决策树(Decision Tree)常用于研究类别归属和预测关系的模型,比如是否抽烟、是否喝酒、年龄、体重等4项个人特征可能会影响到‘是否患癌症’,上述4项个人特征称作‘特征’,也即自变量(影响因素X),‘是否患癌症’称为‘标签’,也即因变量(被影响项Y)。决策树模型时,其可首先对年龄进行划分,比如以70岁为界,年龄大于70岁时,可能更容易归类为‘患癌症’,接着对体重进行划分,比如大于50公斤为界,大于50公斤时更可能划分为‘患癌症’,依次循环下去,特征之间的逻辑组合后(比如年龄大于70岁,体重大于50公斤),会对应到是否患癌症这一标签上。
决策树是一种预测模型,为让其有着良好的预测能力,因此通常需要将数据分为两组,分别是训练数据和测试数据。训练数据用于建立模型使用,即建立特征组合与标签之间的对应关系,得到这样的对应关系后(模型后),然后使用测试数据用来验证当前模型的优劣。通常情况下,训练数据和测试数据的比例通常为9:1,8:2,7:3,6:4或者5:5(比如9:1时指所有数据中90%作为训练模型使用,余下10%作为测试模型好坏使用)。具体比例情况似研究数据量而定无固定标准,如果研究数据较少,比如仅几百条数据,可考虑将70%或者60%,甚至50%的数据用于训练,余下数据用于测试。上述中包括模型构建和模型预测两项,如果训练数据得到的模型优秀,此时可考虑将其进行保存并且部署出去使用(此为计算机工程中应用,SPSSAU暂不提供);除此之外,当决策树模型构建完成后可进行预测,比如新来一个病人,他是否会患癌症及患癌症的可能性有多高。
决策树模型可用于特征质量判断,比如上述是否抽烟、是否喝酒、年龄、体重等4项,该四项对于‘是否患癌症’的预测作用重要性大小可以进行排名用于筛选出最有用的特征项。
决策树模型的构建时,需要对参数进行设置,其目的在于构建良好的模型(良好模型的标准通常为:训练数据得到的模型评估结果良好,并且测试数据时评估结果良好)。需要特别注意一点是:训练数据模型评估结果可能很好(甚至准确率等各项指标为100%),但是在测试数据上评估结果确很糟糕,此种情况称为‘过拟合’。因而在实际研究数据中,需要特别注意此种情况。模型的构建时通常情况下参数设置越复杂,其会带来训练数据的模型评估结果越好,但测试效果却很糟糕,因而在决策树构建时,需要特别注意参数的相关设置,接下来会使用案例数据进行相关说明。
1 背景
使用经典的‘鸢尾花分类数据集’进行案例演示,其数据集为150个样本,包括4个特征属性(4个自变量X),分别是花萼长度,花萼宽度,花瓣长度,花瓣宽度,标签为鸢尾花卉类别,共包括3个类别分别是刚毛鸢尾花、变色鸢尾花和弗吉尼亚鸢尾花(下称A、B、C三类)。
2 理论
