一、实验目标:
熟悉模块的的用法,练习编写爬虫
二、实验要求:
编写代码,完成功能
三、实验内容:
(1)使用urllib模块或request模块读取网页内容,并利用BeautifulSoup模块进行内容解析,编写爬虫从http://www.cae.cn/cae/html/main/col48/column_48_1.html爬取中国工程院院士信息
- 模块导入:
import requests
from bs4 import BeautifulSoup
- 伪造请求头:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
- 爬取信息:
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
response1 = requests.get("http://www.cae.cn/cae/html/main/col48/column_48_1.html",headers=headers)
content = response1.text
soup = BeautifulSoup(content, "html.parser")
names_lists = soup.find_all("li", attrs={"class": "name_list"})
for name in names_lists:
li = BeautifulSoup(str(name), "html.parser")
Name = li.find_all('a')
link = Name[0].get('href')
Link = "http://www.cae.cn"+link
Content = requests.get(Link,headers=headers).text
Soup = BeautifulSoup(Content,"html.parser")
Intro = Soup.find_all("div",attrs={"class":"intro"})
intro = BeautifulSoup(str(Intro[0]),"html.parser")
text = intro.find_all("p")
Text=''
for i in text:
Text=Text+i.text
with open(r"C:\Users\86135\Desktop\院士名单.txt", 'a', encoding='utf-8') as f:#写入文件
f.write(Name[0].string+'\n')
f.write(Text+'\n')
f.write('\n')
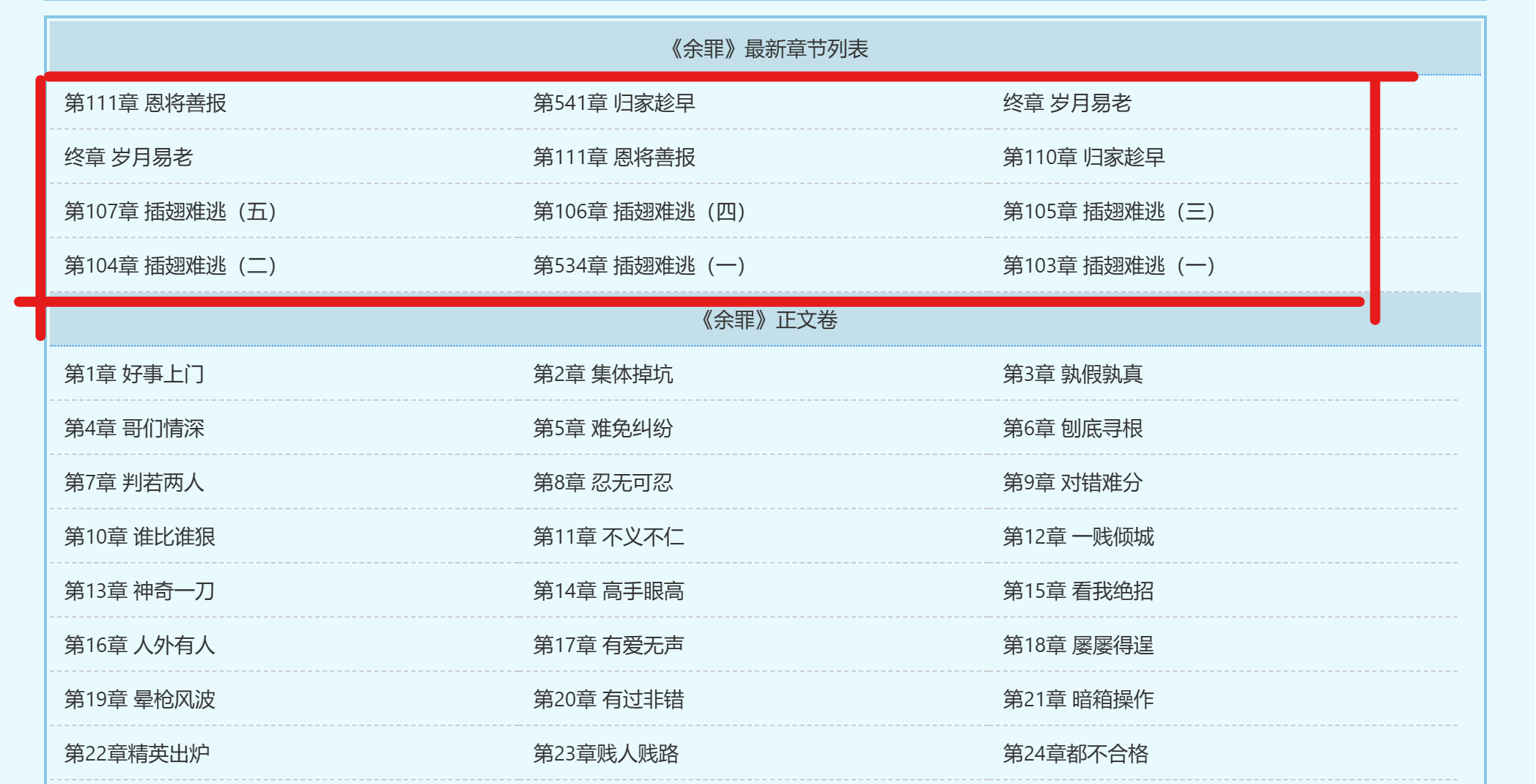
- 爬取结果:

(2)使用urllib模块或request模块读取网页内容,并利用BeautifulSoup模块进行内容解析,编写爬虫从https://www.biqukan.com/2_2671爬取小说《余罪》的内容。要求最终爬取的内容从第一章开始,且不存在大量空格等非必要字符。
由于小说首页不是从第一章开始,我们需要确定第一章的起始位置和最后一章的终止位置
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
content = requests.get("https://www.biqukan8.cc/2_2671",headers=headers).text
soup = BeautifulSoup(content,"html.parser")
titles = soup.find_all('a')
num = 0
global start , end
for title in titles:
num = num + 1
if title.string == '第1章 好事上门':
start = num
if title.string == "都市之战神之王陈锋林雨欣":
end = num
然后处理html中的a标签中的href元素得到每一章跳转的url
for i in range(start-1,end-1):
link = BeautifulSoup(str(titles[i]),"html.parser")
Li = link.find("a")
Link = "https://www.biqukan8.cc/"+Li["href"]
然后爬取每一个Link中的特征为div,class为showtxt,id为content的小说正文,并将标题和正文写入文件
for i in range(start-1,end-1):
link = BeautifulSoup(str(titles[i]),"html.parser")
Li = link.find("a")
Link = "https://www.biqukan8.cc/"+Li["href"]
content = requests.get(Link,headers=headers).text
Soup = BeautifulSoup(content,"html.parser")
novel_content = Soup.find('div', {'class': 'showtxt', 'id': 'content'})
novel_text = novel_content.get_text(separator="\n")
with open(r"C:\Users\86135\Desktop\余罪.txt", 'a', encoding='utf-8') as f:
f.write(titles[i].string+'\n')
f.write(novel_text+'\n')
f.write('\n')
最后添加一个可以实时显示进度的功能,完整代码如下:
import requests
import sys
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
