标签:订阅 pika exchange 队列 RabbitMQ queue 交换机 6.0 channel
【一】发布订阅
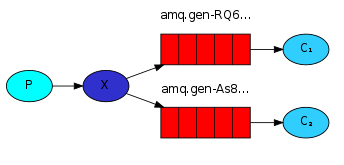
【1】发布者
import pika
# 【1】创建连接并设置认证信息
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
# 【2】创建通道
channel = connection.channel()
# 【3】声明一个队列(创建一个队列)
# 声明一个交换机(exchange)
channel.exchange_declare(exchange='m1',exchange_type='fanout')
# 【4】发布消息
channel.basic_publish(exchange='m1',
routing_key='',
body='dream nb')
# 【5】关闭连接
connection.close()
- 使用Pika库创建了一个与RabbitMQ服务器的连接
- 然后创建了一个通道(channel)。
- 接下来,我们声明了一个名为'm1'的交换机,并指定其类型为'fanout',这表示消息将被广播到所有订阅者。
- 调用
basic_publish方法,我们将消息发布到名为'm1'的交换机,使用空的routing_key表示该消息将被发送到交换机绑定的所有队列中。
【2】订阅者(启动几次订阅者会生成几个队列)
import pika
# 【1】创建连接并设置认证信息
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
# 【2】创建通道
channel = connection.channel()
# 声明一个交换机(exchange)
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m1',exchange_type='fanout')
# 【3】随机生成一个队列
# 【3.1】
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 【3.2】将队列与交换机绑定
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m1',queue=queue_name)
# 【4】定义回调函数
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 【5】消费消息
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
- 使用相同的连接参数创建了一个新的通道。
- 然后,我们声明了与发布者相同的交换机,并随机生成一个独占的队列。
- 随后,我们通过调用
queue_bind方法将队列与交换机进行绑定,这样队列就能接收到交换机发来的消息。
- 接下来,我们定义了一个回调函数
callback,当订阅者接收到消息时,该函数会被调用。
- 最后,我们通过调用
basic_consume方法开始消费消息。
- 订阅者会一直等待,直到接收到消息,并调用回调函数进行处理。
【3】小结
- 1 生产者扔给交换机消息
- 2 交换机根据自身的类型将会把所有消息复制同步到所有与其绑定的队列
- 3 每个队列可以有一个消费者,接收消息进行消费逻辑
【4】应用场景
【5】场景
- 有一个商城,我们新添加一个商品后,可能同时需要去更新缓存和数据库
【二】发布订阅高级之Routing(按关键字匹配)
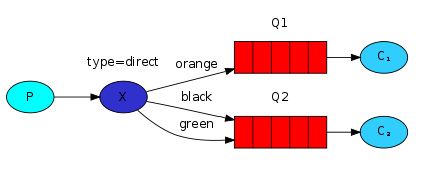
【1】发布者
import pika
# 【1】创建连接并设置认证信息
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
# 【2】创建通道
channel = connection.channel()
# 【3】声明一个队列(创建一个队列)
# 声明一个交换机(exchange)
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 【4】发布消息
channel.basic_publish(exchange='m2',
routing_key='bnb', # 多个关键字,指定routing_key
body='dream nb')
# 【5】关闭连接
connection.close()
- 首先使用给定的认证信息来建立与消息队列服务器的连接。
- 接下来,创建一个通道,所有的API调用都是通过通道进行的。
- 然后,声明一个交换机(exchange),这里使用了
direct类型的交换机。
- 在发布消息时,指定了交换机名称为
m2,并将消息发送到路由键bnb。
- 最后,关闭连接。
【2】订阅者1
import pika
# 【1】创建连接并设置认证信息
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
# 【2】创建通道
channel = connection.channel()
# 【3】声明交换机
# exchange='m1',exchange(秘书)的名称
# exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 【4】随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 【5】将队列与交换机进行绑定
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='nb')
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='bnb')
# 【6】定义回调函数
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 【7】消费消息
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
- 首先建立与消息队列服务器的连接,并创建一个通道。
- 然后,声明交换机,与发布者使用相同的交换机名称和类型。
- 接着,随机生成一个队列,并将该队列与交换机通过路由键
nb和bnb进行绑定。
- 定义了一个回调函数用于处理接收到的消息,并使用
basic_consume函数开始消费消息。
【3】订阅者2
import pika
# 【1】创建连接并设置认证信息
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 【2】声明交换机
# exchange='m1',exchange(秘书)的名称
# exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 【3】随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 【4】将队列与交换机进行绑定
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='nb')
