DataStream API(一)
Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版 本已经实现了流批一体, DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数 据和批数据。由于内容较多,我们将会用几章的篇幅来做详细讲解,本章主要介绍基本的DataStream API 用法。 DataStream(数据流)本身是 Flink 中一个用来表示数据集合的类(Class),我们编写的Flink 代码其实就是基于这种数据类型的处理,所以这套核心 API 就以 DataStream 命名。对于 批处理和流处理,我们都可以用这同一套 API 来实现。 DataStream 在用法上有些类似于常规的 Java 集合,但又有所不同。我们在代码中往往并 不关心集合中具体的数据,而只是用 API 定义出一连串的操作来处理它们;这就叫作数据流 的“转换”(transformations)。
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成
⚫ 获取执行环境(execution environment)
⚫ 读取数据源(source)
⚫ 定义基于数据的转换操作(transformations)
⚫ 定义计算结果的输出位置(sink)
⚫ 触发程序执行(execute)
其中,获取环境和触发执行,都可以认为是针对执行环境的操作。所以本章我们就从执行环境、数据源(source)、转换操作(transformation)、输出(sink)四大部分,对常用的 DataStream API 做基本介绍。

5.1 执行环境(Execution Environment)
1. getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文 直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment . getExecutionEnvironment () ;
2. createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果 不传入,则默认并行度就是本地的 CPU 核心数。
- StreamExecutionEnvironment localEnv =
- StreamExecutionEnvironment . createLocalEnvironment () ;
3. createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定 要在集群中运行的 Jar 包。
- StreamExecutionEnvironmentremoteEnv=StreamExecutionEnvironment
- .createRemoteEnvironment(
- "host",//JobManager主机名
- 1234,//JobManager进程端口号
- "path/to/jarFile.jar"//提交给JobManager的JAR包
- );
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程 序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
5.1.2 执行模式(Execution Mode)
- / / 批处理环境
- ExecutionEnvironment batchEnv=ExecutionEnvironment.getExecutionEnvironment();
- / / 流处理环境
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment . getExecutionEnvironment () ;
⚫ 流执行模式(STREAMING)
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式。
⚫ 批执行模式(BATCH)
专门用于批处理的执行模式, 这种模式下, Flink 处理作业的方式类似于 MapReduce 框架。 对于不会持续计算的有界数据,我们用这种模式处理会更方便。
⚫ 自动模式(AUTOMATIC)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
1. BATCH 模式的配置方法
( 1)通过命令行配置
bin/ flink run -Dexecution.runtime-mode=BATCH ... 在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。
(2)通过代码配置
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment . getExecutionEnvironment ( ) ;
- env . setRuntimeMode (RuntimeExecutionMode . BATCH) ;
建议: 不要在代码中配置,而是使用命令行。这同设置并行度是类似的:在提交作业时指 定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理。而在 代码中硬编码(hard code)的方式可扩展性比较差。
2. 什么时候选择 BATCH 模式
Flink 本身持有的就是流处理的世界观,即使是批量数据,也可以看作“有界流”来进行处理。所以 STREAMING 执行模式对于有界数据和无界数据都是有效的;而 BATCH模式仅能用于有界数据。
说明:如果都是用STREAMING处理,可能有时候不太高效。
原因:是因为流处理会输出一些中间数据,但是批处理直接输出最终结果。
用 BATCH 模式处理批量数据,用 STREAMING模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我 们没得选择——只有 STREAMING 模式才能处理持续的数据流。
5.1.3 触发程序执行
有了执行环境,我们就可以构建程序的处理流程了:基于环境读取数据源,进而进行各种转换操作,最后输出结果到外部系统。
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当 main()方法被调用 时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据 ——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算, 这也被称为“延迟执行”或“懒执行”(lazy execution)。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一 直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
5.2 源算子(Source)

Flink 可以从各种来源获取数据,然后构建 DataStream 进行转换处理。一般将数据的输入 来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source就是我们整个处理程序的输入端。
Flink 代码中通用的添加 source 的方式,是调用执行环境的 addSource()方法:
DataStream<String> stream = env.addSource(...);方法传入一个对象参数,需要实现 SourceFunction 接口;返回 DataStreamSource。这里的DataStreamSource 类继承自 SingleOutputStreamOperator 类,又进一步继承自 DataStream。所以 很明显,读取数据的 source 操作是一个算子,得到的是一个数据流(DataStream)。
