blocking Shuffle 的性能和内存占用情况。这一 Shuffle 模式是在Flink 1.12 的 FLIP-148 中引入的。
这一优化避免了大规模作业下不断出现 OutOfMemoryError: Direct Memory 的问题,并且通过 I/O 调度和 broadcast 优化提高了性能(尤其是在机械硬盘上)。
- HBase 连接器支持异步维表查询和查询缓存
HBase Lookup Table Source 现在可以支持异步查询模式和查询缓存。这极大的提高了使用这一 Source 的 Table / SQL 维表 Join 的性能,并且在一些典型情况下可以减少对 HBase 的 I/O 请求数量。
在之前的版本中,HBase Lookup Source 仅支持同步通信,从而导致作业吞吐以及资源利用率降低。
参考原文
官方原文:
https://flink-learning.org.cn/article/detail/b7c5081a7e8f964a9c856e26eca3369f
六 Flink 1.14
新版本在 SQL API、更多连接器支持、Checkpoint 机制、PyFlink 等多个方面带来了大量的新特性与改进。其中一个主要的改进是针对流批一体的使用体验。我们相信,在实践中,对无界的数据流的处理与对有界的批数据的处理是密不可分的,因为很多场景都需要在处理实时数据流的同时处理来自各种数据源的历史数据。例如开发新应用时的数据探索、新应用的状态初始化、用于流式应用的训练模型、升级或修复后的数据重处理等。
在 Flink 1.14 中,我们终于可以在同一个应用当中混合使用有界流和无界流:Flink 现在支持对部分运行、部分结束的应用(部分算子已处理到有界输入数据流的末端)做 Checkpoint。此外,Flink 在处理到有界数据流末端时会触发最终 Checkpoint,以确保所有计算结果顺利提交到 Sink。
批执行模式现在支持在同一应用中混合使用 DataStream API 和 SQL/Table API(此前仅支持单独使用 DataStream API 或 SQL/Table API)。
我们更新了统一的 Source 和 Sink API,并已开始围绕统一的 API 整合连接器生态。我们新增了混合 Source 可在多个存储系统间过渡。你现在可以实现诸如先从 Amazon S3 中读取旧的数据再无缝切换到 Apache Kafka 这样的处理。
此外,这一版本朝着我们将 Flink 打造得更加自调易用、无需大量流处理特定知识的目标又迈进了一步。作为向此目标迈出的第一步,我们在上个版本中引入了被动弹性伸缩模式。现在,我们又新增了对网络内存的自动调整(即缓冲区去膨胀)。这一特性能在保持高吞吐、不增加 Checkpoint 大小的前提下,加速高负载时的Checkpoint。该机制通过不断调整网络缓冲区的大小,能够以最少的缓冲数据达到最佳的吞吐效率。更多详情请参考缓冲区去膨胀章节。
新版本中有许多来自各个组件的新特性与改进,我们将在下文介绍。与此同时,我们也告别了一些在最近的版本中逐渐被取代、废弃的组件和功能。最具代表性的是,新版本中移除了旧版 SQL 查询引擎和对 Apache Mesos 的集成。
6.1 批流一体
Flink 的一个独特之处是其对流和批处理的统一:使用同一套 API、同一个可支持多种执行范式的运行时。
正如在前文中提到的,我们相信流处理和批处理是密不可分的。下面这段话来自一份关于 Facebook 流式数据处理的报告,很好地呼应了这一观点。
流处理与批处理并不是非此即彼的选择。最初,Facebook 所有数据仓库的处理都是批处理。我们在大约 5 年前开始研发 Puma 和 Swift。混合使用流处理和批处理能够为较长的处理流程节约数个小时。
利用同一引擎处理实时和历史数据还可以确保语义的一致性,使结果具有更好的可比性。这里有一篇关于阿里巴巴使用 Apache Flink 生成统一的、一致的业务报告的文章。