content = requests.get("https://www.biqukan8.cc/2_2671",headers=headers).text
soup = BeautifulSoup(content,"html.parser")
titles = soup.find_all('a')
num = 0
global start , end
for title in titles:
num = num + 1
if title.string == '第1章 好事上门':
start = num
if title.string == "都市之战神之王陈锋林雨欣":
end = num
for i in range(start-1,end-1):
link = BeautifulSoup(str(titles[i]),"html.parser")
Li = link.find("a")
Link = "https://www.biqukan8.cc/"+Li["href"]
content = requests.get(Link,headers=headers).text
Soup = BeautifulSoup(content,"html.parser")
novel_content = Soup.find('div', {'class': 'showtxt', 'id': 'content'})
novel_text = novel_content.get_text(separator="\n")
with open(r"C:\Users\86135\Desktop\余罪.txt", 'a', encoding='utf-8') as f:
f.write(titles[i].string+'\n')
f.write(novel_text+'\n')
f.write('\n')
if (i + 1) % 10 == 0:
# 将下载进度输出到控制台,实时变动
sys.stdout.write(" 已下载:%.3f%%" % float((i + 1) * 100 / (end-start+2)) + '\r')
# 刷新缓存区
sys.stdout.flush()
print('下载完成')
print("————————END————————")
- 爬取结果:
(3)学习使用Feapder框架,编写爬虫,爬取中国工程院院士信息。
import feapder
class TophubSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("http://www.cae.cn/cae/html/main/col48/column_48_1.html")
def parse(self, request, response):
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
print(response.xpath("//meta[@name='description']/@content").extract_first())
print("网站地址: ", response.url)
# 提取所有class为name_list的li元素下的a元素的href和文本内容
items = response.xpath("//li[@class='name_list']//a")
for item in items:
href = item.xpath("@href").extract_first()
person_name = item.xpath("string(.)").extract_first()
print("Found href:", href)
# Follow the link and parse the information from the 'intro' div
yield feapder.Request(url=href, callback=self.parse_intro, meta={'person_name': person_name})
def parse_intro(self, request, response):
# Extract information from the 'intro' div
intro_text = response.xpath("//div[@class='intro']//p/text()").extract()
# Concatenate the text and remove extra spaces
formatted_text = " ".join(map(str.strip, intro_text))
# Extract person_name from meta
person_name = request.meta['person_name']
# Write person_name and information to the file
with open(r"C:\Users\86135\Desktop\院士信息.txt", "a", encoding="utf-8") as file:
file.write(person_name + "\n")
file.write(formatted_text + "\n")
print(f"Information for {person_name} has been saved to 工程院士信息.txt")
if __name__ == "__main__":
TophubSpider().start()
四、实验总结:
本次实验对python的BeautifulSoup+request模块的使用有了更深刻的理解,对Feapder框架的使用有了进一步的了解。
标签:name,text,Feapder,BeautifulSoup,content,headers,html,模块 From: https://www.cnblogs.com/Smera1d0/p/17832857.html