一、引言
随着业务的增长,单体架构发展为分布式架构,大大提升了业务的处理能力,但同时也带来了很多单体架构不存在的问题,如:
- 各节点之间网络通信的异常以及因其引起的脑裂问题(网络分区)。
- 引出“三态”。在单体架构中只会存在“成功”或“失败”两种结果,但是在分布式架构中由于网络异常将会出现“未知”的结果,即请求丢失或者响应丢失,导致客户端超时。
- 各节点会发生故障。
- 分布式事务以及数据一致性。
- 各节点的配置和地址的维护。一台机器我们可以很容易的进行管理,但是在分布式下存在很多台机器共同协作,不可能再由人工手动维护。
本篇,主要讲述数据一致性的解决方案以及服务的协调治理工具Zookeeper基本概念。
二、从ACID到CAP/BASE
事务的ACID特征在单体架构中已经得到很好地验证和实践,但是在分布式架构中,是由多个独立的事务来构成一个完整的分布式事务,我们无法实现一套严格遵循ACID的分布式事务,因为数据的一致性和系统的可用性是冲突的,不存在完美的解决方案。但由于业务的需求和推动,逐渐出现了诸如CAP、BASE这样的经典理论,基于这样的理论我们可以构建出一个大致兼顾二者的分布式系统。
- CAP理论是说一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)以及分区容错性(Partion tolerance),只能同时满足其中两个。而在分布式系统中,P是必须满足的,否则就不存在分布式了。因此,我们需要在C和A之间权衡。
- Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)简称BASE理论,它是对CAP理论的改进,权衡了其中的可用性和一致性。其核心思想是即使无法做到强一致性,但每个业务都可以根据自己的特点,采用适当的方式达到最终一致性。因为对于客户而言,拿到过时的数据总好过于网页都打不开,只要在一个可接受的时间内能保证最终数据是正确的即可。
三、分布式一致性协议
由于在设计分布式架构时,需要根据业务反复权衡可用性和数据一致性,因此产生了一系列的一致性协议算法,其中最著名的就是二阶段提交(2PC)、三阶段提交(3PC)和Paxos算法。
1. 2PC和3PC
在分布式结构中,各节点能明确知道自身的事务执行结果,但是无法直接获取其它节点的事务执行结果。那要如何保证事务执行的一致性呢?我们可以引入一个协调者来统一调度所有节点,被调度的节点称为参与者。就像一支分为很多个小分队的军队,统一受将军的分配调度,如果没有“将军”这样一个“支配者”,那么这个军队就是一盘散沙,根本无法协同作战。分布式架构也是如此,协调者负责调度参与者的行为,并最终决定是否真正的提交事务。在这个思想上,衍生出了2PC和3PC协议。
2PC
2PC将事务提交分为两个阶段:发起事务请求和事务提交/回滚
发起事务请求
- 首先协调者向各参与者发送事务内容,询问是否可以执行事务提交,并等待参与者的反馈。
- 然后各参与者开始执行事务,并记录事务日志信息。
- 最后各参与者向协调者反馈事务执行的结果,成功或者失败。
事务提交/回滚
在该阶段中,协调者根据参与者的反馈决定是否真正提交事务,只要有一个参与者反馈的是“失败”或者等待反馈超时,那么协调者就会通知各参与者回滚之前的事务操作;否则,通知参与者提交事务。参与者执行完成后会反馈协调者一个ACK,协调者收到所有的参与者ACK后,完成事务的提交或中断。
以上就是2PC的执行过程,其中一阶段可以看作是一个投票过程,二阶段则是执行投票的结果。因为需要等待参与者的“全票通过”,因此2PC是一个强一致性的协议算法。
2PC原理简单,实现容易,但同时也存在很多的问题:
- 同步阻塞:在整个二阶段提交的过程中,参与者在释放占用资源之前(提交或终止完成),是处于同步阻塞的,无法处理其它任何操作,极大地影响了系统的性能。
- 单点故障:由上可知,协调者在整个过程中非常的重要,一旦出现问题,整个协议就无法运转了。
- 数据不一致:当在第二个阶段,协调者正在发出提交请求,此时网络出现故障或者协调者自身崩溃导致只有一部分参与者收到提交请求,那么数据就会出现不一致。
- 过于保守:在事务询问阶段,如果任一参与者在反馈协调者之前出现故障而导致协调者无法收到反馈,那么协调者就会一直处于阻塞状态,只能通过自身的超时机制来判断是否要中断事务。
3PC
3PC则是对2PC的改进,将发起事务请求阶段一分为二,因此包含了三个阶段:事务询问(canCommit)、事务预提交(preCommit)和提交事务(doCommit)。
canCommit
- 协调者向所有参与者发送一个包含事务内容的询问请求,等待参与者的反馈。
- 参与者收到请求后,根据自身情况返回"YES"或"NO"。
preCommit
协调者根据参与者的反馈情况来通知参与者预提交事务或者中断事务:
- 预提交事务:协调者收到的都是“YES”反馈,就会通知参与者进行事务的预提交,并记录事务日志,参与者执行预提交完成后,将结果反馈给协调者。
