【一】垃圾回收机制是什么
- 专门用来回收不可用的变量值所占用的内存空间(在内存中,没有变量名指向的数据都是垃圾数据)
【二】为什么要有垃圾回收机制
- 程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃
- 因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
【三】垃圾回收机制原理
- 引用计数为主,垃圾回收、分代回收为辅。
【1】引用记数
(1)引用计数
- 引用计数就是:变量值被变量名关联的次数
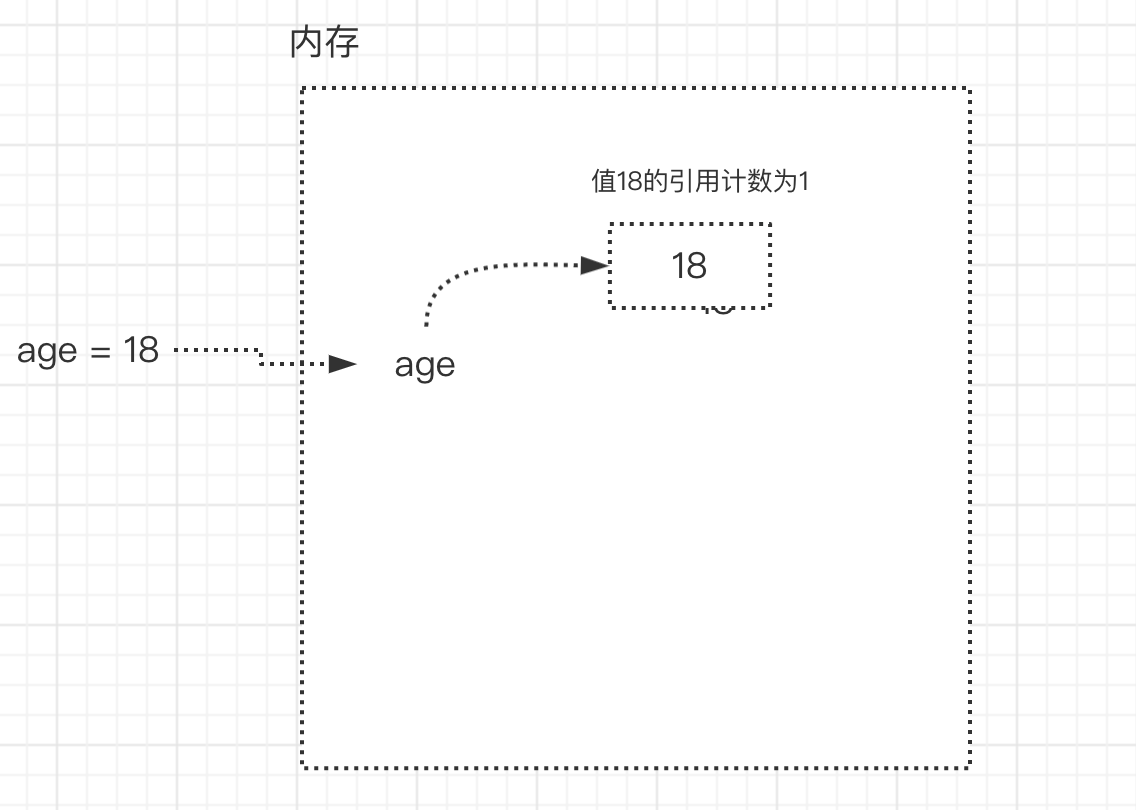
- 如:age=18
- 变量值18被关联了一个变量名age,称之为引用计数为1
(2)引用计数增加
- age=18 (此时,变量值18的引用计数为1)
- m=age (把age的内存地址给了m,此时,m,age都关联了18,所以变量值18的引用计数为2)
(3)引用计数减少
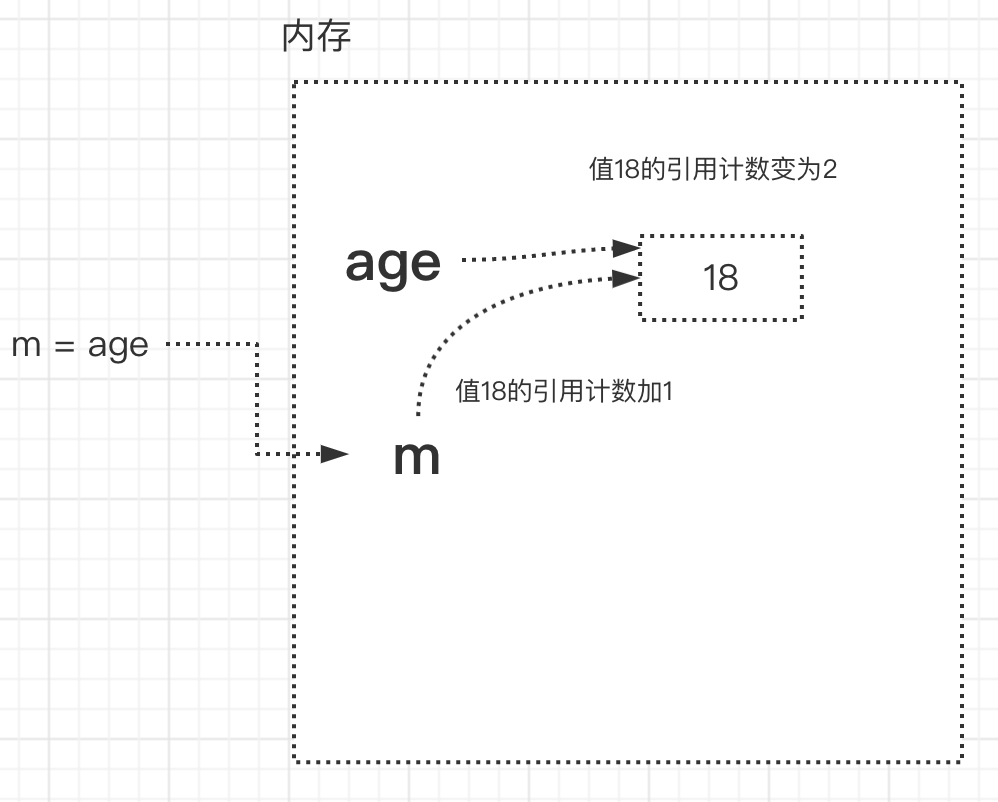
- age=10(名字age先与值18解除关联,再与3建立了关联,变量值18的引用计数为1)
- del m(del的意思是解除变量名x与变量值18的关联关系,此时,变量18的引用计数为0)

- 值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
【2】标记清除
(1)标记-清除算法
