Mixtral-8x7B是最好的开放大型语言模型(LLM)之一,但它是一个具有46.7B参数的庞大模型。即使量化为4位,该模型也无法在消费级GPU上完全加载(例如,24 GB VRAM是不够的)。
Mixtral-8x7B是混合专家(MoE)。它由8个专家子网组成,每个子网有60亿个参数。8位专家中只有2位在解码期间有效,因此可以将其余6位专家移动或卸载到另一个设备,例如CPU RAM,可以释放一些GPU VRAM。但在实践中这种操作是非常复杂的。
选择激活哪个专家是在对每个输入令牌和模型的每个层进行推理时做出的决定。如果暴力的将模型的某些部分移到CPU RAM中,会在CPU和GPU之间造成通信瓶颈。
Mixtral-offloading提出了一个更有效的解决方案,以减少VRAM消耗,同时保持合理的推理速度。
在本文中,我将解释Mixtral-offloading的工作过程,使用这个框架可以节省内存并保持良好的推理速度,我们将看到如何在消费者硬件上运行Mixtral-8x7B,并对其推理速度进行基准测试。
缓存和Speculative Offloading
MoE语言模型通常为子任务分配不同的专家,但在长标记序列上的专家并不唯一。一些专家在短的2-4个令牌序列中激活,而另一些专家则在剩下的令牌激活。下图可以看到这一点:
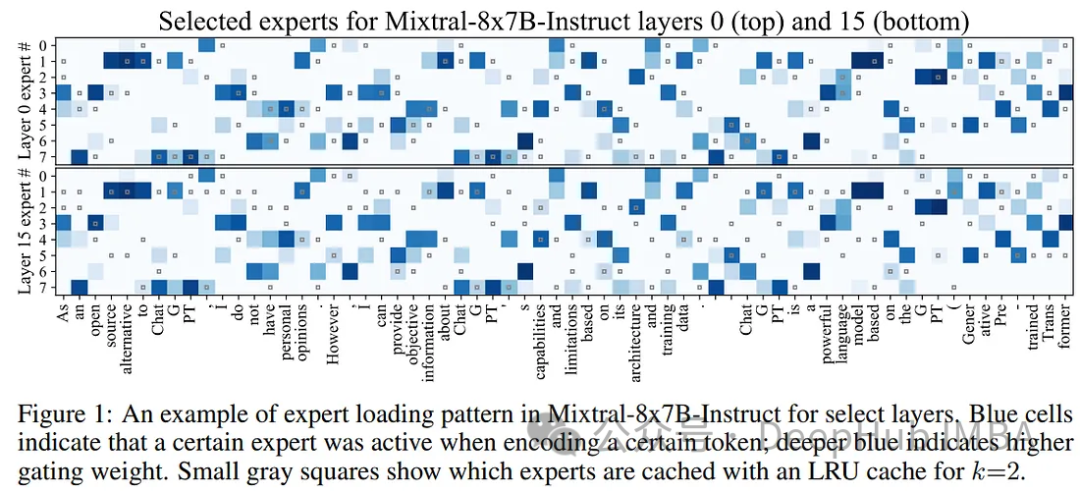
为了利用这种模式,Mixtral-offloading的作者建议将活跃的专家保存在GPU内存中,作为未来令牌的“缓存”。这确保了如果再次需要相同的专家时可以快速获得帮助。GPU内存限制了存储专家的数量,并使用了一个简单LRU(Least Recently Used )缓存,在所有层上统一维护k个最近使用的专家。
尽管它很简单,但LRU缓存策略显著加快了Mixtral-8x7B等MoE模型的推理速度。
尽管LRU缓存提高了专家的平均加载时间,但很大一部分推理时间仍然需要等待下一个专家加载。专家加载与计算之间缺乏有效的重叠。
在标准(非moe)模型中,有效的卸载包括在前一层运行时预加载下一层。这种方法对于MoE模型来说是不可行的,因为专家是在计算的时候选择的。在确定要加载哪些专家之前,系统无法预取下一层。尽管无法可靠地预取,但作者发现可以在处理前一层时猜测下一个专家,如果猜测是正确的,可以加速下一层的推理。
综上所述,LRU缓存和推测卸载可以节省VRAM。
https://avoid.overfit.cn/post/43ee6bb2c402448698fc7c67e2a9bd60
标签:缓存,offloading,模型,专家,8x7B,Mixtral,加载 From: https://www.cnblogs.com/deephub/p/17961979