此前的版本已经可以实现流批一体的数据处理。新版本在这方面增加了针对更多使用场景的新特性,以及一系列使用体验的改进。
有界流 Checkpoint 机制
Flink 的 Checkpoint 机制原本只支持在应用 DAG 中的所有任务都处于运行状态时创建 Checkpoint。这意味着让应用同时读取有界和无界数据源在实质上是不可能的。此外,以流式(而非批式)处理有界输入数据的应用,在数据将要处理完、部分任务结束时将不再做 Checkpoint。这使得最后一部分输出数据无法被提交到要求精确一次语义的 Sink 中,造成业务延迟。
Flink 支持在部分任务结束后创建 Checkpoint,以及在有界流处理结束后触发最终 Checkpoint 以确保在作业结束时将所有输出结果提交到 Sink(与 stop-with-savepoint 类似)。
该特性可通过在配置中添加 execution.checkpointing.checkpoints-after-tasks-finish.enabled: true 启用。出于让用户自主选择并试用重大新特性的传统,这一特性在 Flink 1.14 中没有默认启用。我们希望在下个版本中将其作为默认模式。
背景:处理有界数据时,尽管人们通常倾向于使用批处理模式,仍有一些情况需要用到流处理模式。例如,Sink 可能只支持流模式(即 Kafka Sink),或者应用希望尽量发挥流处理固有的近时间排序特性(例如 Kappa+ 架构)。
DataStream 和 Table/SQL 混合应用的批执行模式
SQL 和 Table API 正在成为新项目的默认起点,其天然的声明式特点和丰富的内置类型与操作使应用开发变得简单快速。然而,开发人员遇到一些特定的、事件驱动的业务逻辑,SQL 的表达能力无法满足(或不适合强行用 SQL 来表达)的情况也并不罕见。
此时,自然的做法是插入一段有状态的 DataStream API 描述的逻辑,再切换回 SQL。
在 Flink 1.14 中,有界的批执行模式的 SQL/Table 应用可将其中间数据表转换成数据流,经过由 DataStream API 定义的算子处理,再转换回数据表。其内部原理是,Flink 构建了一个由优化的声明式 SQL执行和 DataStream 批执行混合而成的数据流 DAG。详见相关文档。
混合 Source
全新的混合 Source 能够依次地从多个数据源读取数据,在不同数据源之间无缝切换,产出一条由来自多个数据源的数据合并而成的数据流。
混合 Source 针对的是从分层存储中读取数据的场景,相当于从一条跨越所有层级的数据流读取数据。例如,将新数据灌入 Kafka,并最终迁移至 S3(出于成本与效率的考量这通常是压缩的列存格式)。混合 Source 可以像读取一条连续的逻辑数据流一样,先从 S3 读取历史数据,然后转换到 Kafka 读取最新的数据。

我们相信这是向着实现日志与 Kappa 架构完整前景的令人兴奋的一步。即使事件日志的陈旧部分在物理上被迁移到了不同的存储(出于成本、压缩效率、读取速度等原因),你仍可以将其视作连续的日志处理。
Flink 1.14 加入了混合 Source 的核心功能。在后续的版本中,我们希望加入更多针对典型切换策略的工具与模式。
整合 Source 和 Sink
随着新的流批统一的 Source 和 Sink API 变得稳定,我们开始了围绕这些 API 整合所有连接器的巨大努力。与此同时,我们也会让 DataStream 和 SQL / Table API 上的连接器更好地对齐,首先是DataStream API 上的 Kafka 和文件 Source、Sink。
伴随着这一努力(预计仍将持续 1-2 个版本),Flink 用户在连接外部系统时将获得更加流畅、一致的体验
6.2 运维改进
6.2.1 缓冲区去膨胀