- 中断事务:若一阶段中任一参与者反馈的是“NO”,或者协调者等待反馈超时,那么协调者就会发出中止请求,此时无论参与者是收到中止请求或是等待请求超时,参与者都会中断事务。
doCommit
协调者根据二阶段参与者的反馈来通知参与者提交事务或者回滚事务:
- 提交事务:二阶段中所有参与者预提交事务成功,则在此阶段真正地提交事务。
- 回滚事务:二阶段中任一参与者预提交事务失败,则在此阶段根据事务日志回滚事务。
需要注意的是,在此阶段,可能会出现以下故障:
- 协调者出现故障
- 协调者和参与者之间通信故障
无论是哪种故障,都是导致参与者无法接收到协调者发出的请求,针对这种情况,参与者在等待请求超时后,都会继续提交事务(不能回滚,因为协调者可能已经提交事务,若参与者回滚事务就会导致数据不一致)。
通过以上过程,我们可以发现,3PC相较于2PC的优点:
- 降低了阻塞的范围,3PC要到阶段二才会出现阻塞,而2PC在整个提交过程中都是阻塞的。
- 在阶段三出现单点故障后能够保证数据的一致性
但在优化阻塞问题的同时带来了新的问题,当参与者收到preCommit请求后出现网络分区,那么断开连接的参与者会继续提交事务,而协调者由于未收到全部参与者的“YES”反馈,就会向保持连接的参与者发出中断事务的请求,导致数据出现不一致。
因此,我们可以看出无论是2PC还是3PC都无法完全解决数据一致性问题,并且整个事务提交过程太过保守,导致性能并不是很好。所以,Paxos算法也就出现了。
2. Paxos
Paxos算法被认为是唯一的一致性算法,而其它的协议算法都是它的不完整版,其复杂难以理解程度是公认的,因此,小编这里不花费过多的时间来表述,感兴趣的读者可以去了解其诞生背景和原论文《Paxos Made Simple》。(注:Paxos发展历史是很有意思的,该篇论文是由于作者第一篇论文太过晦涩几乎无人理解,不得不用通俗易懂的语言重新描述而发表的)
3. ZAB协议
Zookeeper Atmoic Broadcast(ZAB,Zookeeper的原子消息广播协议),一种基于Paxos算法实现的协议,但又和Paxos不完全相同,是Zookeeper保证数据一致性的核心算法。这里只是列举,后文进行阐述。
四、Zookeeper初探

1. 简介
Zookeeper是一个开源的分布式协调服务组件,由雅虎公司创建。分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、分布式锁和队列等功能。它可以保证如下分布式一致性特性:
- 顺序一致性:同一客户端的事务请求按照“先入先出”的方式处理,保证了事务执行的顺序。
- 原子性:集群情况下,保证事务要么都被所有机器执行,要么都不执行,不存在部分执行部分不执行的情况。
- 最终一致性:客户端从服务端获取的数据不一定是实时最新的,但是能保证在一定的时间内服务端数据达到最终一致性,即客户端最终能获取到最新的数据。
- 共享视图:无论客户端连接的是哪个服务端,获取到的数据都是一样的,不存在特例。
- 可靠性:一旦一个事务被执行成功且正确的返回给了客户端,那么这个事务结果就会持久化存在并共享给所有服务器节点,除非有新的事务更改了该事务的结果。
2. Zookeeper的设计目标
Zookeeper致力于提供一个高性能、高可用、且具有严格的顺序访问控制能力的分布式协调服务。其设计目标主要有四个:
简单的数据模型
Zookeeper内部使用共享的、树形结构的数据模型来存储数据,并且是基于key-value键值对存储的,每一个key-value都是一个ZNode。其中key存储格式必须类似于文件夹路径,如:/service/1、/service/2(可以看作是在service节点下存放了两个服务节点1和2);value可以存储任意值(一般没什么用处)。
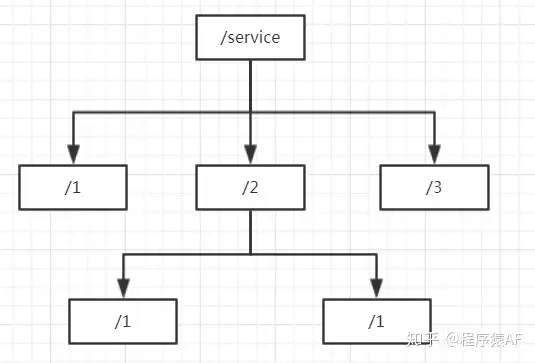
如上图,每个层级的节点key是唯一的,且多个客户端创建相同的节点只会有一个成功,基于这一点我们就可以实现一个分布式锁。
可以构建集群
既然是作为分布式应用的协调组件,那么就必须天然支持集群的搭建扩展,否则就会存在单点故障,造成整个分布式应用的崩溃。同时需要考虑的问题是,是否集群中任一台机器故障了整个集群就不可用呢?肯定不是的,否则和单点又有什么区别呢?那么就需要考虑的是集群可用的最少机器数量如何确定,在Zookeeper中是需要保证存活服务器数量至少为集群总数量的n/2 + 1台,即过半的机器存活集群就可以对外提供服务,至于为什么,可以先自己思考下(提示:和投票有关)。
顺序访问
主要是要保证事务请求(增、删、改)的顺序执行,对于每次事务请求,Zookeeper会通过分配一个全局递增的编号来控制事务请求的顺序。
高性能
Zookeeper将所有数据存于内存当中,因此其对于读请求的响应是非常快的。
3. 基本概念
在对Zookeeper进行实操和深入了解之前,我们有必要先了解一下其核心概念。
集群角色
