VIT Vision Transformer
目录论文地址:https://arxiv.org/abs/2010.11929
源码地址(pytorch):https://github.com/lucidrains/vit-pytorch
DETR首次将Transformer应用到了目标检测任务中。图像会先经过一个传统的CNN抽出图像特征来,然后再将CNN的输出直接送到Transformer网路中
VIT就是在transformer前面添加 CNN结构的backbone提取特征,最后通过MLP进行类别输出。
在ViT中,模型只有Encoder的,没有Decoder,因为只是用于识别分类任务,不需要Decoder
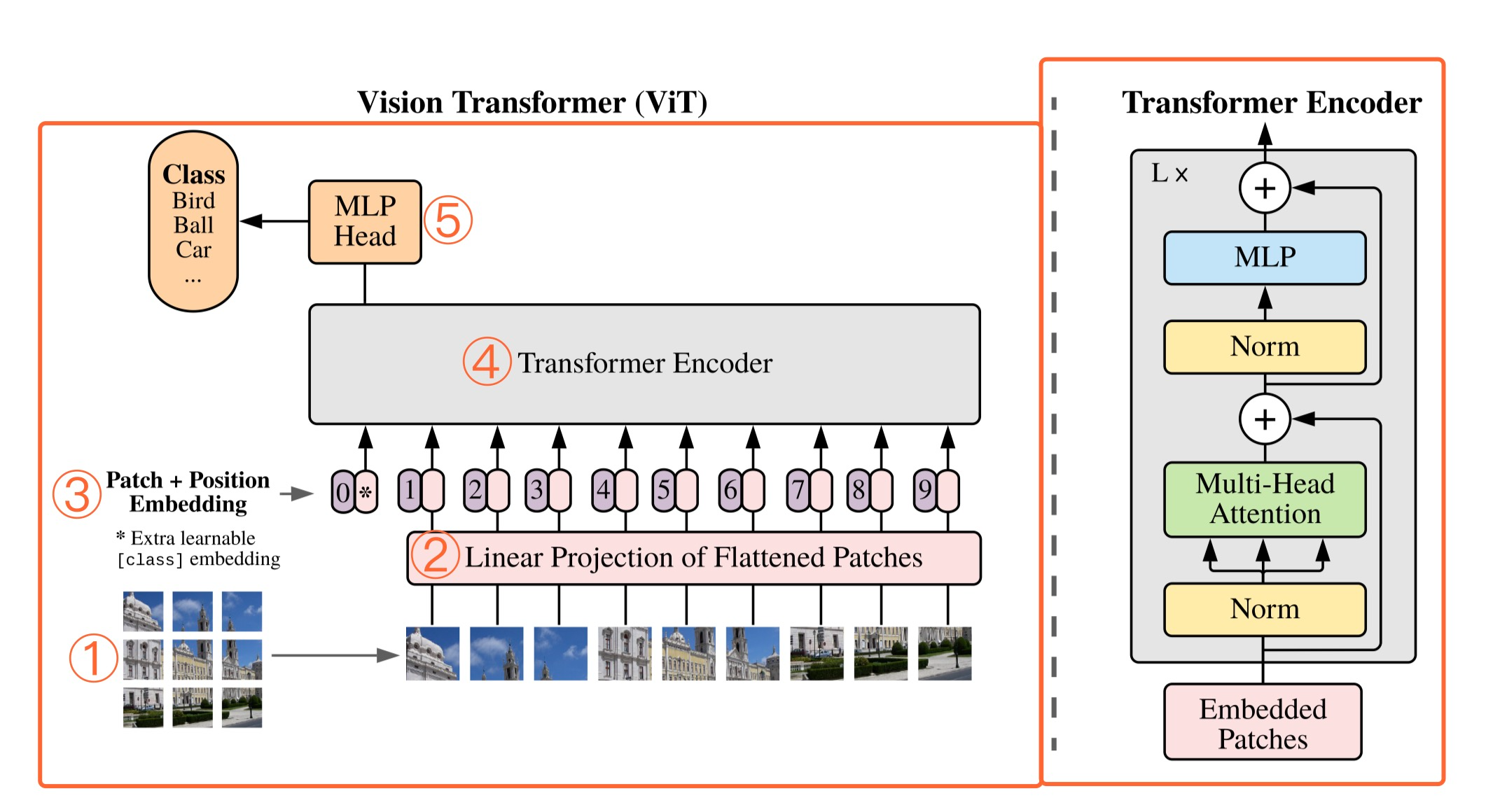
ViT模型结构
核心包括:
- 图像分块处理 (make patches)
- 图像块嵌入 (patch embedding)与位置编码、
- Transformer编码器
- MLP分类处理等4个主要部分。
将图像分割成固定大小的块,线性嵌入其中的每个块,加入位置嵌入,并将得到的向量序列反馈给标准的Transformer编码器。为了执行分类,我们采用在序列中添加额外可学习的“classification token”的标准方法。
图像划分Patch
假设一个图像 H × W × C 现在将其切分成P x P x C 全部的patches的维度为 N×P×P×C, 然后将每个patch进行展平,相应的数据维度就可以写为 $(N,P^2,C) $
N 输入到Transformer的序列长度, C 为输入图像的通道数, P 为图像patch的大小
以ViT-B/16模型为例
将图像分成16×16的patch(小方块),每个patch块可以看做是一个token(词向量),共有(224/16=14)14×14=196 个token,每个token的维度为16×16×3=768,patch块大小是16×16,每个patch块是RGB三通道的彩色图像)
Linear Projection of Flatted Patches
一个patch块它的维度是16×16×3=768,我们把它flatten拉平成行向量它的长度就为768,一共有14×14=196个patch,所以输入的维度是[196, 768],我们经过一个Linear Projection(映射)到指定的维度,比如1024,这里用全连接层来实现,映射的维度任然选择为768,那么此时的输出是[196, 768]。
输出的结成为果图像块嵌入(Patch Embeddings)类似于NLP中的词嵌入Word Embeddings。
Patch+Position Embedding
patch embedding的维度为[196, 768]
1、首先生成一个 分类向量 cls token,维度为[1, 768],然后拼接到输入的path embedding,得到的最后的patch 的维度为[197, 768]
2、对197个patch都生成一个位置信息,它的维度同patch维度为[197, 768]
3、Patch+Position Embedding,直接相加为新的的token作为encoder的输入
cls token和位置信息编码通过训练得到, cls token的作用是为了同NLP领域的Transformer保持一致,最后直接提取cls token作为网络提取得到的特征,作为类别预测的输出,放入MLP进行分类

分类向量和位置向量
在图像块嵌入后得到的向量中追加了一个分类向量,用于训练 Transformer 时学习类别信息。假设将图像分为N个图像块,输入到 Transformer 编码器中就有N个向量,但该取哪一个输出向量用于分类预测呢?因此再手动添加一个 可学习的嵌入向量作为用于分类的类别向量 ,同时与其他图像块嵌入向量一起输入到 Transformer 编码器中,最后取追加的首个可学习的嵌入向量作为类别预测结果。
如果不加分类向量,在encoder的输出时,不知道采用哪个向量进行最后结果的计算
