基于深度相机的3D建模
受到夏同学和王希同学的启发,我这几天看了下深度相机这一块,用于三维重建
三维重建的pipeline是:深度图采集(主动式和被动式)->深度图预处理(噪音)->场景表示(立体/表面表示)->深度图像融合(相邻帧,涉及到点对匹配和位姿联合优化)->纹理重建。trade-offs有:基于体素的重建方法的分辨率/精度和计算成本;基于点云的重建方法连接性的高精度和不能高效处理复杂拓扑结构;基于网格的重建的低计算成本和精度损失;
关键词:动作捕捉/姿势重建、旋转表示、三维
如何基于深度相机进行3D建模?
基本流程:深度图->去噪->位姿融合,找到点对应关系,估计变换矩阵->模型融合->颜色及纹理信息的渲染
三维重建领域主要的数据格式有四种
• 深度图(depth map),2D图片,每个像素记录从视点到物体的距离,以灰度图表示,越近越黑;
• 体素(voxel),体积像素概念,类似于2D之于像素定义;
• 点云(point cloud),每个点逗含有三维坐标,乃至色彩、反射强度信息;
• 网格(mesh),即多边形网格,容易计算。
Reference:
ECCV 2016: 基于体素 适用单/多视图 -> 缺点:分辨率和精度之间的trade-off

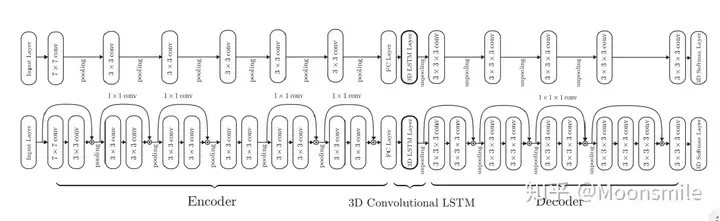
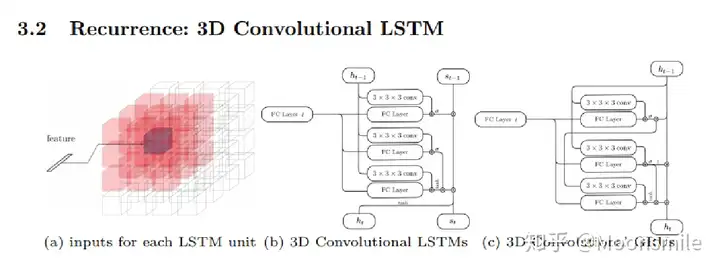
CVPR 2017: 基于点云 单视图

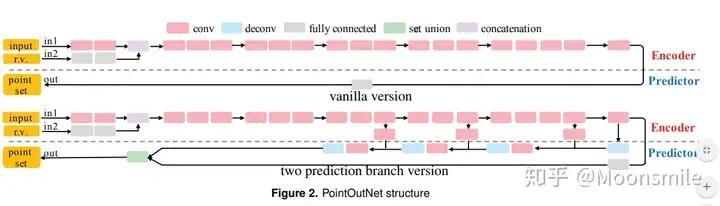
本文还系统地探讨了体系结构中的问题点生成网络的损失函数设计:
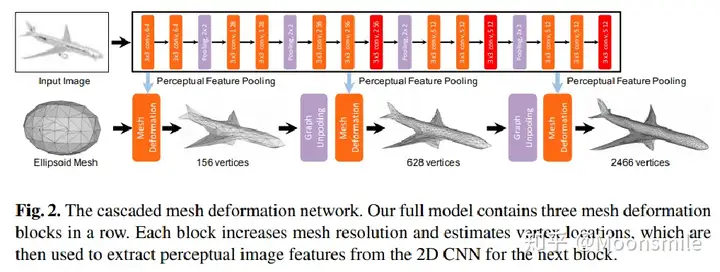
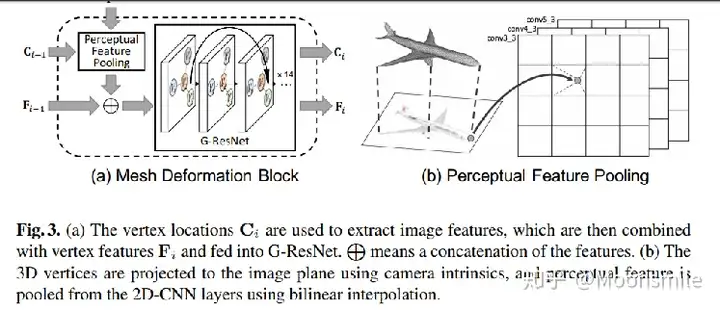
ECCV 2018: 三角网格 单图 -> 端到端的神经网络,粒度上coarse-to-fine,
Dataset: ShapeNet
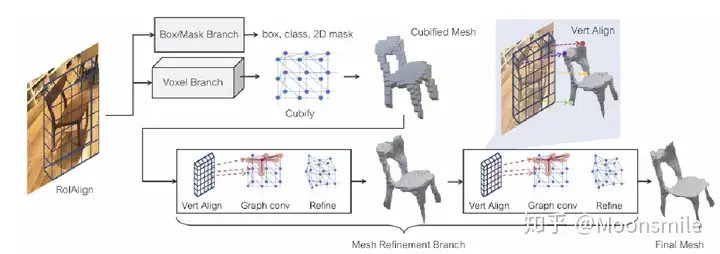
Mask R-CNN
- Mask RCNN可以看做是一个通用实例分割架构,以Faster RCNN原型,增加了一个分支用于分割任务;比Faster RCNN速度慢一些,达到了5fps。
应用:可用于人的姿态估计等其他任务;

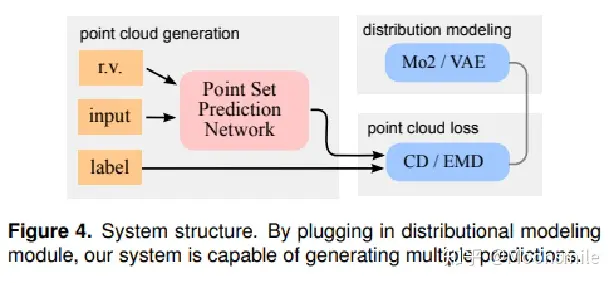
CVPR 2019: 对不可见部分(不确定性)进行建模 适用单/多视图 -> 提出了条件生成模型