在分布式系统中,构成集群的机器都有自己的角色,通常是是Master/Slave(主/备)模式。在该模式中,通常将能够处理写操作的机器称为Master机器,而通过异步复制手段获取最新数据的机器,并处理读操作的机器称为Slave机器。但Zookeeper并未采用该模式,而是使用了Leader、Follower、Observer三种角色。
Zookeeper通过Leader选举算法选出一台机器作为Leader,对外提供事务请求处理的服务,而其余的机器则作为Follower和Observer(具体是哪一个角色,是根据配置决定的)对外提供非事务请求处理的服务。其中Follower会参与到Leader的选举投票,Observer仅处理非事务请求,不参与投票(也不在“过半”的统计中);因此,在查询性能达到瓶颈时,往往会增加Observer服务器来提高查询性能,同时不对事务请求性能造成影响。
会话
Zookeeper底层是通过TCP长连接来保持客户端会话的,客户端可以通过该连接进行心跳检测、发起请求、接收响应和接收来自服务端的Watch事件。在创建会话时可以设置一个超时时间sessionTimeout,当客户端由于某种原因导致连接断开时,在该时间内重新连接上任意一台服务器后,之前创建的会话仍然有效。
数据节点
在上文已经说过了,Zookeeper的数据模型是一系列的ZNode构成的树形结构,并且分为持久节点和临时节点。持久节点指一旦被创建除非主动删除就会一直存在的节点;而临时节点则是和会话绑定的,会话失效,所有的临时节点都会自动删除。另外,Zookeeper还可以指定节点是否有序,有序节点在创建时会自动在节点名称后面追加递增的整型数字。
版本
对于每个ZNode,Zookeeper都会维护一个Stat的数据结构,其中记录了这个节点的三个数据版本:version(当前节点版本)、cversion(当前节点的子节点版本)、aversion(当前节点的ACL版本)。
Watcher机制
Zookeeper可以为每个节点指定特定的Watcher事件监听,当被监听节点有相应的变化时会自动触发事件。
ACL
Zookeeper采用了Access Control Lists策略来控制权限,定义了如下权限:
- CREATE:创建子节点的权限
- READ:获取节点数据和子节点列表的权限
- WRITE:更新节点数据的权限
- DELETE:删除子节点的权限
- ADMIN:权限设置的权限
4. Zookeeper一致性协议ZAB
Zookeeper在保证数据一致性上并未完全基于Paxos实现,而是使用了其特定的ZAB原子广播协议,支持崩溃恢复和消息广播。下面就来看看ZAB的实现原理吧。
实现原理
ZAB协议是一个类2PC的协议,也是分两步提交,它包含了两个模式:消息广播和崩溃恢复。
消息广播
Zookeeper集群在启动时会选择出一个Leader服务器用于处理事务请求,当客户端发起事务请求时,若收到请求的服务器不是Leader,就会将请求转发给Leader服务器,该服务器会给创建一个事务Proposal并广播给所有的Follower服务器(Proposal需要保证顺序性,而Zookeeper是基于TCP实现的长连接,天然具有FIFO特性,同时Leader服务器会为每一个Proposal分配一个全局递增的唯一ID(ZXID),以及为每一个Follower服务器都创建一个单独的队列,然后将这些Proposal按照ZXID的先后顺序放入到队列中等待Follower服务器处理。),然后再收集各个服务器的投票信息,当有过半的服务器反馈的是“肯定”选票,Leader服务器就会再广播一个commit请求提交事务,同时自身也提交该事务,这就是消息广播模式。
这个过程看起来好像和我们上文所说的2PC没什么区别,但实际上,Zookeeper的消息广播移除了二阶段提交中的中断逻辑,这就意味着Leader服务器不必再等待集群中其它所有服务器的反馈,只要有过半的服务器给出了正常的反馈(这就是为什么集群需要保证存活服务器数量过半才能对外提供服务的原因),就广播commit请求;反观Follower服务器,也只需要给出正常的反馈或者直接丢弃掉该Proposal。这样就解决了同步阻塞的问题,处理更加简单了,但是无法解决Leader服务器由于崩溃退出而导致的数据不一致问题,因此,就需要崩溃恢复模式来解决该问题。
崩溃恢复
消息广播模式在Leader服务器运行正常的情况下表现良好,但是刚刚也说了一旦Leader服务器崩溃,或者网络分区导致该Leader服务器失去了过半服务器的支持,此时集群就会进入崩溃恢复模式,重新选举Leader。重新选举Leader需要保证两个特性:
- 已经在Leader服务器上提交的事务最终需要所有的服务器都提交。很好理解,当有过半服务器给出反馈后,Leader服务器就会提交自身的事务,并广播commit请求给所有服务器,但在此之前Leader服务器挂了,那么如果不满足该特性必然就会出现数据的不一致。