决策树模型的原理上,其第1步是找出最优的特征和其分割点,比如影响是否患癌症的特征最可能是年龄,并且分割点可能是70岁,小于70岁可能归为‘不患癌症’,70岁及以上可能归为‘患癌症’。此第1步时会涉及到2个专业名词,分别是‘节点分裂标准’和‘节点划分方式’。第2步是找出次优的特征和其分割点,继续进行拆分。一直循环下去。
关于决策树模型时,通常涉及到以下参数值,如下:
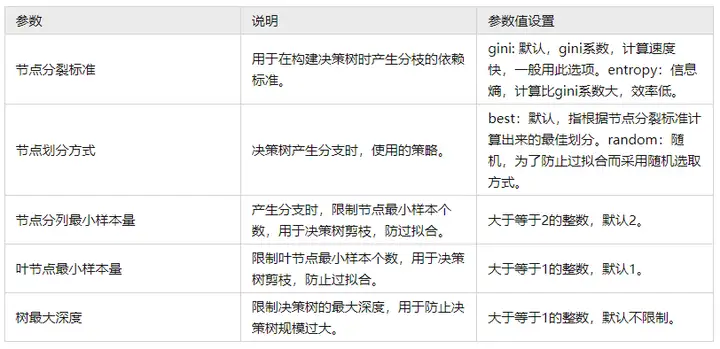
节点分裂标准:其指模型找到特征优先顺序的计算方式,共有两种,分别是gini系数和entropy系数,二者仅为计算标准的区别功能完全一致,一般情况下使用gini系数。
特别提示:
节点分裂标准的数学原理为:如果按某特征及其分割点后(比如年龄这个特征并且70岁这个分割点)后,分成两组时,一组为患癌症,一组不患癌症,如果‘分的特别开’,特别纯,混杂性特别小(比如一组为患癌症确实全部都患问卷,一组不患癌症确实都不患癌症),那么这个特征就是优秀的,节点分裂标准正是用于衡量特征的优劣。
节点划分方式:包括两种,一是best法即完全按照节点分裂标准进行计算,另一种是random随机法,随机法会减少过拟合现象,但通常默认使用best法。
节点分列最小样本:比如大于等于70岁划分为一组,如果发现70岁及以上时患癌症的样本量特别小,说明不能继续划分分组,一般情况下该值应该越大越好,过小的话容易带来过拟合现象。
叶节点最小样本量:比如大于等于70岁划分为一组,那么这个组别时最小的样本量需要多少,SPSSAU默认是2,一般情况下:该值越大越可能减少过拟合现象,该值越小越容易导致过拟合。
树最大深度:比如上述先按年龄划分,接着小于70岁时,再按次优特征比如体重进行划分,接着再按次次优特征比如是否吸烟进行划分,此处则出现划分的层次(即权最大深度),该值可以自行指定,当层次越多(树最大深度)时,此时模型越为复杂,拟合效果通常更好,但也可能带来过拟合现象,因而可结合特征数量及输出等,调整该参数值,确保模型相对简单但拟合效果良好时。
3 操作
本例子操作如下:
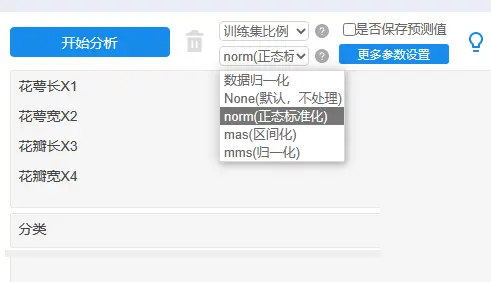
训练集比例默认选择为:0.8即80%(150*0.8=120个样本)进行训练决策树模型,余下20%即30个样本(测试数据)用于模型的验证。需要注意的是,多数情况下,会首先对数据进行标准化处理,处理方式一般使用为正态标准化,此处理目的是让数据保持一致性量纲。当然也可使用其它的量纲方式,比如区间化,归一化等。
接着对参数设置如下:
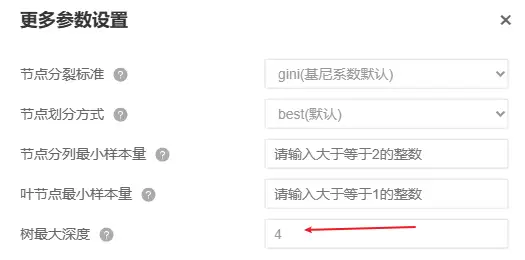
节点分裂标准默认为gini系数(该参数值只是计算分裂标准的方式,不需要设置),节点划分方式为best法,即为结合特征的优劣顺序进行分类划分,如果为了设置参数对比需要考虑,建议可对该参数值进行切换为random即随机特征的优先顺序,用于对比模型训练效果。