实现逻辑: training with diversity constraints(introduce noise by sampling technology) -> predictor voting ensemble for inference with consistency constraints

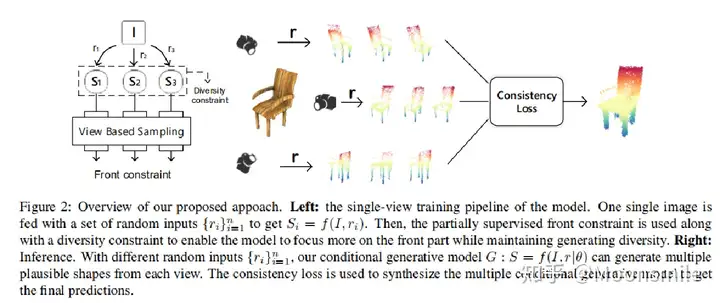
pipeline:
single-view形状生成:模型通过条件生成网络,将输入的RGB图像 I 和随机输入向量 r作为条件,生成预测的形状S。为了模拟单视图重建的不确定性,模型采用部分监督的架构,其中前部分的点云是通过视角采样得到的,而后部分的点云是通过条件生成模型生成的。模型使用前部分的点云作为监督信号,使用Chamfer距离或EMD距离作为损失函数来引导生成模型的预测。 -> 视角采样 -> 避免(病态)
single-view合成:模型将单视图形状生成扩展到多视图形状合成。对于每个单视图图像I,模型使用条件生成网络生成多个可能的形状预测。然后,模型通过在线优化来最小化多视图一致性损失,以获得最终的形状预测。最后,模型将多个视图的点云结果进行拼接,得到最终的预测结果。 -> 多视图一致性 -> 后部分点云
前部约束:模型引入了前部约束,通过视角采样层从特定视角获取形状的前部分。这样可以使生成模型更加关注形状的前部分,并使用Chamfer距离或EMD距离来引导生成模型的预测。 -> 前部分形状
多样性约束:为了使生成模型能够生成多个合理的形状预测,模型引入了多样性约束。通过使用两个不同的输入向量r1和r2,模型生成两个预测的点云S1和S2,并使用EMD距离来衡量它们之间的距离。通过最大化两个点云之间的距离与输入向量之间的距离的差值,模型可以生成多个满足前部约束的形状预测。 -> 多样性
latent space discriminator:为了更好地学习形状的先验知识,模型引入了潜空间鉴别器。模型首先在点云域上训练一个自编码器,然后将解码器固定在模型的末端,并在潜空间上应用WGAN-GP。这样可以通过鉴别器来学习形状的先验知识,并提高生成模型的性能。 -> 一致性
3D建模与深度相机简介
常见的深度相机
-
结构光
-
光源 + 投影仪 + 多个相机(形成三角结构)
-
结构光->目标对象表面->接收反射光的图案->根据位置角度等,得到每个像素点的深度值等空间信息
- 像素点 -> 物体 -> 三维模型
-
优势:高精度、高速度、无需接触
-
劣势:易受室外强光和镜面反射影响
