本文分享自华为云社区《从HumanEval到CoderEval: 你的代码生成模型真的work吗?》,作者:华为云PaaS服务小智 。
本文主要介绍了一个名为CoderEval的代码生成大模型评估基准,并对三个代码生成模型(CodeGen、PanGu-Coder和ChatGPT)在该基准上的表现进行了评估和比较。研究人员从真实的开源项目中的选取了代码生成任务来构建CoderEval,并根据对外部依赖的程度为标准将这些任务分为6个等级、根据生成的目标分为3类生成任务,以更多维地评估不同大模型在不同上下文场景中的生成效果。
实验结果表明,这三个模型在生成自包含函数方面的效果明显优于其他任务,但实际项目中的函数大部分依赖不同程度的上下文信息,因此提高模型对上下文信息的考虑和利用能力对于代码生成技术的实际可用性非常重要。该工作由北京大学和华为云Paas技术创新LAB合作完成,论文已经被软件工程顶会ICSE 2024录用。

从HumanEval到CoderEval
就像ImageNet之于图像识别,Defects4J之于缺陷检测,在以工具和方法为主要贡献的研究领域中,一个被广泛接受和采用的评估数据集及其配套的基准指标,对该领域的研究和发展至关重要。一方面,评估方式作为度量尺,可以在同一维度上起到横向对比各类方法的水平,并估计距离成熟实用的差距;另一方面,评估方式作为风向标,直接指导着各种方法共同的优化和迭代目标,决定了研究者们前进的方向。
在代码生成领域,当前最广泛被使用的是OpenAI在Codex论文中开源的HumanEval,该基准测试集由164道由OpenAI工程师手动编写的编程任务组成,以一定程度上确保与训练集的不重叠性。初版的HumanEval仅支持Python语言,每个编程任务包括了任务描述、参考代码、若干测试样例等。近期有部分研究者将HumanEval扩展到多种编程语言,例如:清华大学CodeGeex团队基于HumanEval开源了HumanEval-X,将HumanEval扩展到C++、Java、JavaScript、Go等语言;于2022年8月19日发布在arXiv上发布的一篇论文提出了MultiPL-E,将HumanEval扩展到了18种语言。
然而,HumanEval本身存在一些问题,这些问题使得它并不适合成为代码生成任务的一个评估平台,特别是对于以实际开发为目标的代码生成研究和工具。基于HumanEval进行扩展的一类工作仅仅是将HumanEval中的任务描述、参考代码、测试样例以及执行环境等翻译或适配到了其他语言,实质上并未解决HumanEval自身存在的一些问题。那么,这些问题有哪些呢?经过对HumanEval中的任务和测试样例、以及多个模型生成结果的人工检视,我们主要归纳出以下问题:
1.领域单一,仅覆盖了语言本身基础的编程知识,如数据结构操作、简单算法等;
2.任务本身过于简单,参考代码均为自包含的单一函数,并未考虑复杂类型、自定义类型、三方库、跨过程调用等情况。
根据我们对GitHub仓库数据的统计,HumanEval所对应的自包含单一函数在Top 100的Python项目中只占11.2%,在Top 100的Java项目中只占21.3%,因此,HumanEval可能实际上无法准确反映代码生成模型在实际项目级开发中的表现。
针对HumanEval的限制和不足,我们提出了CoderEval,一个面向真实场景和实际用户的代码生成模型可用性评测系统。CoderEval在一定程度上解决了当前被广泛使用的评测基准的问题,主要体现在以下几点:
1.直接来源于真实的开源项目,覆盖多个领域,从而可以全面评估代码生成在不同领域中的表现;
2. 考虑了复杂数据类型或项目代码中开发者自定义的类型,支持面向对象特性和跨过程调用;
3. 尽量保证覆盖率和完备性,从而在一定程度上降低测试误报率。
综上所述,相比于HumanEval,CoderEval与实际开发场景中的生成任务更加对齐,在基于大模型的代码生成工具逐步落地并商业化的背景下,可能更加真实地反映并比较不同模型在实际落地为工具之后的开发者体验。接下来,我们将简要介绍CoderEval的组成部分、构建过程以及使用方法。
CoderEval论文目前已被ICSE2024接收:
https://arxiv.org/abs/2302.00288
CoderEval-GitHub目前已开源:
https://github.com/CoderEval/CoderEval
CoderEval:面向实际开发场景的代码生成模型评估
CoderEval组成部分
整体而言,CoderEval主要由三部分组成:
1.生成任务:以函数/方法为基本单位的代码生成任务,包括任务描述(即自然语言注释)、函数签名、参考代码(即原始代码实现)、所在文件所有上下文代码、所在项目其他文件内容等;
2. 测试代码:针对某一编程任务的单元测试,一个编程任务可能对应一到多个测试文件、一到多个测试方法,以及附加的测试数据(如操作文件的编程任务中的文件等);
3. 测试环境:由于CoderEval中的函数/方法允许使用自定义类型、调用语言标准库或三方库、调用项目中其他方法等,因此需要在配置好所在项目的环境中执行。为此,CoderEval基于Docker构建了沙箱测试环境,其中包含了所有被测项目及其依赖,并且附有单一入口的自动化执行程序。此测试环境预计将以线上服务的形式提供。
CoderEval构建过程

图1 CoderEval的构建过程