节点分列最小样本量默认为2即可,叶节点最小样本量默认为1即可。需要注意的是:如果数据量较大时,建议将该2个参数值尽量大,以减少过拟合现象,但该2个参数值越大时通常训练模型的拟合效果越差。具体应该以测试数据的拟合效果为准,因为训练模型容易出现过拟合现象。树最大深度这个参数时,其代表决策树最多有几层的意思,该参数值设置越大时,训练模型拟合效果通常越好,但可能带来过拟合情况,本案例出于演示需求,先设置为4层。(另提示:树最大深度会受到节点分裂最小样本量、叶节点最小样本量的影响,并非设置为4它一定就会为4)。
4 SPSSAU输出结果
SPSSAU共输出7项结果,依次为基本信息汇总,决策树结构图,特征模型图和特征权重图,训练集或测试集模型评估结果,测试集结果混淆矩阵,模型汇总表和模型代码,如下说明:
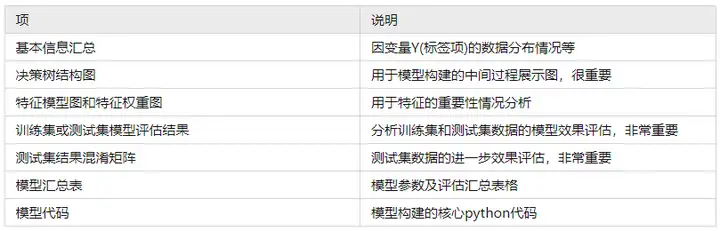
上述表格中,决策树结构图用于展示决策树构建的具体过程,通过决策树结构图可查看到模型构建的具体步骤;特征模型图和特征权重图可用于查看特征的相对重要性对比情况;模型评估结果(包括训练集或测试集),其用于对模型的拟合效果判断,尤其是测试集的拟合效果,非常重要,因而SPSSAU单独提供测试集结果混淆矩阵,用于进一步查看测试集数据的效果情况;模型汇总表格将各类参数值进行汇总,并且在最后,SPSSAU附录核心的决策树构建代码,需要提示的是:SPSSAU机器学习算法模块直接调用sklean包进行构建,因而研究者可使用核心代码进行复现使用等。
5文字分析
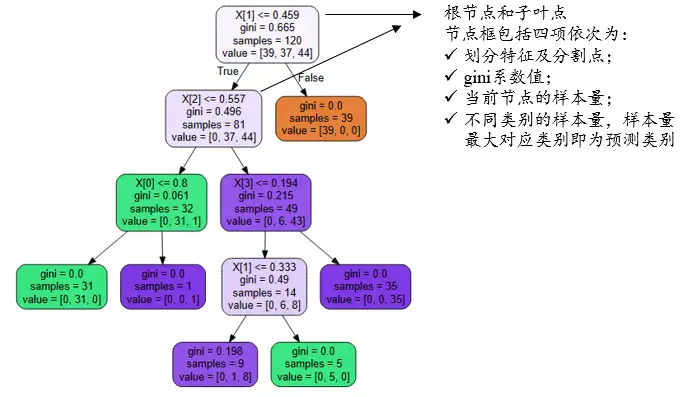
决策树结构图中:第1个矩阵称为‘根节点’,下面为子节点,不能再细分的为‘叶子节点’。树最大深度当前设置为4,上图中除‘根节点’外为4层。针对每个节点(根节点或叶子节点),其包括四项,分别是‘划分特征及分割点’,gini系数值,当前节点的样本量,不同类别的样本量。如下表格说明:
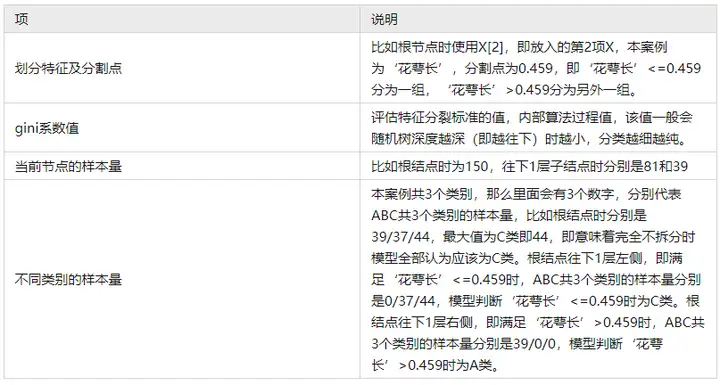
上述决策树结构图时,第1个点使用X[2],接着使用X[3],接着使用X[1],X[4],接着使用X[2]等,括号里面数字表示放入模型的第几个X。那么这几个X的综合重要性情况如何,可查看特征权重图,如下:
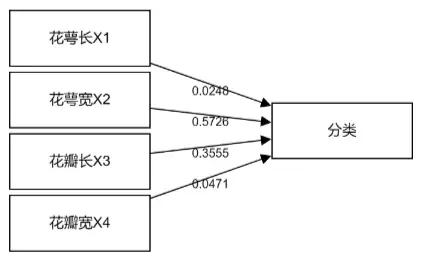
花萼宽的重要性度量值为0.5726,其对模型的作用力度最大,其次是花瓣长为0.3555。相对来看,花萼长和花瓣宽这两项的重要性相对较弱,如果是进行特征筛选,可考虑只留下最重要的两项即可。
