Sentinel工作原理和源码解析
1 架构图解析
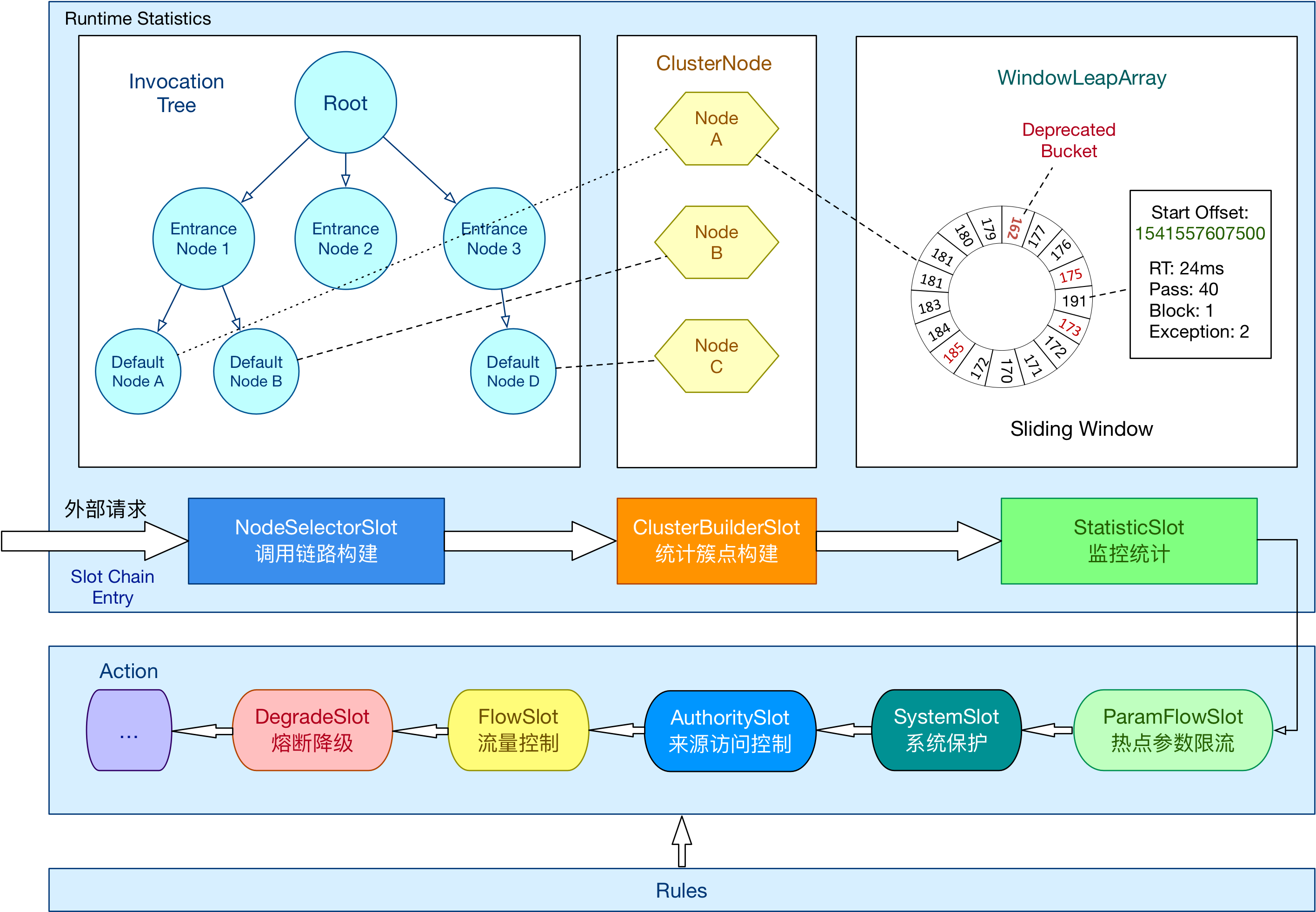
Sentinel的核心骨架是ProcessorSlotChain,其将不同的Slot按照顺序串在一起(责任链模式),从而将不同的功能组合在一起,系统会为每个受保护的资源都创建一套SlotChain。
整个架构分为两部分,一部分的Slot用于数据统计,另一部分Slot则使用统计的数据做具体的流控
2 SPI机制
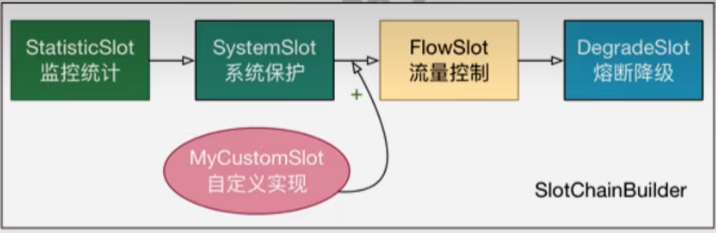
Sentinel槽链中的各Slot的执行顺序是固定好的,但并不是绝对不能够改变的,Sentinel将ProcessorSlot作为SPI接口进行扩展,使得SlotChain具备了扩展能力,用户可以自定义Slot并编排Slot之间的顺序。
3 Slot简介
在 Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 SphU API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
用于数据统计的Slot:
NodeSelectorSlot负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticSlot则用于记录、统计不同纬度的 runtime实时指标监控信息;
使用统计的数据进行具体流控的Slot:
ParamFlowSlot:对应的是热点参数限流部分,FlowSlot则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;对应流控规则部分AuthoritySlot则根据配置的黑白名单和调用来源信息,来做黑白名单控制,对应的是授权规则部分;DegradeSlot则通过统计信息以及预设的规则,来做熔断降级,对应降级规则部分SystemSlot则通过系统的状态,例如 load1 等,来控制总的入口流量,对应系统规则部分;
3.1 Sentinel Context
- Context是对资源操作的上下文,每个资源操作必须属于一个Context,如果代码中没有指定Context,则系统会创建一个name为
sentinel_default_context的默认Context - 一个context的生命周期可以包含多个资源操作,Context的生命周期的最后一个资源在exit的时候会清理Context,也意味着该Context的生命周期结束了
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
ContextUtil.enter("entrance2", "appA");
nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
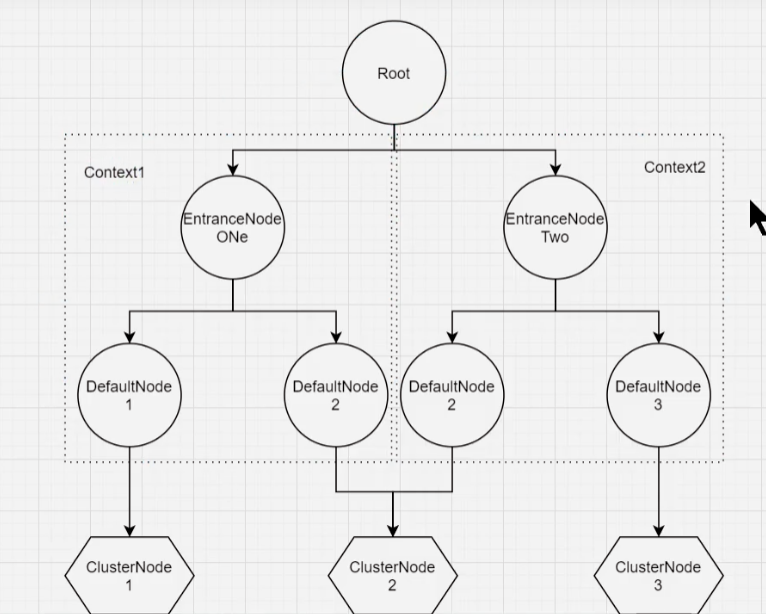
以上代码将在内存中生成以下结构:
machine-root / \ / \ EntranceNode1 EntranceNode2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA)