缓冲区去膨胀是 Flink 中的一项新技术,可以最小化 Checkpoint 的延迟和开销。它通过自动调整网络内存的用量,在确保高吞吐的同时最小化缓冲区中的数据量。
Apache Flink 在其网络栈中缓冲了一定量的数据,以便有效利用快速网络的高带宽。Flink 应用以高吞吐运行时,会使用部分(或全部)网络缓冲内存。对齐的 Checkpoint 随着数据在毫秒级的时间内流过网络缓冲区。
当 Flink 应用出现(暂时的)反压时(例如外部系统反压或遇到数据倾斜),往往会导致网络缓冲区中存放了相对应用当前吞吐(因反压而降低)所需的带宽过多的数据。更加不利的是,缓冲的数据越多意味着 Checkpoint 机制需要做越多的工作。对齐的 Checkpoint 需要等待更多的数据得到处理,非对齐的 Checkpoint 则需要持久化更多排队中的数据。
这就轮到缓冲区去膨胀登场了。它将网络栈从持有最多 X 字节的数据改为持有需要接收端 X 毫秒计算时间处理的数据。默认值是 1000 毫秒,意味着网络栈会缓冲下游任务 1000 毫秒所能处理的数据量。通过持续的测量和调整,系统能够在不断变化的情况下保持这一特性。因此,Flink 对齐式 Checkpoint 具备了稳定的、可预测的对齐时间,反压时存放在非对齐式 Checkpoint中的数据量也极大程度减少了。
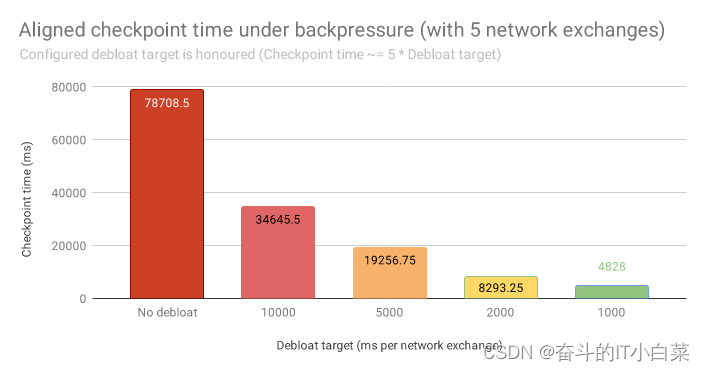
缓冲区去膨胀可以作为非对齐式 Checkpoint 的补充,甚至是替代选择。关于如何启用该特性,请参考文档。
6.2.2 细粒度资源管理
细粒度资源管理是一项新的高级功能,用于提高大型共享集群的资源利用率。
Flink 集群执行多种多样的数据处理工作负载。不同的数据处理步骤通常需要不同的资源,如计算资源、内存等。例如,大多数映射函数都比较轻量,而较大的、保留时间较长的窗口函数往往受益于大量内存。默认情况下,Flink 以粗粒度的 Slot 管理资源,一个 Slot 代表 TaskManager 的一个资源切片。一个 Slot 可以存放流式处理流程中每个算子的一个并发子任务实例,即一个 Slot 可持有一整条处理流程的并发子任务实例。通过 Slot Sharing Group,用户可以影响子任务在 Slot 上的分布。
有了细粒度资源管理,TaskManager 上的 Slot 可以动态改变大小。转换和算子指定所需的资源配置(CPU、内存、磁盘等),由 Flink 的 ResourceManager 和 TaskManager 负责从 TaskManager 的总资源中划分出指定大小的资源切片。你可以将这看做是 Flink 中的一层最小化、轻量化的资源编排。下图展示了细粒度资源管理与目前默认的共享固定大小 Slot 资源管理方式的区别。

你可能会问,Flink 已经集成了 Kubernetes、Yarn 等成熟的资源编排框架,为什么还要增加这样一个新特性?有几种情况,在 Flink 内部增加一层资源管理可以显著提高资源利用率:
-
当 Slot 比较小时,为每个 Slot 专门申请 TaskManager 的代价是非常高的(JVM 开销、Flink 框架开销等)。Slot Sharing 通过让不同类型的算子共享 Slot,即在轻量的算子(需要较小的 Slot)和重量的算子(需要较大的 Slot)间共享资源,在一定程度上解决了这个问题。然而,这仅在所有算子的并发度相同时有较好的效果,并非总是最优的。此外,有些算子更适合单独运行(例如机器学习中负责训练的算子需要专用的 GPU资源)。
-
Kubernetes 和 Yarn 往往需要花费一段时间来满足资源请求,特别是在集群负载较高时。对于一些批处理作业,等待资源的时间会降低作业的执行效率。
那么什么时候应该启用这一特性呢?默认的资源管理机制适用于大多数流处理和批处理作业。如果你的作业是长时间运行的流作业或快速的批作业,其不同处理阶段需要的资源差异明显,且你已经为不同算子设置了不同的并发度,那么你可以尝试用细粒度资源管理提高资源效率。
