
T2I-Adapter 是一种高效的即插即用模型,其能对冻结的预训练大型文生图模型提供额外引导。T2I-Adapter 将 T2I 模型中的内部知识与外部控制信号结合起来。我们可以根据不同的情况训练各种适配器,实现丰富的控制和编辑效果。
同期的 ControlNet 也有类似的功能且已有广泛的应用。然而,其运行所需的 计算成本比较高。这是因为其反向扩散过程的每个去噪步都需要运行 ControlNet 和 UNet。另外,对 ControlNet 而言,复制 UNet 编码器作为控制模型的一部分对效果非常重要,这也导致了控制模型参数量的进一步增大。因此,ControlNet 的模型大小成了生成速度的瓶颈 (模型越大,生成得越慢)。
在这方面,T2I-Adapters 相较 ControlNets 而言颇有优势。T2I-Adapter 的尺寸较小,而且,与 ControlNet 不同,T2I-Adapter 可以在整个去噪过程中仅运行一次。
| 模型 | 参数量 | 所需存储空间(fp16) |
|---|---|---|
| ControlNet-SDXL | 1251 M | 2.5 GB |
| ControlLoRA (rank = 128) | 197.78 M (参数量减少 84.19%) | 396 MB (所需空间减少 84.53%) |
| T2I-Adapter-SDXL | 79 M (参数量减少 93.69%) | 158 MB (所需空间减少 94%) |
在过去的几周里,Diffusers 团队和 T2I-Adapter 作者紧密合作,在 diffusers 库上为 Stable Diffusion XL (SDXL) 增加 T2I-Adapter 的支持。本文,我们将分享我们在从头开始训练基于 SDXL 的 T2I-Adapter 过程中的发现、漂亮的结果,以及各种条件 (草图、canny、线稿图、深度图以及 OpenPose 骨骼图) 下的 T2I-Adapter checkpoint!

与之前版本的 T2I-Adapter (SD-1.4/1.5) 相比,T2I-Adapter-SDXL 还是原来的配方,不一样之处在于,用一个 79M 的适配器去驱动 2.6B 的大模型 SDXL! T2I-Adapter-SDXL 在继承 SDXL 的高品质生成能力的同时,保留了强大的控制能力!
用 diffusers 训练 T2I-Adapter-SDXL
我们基于 diffusers 提供的 这个官方示例 构建了我们的训练脚本。
本文中提到的大多数 T2I-Adapter 模型都是在 LAION-Aesthetics V2 的 3M 高分辨率 图文对 上训练的,配置如下:
- 训练步数: 20000-35000
- batch size: 采用数据并行,单 GPU batch size 为 16,总 batch size 为 128
- 学习率: 1e-5 的恒定学习率
- 混合精度: fp16
我们鼓励社区使用我们的脚本来训练自己的强大的 T2I-Adapter,并对速度、内存和生成的图像质量进行折衷以获得竞争优势。
在 diffusers 中使用 T2I-Adapter-SDXL
这里以线稿图为控制条件来演示 T2I-Adapter-SDXL 的使用。首先,安装所需的依赖项:
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate
T2I-Adapter-SDXL 的生成过程主要包含以下两个步骤:
- 首先将条件图像转换为符合要求的 控制图像 格式。
- 然后将 控制图像 和 提示 传给
StableDiffusionXLAdapterPipeline。
我们看一个使用 Lineart Adapter 的简单示例。我们首先初始化 SDXL 的 T2I-Adapter 流水线以及线稿检测器。
import torch
from controlnet_aux.lineart import LineartDetector
from diffusers import (AutoencoderKL, EulerAncestralDiscreteScheduler,
StableDiffusionXLAdapterPipeline, T2IAdapter)
from diffusers.utils import load_image, make_image_grid
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load pipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(
model_id, subfolder="scheduler"
)
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16
)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id,
vae=vae,
adapter=adapter,
scheduler=euler_a,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# load lineart detector
line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
然后,加载图像并生成其线稿图:
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
image = load_image(url)
image = line_detector(image, detect_resolution=384, image_resolution=1024)

然后生成:
prompt = "Ice dragon roar, 4k photo"
negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.8,
guidance_scale=7.5,
).images[0]
gen_images.save("out_lin.png")

