前言
最近在做性能优化,具体优化手段,网上铺天盖地,这里就不重复了。
性能优化可分为以下几个维度:代码层面、构建层面、网络层面。
本文主要是从代码层面探索前端性能,主要分为以下 4 个小节。
-
使用 CSS 替代 JS
-
深度剖析 JS
-
前端算法
-
计算机底层
使用 CSS 替代 JS
这里主要从动画和 CSS 组件两个方面介绍。
CSS 动画
CSS2 出来之前,哪怕要实现一个很简单的动画,都要通过 JS 实现。比如下面红色方块的水平移动:

对应 JS 代码:
let redBox = document.getElementById('redBox')
let l = 10
setInterval(() => {
l+=3
redBox.style.left = `${l}px`
}, 50)
1998 年的 CSS2 规范,定义了一些动画属性,但由于受当时浏览器技术限制,这些特性并没有得到广泛的支持和应用。
直到 CSS3 的推出,CSS 动画得到了更全面地支持。同时,CSS3 还引入了更多的动画效果,使得 CSS 动画在今天的 Web 开发中得到了广泛的应用。
那么 CSS3 都能实现什么动画,举几个例子:
-
过渡(Transition)- 过渡是 CSS3 中常用的动画效果之一,通过对一个元素的某些属性进行变换,使元素在一段时间内从一个状态平滑地过渡到另一个状态。
-
动画(Animation)- 动画是 CSS3 中另一个常用的动画效果,其用于为一个元素添加一些复杂的动画效果,可以通过关键帧(@keyframes)来定义一串动画序列。
-
变换(Transform)- 变换是 CSS3 中用于实现 2D/3D 图形变换效果的一种技术,包括旋转、缩放、移动、斜切等效果。
把上面的例子改写成 CSS 代码如下:
#redBox {
animation: mymove 5s infinite;
}
@keyframes mymove
{
from {left: 0;}
to {left: 200px;}
}
同样的效果,用样式就能实现,何乐而不为呢。
需要指出的是,CSS 的动画仍在不断发展和改进,随着新的浏览器特性和 CSS 版本的出现,CSS 动画的特性也在不断地增加和优化,以满足日益复杂的动画需求和更好的用户体验。
CSS 组件
在一些知名的组件库中,有些组件的大部分 props 是通过修改 CSS 样式实现的,比如 Vant 的Space组件。
| Props | 功能 | CSS 样式 |
|---|---|---|
| direction | 间距方向 | flex-direction: column; |
| align | 对齐方式 | align-items: xxx; |
| fill | 是否让 Space 变为一个块级元素,填充整个父元素 | display: flex; |
| wrap | 是否自动换行 | flex-wrap: wrap; |
再比如 Ant Design 的Space组件。
| Props | 功能 | CSS 样式 |
|---|---|---|
| align | 对齐方式 | align-items: xxx; |
| direction | 间距方向 | flex-direction: column; |
| size | 间距大小 | gap: xxx; |
| wrap | 是否自动换行 | flex-wrap: wrap; |
这类组件完全可以封装成 SCSS 的 mixin 实现(LESS 也一样),既能减少项目的构建体积(两个库的 Space 组件 gzip 后的大小分别为 5.4k 和 22.9k),又能提高性能。
查看组件库某个组件的体积,可访问连接。
比如下面的 space mixin:
/*
* 间距
* size: 间距大小,默认是 8px
* align: 对齐方式,默认是 center,可选 start、end、baseline、center
* direction: 间距方向,默认是 horizontal,可选 horizontal、vertical
* wrap: 是否自动换行,仅在 horizontal 时有效,默认是 false
*/
@mixin space($size: 8px, $direction: horizontal, $align: center, $wrap: false) {
display: inline-flex;
gap: $size;
@if ($direction == 'vertical') {
flex-direction: column;
}
@if ($align == 'center') {
align-items: center;
}
@if ($align == 'start') {
align-items: flex-start;
}
@if ($align == 'end') {
align-items: flex-end;
}
@if ($align == 'baseline') {
align-items: baseline;
}
@if ($wrap == true) {
@if $direction == 'horizontal' {
flex-wrap: wrap;
}
}
}
类似的组件还有 Grid、Layout 等。