解读完决策树结构图和特征重要性图后,已经理解决策树运行原理,其实质上是不断地对各个特征进行循环划分下去,根深度越深时,其划分出来后通常拟合效果越好。但训练数据拟合效果好,并不一定代表测试数据上也好,训练数据拟合效果很容易‘造假’,即过拟合现象。因而接下来对模型拟合效果进行说明。
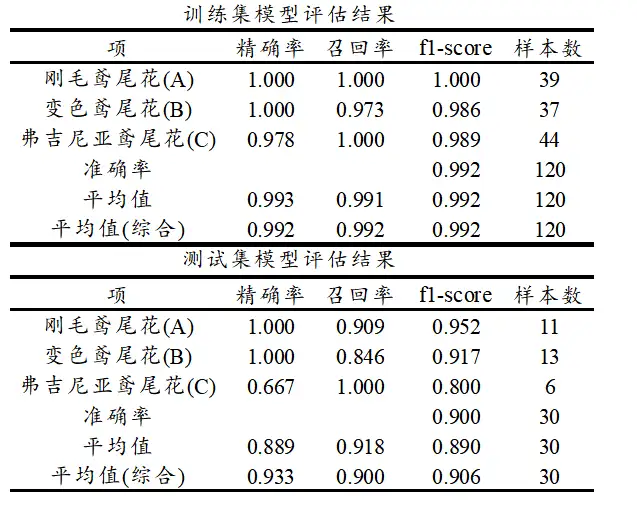
上表格中分别针对训练集和测试集,提供四个评估指标,分别是精确率、召回率、f1-scrore、准确率,以及平均指标和样本量指标等,如下表格说明:
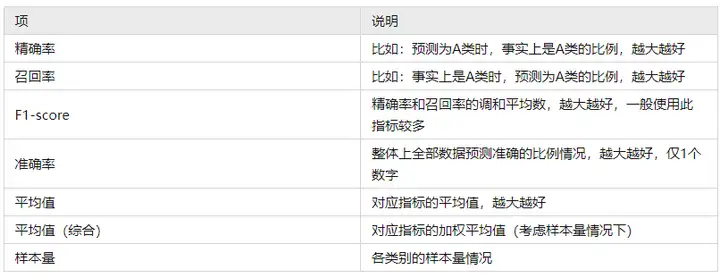
一般来说,f1-score指标值最适合,因为其综合精确率和召回率两个指标,并且可查看其平均值(综合)指标,本案例为0.992,接近于1非常高,但训练数据指标拟合可以‘造假’即可能有过拟合现象,最准确的是查看‘测试集数据’时的指标情况,本案例时测试数据占比是20%即30个样本,其平均综合f1-score值 为0.906,可以简单理解为模型拟合优度为90.6%,依旧比较高(即使小于训练数据的0.992),整体说明当前模型拟合良好,即可用于特征筛选,数据进一步预测使用等。
另需要提示:当训练数据的拟合效果远好于测试数据时,通常则为‘过拟合现象’,但训练数据的拟合效果不好但测试数据拟合效果好时,此种情况也不能使用,可能仅仅是偶然现象。因而可使用的模型应该为“训练数据和测试数据上均有良好的拟合效果,并且差别应该较小”。
进一步地,可查看测试数据的‘混淆矩阵’,即模型预测和事实情况的交叉集合,如下图:
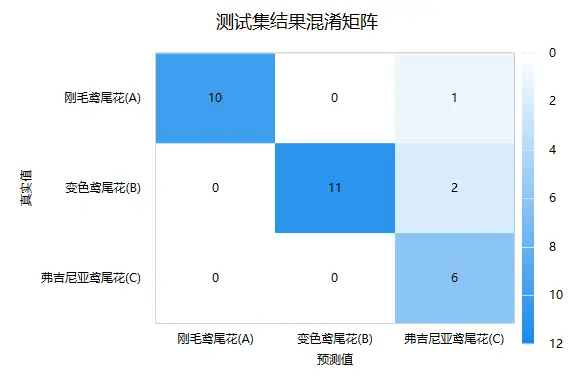
‘混淆矩阵’时,右下三角对角线的值越大越好,其表示预测值和真实值完全一致。上图中A类共11个,其中10个预测准确,还有1个被预测成C类; B类共13个,11个预测准确,但2个被预测为C类;C类时全部预测准确。另外还可通过‘混淆矩阵’自行计算精确率、召回率和准确率等指标。
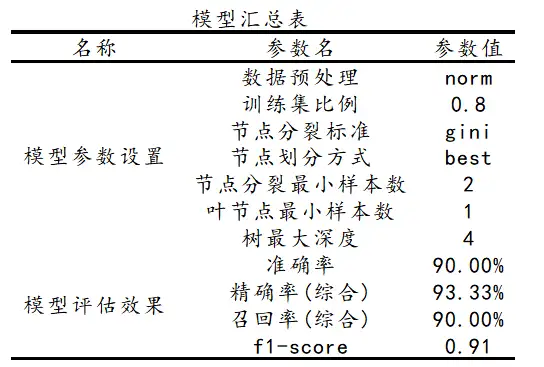
最后针对模型汇总表,其展示构建决策树的各项参数设置,包括针对数据进行标准化正态处理,参数值为norm,训练集占比,节点分裂标准等指标值。并且将测试集合上的模型评估结果汇总在一个表格里面。最后,SPSSAU输出使用python中slearn包构建本次决策树模型的核心代码如下:
model = DecisionTreeClassifier(criterion=gini, max_depth=4, min_samples_leaf=1, min_samples_split=2, splitter=best)
model.fit(x_train, y_train)
6 剖析