图1展示了针对某一种编程语言(目标语言)构建CoderEval的一般性的过程,主要分为三个部分:
1.目标选取:从GitHub或CodeHub选择目标语言为主的项目中的高质量目标函数/方法,作为测试任务
2. 数据收集:针对每个候选测试任务,分析和收集目标函数/方法的元信息、自身信息、测试信息等
3. 环境构建:准备目标项目和依赖,为测试代码提供执行环境,并通过执行测试验证测试代码和目标代码的正确性
作为第一个版本,CoderEval首先支持了两大语言:
• CoderEval4Python:包含来自43个项目的230个生成任务
• CoderEval4Java:包含来自10个项目的230个生成任务
为了真实反映代码生成模型在实际项目开发中的效果和价值,我们需要从真实、多元的开源项目中选取高质量的生成任务,并配备尽可能完善的测试。为此,我们首先爬取了GitHub上Python和Java项目的所有标签,根据最频繁的14个标签和标星数筛选出若干项目,然后抽取出项目中所有的测试代码以及被测函数/方法,仅保留符合以下全部条件的部分:
• 并非以测试为目的的、deprecated的、接口形式的函数/方法
• 包含一段英文自然语言描述作为函数/方法级注释
• 可以在测试环境中正确执行并通过原始测试
经过这些筛选保留下来的函数/方法,再经过人工筛选和程序分析,构成了CoderEval中的代码生成任务,每个生成任务提供的信息有:
• 元信息(Meta):所在项目地址、文件路径、行号范围等
• 自身信息(Native):该函数/方法的原始注释、签名、代码等
• 上下文信息(Context,可选):所在文件内容、可访问上下文信息、所使用上下文信息、运行级别分类等
• 测试信息(Test):人工标注的自然语言描述、在原始代码上的若干测试样例等
CoderEval使用方法
CoderEval支持函数/方法块级生成(Block Generation):根据注释形式的任务描述和/或函数签名,生成实现对应功能的完整函数体。
CoderEval支持的指标:基于运行的指标(Comparison-based Metrics)。与HumanEval一致,我们同样采取了Pass@k作为测试指标,从而评估所生成代码实际的运行效果,允许模型生成不同版本的实现。
CoderEval支持更细粒度的评估:
1. 上下文感知能力评估:我们在研究中发现,对于非自包含函数/方法,其代码实现中的外部依赖信息对于其功能和行为非常关键。因此,模型的上下文感知能力(Context-awareness,即正确生成外部依赖信息的能力)是另一个重要指标。CoderEval提供了生成任务所在项目以及文件内容可作为输入,原始代码中实际用到的上下文信息作为期望输出,因此,可以分析并计算生成代码中上下文信息的准确率以及召回率,作为上下文感知能力的评估指标。