再说下图标,下面是 Ant Design 图标组件的第一屏截图,有很多仅用 HTML + CSS 就可以轻松实现。
实现思路:
-
优先考虑只使用样式实现
-
仅靠样式满足不了,就先增加一个标签,通过这个标签和它的两个伪元素 ::before 和 ::after 实现
-
一个标签实在不够,再考虑增加额外的标签
比如实现一个支持四个方向的实心三角形,仅用几行样式就可以实现(上面截图是 4 个图标):
/* 三角形 */
@mixin triangle($borderWidth: 10, $shapeColor: #666, $direction: up) {
width: 0;
height: 0;
border: if(type-of($borderWidth) == 'number', #{$borderWidth} + 'px', #{$borderWidth}) solid transparent;
$doubleBorderWidth: 2 * $borderWidth;
$borderStyle: if(type-of($doubleBorderWidth) == 'number', #{$doubleBorderWidth} + 'px', #{$doubleBorderWidth}) solid #{$shapeColor};
@if($direction == 'up') {
border-bottom: $borderStyle;
}
@if($direction == 'down') {
border-top: $borderStyle;
}
@if($direction == 'left') {
border-right: $borderStyle;
}
@if($direction == 'right') {
border-left: $borderStyle;
}
}
总之,能用 CSS 实现的就不用 JS,不仅性能好,而且还跨技术栈,甚至跨端。
深度剖析 JS
介绍完了 CSS,再来看 JS,主要从基本语句和框架源码两个方面深入。
if-else 语句的优化
先了解下 CPU 是如何执行条件语句的。参考如下代码:
const a = 2
const b = 10
let c
if (a > 3) {
c = a + b
} else {
c = 2 * a
}
CPU 执行流程如下:
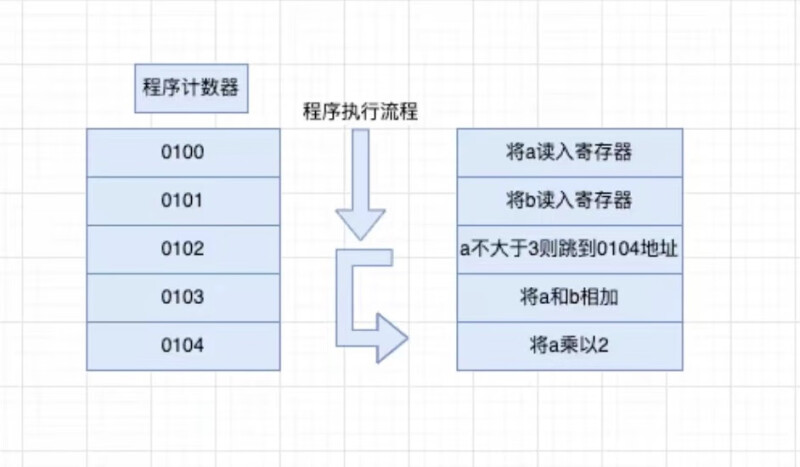
我们看到,在执行到指令 0102 时候,由于不满足 a > 3 这个条件,就直接跳转到 0104 这个指令去执行了;而且,计算机很聪明,如果它在编译期间发现 a 永远不可能大于 3,它就会直接删除 0103 这条指令,然后,0104 这条指令就变成了下一条指令,直接顺序执行,也就是编译器的优化。
那么回到正题,假如有以下代码:
function check(age, sex) {
let msg = ''
if (age > 18) {
if (sex === 1) {
msg = '符合条件'
} else {
msg = ' 不符合条件'
}
} else {
msg = '不符合条件'
}
}
逻辑很简单,就是筛选出 age > 18 并且 sex == 1 的人,代码一点儿问题都没有,但是太啰嗦,站在 CPU 的角度来看,需要执行两次跳转操作,当 age > 18 时,就进入内层的 if-else 继续判断,也就意味着再次跳转。
其实我们可以直接优化下这个逻辑(通常我们也是这样做的,但是可能知其然而不知其所以然):
function check(age, sex){
if (age > 18 && sex ==1) return '符合条件'
return '不符合条件'
}
所以,逻辑能提前结束就提前结束,减少 CPU 的跳转。
Switch 语句的优化
其实 switch 语句和 if-else 语句的区别不大,只不过写法不同而已,但是,switch 语句有个特殊的优化,那就是数组。
参考以下代码:
function getPrice(level) {
if (level > 10) return 100
if (level > 9) return 80
if (level > 6) return 50
if (level > 1) return 20
return 10
}
我们改成 switch 语句:
function getPrice(level) {
switch(level)
case 10: return 100
case 9: return 80
case 8:
case 7:
case 6: return 50
case 5:
case 4:
case 3:
case 2:
case 1: return 20
default: return 10
}
看着没啥区别,其实编译器会把它优化成一个数组,其中数组的下标为 0 到 10,不同下标对应的价格就是 return 的数值,也就是:
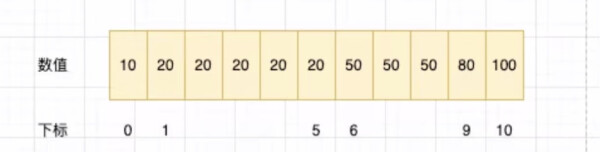
而我们又知道,数组是支持随机访问的,速度极快,所以,编译器对 switch 的这个优化就会大大提升程序的运行效率,这可比一条一条执行命令快多了。
那么,我还写个毛的 if-else 语句啊,我直接全部写 switch 不就行了?