阿里巴巴内部基于 Flink 的平台已经应用这种机制有一段时间了,在实践中集群资源利用率有着显著的提高。
参考原文
官方原文:
https://flink-learning.org.cn/article/detail/e9f4182d65bc9f5e8701be8510123381
七 Flink 1.15
在 1.15 版本中,Apache Flink 社区在上述这些方面都取得了重大进展:
-
1.15 版本的一大看点是改进了运维 Apache Flink 的体验:包括明确 Checkpoint 和 Savepoint 在不同作业之间的所属权,简化 Checkpoint 和 Savepoint 生命周期管理;更加无缝支持完整的自动伸缩;通过 Watermark 对齐来消除多个数据源速率不同带来的问题等
-
1.15 版本中,Flink 进一步完善流批一体的体验:继续完善部分作业完成后的 Checkpoint 操作;支持批模式下的 Window table-valued 函数,并且使其在流批混合的场景下更加易用。
-
Flink SQL 的进阶:包括能够在不丢失状态的情况下升级 SQL 作业;添加了对 JSON 相关函数的支持来简化数据的输入与输出操作。
-
Flink 作为整个数据处理生态中的一环,1.15 版本进一步提升了与云服务的交互操作性,并且添加了更多的 Sink 连接器与数据格式。最后,我们在运行时中去除了对 Scala 的依赖[2]。
总结
Apache Flink 简化了运维操作,在对齐流批处理功能取得进一步进展,改进了 SQL 组件使其变得更易于使用,并且现在可以更好地与其他系统进行集成。
同值得一提的是社区为 CDC 连接器[33] 建立了一个新家。同时,连接器相关代码[34] 将被移动到 Flink 外一个单独的仓库中 (以 Elasticsearch Sink 作业第一个例子[35] )。此外,现在社区新增了一个由社区维护的关于 K8s Operator[36] 的公告博客[37]。
展望未来,社区将继续专注于使 Apache Flink 成为真正的流批一体处理系统,并致力于将 Flink 更好地集成到云原生生态系统中。
参考原文
官方原文:
https://flink-learning.org.cn/article/detail/d90996fd6ec738d44f73ba58c3ad82ee
八 Flink 1.16
在批处理方面,完成了易用性、稳定性、性能全方位的改进,1.16 是 Fink 批处理的里程碑式的版本,是走向成熟的重要一步。
易用性:引入 SQL Gateway 并完全兼容 HiveServer2,用户可以非常方便的提交 Flink SQL 作业和 Hive SQL 作业,同时也很容易连接到原有的 Hive 生态。
功能:Flink SQL 用户支持通过 Join Hint 指定 Join 策略,避免不合理的执行计划;Hive SQL 的兼容性已经达到 94%,用户可以以极低的成本完成 Hive 到 Flink 的迁移。
稳定性:通过预测执行减少作业长尾以提高作业整体运行稳定性;支持自适应 HashJoin,通过失败回滚机制避免作业失败。
性能:对多分区表进行动态分区裁剪以提高处理效率,TPC-DS 在 10TB 规模数据集下性能提升了 30%;支持混合 Shuffle 模式,提高资源使用率和处理性能。
在流处理方面,也完成了很多重大改进:
Changelog State Backend 可以为用户提供秒级甚至毫秒级 Checkpoint,从而大幅提升容错体验,同时为事务性 Sink 作业提供更小的端到端延迟体验。
维表关联在流处理中广泛被使用,引入了通用的缓存机制加快维表查询速度,引入了可配置的异步模式提升维表查询吞吐,引入可重试查询机制解决维表延迟更新问题。这些功能都非常实用,解决了用户经常抱怨的痛点,支持了更丰富的场景。