涉及以下几个关键点,分别如下:
- 决策树模型时是否需要标准化处理?
一般建议是进行标准化处理,通常使用正态标准化处理方式即可。 - 训练集比例应该选择多少?
如果数据量很大,比如1万,那么训练集比例可以较高比如0.9,如果数据量较小,此时训练集比例选择较小预留出较多数据进行测试即可。 - 保存预测值
保存预测值时,SPSSAU会新生成一个标题用于存储模型预测的类别信息,其数字的意义与模型中标签项(因变量Y)的数字保持一致意义。 - 参数如何设置?
如果要进行参数设置,建议针对‘节点划分方式’切换best和random,节点分列最小样本量往上调,叶节点最小样本量往上调,树最大深度可考虑设置相对较小值。设置后,分别将训练拟合效果,测试拟合效果进行汇总和对比,调整参数,找出相对最优模型。另建议保障训练集和测试集数据的f1-score值在0.9以上。 - SPSSAU中决策树具体算法是什么?
决策树的具体算法通常包括ID3, C4.5, C5.0 和CART等,SPSSAU当前借助sklearn包进行决策树,其算法为CART优化版,具体可点击查看。
https://scikit-learn.org/stable/modules/tree.html#tree-algorithms-id3-c4-5-c5-0-and-cart - SPSSAU进行决策树模型构建时,自变量X(特征项)中包括定类数据如何处理?
决策树模型时本身并不单独针对定类数据处理,如果有定类数据,建议对其哑变量处理后放入,关于哑变量可点击查看。
http://spssau.com/front/spssau/helps/otherdocuments/dummy.html - SPSSAU中决策树剪枝优化方式是什么?
决策树剪枝主要有两种方式,分别是前置剪枝和后置剪枝,当前SPSSAU只提供前置剪枝方式。 - SPSSAU中决策树模型合格的判断标准是什么?
机器学习模型中,通常均为先使用训练数据训练模型,然后使用测试数据测试模型效果。通常判断标准为训练模型具有良好的拟合效果,同时测试模型也有良好的拟合效果。机器学习模型中很容易出现‘过拟合’现象即假的好结果,因而一定需要重点关注测试数据的拟合效果。针对单一模型,可通过变换参数调优,与此同时,可使用多种机器学习模型,比如使用随机森林等,综合对比选择最优模型。 - SPSSAU进行决策树时提示数据质量异常?
当前决策树模型支持分类任务,需要确保标签项(因变量Y)为定类数据,如果为定量连续数据,也或者样本量较少(或者非会员仅分析前100个样本)时可能出现无法计算因而提示数据质量异常。
标签:分析,训练,模型,案例,SPSSAU,拟合,节点,决策树 From: https://www.cnblogs.com/spssau/p/17712529.html