Context 代表调用链路上下文,贯穿一次调用链路中的所有 Entry。Context 维持着入口节点(entranceNode)、本次调用链路的 curNode、调用来源(origin)等信息。Context 名称即为调用链路入口名称。
Context 维持的方式:通过 ThreadLocal 传递,只有在入口 enter 的时候生效。由于 Context 是通过 ThreadLocal 传递的,因此对于异步调用链路,线程切换的时候会丢掉 Context,因此需要手动通过 ContextUtil.runOnContext(context, f) 来变换 context。
下面有一段代码举例说明Context对资源操作:
public void m() {
// 创建一个来自appA的访问、名为"enterOne"的Context
ContextUtil.enter("enterOne", "appA");
// Entry的本质是一个资源操作对象
Entry nodeA = null;
Entry nodeB = null;
try {
// 一个Context对多个资源的操作
// 使用context(本质是ThreadLocal)获取对"resource1"的资源操作
nodeA = SphU.entry("resource1");
// 走到这里说明获取成功,对资源的请求通过了流控
// 执行对resource1的相关业务
// 使用context(本质是ThreadLocal)获取对"resource2"的资源操作
nodeB = SphU.entry("resource2");
// 走到这里说明获取成功,对资源的请求通过了流控
// 执行对resource2的相关业务
} catch (BlockException e) {
e.printStackTrace();
// 到这里说明获取操作资源失败,被流量控制了
// 会去执行降级处理
} finally {
if(nodeA != null) {
nodeA.exit();
}
if(nodeB != null) {
nodeB.exit();
}
}
// 释放Context
ContextUtil.exit();
}
3.2 Node类别及之间的关系
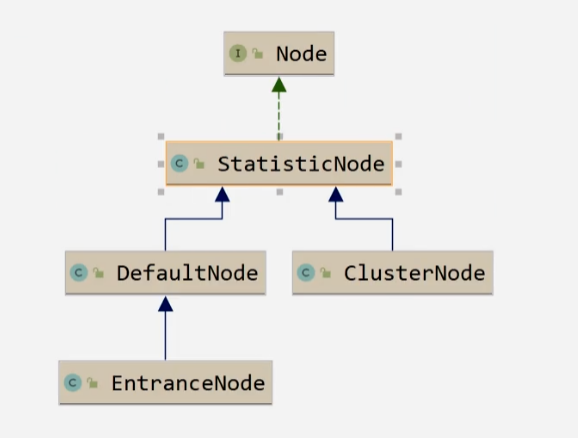
Node:用于完成数据统计的接口StatisticNode:统计节点,是Node接口的实现类,用于完成数据统计EntranceNode:入口节点,每一个Context都会有一个入口节点,用于统计当前Context的总体流量数据DefaultNode:默认节点,用于统计一个资源在当前Context的流量数据ClusterNode:集群节点,用于统计一个资源在所有Context中的总体资源流量
3.3 源码分析入口
分析思路如下,

3.4 entryWithPriority方法解析
3.5 Context的创建解析
3.6 FlowSlot流控槽解析
3.7 Degrade Slot熔断降级Slot解析