- 在Python的内存管理中,标记-清除算法是一种常用的垃圾回收(Garbage Collection)方法之一。它的主要目标是解决循环引用导致的内存泄漏问题。
- 通俗理解为当内存空间即将沾满的时候,python会暂停程序的运行,从头到位扫描一遍,并且把扫描出来的垃圾数据做标记,然后,一次性做清除处理
- 容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。
- 而“标记-清除”计数就是为了解决循环引用的问题。
- 标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作
(2)标记阶段
- 通俗地讲就是:栈区相当于“根”,凡是从根出发可以访达(直接或间接引用)的,都称之为“有根之人”,有根之人当活,无根之人当死。
- 标记GC Roots: 栈区中的所有内容或者线程都可以作为GC Roots对象。这些对象被认为是根源,是可达的。在标记阶段,遍历GC Roots对象,将可以直接或间接访问到的对象标记为存活对象。
- 标记存活对象: 遍历所有GC Roots的对象引用链,将可达的对象进行标记。这些对象将被保留,认为是存活的。
(3)清除阶段
- 清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
- 清除非存活对象: 遍历整个堆内存,将没有被标记的对象认定为非存活对象,进行清除操作。这些对象所占用的内存空间将被释放。
(4)循环引用的处理
- 标记-清除算法解决了循环引用的问题。当两个对象互相引用,但与GC Roots没有直接引用关系时,它们在标记阶段将被标记为非存活对象,然后在清除阶段被释放。
- 基于上例的循环引用,当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容以及直接引用关系
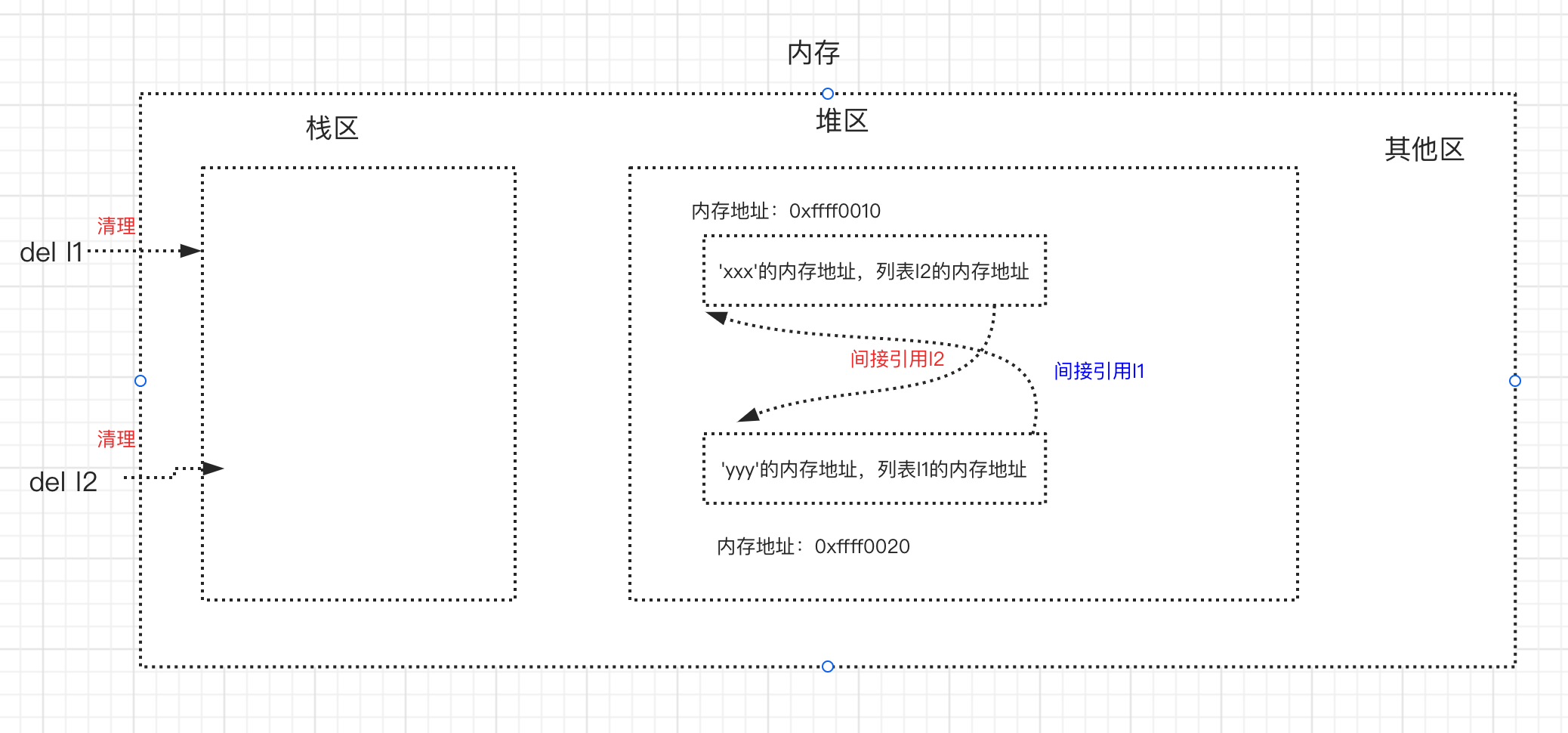
- 这样在启用标记清除算法时,从栈区出发,没有任何一条直接或间接引用可以访达l1与l2,即l1与l2成了“无根之人”,于是l1与l2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
(5)标记-清除的问题
- 效率: 标记-清除算法可能导致程序在执行过程中停顿,因为在标记和清除阶段,程序的执行会被暂停一段时间。这可能会影响对实时性要求较高的应用程序。
- 空间碎片: 清除阶段释放的内存可能导致堆内存出现空间碎片。在长时间运行的程序中,这可能会导致内存的浪费。
【3】分代回收
- 核心的思想:因为GC机制每次回收内存,都需要将所有对象的引用计数都遍历一次,这是非常耗时间的操作,所以在历经多次扫描的情况下,都没有被回收的变量,GC机制就会将他们按等级划分,GC机制就会认为该变量是常用的量,对其的扫描频率就会降低
(1)分代回收的核心思想
- 分代回收是一种垃圾回收的策略,其核心思想是根据对象的存活时间将其划分为不同的代(generation)。
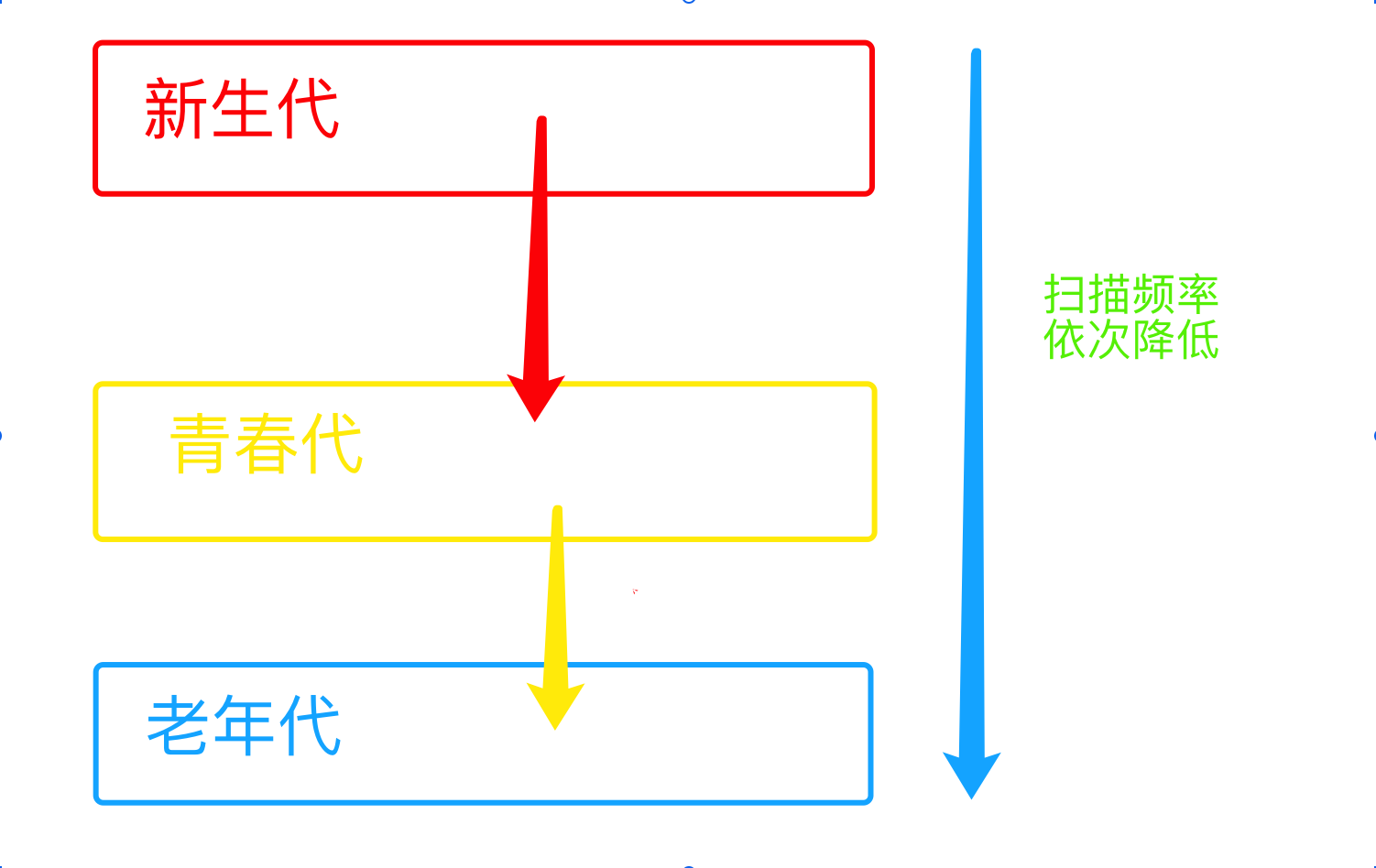