- 需要确保丢弃那些只在Leader服务器上被提出的事务。在Leader服务器提出Proposal还未发送给其它服务器时,该服务器挂了,而后,该服务器恢复正常加入到集群中时,必然要丢弃掉该事务才能达到数据一致。
只有这两个特性都被满足,数据才能达到最终一致。但是要如何做到这一点呢?这就需要用到上文提及的ZXID。那什么是ZXID?它是一个64位的编号,分为高32位和低32位。高32位是“朝代”编号,即每进行一轮Leader选举,该编号就会自增1;低32位是当前“朝代”数据更新次数,即每生成一个Proposal,该编号就会自增1,若“更朝换代”,该编号会重置为0。
有了这个编号后,当Leader服务器挂掉,剩余服务器重新选举Leader时,只需要将拥有最大ZXID编号的的服务器作为新的Leader服务器即可保证数据的一致性。这个不难理解,若Leader服务器是已经广播commit后挂掉的,那么肯定有服务器已经拥有了最新的Proposal,即最大的ZXID,那么将该服务器作为Leader,其它服务器只需要同步该服务器上的数据即可达到数据一致;若Leader服务器创建了Proposal但未广播就挂掉了,则此时剩余服务器并不会拥有该Proposal的ZXID,当挂掉服务器恢复后,此时,该集群中已经有新的Leader,也就是之前未广播的Proposal的ZXID肯定不会大于当前Leader拥有的ZXID,所以直接丢弃即可。
5. Leader选举详解
Zookeeper选举Leader分为启动时选举和服务运行期间的选举。在往下看之前需要先了解服务器的几个状态:
- LOOKING:观望状态,此时还未选举出Leader
- LEADING:该服务器为Leader
- FOLLOWING:该服务器为Follower
- OBSERVING:该服务器为Observer
在构建Zookeeper集群时,最少服务器数量是2,但是服务器数量最好为奇数(因为需要过半服务器的支持才能完成投票和决策,如果是6台,那么最多允许挂掉2台服务器,存活4台进行投票决策;而如果是5台,那么最多允许挂掉的台数也是2台,但是只有3台进行投票决策。因此,相比较而言,奇数台服务器数量容错率更高的同时还降低了网络通信负担),因此,这里使用3台服务器说明,分别是server1、server2、server3。
启动时选举
启动服务器,当选举完成前,所有服务器的状态都是LOOKING。当启动server1(我们假设其myid为1,myid就是服务器id,需要自己配置,后面实际操作时会讲)时,一台服务器无法完成选举,因为需要过半服务器;然后启动server2(假设myid为2),这时两台服务器开始通信,并进入选举流程竞选Leader。
- 首先每台服务器都会将自己的myid和ZXID作为投票发送给其它服务器,因为是第一轮投票,所以假设ZXID都会0,那么server1的投票为(1,0),server2的投票为(2, 0)
- 服务器接收其它服务器的投票并检测投票是否有效,包括是否为同一轮投票,以及是否来自于LOOKING服务器
- 检验通过后,每个服务器都会将自己的投票和收到的投票进行比较。首先比较ZXID,选出最大的并更新为自己新的一轮投票,这里ZXID都是一样的,所以继续比较myid,同样选出最大的作为自己新的一轮投票。因此,这里server1会更新自己的投票为(2,0),而server2则是将自己之前的投票再重新投一次即可。
- 每一轮投票结束后,服务器都会统计投票信息,看看是否已经有服务器受到过半服务器的支持,若有,就将其作为Leader服务器,并将状态修改为LEADING,其它服务器状态则变为FOLLOWING。这里就是server2成为了Leader,选举结束。
当server3启动时,发现集群中已经存在Leader,则只需作为Follower服务器将入进去即可,不需要重新选举,除非Leader服务器挂掉。
服务运行期间的选举
服务运行期间Leader的选举其实在崩溃恢复那一节已经提及到,这里再详细说说。
- 当server2服务器崩溃时,剩余服务器因为找不到Leader,就会将自己的状态更新为LOOKING并进入Leader选举流程,这时候服务是不可用的。
- 存活服务器都会生成投票信息,因为服务已经运行一段时间,所以ZXID可能是不一样的,我们假设server1的投票为(1, 10),server3的投票为(3,11)。后面的流程就会启动时的选举是一样的了,只不过,server1在收到(3,11)投票后,只要比较ZXID即可。所以最终确定server3为新的LEADER。
Leader选举源码分析
从上文我们了解了Leader选举的核心原理,但代码层面是如何实现的呢?这就要通过分析其源码才能明白。
首先我们需要找到一个入口类,即Zookeeper集群启动的主类QuorumPeerMain:
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
main.initializeAndRun(args);
}
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