不行!因为编译器对 switch 的优化是有条件的,它要求你的 code 必须是紧凑的,也就是连续的。
这是为什么呢?因为我要用数组来优化你啊,你如果不是紧凑的,比如你的 code 是 1、50、51、101、110,我就要创建一个长度 110 的数组来存放你,只有这几个位置有用,岂不是浪费空间!
所以,我们在使用 switch 的时候,尽量保证_code 是紧凑的数字类型_的。
循环语句的优化
其实循环语句跟条件语句类似,只不过写法不同而已,循环语句的优化点是以减少指令为主。
我们先来看一个中二的写法:
function findUserByName(users) {
let user = null
for (let i = 0; i < users.length; i++) {
if (users[i].name === '张三') {
user = users[i]
}
}
return user
}
如果数组长度是 10086,第一个人就叫张三,那后面 10085 次遍历不就白做了,真拿 CPU 不当人啊。
你直接这样写不就行了:
function findUserByName(users) {
for (let i = 0; i < users.length; i++) {
if (users[i].name === '章三') return users[i]
}
}
这样写效率高,可读性强,也符合我们上述的_逻辑能提前结束就提前结束_这个观点。CPU 直接感谢你全家。
其实,这里还有一点可以优化的地方,就是我们的数组长度可以提取出来,不必每次都访问,也就是这样:
function findUserByName(users) {
let length = users.length
for (let i = 0; i < length; i++) {
if (users[i].name === '章三') return users[i]
}
}
这看起来好像有点吹毛求疵了,确实是,但是如果考虑到性能的话,还是有点用的。比如有的集合的 size() 函数,不是简单的属性访问,而是每次都需要计算一次,这种场景就是一次很大的优化了,因为省了很多次函数调用的过程,也就是省了很多个 call 和 return 指令,这无异是提高了代码的效率的。尤其是在循环语句这种容易量变引起质变的情况下,差距就是从这个细节拉开的。
函数调用过程参考:
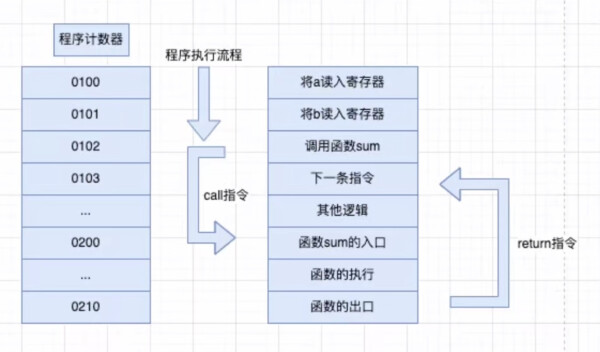
对应代码如下:
let a = 10
let b = 11
function sum (a, b) {
return a + b
}
说完了几个基础语句,再来看下我们经常使用的框架内部,很多地方的性能都值得探索。
diff 算法
Vue 和 React 中都使用了虚拟 DOM,当执行更新时,要对比新旧虚拟 DOM。如果没有任何优化,直接严格 diff 两颗树,时间复杂度是 O(n^3),根本不可用。所以 Vue 和 React 必须使用 diff 算法优化虚拟 DOM:
Vue2 - 双端比较:
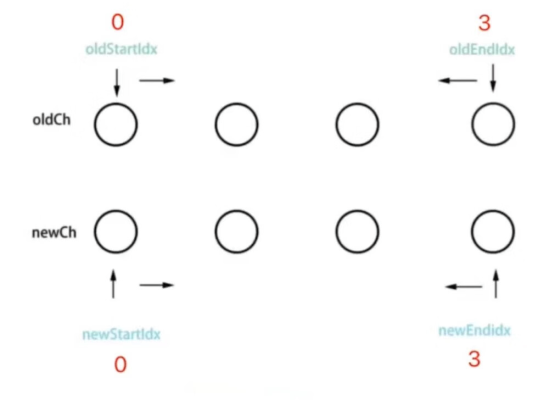
类似上面的图:
-
定义 4 个变量,分别为:oldStartIdx、oldEndIdx、newStartIdx 和 newEndIdx
-
判断 oldStartIdx 和 newStartIdx 是否相等
-
判断 oldEndIdx 和 newEndIdx 是否相等