- 在Python中,通常将内存分为三代:
- 新生代(young generation): 包含了大部分新创建的对象,其存活时间较短。
- 青春代(youth generation): 包含了已经经历过垃圾回收一次的新生代对象,存活时间较长。
- 老年代(old generation): 包含了已经经历过多次垃圾回收的对象,存活时间较长。
(2)具体实现原理
-
大部分对象在其刚被创建的时候往往很快变得不可达,即它们的生命周期较短。
-
部分对象在经历了一次垃圾回收后,仍然存活的概率较高,即它们的生命周期较长。
-
因此,分代回收将内存划分为不同的代,并根据代的特点采用不同的垃圾回收策略。
- 新生代中的对象:采用较为频繁的垃圾回收,通常使用标记-复制算法,即标记存活对象,然后将存活对象复制到另一块内存中,最后清理掉原有的内存。这能有效处理新生代中大部分对象的垃圾回收。
- 青春代中的对象:采用标记-清除算法,其目标是处理在新生代中经历了一次回收的对象。由于这些对象的生命周期较长,不需要频繁地进行回收。
- 老年代中的对象:采用标记-清除算法或标记-整理算法。老年代的对象生命周期更长,采用相对稳定的垃圾回收策略。
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代) 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代, 青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间, 接下来,青春代中的对象,也会以同样的方式被移动到老年代中。 也就是等级(代)越高,被垃圾回收机制扫描的频率越低(3)回收