位置嵌入的目的是为了保留图像的空间位置信息。Transformer 不同于CNN,由于图像块嵌入的缘故,它失去了原图像的位置信息,因此这个需要进行位置嵌入来提供额外的位置信息。这里没有采用原版Transformer的sincos编码,而是直接设置为可学习的Positional Encoding
Encoder
Encoder输入的维度为[197, 768],输出的维度为[197, 768],可以把中间过程简单的理解成为特征提取的过程
Transformer编码器由交替的多头自注意力层(MSA)和多层感知机块(MLP)构成。在每个块前应用层归一化(Layer Norm),在每个块后应用残差连接(Residual Connection)。
MLP Head(全连接头)
通过Transformer Encoder 后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。
这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出 [class]token(也就是添加的分类向量) 对应的[1, 768]。
VIT模型参数
在论文中给出了三个模型(Base Large Huge)的参数,如下:
| Model | Patch size | Layers | Hidden Size | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| VIT-Base | 16*16 | 12 | 768 | 3072 | 12 | 86M |
| VIT-Large | 16*16 | 24 | 1024 | 4096 | 16 | 307M |
| VIT-Huge | 14*14 | 32 | 1280 | 5120 | 16 | 632M |
对比 ViT 思考 DETR
-
首先 ViT 是没有使用 CNN 的,而 DETR 是先用 CNN 提取了图像的特征
-
ViT 只使用了Transformers-encoder,在 encoder 的时候额外添加了一个 Class token 来预测图像类型,而 DETR 的 object token 则是通过 Decoder 学习的.
-
DETR 和 VIT 中的Transformers 在 encoder 部分都使用了Position Embedding,但是使用的并不一样,而 VIT 在使用的 Position Embedding 是可训练的Position
-
DETR 的 Transformers encoder使用的feature 的每一个pixel作为token embeddings输入,而ViT 则是直接把图像切成 16*16 个 Patch,每个 patch 直接拉平作为token embeddings
-
相比较 VIT, DETR 更接近原始的 Transformers 架构.
-
ViT是用于图像分类的,DETR可以用于目标检测和分割
为什么处理成patch
- 是为了减少模型计算量。注意力机制下,每个token都要和包括自己在内的所有token做一次attention score计算。
- 减少冗余,和语言数据中蕴含的丰富语义不同,像素本身含有大量的冗余信息。
部分模块改进思路
https://blog.51cto.com/u_15279692/4888834
主要有:
- 渐进式分块
- 相对位置编码改进
- 编码器改进
参考资料
https://blog.csdn.net/qq_37541097/article/details/118242600
https://juejin.cn/post/7081894732233719822?searchId=20231214160746D70BFF6F41E9C0014C0D
https://juejin.cn/post/7277490138518175763?searchId=20231214160746D70BFF6F41E9C0014C0D#heading-5 代码及其训练
标签:768,16,Transformer,patch,token,VIT,图像,Vision From: https://www.cnblogs.com/tian777/p/17935072.html