1.从文件最终读取数据
2.从集合中读取数据
3.从元素中读取数据
4.从Socket文本流中读取数据
- mport org.apache.flink.api.common.serialization.SimpleStringSchema;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
- import java.util.ArrayList;
- import java.util.Properties;
- public class SourceTest {
- public static void main(String[] args) throws Exception {
- //创建执行环境
- StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
- //设置并行度为1
- env.setParallelism(1);
- //1.从文件中读取数据
- DataStreamSource<String> stream1=env.readTextFile("input/clicks.txt");
- //2.从集合中读取数据
- ArrayList<Integer> nums=new ArrayList<>();
- nums.add(2);
- nums.add(5);
- DataStreamSource<Integer> numStream = env.fromCollection(nums);
- ArrayList<Event> events=new ArrayList<>();
- events.add(new Event("Mary","./home",1000L));
- events.add(new Event("Boe","./cart",2000L));
- DataStreamSource<Event> stream2 = env.fromCollection(events);
- //3.从元素中读取数据
- DataStreamSource<Event> stream3 = env.fromElements(
- new Event("Mary", "./home", 1000L),
- new Event("Boe", "./cart", 2000L)
- );
- //4.从Socket文本流中读取
- DataStreamSource<String> stream4 = env.socketTextStream("hadoop102", 7777);
- //5.从Kafka中读取数据
- Properties properties = new Properties();
- properties.setProperty("bootstrap.servers","hadoop102:9092");
- properties.setProperty("group.id","consumer-group");
- properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- properties.setProperty("auto.offset.reset","latest");
- DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));
- /*
- stream1.print("1");
- numStream.print("nums");
- stream2.print("2");
- stream3.print("3");
- stream4.print("4");
- */
- kafkaStream.print("kafka");
- env.execute();
- }
- }

5.从kafka中读取数据(这里重点说明一下)
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。而消息队列的传 输方式,恰恰和流处理是完全一致的。所以可以说 Kafka 和 Flink 天生一对,是当前处理流式 数据的双子星。在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算。
想要以 Kafka 作为数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官 方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本的 Kafka 客户端。
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
- <version>${flink.version}</version>
- </dependency>
- import org.apache.flink.api.common.serialization.SimpleStringSchema;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
- import java.util.Properties;
- public class SourceKafkaTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- Properties properties = new Properties();
- properties.setProperty("bootstrap.servers", "hadoop102:9092");
- properties.setProperty("group.id", "consumer-group");
- properties.setProperty("key.deserializer",
- "org.apache.kafka.common.serialization.StringDeserializer");
- properties.setProperty("value.deserializer",
- "org.apache.kafka.common.serialization.StringDeserializer");
- properties.setProperty("auto.offset.reset", "latest");
- DataStreamSource<String> stream = env.addSource(new
- FlinkKafkaConsumer<String>(
- "clicks",
- new SimpleStringSchema(),
- properties
- ));
- stream.print("Kafka");
- env.execute();
- }
- }
要想从kafka中读取数据,首先要先启动zookeeper和kafka
- #启动单节点zookeeper
-
- cd /opt/module/zookeeper
- ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
-
- #启动单节点kafka
- cd /opt/module/kafka
- ./bin/kafka-server-start.sh -daemon ./config/server.properties
然后创建一个生产者,然后Flink运行代码,消费数据。
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic clicks然后就可以生产数据了。