// 加载配置的类
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
// 从配置文件加载配置到内存中
config.parse(args[0]);
}
if (args.length == 1 && config.servers.size() > 0) {
// 配置集群
runFromConfig(config);
} else {
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
// 将配置信息设置到QuorumPeer类
quorumPeer = new QuorumPeer();
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.start(); // 开启子线程加载db信息以及开始选举
quorumPeer.join(); // 主线程等待子线程完成
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}主要逻辑都在QuorumPeer类中,该类继承自Thread类:
public synchronized void start() {
loadDataBase(); // 这里是恢复DB信息,如epoch和ZXID等
cnxnFactory.start();
startLeaderElection(); //开始选举的流程
super.start(); // 启动线程
}
synchronized public void startLeaderElection() {
try {
// 投自己一票
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
} catch(IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
// 创建选举算法,默认是使用FastLeaderElection选举算法
this.electionAlg = createElectionAlgorithm(electionType);
}
protected Election createElectionAlgorithm(int electionAlgorithm){
Election le=null;
//TODO: use a factory rather than a switch
switch (electionAlgorithm) {
case 0:
le = new LeaderElection(this);
break;
case 1:
le = new AuthFastLeaderElection(this);
break;
case 2:
le = new AuthFastLeaderElection(this, true);
break;
case 3:
qcm = new QuorumCnxManager(this);
QuorumCnxManager.Listener listener = qcm.listener;
if(listener != null){
listener.start();
// 默认会进入到这里,可以在zoo.cfg配置文件中配置
le = new FastLeaderElection(this, qcm);
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}从上述代码中我们可以看到QuorumPeer创建选举算法的流程,默认是使用的是FastLeaderElection类(早期的版本中有LeaderElection、UDP版本的FastLeaderElection和TCP版本的FastLeaderElection,自3.4.0版本开始只保留了TCP版本的FastLeaderElection,我们也可以自己实现一个选举算法,然后在zoo.cfg配置文件配置即可)。选定选举算法后,调用了线程的start方法,那我们只需要找到run方法即可:
public void run() {
try {
while (running) {
// 根据服务器状态进入相应的流程,因为是选举流程,所以都是LOOKING状态,其它的流程可以暂时忽略
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) { // 当前服务器为只读服务器,与我们的流程无关
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb);
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
setBCVote(null);
// 选出leader
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
