CrossVul A Cross-Language Vulnerability Dataset with Commit Data
概述
本文章主要讲的是一个跨语言漏洞数据集,其收集与GitHub的commit。与其他漏洞数据集不同的是,文章中的数据集包含了四十多种编程语言。数据集不仅有存在漏洞的数据,也有对应的打了补丁的数据,所以此数据集既可以用于漏洞的识别训练,也可以用于补丁的识别训练。而且此数据集的数据都是从实际的代码中提取的,并不是合成的数据,所以质量要高不少。
-
数据下载地址:dataset
-
代码下载地址:Mine_Vulnerable_Code
-
目录结构如下:
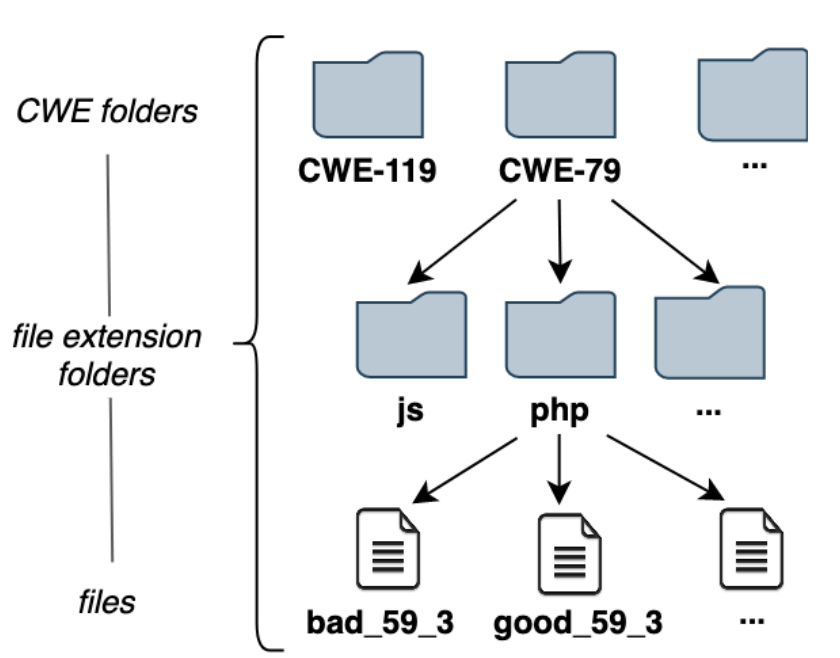
内容理解
术语解释:
-
CVE (Common Vulnerability and Exposures):公共漏洞和暴露
-
CWE (Common Weakness Enumeration):常见缺陷枚举
-
区别和联系:简而言之,弱点(Weakness)是导致漏洞的源头,或者具体的软件/硬件薄弱之处;漏洞(Vulnerability)是软件/硬件没有及时修补掉薄弱之处,可被攻击者用于攻击的突破口。
- NVD (National Vulnerability Database):NVD - Home (nist.gov)是一个由美国国家标准与技术研究院(NIST)维护的综合性漏洞数据库,旨在收集、共享和分发关于计算机软件和硬件中存在的安全漏洞的信息。
-
TP:True Positive,分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的数量。
-
FP:False Positive,分类器预测结果为正样本,实际为负样本,即误报的负样本数量。
-
TN:True Negative,分类器预测结果为负样本,实际为负样本,即负样本被正确识别的数量。
-
FN:False Negative,分类器预测结果为负样本,实际为正样本,即漏报的正样本数量。
要点
- 数据集特点
原文:Our method ensures that no filename collisions will occur when merging different directories that contain files associated with different vulnerability types. This allows researchers to group many different vulnerability categories together into fewer, more general categories.
- 个人理解:用最少的类别,包含最多的文件,即用分类尽量最少,但是也不失齐全的种类。
- 应用(重要)
- Vulnerability detection and code repair:可用于漏洞检测和分类任务,还可用于训练自动源代码纠正任务的深度学习模型。
- Code change embeddings:学习实际代码更改的向量表示,检测漏洞补丁提交或其对漏洞类别的分类。
- Applications on commit messages:添加漏洞补丁的语义意图;可用于训练深度学习模型以自动生成提交消息;用于漏洞提交消息的检测和分类,并有助于创建新的源代码漏洞数据集。
- 数据集的限制及解决方法
-
限制:细粒度不够,只是对整个代码文本的处理而不是具体函数
-
解决方法:为每种编程语言使用一个语言解析器,将文件分解成函数,然后使用提交的git -diff对其进行标记。
-
限制:漏洞较多,但是对应的安全补丁较少。
-
解决方法:可以通过以更多的假阴性为代价来减少假阳性,从而进一步提高模型在挖掘场景中的效率。(翻译,未看懂-MARK)
-
不同分类模型的性能指标
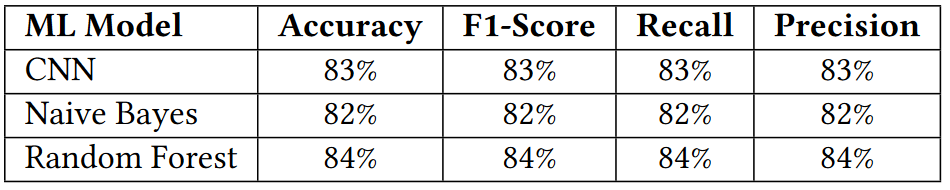
- 可以看出Random Forest模型要略好于其他两个模型。