从 Flink SQL 诞生第一天就存在一些非确定性操作可能导致用户作业出现错误结果或作业运行异常,这给用户带来了极大的困扰。1.16 里我们花了很多大精力解决了大部分问题,未来还会持续改进。
随着流批一体的进一步完善和 Flink Table Store 的不断迭代(0.2版本已发布[3]),Flink 社区正一步一步推动 Streaming Warehouse 从概念变为现实并走向成熟。
官方原文:
https://flink-learning.org.cn/article/detail/ccb3b222e0c4eb8ce3312c94b3d4bf0a
九 Flink 1.17
针对批处理,此次发布包含了下述几项新特性和改进。
-
Streaming Warehouse API: FLIP-282 在 Flink SQL 中引入了新的 Delete 和 Update API,它们可以在 Batch 模式下工作。在此基础上,外部存储系统比如 Flink Table Store 可以通过这些新的 API 实现行级删除和更新。同时对 ALTER TABLE 语法进行了增强,包括 ADD/MODIFY/DROP 列、主键和 watermark 的能力,这些增强使得用户更容易维护元数据。
-
Batch 性能优化: 在 Flink 1.17 中,批处理作业的执行在性能、稳定性和可用性方面都得到了显着改进。就性能而言,通过策略优化和算子优化,如新的 join-reorder 算法和自适应的本地哈希聚合优化、Hive 聚合函数改进以及混合 shuffle 模式优化,这些改进带来了 26% 的 TPC-DS 性能提升。就稳定性而言,Flink 1.17 预测执行可以支持所有算子,自适应的批处理调度可以更好的应对数据倾斜场景。就可用性而言,批处理作业所需的调优工作已经大大减少。自适应的批处理调度已经默认开启,混合 shuffle 模式现在可以兼容预测执行和自适应批处理调度,同时所需的各种配置都进行了简化。
-
SQL Client/Gateway: Apache Flink 1.17 支持了 SQL Client 的 gateway 模式,允许用户将 SQL 提交给远端的 SQL Gateway。同时,用户可以在 SQL Client 中使用 SQL 语句来管理作业,包括查询作业信息和停止正在运行的作业等。这表示 SQL Client/Gateway 已经演进为一个作业管理、提交工具。
针对流处理,Flink 1.17 完成了以下功能和改进:
-
Streaming SQL 语义增强: 非确定性操作可能会导致不正确的结果或异常,这在 Streaming SQL 中是一个极具挑战性的话题。Flink 1.17 修复了不正确的优化计划和功能问题,并且引入了实验性功能 PLAN_ADVICE,PLAN_ADVICE 可以为 SQL 用户提供潜在的正确性风险提示和 SQL 优化建议。
-
Checkpoint 改进: 通用增量 Checkpoint(GIC)增强了 Checkpoint 的速度和稳定性,Unaligned Checkpoint (UC) 在作业反压时的稳定性也在 Flink 1.17 中提高至生产可用级别。此外,该版本新引入一个 REST API 使得用户可以触发自定义 Checkpoint 类型的 Checkpoint。
-
Watermark 对齐完善: 高效的 watermark 处理直接影响 event time 作业的执行效率,在 Flink 1.17 中, FLIP-217 通过对 Source 算子内部的 split 进行数据对齐发射,完善了 watermark 对齐功能。这一改进使得 Source 中 watermark 进度更加协调,从而减轻了下游算子的缓存过多数据,增强了流作业执行的整体效率。
-