2. 分级评估:如图2所示,依据所依赖的上下文信息,CoderEval进一步将生成任务分成了6个级别(self_contained、slib_runnable、plib_runnable、class_runnable、project_runnable),代表所对应代码可执行的环境(标准库、第三方库、当前文件、当前项目等)。CoderEval支持更细粒度地测试和分析模型在每个级别上的生成能力,从而可以全面地分析当前模型的不足和待优化的方向(如引入课程学习、针对性微调、上下文可感知度的针对性提升等)。
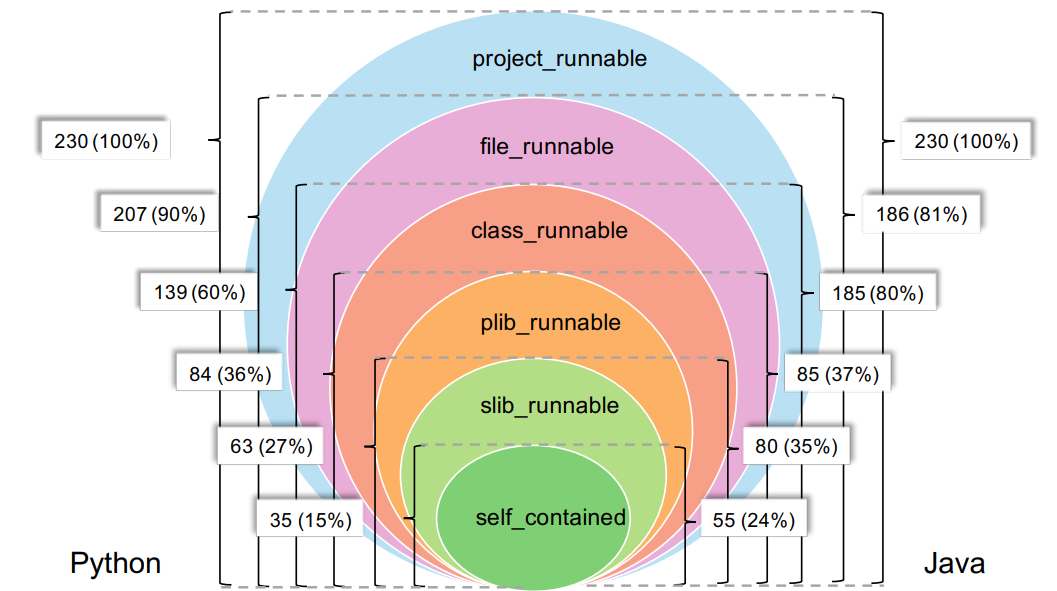
图2 CoderEval中按依赖级别的数据分布
3. Prompt评估:CoderEval同时提供了原始注释和开发者另外标注的代码功能描述,从而研究模型记忆效应、Prompt形式、Prompt质量对不同模型的影响。
由于CoderEval源于实际的开源项目,并且我们无法精确获得或控制各个模型训练数据,因此可能无法避免存在因模型的记忆效应和复制机制产生的误差。CoderEval缓解此类误差的主要措施包括:
1.为所有任务补充了人工改写的注释替代原注释,该部分可确保不存在于训练集中。为此,我们同时会测试。
2. 可增大采样次数并综合基于运行的指标和基于比较的指标进行分析,从而分析模型是否能实现与原代码不同、但又可通过测试的方案。
CoderEval实测结果
我们测试了工业界为主提出的、具有代表性的三个模型在CoderEval上的表现,被测模型包括:
1.CodeGen(Salesforce):采用GPT-2架构,在自然语言上先进行预训练,再在多种编程语言混合语料上继续训练,最后在单一编程语言上进行微调。
2. PanGuCoder(Huawei):基于PanGu-alpha架构,采用<自然语言描述, 程序语言代码>对的形式和多阶段预训练方法,专注于Text2Code任务,对中文支持较好。
3. ChatGPT(OpenAI):基于GPT-3.5系列模型使用人类反馈进行微调,可以根据用户的指令或问题来生成代码。
部分实验结果如下:
1. 如表1所示,在CoderEval和HumanEval上,ChatGPT的效果都大幅超出其他两个模型,原因可能来自于更大的模型规模、更充分的训练度、更优的超参数等方面。
表1 三个模型在CoderEval上和HumanEval上的
总体效果对比
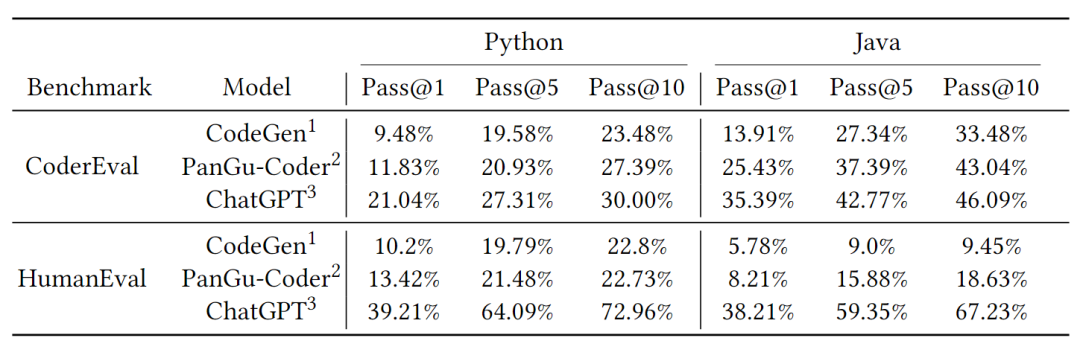