-
-
ToF: Time of Flight
- 发射光->接收反射的光-> 检测光飞行往返时间->计算距离
- 优势:快速、精确、低功耗
- 劣势:获取的深度图分辨率不高,当测量较短距离时误差相对其他深度相机较大
三维模型表示方法及数据结构
立体表示方法:Volumetirc representation
-
TSDF:Truncated Signed Distance Function
-
带截断的
-
带符号距离场(函数):连续场((x,y,z)->NN->SDF:任意高分辨率)
- TSDF主要用于表示和融合三维空间中的点云数据。对于每个三维空间的网格单元(voxel),TSDF存储了该单元内距离表面的有符号距离值。有符号距离表示点云点相对于表面的距离,如果点在表面上方,则距离为正;如果点在表面下方,则距离为负。(二维连续场-整个模型的一个场,包络思想) KinectFusion:RGB-D-static-3D reconstruction; DynamicFusion:movement
- 通过遍历点云数据,将每个点映射到对应的网格单元,并更新该单元内的TSDF值。通常情况下,要对TSDF进行截断操作,将距离超过某个阈值的值截断为固定的最大或最小值,以限制距离函数的范围。SDF-3P-SDF-UDF
-
SDF: 3D信息(拓扑->3D,形状的刻画(表示=显式表示-点云...->分辨率bottleneck + 隐式表示-SDF(闭合曲面-内外,SDF变体-非闭合) + UDF-离空间表面最近的点,零等值面表面的提取精度不同,只有梯度信息,计算量up,精度不高)+颜色:传统渲染管线->2D上颜色比较多)
-
-
Octree 八叉树:将初始的三维空间划分为八个相等大小的子立方体。每个子立方体可以使用边界框(bounding box)或中心点和边长来表示;八叉树常用于碰撞检测领域,可以通过遍历树的节点来寻找可能的碰撞候选项,并进行详细的碰撞检测。遍历可以使用深度优先搜索(DFS)或广度优先搜索(BFS)等算法来实现。 -> 局部依赖关系 -> 异常检测 -> 真实场景
-
体素哈希结构
表面表示方法:Surfel-surface element
- Surfel面片要素
- 空间点坐标:面片位置
- 空间法向量:面片方向
- 颜色信息
- 权重/置信度:用于判断当前面片的是否稳定,以及后续的加权平均等运算。根据当前点到相机的距离进行初始化,距离越远,权重越小,越不可信
- 半径:由当前表面到相机光心的距离决定,距离越大,半径越大
- 时间戳
- 八叉树表示面片 -> 优化面片的表示方法