-
判断 oldStartIdx 和 newEndIdx 是否相等
-
判断 oldEndIdx 和 newStartIdx 是否相等
-
同时 oldStartIdx 和 newStartIdx 向右移动;oldEndIdx 和 newEndIdx 向左移动
Vue3 - 最长递增子序列:
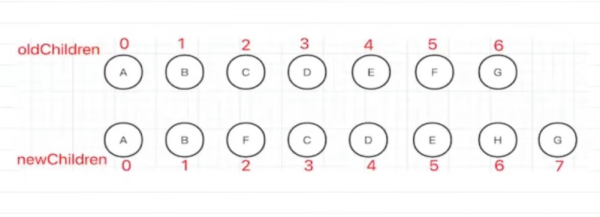
整个过程是基于 Vue2 的双端比较再次进行优化。比如上面这个截图:
-
先进行双端比较,发现前面两个节点(A 和 B)和最后一个节点(G)是一样的,不需要移动
-
找到最长递增子序列 C、D、E(新旧 children 都包含的,最长的顺序没有发生变化的一组节点)
-
把子序列当成一个整体,内部不用进行任何操作,只需要把 F 移动到它的前面,H 插入到它的后面即可
React - 仅右移:
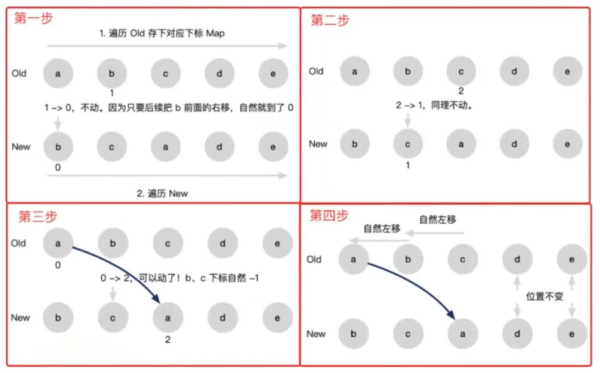
上面截图的比较过程如下:
-
遍历 Old 存下对应下标 Map
-
遍历 New,b 的下标从 1 变成了 0,不动(是左移不是右移)
-
c 的下标从 2 变成了 1,不动(也是左移不是右移)
-
a 的下标从 0 变成了 2,向右移动,b、c 下标都减 1
-
d 和 e 位置没变,不需要移动
总之,不管用什么算法,它们的原则都是:
-
只比较同一层级,不跨级比较
-
Tag 不同则删掉重建(不再去比较内部的细节)
-
子节点通过 key 区分(key 的重要性)
最后也都成功把时间复杂度降低到了 O(n),才可以被我们实际项目使用。
setState 真的是异步吗
很多人都认为 setState 是异步的,但是请看下面的例子:
clickHandler = () => {
console.log('--- start ---')
Promise.resolve().then(() => console.log('promise then'))
this.setState({val: 1}, () => {console.log('state...', this.state.val)})
console.log('--- end ---')
}
render() {
return <div onClick={this.clickHandler}>setState</div>
}
实际打印结果:
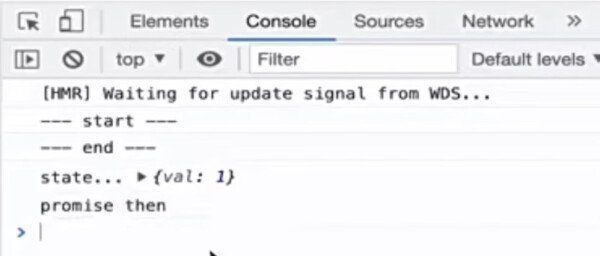
如果是异步的话,state 的打印应该在微任务 Promise 后执行。
为了解释清这个原因,必须先了解 JSX 里的事件机制。
JSX 里的事件,比如 onClick={() => {}},其实叫合成事件,区别于我们常说的自定义事件:
// 自定义事件
document.getElementById('app').addEventListener('click', () => {})
合成事件都是绑定在 root 根节点上,有前置和后置操作,拿上面的例子举例:
function fn() { // fn 是合成事件函数,内部事件同步执行
// 前置
clickHandler()
// 后置,执行 setState 的 callback
}
可以想象有函数 fn,里面的事件都是同步执行的,包括 setState。fn 执行完,才开始执行异步事件,即 Promise.then,符合打印的结果。
那么 React 为什么要这么做呢?