2. 如表1所示,在HumanEval上,ChatGPT的效果更是大幅超过其他模型,幅度要远大于在CoderEval上三个模型的差距。考虑到HumanEval的局限性,这一结果从侧面表明HumanEval可能已经不适合作为单一的代码生成Benchmark。
3. 如图3所示,在CoderEval上,三个模型正确生成的任务存在较大的交集(Python:32,Java:56),说明三个模型在解决部分任务上有共性能力;同时,对于仅有一个模型能正确生成、而其他两个模型未正确生成的任务而言,ChatGPT在Python和Java上都是最多的(Python:18,Java:27),说明ChatGPT在解决这部分任务上的能力具有显著优势;最后,三个模型一共解决的任务数仍仅占CoderEval所有任务数的约40%(Python:91/230)和59%(Java:136/230),说明三个模型的能力具有一定的互补性,且各自仍有较大提升空间。
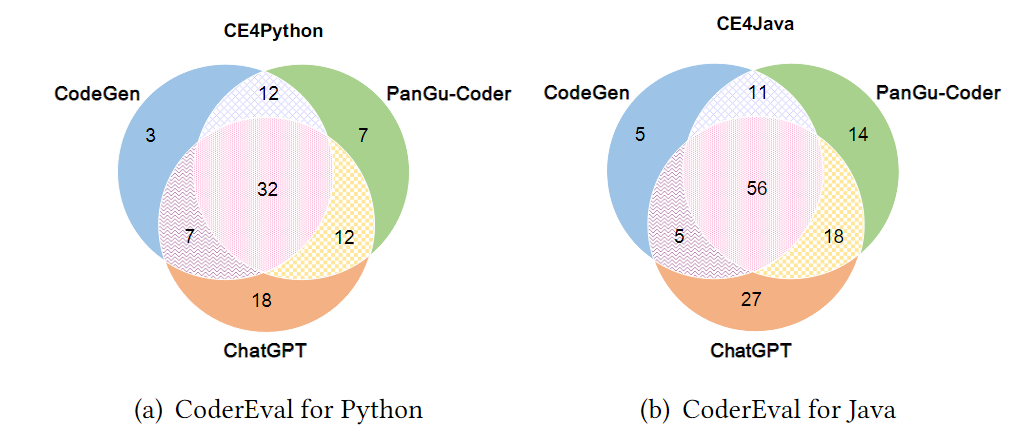
图3 三个模型在CoderEval上和HumanEval上
正确生成的题目数对比
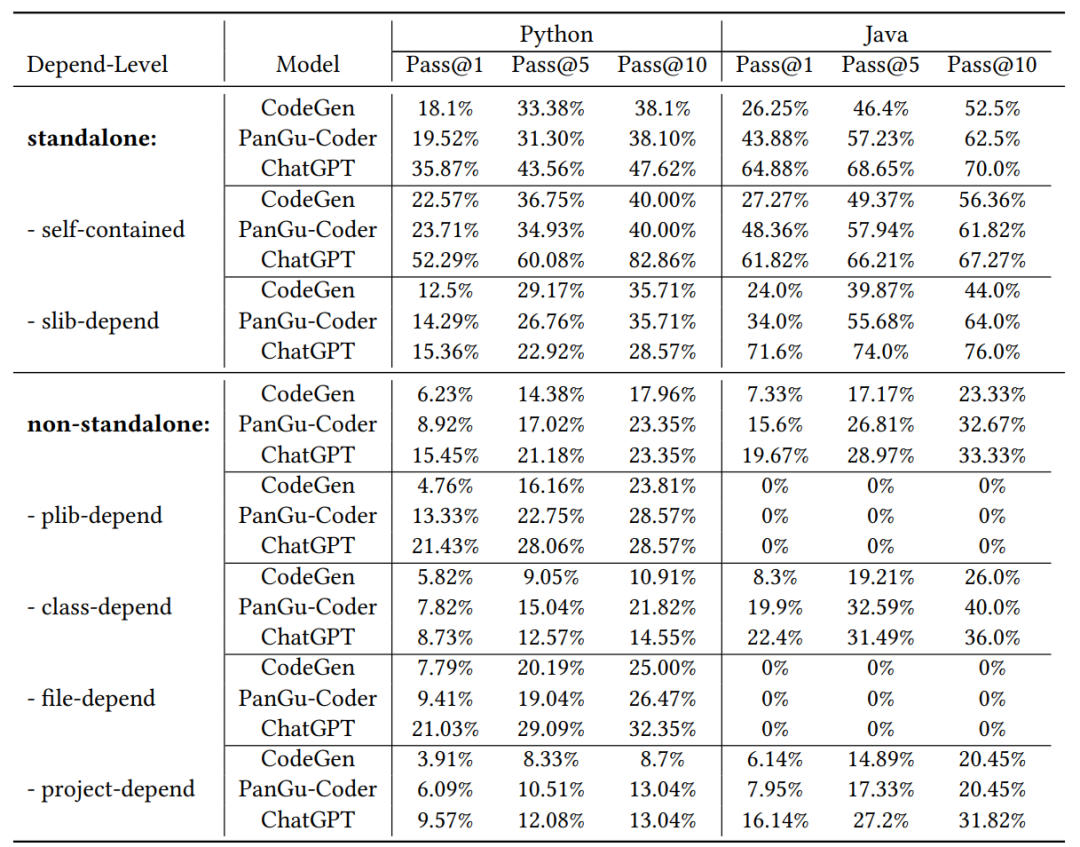
4. 如表2所示,在CoderEval的standalone子集上,三个模型的表现与HumanEval上基本接近,ChatGPT的表现大幅超过另外两个模型;但是,在其他依赖于上下文信息的生成任务上(占实际情况的60%以上),三个模型的表现都有较大下降,即使是最强大的ChatGPT的表现也有很大波动,甚至在部分级别上三个模型生成10次的结果均错误,这一定程度上说明了依赖上下文的代码生成任务是大模型代码生成下一步优化的重点方向。
表2 三个模型在CoderEval的两类子集上的表现对比
更多的实验数据以及分析过程,请见CoderEval论文。
总结
CoderEval论文目前已公开在arXiv(https://arxiv.org/abs/2302.00288 ),其开源项目版可在GitHub获得(https://github.com/CoderEval/CoderEval ),欢迎大家关注并一键Follow+Star。我们致力于将CoderEval打造为一个客观、公正、全面的Benchmark,不过,尽量我们已努力完善,但它仍然不可避免地存在一些限制和错误。因此,我们希望借助代码生成研究者社区的力量,持续迭代和更新CoderEval的版本,以扩展和完善其语言支持、数据集、测试方式等方面,从而持续推动代码智能社区的研究与落地。
标签:代码生成,模型,work,生成,HumanEval,任务,CoderEval From: https://www.cnblogs.com/huaweiyun/p/17875505.html