方法的对比
- 立体:当前帧的TSDF和全局的TSDF进行加权求和即可
- 表面:当前帧的每个顶点和法向量以及半径,其步骤为:
- 3D->2D projection
- P2P matching
- Not matches, as outliers, add into global graph
- Mitigate the outliers by global graph(filter)
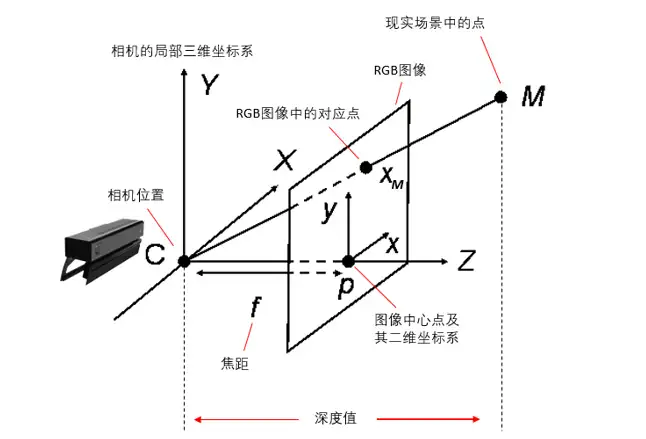
基于深度相机的三维重建
深度图像预处理
-
通常采用双边滤波去噪
- 去噪之后,KinectFusion通过降采样得到三层的深度图金字塔,用于后续估计相机位姿。
-
深度图的噪声可分为三类
- 深度缺失:太近或太远、表面不连续、高光或阴影等原因
- 深度错误:深度测量具有一定的准确率
- 深度不一致:随着时间变化,对同一点的测量的深度可能不一致
相机跟踪
-
ICP是相对位姿估计中非常重要的算法,主要用于3D形状的配准。通过计算相邻帧的****点云的匹配关系,然后最小化点对之间的欧氏距离,从而计算得出一个刚体变换(A点云->仿射变换->B点云:点对匹配(解一个最小二乘优化问题,R+T)+贪心算法(迭代优化))。这样会有一个问题,就是相邻帧的误差会在扫描过程中不断累积,也就是常说的累计误差。
-
消除位姿估计累积误差
- frame-to-model
- 全局位姿联合优化
-
点对匹配问题
- 稀疏点对匹配
- 稠密点对匹配
-
Objective:距离之和尽可能小,不同距离定义
- 点点距离:欧式
- 点面距离:法向量,求解复杂,迭代次数少
- ICP变体
深度图像的融合
-
立体表示i的模型融合
- 当前帧的TSDF和全局的TSDF进行加权求和即可
-
表面表示i的模型融合
-
当前帧的每个顶点和法向量以及半径,要融入全局的模型中
- 将当前3D模型中的顶点投影到当前帧相机的图像平面中,寻找匹配点对关系
- 如果找到了匹配点对,那么最可靠的点和新的点进行加权平均
- 如果没找到,那么新的点将加入全局模型,作为一个不稳定点
- 随着处理的帧数越来越多,全局模型会清理外点
-
动态场景的三维重建
- 基于立体表示
- 基于表面表示
- 基于移动估计或语义信息
场景理解
- 考虑事内场景平面的几何特征的三维重建
- 基于物体检测的物体三维重建
- 基于2D语义分割的三位重建
纹理重建
在线
离线
未来工作及研究空间
长距离、大范围重建
- 反射表面可能镜面反射,使得深度计算变得复杂甚至不可行