5.2.6 自定义 Source
我们想要读取的数据源来自某个外部系统,而 flink 既没有预实现的方法、也没有提供连接器, 又该怎么办呢?那就只好自定义实现 SourceFunction 了。接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()。
⚫ run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
⚫ cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-
- public class SourceCustom {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
-
- //有了自定义的 source function,调用 addSource 方法
- DataStreamSource<Event> stream = env.addSource(new ClickSource());
-
- stream.print("SourceCustom");
-
- env.execute();
-
- }
-
-
- }
这里要注意的是 SourceFunction 接口定义的数据源,并行度只能设置为 1,如果数据源设 置为大于 1 的并行度,则会抛出异常。
所以如果我们想要自定义并行的数据源的话,需要使用 ParallelSourceFunction,示例程序 如下
- package com.atguigu.chapter05;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
- import java.util.Random;
- public class ParallelSourceExample {
- //实现自定义并行的数据源
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
- //先设置全局并行度为1
- env.setParallelism(4);
- DataStreamSource<Integer> dataStreamSource=env.addSource(new ParallelSource()).setParallelism(2);
- dataStreamSource.print();
- env.execute();
- }
- }
- class ParallelSource implements ParallelSourceFunction<Integer> {
- //声明一个标志位
- private Boolean running=true;
- private Random random=new Random();
- public ParallelSource() {
- }
- @Override
- public void run(SourceContext<Integer> sourceContext) throws Exception {
- while (running){
- sourceContext.collect(random.nextInt(100));
- }
- Thread.sleep(2000L);
- }
- @Override
- public void cancel() {
- running=false;
- }
- }
5.2.7 Flink 支持的数据类型
1. Flink 的类型系统
为了方便地处理数据,Flink 有自己一整套类型系统。Flink 使用“类型信息” (TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。 它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
2. Flink 支持的数据类型
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger。
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)
(3)复合数据类型
⚫ Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多
25 个字段,也就是从 Tuple0~Tuple25,不支持空字段
⚫ Scala 样例类及 Scala 元组:不支持空字段
⚫ 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
⚫ POJO:Flink 自定义的类似于 Java bean 模式的类
(4)辅助类型 Option、Either、List、Map 等
(5)泛型类型(GENERIC) Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义, 就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它 们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之 下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。 所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。 Flink 对 POJO 类型的要求如下:
⚫ 类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
⚫ 类有一个公共的无参构造方法;
⚫ 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些 方法需要符合 Java bean 的命名规范。
所以我们看到,之前的 UserBehavior,就是我们创建的符合 Flink POJO 定义的数据类型。
3. 类型提示(Type Hints)
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息, 从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情 况下(比如 Lambda 表达式中),自动提取的信息是不够精细的,这时就需要显式地提供类型信息才能使应用程序正常工作或提高其性能。只有显式地 告诉系统当前的返回类型,才能正确地解析出完整数据。
这是一种比较简单的场景,二元组的两个元素都是基本数据类型。那如果元组中的一个元 素又有泛型,该怎么处理呢? Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行 时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元 素的类型。
returns(new TypeHint>(){})5.3 转换算子(Transformation)

数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个 DataStream 转换为 新的DataStream,如图所示。一个 Flink 程序的核心,其实就是所有的转换操作,它们决 定了处理的业务逻辑。
我们可以针对一条流进行转换处理,也可以进行分流、合流等多流转换操作,从而组合成复杂的数据流拓扑。
5.3.1 基本转换算子
1. 映射(map)
map 是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的 数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素
