经过2023年的发展,大语言模型展示出了非常大的潜力,训练越来越大的模型成为有效性评估的一个关键指标,论文《A Comparative Analysis of Fine-Tuned LLMs and Few-Shot Learning of LLMs for Financial Sentiment Analysis》中,作者全面分析了微调大语言模型(llm)及其在金融情绪分析中的零样本和少样本的能力。
作者通过使用两种方法来探索金融情绪分析背景下的潜力和适用性:
- 在特定的领域(金融领域)的数据集上,使用小语言模型进行微调,作者测试了250M到3B参数各种模型
- 以gpt-3.5 turbo为重点的情境学习
作者还将结果与SOTA(最先进的)模型进行比较以评估其性能,我们看看小模型是否还同样有效。
论文证明了以下观点:
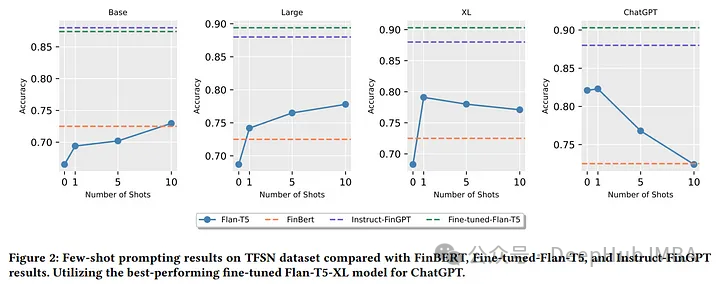
- 微调较小的llm可以达到与SOTA微调llm相当的性能。
- 零样本和少样本学习的的性能与经过微调的小型llm相当。
- 增加上下文学习中的样本数量并不一定会提高情感分析任务的性能。
- 微调较小的llm会降低成本和提高计算效率。
作者专注于使用QLoRa (Quantized low - rank - adaptive)机制对FLAN-T5模型进行微调。使用财务特定数据集,研究了3种尺寸:Flan-T5 base (250M), Flan-T5 large (780M)和Flan-T5-xl (3B参数)。
https://avoid.overfit.cn/post/c9d9a74fd94444189283a1b3d31f6b28
标签:微调,语言,模型,T5,样本,特定,llm,Flan From: https://www.cnblogs.com/deephub/p/17979294