这是谷歌在9月最近发布的一种新的架构 TSMixer: An all-MLP architecture for time series forecasting ,TSMixer是一种先进的多元模型,利用线性模型特征,在长期预测基准上表现良好。据我们所知,TSMixer是第一个在长期预测基准上表现与最先进的单变量模型一样好的多变量模型,在长期预测基准上,表明交叉变量信息不太有益。”
研究人员将TSMixer与各种Transformer模型进行了比较(后者输给了TSMixer)。但是当引入一个令人尴尬的简单线性模型DLinear作为Dynamic Model Selection (DMS), 预测基线进行比较。结果表明,在大多数情况下,DLinear在9个广泛使用的基准测试中也优于现有的基于transformer的解决方案,并且通常有很大的优势,所以目前来看Transformer模型并不太适合时间序列的预测,或者说Transformer可能还没能找到适合时间序列预测的方式(就像以前没人想过VIT能够比CNN更好一样)
所以TSMixer是不是能够更好的进行预测,我们也不知道。但是学习TSMixer的架构和思路是对我们有非常大的帮助的。尤其是这是谷歌发布的模型,肯定值得我们深入研究。
为什么单变量模型胜过多变量模型
这是时间序列预测中最有趣的问题之一。理论上来说多元模型应该比单变量模型更有效,这是很自然的,因为它们能够利用交叉变量信息(更多变量→更深入的见解->更好的预测)。但是在许多常用的预测基准上,基于Transformer的模型可以被证明比简单的单变量时间线性模型要差得多。多变量模型似乎存在过拟合的问题,尤其是当目标时间序列与其他协变量不相关时(在表格数据的深度学习中看到了类似的情况——树胜过深度学习,因为深度学习模型往往受到不相关/无信息特征的影响)。
多元模型的这一弱点导致了两个有趣的问题
1、交叉变量信息真的能为时间序列预测提供好处吗?
2、当交叉变量信息不是有益的,多变量模型仍然可以表现得像单变量模型一样好吗?
当我们考虑到某些重要的预测用例需要处理非常混乱的高维数据时,第二点尤其重要。例如供应链风险预测,必须依靠经济和社会指标的数据来预测安全风险。我们必须进行大量的试验和错误来确定有用的指标(这意味着数据漂移的固有波动性是一个杀手)。对非信息性交叉变量具有鲁棒性的模型对波动性具有更强的鲁棒性——允许更稳定的部署。

当谈到Transformer时,时间序列预测还有另一个缺陷阻碍了他们。在Transformer中多头自我注意力从一件好事变成了一件坏事。
因为Transformer架构的主要工作能力来自于它的多头自关注机制,该机制具有在长序列(例如,文本中的单词或图像中的2D补丁)中提取配对元素之间的语义相关性的显著能力,并且该过程是排列不变的。但是对于时间序列分析,我们主要对一组连续点之间的时间动态建模感兴趣,其中顺序本身通常起着最关键的作用。”
那么,TSMixer如何适应这种情况呢?
TSMixer架构
作者将TSMixer的设计理念描述如下:
在我们的分析中表明,在时间模式的常见假设下,线性模型具有naïve解决方案,可以完美地恢复时间序列或误差的位置边界,这意味着它们是更有效地学习单变量时间序列静态时间模式的解决方案。相比之下,为注意力机制找到类似的解决方案并非易事,因为每个时间步的权重都是动态的。所以我们开发了一个新的架构,将Transformer的注意力层替换为线性层。得到的TSMixer模型类似于计算机视觉的MLP-Mixer方法,在多层感知器的不同方向上交替应用,我们分别称之为时间混合和特征混合。TSMixer体系结构有效地捕获时间模式和交叉变量信息
事实证明,“它们的时间阶跃依赖特征使时间线性模型成为在常见假设下学习时间模式的绝佳候选者。”因此,TSMixer的创建者决定通过两个很酷的步骤来增强线性模型
将时间线性模型与非线性(TMix-Only)叠加——非线性是深度学习模型可以作为通用函数逼近器的秘密,因此这可以更好地建模复杂关系。
引入交叉变量前馈层(TSMixer)——用于处理交叉变量信息。
TSMixer架构看起来像这样
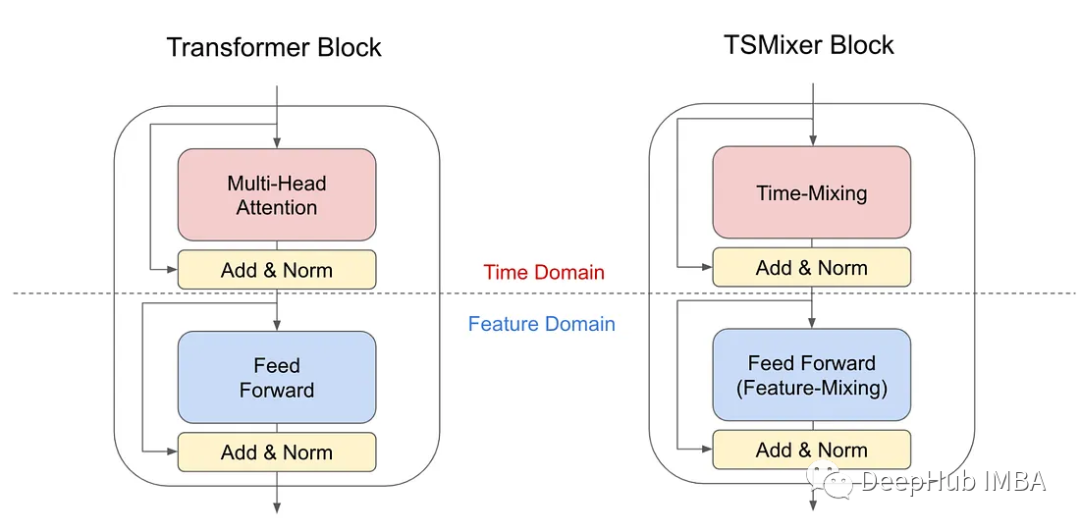
https://avoid.overfit.cn/post/7039c1a9ed3d4b97a64e89aa4266dd1d
标签:Transformer,架构,预测,模型,TSMixer,mlp,序列,变量 From: https://www.cnblogs.com/deephub/p/17771352.html