因为要考虑性能,如果要多次修改 state,React 会先合并这些修改,合并完只进行一次 DOM 渲染,避免每次修改完都渲染 DOM。
所以 setState_本质是同步_,日常说的“异步”是不严谨的。
前端算法
讲完了我们的日常开发,再来说说算法在前端中的应用。
友情提示:算法一般都是针对大数据量而言,区别于日常开发。
能用值类型就不用引用类型
先来看一道题。
求 1-10000 之间的所有对称数,例如:0, 1, 2, 11, 22, 101, 232, 1221...
思路 1 - 使用数组反转、比较:数字转换为字符串,再转换为数组;数组 reverse,再 join 为字符串;前后字符串进行对比。
function findPalindromeNumbers1(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
// 转换为字符串,转换为数组,再反转,比较
const s = i.toString()
if (s === s.split('').reverse().join('')) {
res.push(i)
}
}
return res
}
思路 2 - 字符串头尾比较:数字转换为字符串;字符串头尾字符比较。
function findPalindromeNumbers2(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
const s = i.toString()
const length = s.length
// 字符串头尾比较
let flag = true
let startIndex = 0 // 字符串开始
let endIndex = length - 1 // 字符串结束
while (startIndex < endIndex) {
if (s[startIndex] !== s[endIndex]) {
flag = false
break
} else {
// 继续比较
startIndex++
endIndex--
}
}
if (flag) res.push(res)
}
return res
}
思路 3 - 生成翻转数:使用 % 和 Math.floor 生成翻转数;前后数字进行对比(全程操作数字,没有字符串类型)。
function findPalindromeNumbers3(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
let n = i
let rev = 0 // 存储翻转数
// 生成翻转数
while (n > 0) {
rev = rev * 10 + n % 10
n = Math.floor(n / 10)
}
if (i === rev) res.push(i)
}
return res
}
性能分析:越来越快
-
思路 1- 看似是 O(n),但数组转换、操作都需要时间,所以慢
-
思路 2 VS 思路3 - 操作数字更快(电脑原型就是计算器)
总之,尽量不要转换数据结构,尤其数组这种有序结构,尽量不要用内置 API,如 reverse,不好识别复杂度,数字操作最快,其次是字符串。
尽量用“低级”代码
还是直接上一道题。
输入一个字符串,切换其中字母的大小写
如,输入字符串 12aBc34,输出字符串 12AbC34
思路 1 - 使用正则表达式。
function switchLetterCase(s) {
let res = ''
const length = s.length
if (length === 0) return res
const reg1 = /[a-z]
const reg2 = /[A-Z]
for (let i = 0; i < length; i++) {
const c = s[i]
if (reg1.test(c)) {
res += c.toUpperCase()
} else if (reg2.test(c)) {
res += c.toLowerCase()
} else {
res += c
}
}
return res
}
思路 2 - 通过 ASCII 码判断。
function switchLetterCase2(s) {
let res = ''
const length = s.length
if (length === 0) return res
for (let i = 0; i < length; i++) {
const c = s[i]
const code = c.charCodeAt(0)
if (code >= 65 && code <= 90) {
res += c.toLowerCase()
} else if (code >= 97 && code <= 122) {