StateBackend 升级: 此次发布将 FRocksDB 的版本升级到了 6.20.3-ververica-2.0,对 RocksDBStateBackend 带来了许多改进。同时,例如在插槽之间共享内存,并且现在支持 Apple Silicon 芯片组,如 Mac M1。Flink 1.17 版本还提供了参数扩大 TaskManager 的 slot 之间共享内存的范围,提升了 TaskManager 中 slot 内存使用不均是的效率。
其他
PyFlink
在 Flink 1.17 中,PyFlink 也完成了若干功能,PyFlink 是 Apache Flink 的 Python 语言接口。PyFlink 中,一些比较重要的改进包括支持 Python 3.10、支持在 Mac M1 和 M2 电脑上运行 PyFlink 等。此外,在该版本中还完成了一些小的功能优化,比如改进了 Java 和 Python 进程之间的跨进程通信的稳定性、支持以字符串的方式声明 Python UDF 的结果类型、支持在 Python UDF 中访问作业参数等。总体来说,该版本主要专注于改进 PyFlink 的易用性,而不是引入一些新的功能,期望通过这些易用性改进,改善用户的使用体验,使得用户可以更高效地进行数据处理。
性能监控 Benchmark
这个版本周期中,我们也在 Slack 频道( #flink-dev-benchmarks )中加入了性能日常监控汇报来帮助开发者快速发现性能回退问题,这对代码质量保证非常有意义。 通过 Slack 频道或 Speed Center 发现性能回退后,开发者可以按照 Benchmark’s wiki 中方式处理它。
Task 级别火焰图
从 Flink 1.17 版本开始,Flame Graph 功能提供了针对 task 级别的可视化支持,使得用户可以更详细地了解各个 task 的性能。该功能是相比于之前版本的 Flame Graph 的重大改进,因为它可以让用户选择感兴趣的 subtask 并查看相应的火焰图。通过这种方式,用户可以确定任务可能出现性能问题的具体区域,然后采取措施加以解决。这可以显著提高用户数据处理管道的整体效率。

通用的令牌机制
在 Flink 1.17 之前,Flink 只支持 Kerberos 认证和基于 Hadoop 的令牌。随着 FLIP-272 的实现,Flink 的委托令牌框架更加通用,使其认证协议不再局限于 Hadoop。这将允许贡献者在未来可以添加对非 Hadoop 框架的支持,这些框架的认证协议可以不用基于 Kerberos。此外, FLIP-211 改进了 Flink 与 Kerberos 的交互,减少了在 Flink 中交换委托令牌所需的请求数量。
参考原文
官方原文:
https://flink-learning.org.cn/article/detail/d6760c304235557a61f94c88c1a04f17
Flink 2.0 规划
明年是 Flink 作为 Apache 项目的第十年。Flink 于 2014 年 4 月加入 Apache 孵化器,并于 2014 年 12 月成为顶级项目。2024 年将是发布 2.0 版本的完美时机。
我们在 2.0 版本中应该关注什么?
- 路线图讨论:我们如何在现在和未来定义和定位 Flink?我相信很多人对此有所思考,但我们还没有在社区明确地讨论和对齐这方面的想法。理想情况下,2.0 版本应该是路线图讨论的一个结果。
- 非兼容性改动:涉及打破 API 向后兼容性的重要改进、错误修复、技术债务,这只能在主要版本中进行。
在具有 API 非兼容性改动的情况下,我们可能需要多个 2.0-alpha/beta 版本来收集反馈。 - 核心的新特性:重要的新功能和改进(例如,新的用户故事、架构升级),它们可能会改变用户使用 Flink 的方式以及 Flink 在行业中的定位。其中一些也可能涉及非兼容性改动或重大的行为变化。
- 也有一些观点认为,我们应该尽可能地将精力只集中在非兼容性改动上。增量的、兼容性的改进和功能,或任何可以添加到 2.x 小版本中的内容,都不应该阻碍 2.0 版本的发布。