}
}
} finally {
LOG.warn("QuorumPeer main thread exited");
try {
MBeanRegistry.getInstance().unregisterAll();
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
}
}Leader选举的细节主要就在FastLeaderElection.lookForLeader()(makeLEStrategy().lookForLeader())方法中:
// 发送和接收选票队列
LinkedBlockingQueue<ToSend> sendqueue;
LinkedBlockingQueue<Notification> recvqueue;
public Vote lookForLeader() throws InterruptedException {
try {
// 存放收到的投票信息
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
// 存放当前服务器的投票信息
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
// 第一次投票都投自己
synchronized(this){
logicalclock++;
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 发送自己的投票信息
sendNotifications();
// 循环直到选出Leader
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
// 从队列中按顺序取出投票
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
if(n == null){ // 未收到任何投票信息
if(manager.haveDelivered()){ // 发送队列空闲情况下,就继续发送自己的投票信息
sendNotifications();
} else { // 发送队列不为null,可能是其它服务器还未启动,尝试重连
manager.connectAll();
}
}
else if(self.getVotingView().containsKey(n.sid)) { // 该消息是否属于当前集群
switch (n.state) { // 判断收到消息的节点的状态
case LOOKING:
// 判断是否是新一轮的选举
if (n.electionEpoch > logicalclock) {
logicalclock = n.electionEpoch; // 更新logicalclock
recvset.clear(); // 清空前一轮收到的投票信息
// 比较epoch、myid和zxid,并更新自己的投票为胜出的节点
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
// 发送新的投票
sendNotifications();
} else if (n.electionEpoch < logicalclock) { // 收到的投票信息已经过期,直接忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
// 同一轮投票直接比较myid和zxid
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
// 判断选举是否结束,默认算法是超过半数同意
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock, proposedEpoch))) {
// 等待所有notification都被处理完,直到超时
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
// leader已经确定
if (n == null) {
// 修改状态为leader或者follower
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid,
logicalclock,
proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING: // observer不参与投票
LOG.debug("Notification from observer: " + n.sid);
break;
// follower和leader都要参与投票
case FOLLOWING:
case LEADING:
/*
* Consider all notifications from the same epoch
* together.