- 分代回收机制对不同代的垃圾回收频率进行了调整:
- 新生代的垃圾回收比较频繁,因为大部分对象在新生代中被创建后很快就变得不可达。
- 青春代的垃圾回收频率较低,因为这些对象已经经历了一次回收,存活概率相对较高。
- 老年代的垃圾回收频率较低,因为老年代的对象生命周期较长。

(4)分代回收的问题
- 新生代到青春代的延迟问题: 当一个变量从新生代移入青春代时,其绑定关系解除,应该被回收。然而,由于青春代的扫描频率低于新生代,可能导致这些变量的垃圾没有得到及时的清理。
- 权重提升的不精确性: 分代回收中通过给对象的权重进行提升来判断其生命周期。然而,这种机制并不完美,可能存在一些不够准确的情况,导致有些垃圾对象没有被及时清理。
- 无法解决循环引用的所有问题: 尽管分代回收可以处理一些循环引用的情况,但并不能解决所有可能的循环引用问题。在某些情况下,仍然需要手动处理循环引用,例如通过显式地断开引用或使用弱引用。
- 全局解释器锁(GIL): 在多线程的情况下,全局解释器锁可能会影响垃圾回收的效率,尤其是对于CPU密集型的任务。在处理大规模数据或高并发情况下,需要考虑GIL的影响。
- 没有十全十美的方案:
- 毫无疑问,如果没有分代回收,即引用计数机制一直不停地对所有变量进行全体扫描,可以更及时地清理掉垃圾占用的内存,但这种一直不停地对所有变量进行全体扫描的方式效率极低,所以我们只能将二者中和。