理解下述两个重要的参数,可以帮助你调节控制程度。
-
adapter_conditioning_scale该参数调节控制图像对输入的影响程度。越大代表控制越强,反之亦然。
-
adapter_conditioning_factor该参数调节适配器需应用于生成过程总步数的前面多少步,取值范围在 0-1 之间 (默认值为 1)。
adapter_conditioning_factor=1表示适配器需应用于所有步,而adapter_conditioning_factor=0.5则表示它仅应用于前 50% 步。
更多详情,请查看 官方文档。
试玩演示应用
你可以在 这儿 或下述嵌入的游乐场中轻松试玩 T2I-Adapter-SDXL:
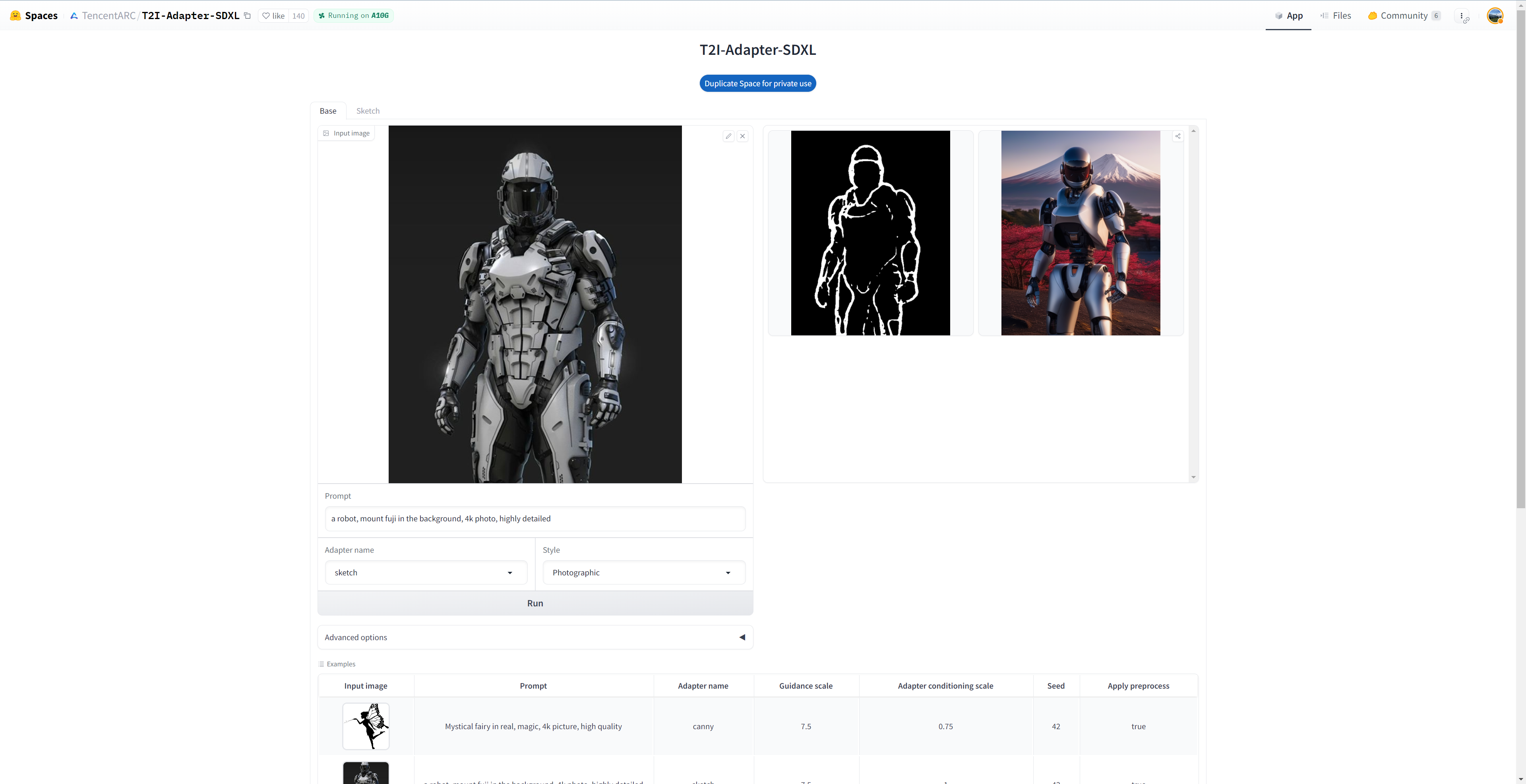
你还可以试试 Doodly,它用的是草图版模型,可以在文本监督的配合下,把你的涂鸦变成逼真的图像:
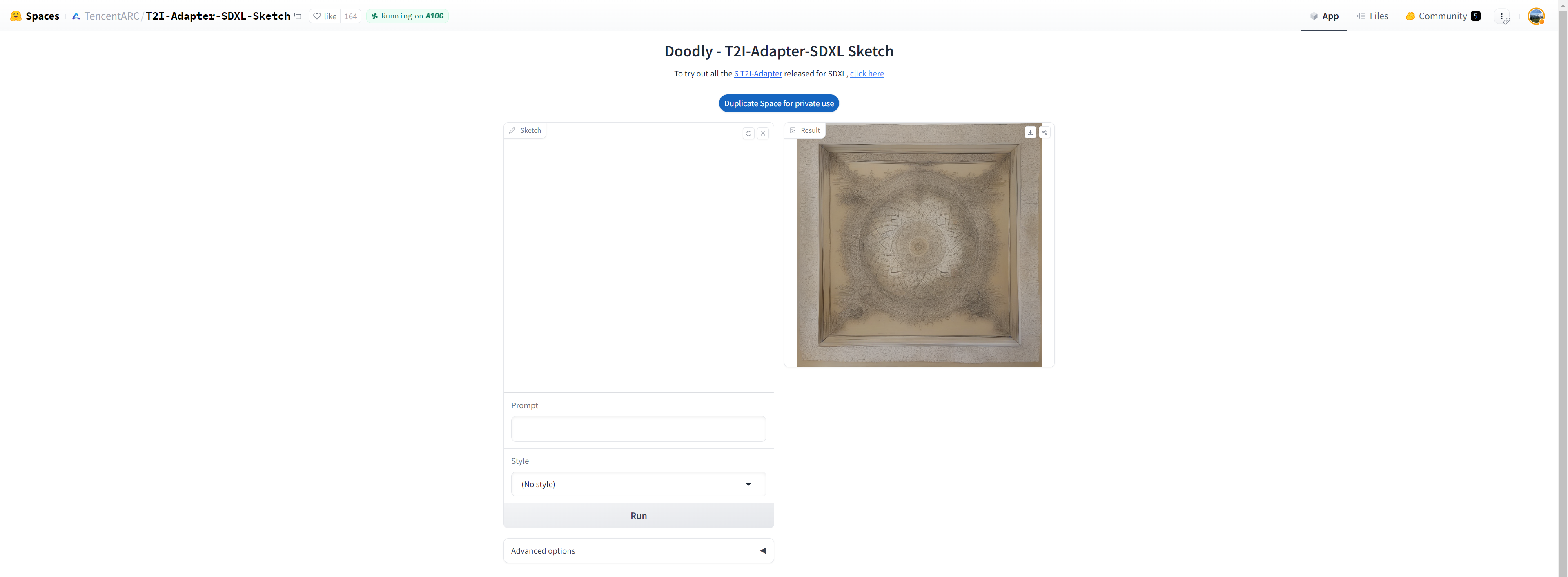
更多结果
下面,我们展示了使用不同控制图像作为条件获得的结果。除此以外,我们还分享了相应的预训练 checkpoint 的链接。如果想知道有关如何训练这些模型的更多详细信息及其示例用法,可以参考各自模型的模型卡。
使用线稿图引导图像生成

模型见 TencentARC/t2i-adapter-lineart-sdxl-1.0
使用草图引导图像生成

模型见 TencentARC/t2i-adapter-sketch-sdxl-1.0
使用 Canny 检测器检测出的边缘图引导图像生成

模型见 TencentARC/t2i-adapter-canny-sdxl-1.0
使用深度图引导图像生成

模型分别见 TencentARC/t2i-adapter-depth-midas-sdxl-1.0 及 TencentARC/t2i-adapter-depth-zoe-sdxl-1.0
使用 OpenPose 骨骼图引导图像生成

模型见 TencentARC/t2i-adapter-openpose-sdxl-1.0
致谢: 非常感谢 William Berman 帮助我们训练模型并分享他的见解。
标签:T2I,SDXL,文生,Adapter,image,adapter,模型 From: https://www.cnblogs.com/huggingface/p/17737483.html英文原文: https://hf.co/blog/t2i-sdxl-adapters
原文作者: Chong Mou,Suraj Patil,Sayak Paul,Xintao Wang,hysts
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)