*/
if(n.electionEpoch == logicalclock){
recvset.put(n.sid, new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch));
if(ooePredicate(recvset, outofelection, n)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify
* a majority is following the same leader.
*/
outofelection.put(n.sid, new Vote(n.version,
n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch,
n.state));
if(ooePredicate(outofelection, outofelection, n)) {
synchronized(this){
logicalclock = n.electionEpoch;
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecognized: {} (n.state), {} (n.sid)",
n.state, n.sid);
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
try {
if(self.jmxLeaderElectionBean != null){
MBeanRegistry.getInstance().unregister(
self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
}
}至此,Leader选举流程就结束了,但还有个问题,消息是如何广播的?就是sendNotifications方法:
private void sendNotifications() {
for (QuorumServer server : self.getVotingView().values()) {
long sid = server.id;
ToSend notmsg = new ToSend(ToSend.mType.notification,
proposedLeader,
proposedZxid,
logicalclock,
QuorumPeer.ServerState.LOOKING,
sid,
proposedEpoch);
if(LOG.isDebugEnabled()){
LOG.debug("Sending Notification: " + proposedLeader + " (n.leader), 0x" +
Long.toHexString(proposedZxid) + " (n.zxid), 0x" + Long.toHexString(logicalclock) +
" (n.round), " + sid + " (recipient), " + self.getId() +
" (myid), 0x" + Long.toHexString(proposedEpoch) + " (n.peerEpoch)");
}
sendqueue.offer(notmsg);
}
}这个方法主要是将封装一个ToSend对象并加入到发送队列中,那这个队列是被谁消费的呢?浏览FastLeaderElection类结构,我们会看到WorkerSender和WorkerReceiver两个类,不用想,一个是接收,一个发送。我们这里是广播消息,那肯定就是WorkerSender类了(这两个类都是继承自Thread类的)。我们直接看run方法:
public void run() {
while (!stop) {
try {
ToSend m = sendqueue.poll(3000, TimeUnit.MILLISECONDS);
if(m == null) continue;
process(m); // 发送ToSend
} catch (InterruptedException e) {
break;
}
}
}最终会调用QuorumCnxManager的toSend方法:
public void toSend(Long sid, ByteBuffer b) {
if (self.getId() == sid) { // 发送给自己不需要走网络通信,直接放到接收队列中即可
b.position(0);
addToRecvQueue(new Message(b.duplicate(), sid));
} else {
// 发送给其它节点,需要判断之前是否发送过
if (!queueSendMap.containsKey(sid)) {
// 未发送过则新建发送队列,SEND_CAPACITY为1,表示每次只发送一个消息
ArrayBlockingQueue<ByteBuffer> bq = new ArrayBlockingQueue<ByteBuffer>(
SEND_CAPACITY);
queueSendMap.put(sid, bq);
addToSendQueue(bq, b);
} else {
// 前一个消息还未发送完成,则重新发送
ArrayBlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);
if(bq != null){
addToSendQueue(bq, b);
} else {
LOG.error("No queue for server " + sid);
}
}
connectOne(sid); // 真正的底层传输逻辑
}
}至此Leader的选举分析就全部完成,总的也就涉及到以下几个类
- QuorumPeerMain:启动类
- QuorumPeer:集群环境辅助初始化类
- FastLeaderElection:选举算法的实现,其中包含了以下几个内部类:Notification:表示收到的投票信息ToSend:表示发送给其它服务器的投票信息Messager:包含了WorkerSender发送类和WorkerReceiver接受类,通过这两个类去发送和接收投票信息
总结
本篇是Zookeeper系列的开篇,着重讲解了分布式一致性协议以及Zookeeper的基本概念和Leader选举流程,了解原理才能够让我们更好的理解技术的使用场景和处理的问题,在架构设计时才能更有理有据的做出取舍。
标签:事务,Zookeeper,投票,new,服务器,Leader,分布式 From: https://www.cnblogs.com/guoyu1/p/17879284.html