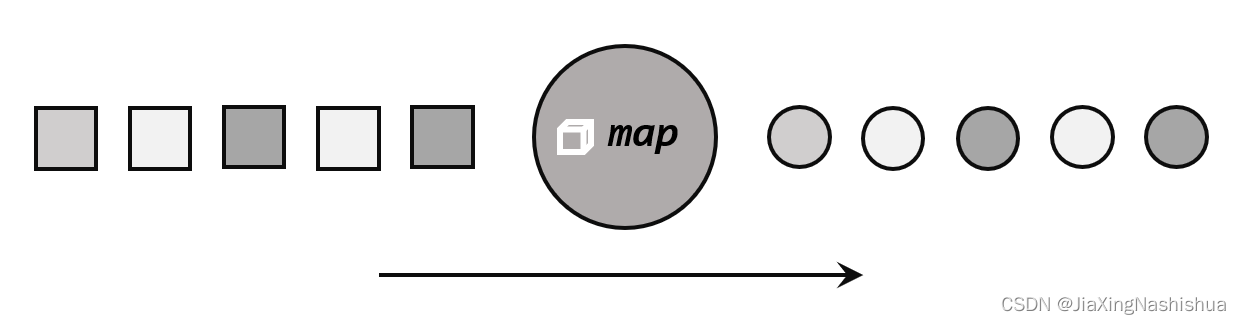
我们只需要基于 DataStrema 调用 map()方法就可以进行转换处理。方法需要传入的参数是 接口 MapFunction 的实现;返回值类型还是 DataStream,不过泛型(流中的元素类型)可能改变。
下面的代码用不同的方式,实现了提取 Event 中的 user 字段的功能。
- package com.atguigu.chapter05;
-
- import org.apache.flink.api.common.functions.MapFunction;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-
- public class TransFromMapTest {
- public static class Mapper implements MapFunction<Event,String>{
-
- @Override
- public String map(Event event) throws Exception {
- return event.user;
- }
- }
-
- public static void main(String[] args) throws Exception{
- StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
-
- //从元素中读取数据
- DataStreamSource<Event> stream=env.fromElements(new Event("mary","./home",1000L),
- new Event("Bob","./cart",2000L),
- new Event("Alice","./prod?id=100",3000L)
- );
-
- //进行转换计算,提取user字段
-
- //1.使用自定义类,实现MapFunction接口
- SingleOutputStreamOperator<String> result1 = stream.map(new Mapper());
- result1.print();
-
- //2.使用匿名类实现MapFunction接口
- SingleOutputStreamOperator<String> result2 = stream.map(new MapFunction<Event, String>() {
- @Override
- public String map(Event event) throws Exception {
- return event.user;
- }
- });
- result2.print();
-
- //3.传入Lambda表达式
- SingleOutputStreamOperator<String> result3 = stream.map(data -> data.user);
- result3.print();
-
- env.execute();
-
- }
- }
2. 过滤(filter)
filter 转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤 条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。
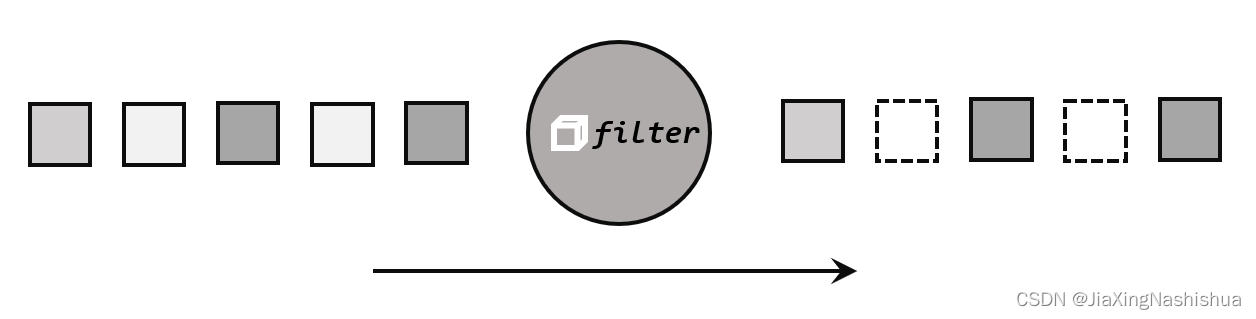
进行 filter 转换之后的新数据流的数据类型与原数据流是相同的。filter 转换需要传入的参数需要实现 FilterFunction 接口,而 FilterFunction 内要实现 filter()方法,就相当于一个返回布尔类型的条件表达式。
代码实现:
- package com.atguigu.chapter05;
-
- import org.apache.flink.api.common.functions.FilterFunction;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-
- public class TransFromFilterTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
-
- //从元素中读取数据
- DataStreamSource<Event> stream=env.fromElements(new Event("mary","./home",1000L),
- new Event("Bob","./cart",2000L),
- new Event("Alice","./prod?id=100",3000L)
- );
-
- //1.直接传入一个实现了FilterFunction类的对象
- SingleOutputStreamOperator<Event> result = stream.filter(new MyFilter());
- result.print();
-
- //2.传入一个匿名类实现FilterFunction接口
- SingleOutputStreamOperator<Event> result2 = stream.filter(new FilterFunction<Event>() {
- @Override
- public boolean filter(Event event) throws Exception {
- if (event.user.equals("mary")) {
- return true;
- }
- return false;
- }
- });
- result2.print();
-
- //传入lambda表达式
- SingleOutputStreamOperator<Event> result3 = stream.filter(data -> data.user.equals("m; ary"));
- result3.print();
-
- env.execute();
- }
-
-
- //实现一个自定义的FilterFunction
- public static class MyFilter implements FilterFunction<Event>{
-
- @Override
- public boolean filter(Event event) throws Exception {
- if (event.user.equals("mary")){
- return true;
- }
- return false;
- }
- }
- }
原文链接:https://blog.csdn.net/JiaXingNashishua/article/details/126692053?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170392534116800182195992%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170392534116800182195992&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-3-126692053-null-null.nonecase&utm_term=DataStream&spm=1018.2226.3001.4450 标签:DataStream,StreamExecutionEnvironment,Flink,API,flink,env,apache,new From: https://www.cnblogs.com/sunny3158/p/17936520.html