res += c.toUpperCase()
} else {
res += c
}
}
return res
}
性能分析:前者使用了正则,慢于后者
所以,尽量用“低级”代码,慎用语法糖、高级 API 或者正则表达式。
计算机底层
最后说一些前端需要了解的计算机底层。
从“内存”读数据
我们通常说的:从内存中读数据,就是把数据读入寄存器中,但是我们的数据不是直接从内存读入寄存器的,而是先读入一个高速缓存中,然后才读入寄存器的。
寄存器是在 CPU 内的,也是 CPU 的一部分,所以 CPU 从寄存器读写数据非常快。
这是为啥呢?因为从内存中读数据太慢了。
你可以这么理解:CPU 先把数据读入高速缓存中,以备使用,真正使用的时候,就从高速缓存中读入寄存器;当寄存器使用完毕后,就把数据写回到高速缓存中,然后高速缓存再在合适的时机将数据写入到存储器。
CPU 运算速度非常快,而从内存读数据非常慢,如果每次都从内存中读写数据,那么势必会拖累 CPU 的运算速度,可能执行 100s,有 99s 都在读取数据。为了解决这个问题,我们就在 CPU 和存储器之间放了个高速缓存,而 CPU 和高速缓存之间的读写速度是很快的,CPU 只管和高速缓存互相读写数据,而不管高速缓存和存储器之间是怎么同步数据的。这样就解决了内存读写慢的问题。
二进制的位运算
灵活运用二进制的位运算不仅能提高速度,熟练使用二进制还能节省内存。
假如给定一个数 n,怎么判断 n 是不是 2 的 n 次方呢?
很简单啊,直接求余就行了。
function isPowerOfTwo(n) {
if (n <= 0) return false
let temp = n
while (temp > 1) {
if (temp % 2 != 0) return false
temp /= 2
}
return true
}
嗯,代码没毛病,不过不够好,看下面代码:
function isPowerOfTwo(n) {
return (n > 0) && ((n & (n - 1)) == 0)
}
大家可以用 console.time 和 console.timeEnd 对比下运行速度便知。
我们可能还会看到一些源码里面有很多 flag 变量,对这些 flag 进行按位与或按位或运算来检测标记,从而判断是否开启了某个功能。他为什么不直接用布尔值呢?很简单,这样效率高还节省内存。
比如 Vue3 源码中的这段代码,不仅用到了按位与和按位或,还用到了左移:
export const enum ShapeFlags {
ELEMENT = 1,
FUNCTIONAL_COMPONENT = 1 << 1,
STATEFUL_COMPONENT = 1 << 2,
TEXT_CHILDREN = 1 << 3,
ARRAY_CHILDREN = 1 << 4,
SLOTS_CHILDREN = 1 << 5,
TELEPORT = 1 << 6,
SUSPENSE = 1 << 7,
COMPONENT_SHOULD_KEEP_ALIVE = 1 << 8,
COMPONENT_KEPT_ALIVE = 1 << 9,
COMPONENT = ShapeFlags.STATEFUL_COMPONENT | ShapeFlags.FUNCTIONAL_COMPONENT
}
if (shapeFlag & ShapeFlags.ELEMENT || shapeFlag & ShapeFlags.TELEPORT) {
...
}
if (hasDynamicKeys) {
patchFlag |= PatchFlags.FULL_PROPS
} else {
if (hasClassBinding) {
patchFlag |= PatchFlags.CLASS
}
if (hasStyleBinding) {
patchFlag |= PatchFlags.STYLE
}
if (dynamicPropNames.length) {
patchFlag |= PatchFlags.PROPS
}
if (hasHydrationEventBinding) {
patchFlag |= PatchFlags.HYDRATE_EVENTS
}
}
结语
文章从代码层面讲解了前端的性能,有深度维度的:
-
JS 基础知识深度剖析
-
框架源码
也有广度维度的:
-
CSS 动画、组件
-
算法
-
计算机底层
希望能让大家拓宽前端性能的视野,如果对文章感兴趣,欢迎留言讨论~~~
标签:function,动画,return,层面,前端,CPU,let,代码,CSS From: https://www.cnblogs.com/jingdongkeji/p/17729524.html作者:京东零售 杨进军
来源:京东云开发者社区 转载请注明来源