# 【5】定义回调函数
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 【6】消费消息
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
# 【7】开始消费消息
channel.start_consuming()
- 订阅者2的代码与订阅者1类似,它也会建立与消息队列服务器的连接,并创建一个通道。
- 然后,声明交换机,并生成一个随机队列。
- 将这个队列与交换机绑定通过路由键
nb,定义了一个回调函数用于处理接收到的消息,并开始消费消息。
【4】小结
- 发布者向交换机
m2发送一条消息,路由键为bnb。
- 订阅者1和订阅者2都绑定了交换机
m2并监听不同的路由键,订阅者1监听nb和bnb,订阅者2只监听nb。
- 当有消息被发送到交换机时,与之匹配的订阅者将接收到消息并执行回调函数。
- 1 生产者还是将消息发送给交换机,消息携带具体的路由key(routingKey)
- 2 交换机类型direct,将接收到的消息中的routingKey,比对与之绑定的队列的routingKey
- 3 消费者监听一个队列,获取消息,执行消费逻辑
【5】应用场景
- 根据生产者的要求发送给特定的一个或者一批队列;
- 错误的通报;
【6】场景
- 还是一样,有一个商城,新添加了一个商品,实时性不是很高,只需要添加到数据库即可,不用刷新缓存
【三】发布订阅高级之Topic(按关键字模糊匹配)
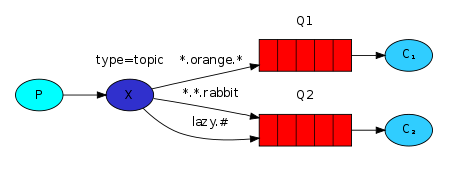
【1】发布者
import pika
# 【1】连接到RabbitMQ服务器
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 【2】声明一个topic类型的交换机
channel.exchange_declare(exchange='m3',exchange_type='topic')
# 【3】发布消息到交换机
channel.basic_publish(exchange='m3',
# routing_key='dream.handsome', #都能收到
routing_key='dream.handsome.xx', #只有dream.#能收到
body='dream nb')
# 【4】关闭连接
connection.close()
- 发布者通过连接到RabbitMQ服务器并创建一个通道(channel)。
- 然后声明了一个名为'm3'的交换机(exchange),类型为'topic'。
- 交换机的作用是将消息发送给相应的队列。
【2】订阅者1
import pika
# 【1】连接到RabbitMQ服务器
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 【2】声明一个topic类型的交换机
# exchange='m1',exchange(秘书)的名称
# exchange_type='direct' , 秘书工作方式将消息发送给不同的关键字
channel.exchange_declare(exchange='m3',exchange_type='topic')
# 【3】随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 【4】将队列绑定到交换机上,指定路由键为'dream.#'
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m3',queue=queue_name,routing_key='dream.#')
# 【5】设置接收消息的回调函数
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
- 订阅者1首先连接到RabbitMQ服务器,并创建一个通道。
- 然后声明了一个名字为空的队列,该队列是一个随机生成的独占队列,用来接收消息。
- 接着绑定队列到交换机上,并指定路由键为'dream.#',表示订阅所有以'dream.'开头的消息。
- 最后定义一个回调函数,在接收到消息时进行处理。
【3】订阅者2
import pika
# 【1】连接到RabbitMQ服务器
credentials = pika.PlainCredentials("admin","admin")
connection = pika.BlockingConnection(pika.ConnectionParameters('101.133.225.166',credentials=credentials))
channel = connection.channel()
# 【2】声明一个topic类型的交换机
# exchange='m1',exchange(秘书)的名称
# exchange_type='topic' , 模糊匹配
channel.exchange_declare(exchange='m3',exchange_type='topic')
# 【3】随机生成一个队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
# 【4】将队列绑定到交换机上,指定路由键为'dream.*'
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m3',queue=queue_name,routing_key='dream.*')
# 【5】设置接收消息的回调函数
def callback(ch, method, properties, body):
queue_name = result.method.queue # 发送的routing_key是什么
print("消费者接受到了任务: %r" % body)
channel.basic_consume(queue=queue_name,on_message_callback=callback,auto_ack=True)
channel.start_consuming()
- 订阅者2的代码与订阅者1的代码相似,区别在于路由键的设置。
- 这里使用了通配符'*'来匹配一个单词,表示只订阅以'dream.'开头并且只有一个单词的消息
【4】小结
- 这个发布订阅模式可以用于在分布式系统中实现解耦合的消息传递。
- 通过使用交换机和不同的路由键,发布者可以将消息发送到不同的队列,而订阅者只需要关注自己感兴趣的消息,提高了系统的可扩展性和灵活性。
- 1 生产端发送消息,消息携带具体的路由key
- 2 交换机的类型topic
- 3 队列绑定交换机不在使用具体的路由key而是一个范围值
.orange. : haha.orange.haha,haha.haha.orange.hahalazy.# : haha.lazy.haha.haha,layz.alsdhfsh(sh9ou)N0*表示一个字符串(不能携带特殊符号) 例如 *表示 haha,item,update#表示任意字符串
【5】场景
- 还是一样,有一个商城,新添加了一个商品,实时性不是很高,只需要添加到数据库即可,数据库包含了主数据库mysql1和从数据库mysql2的内容,不用刷新缓存
标签:订阅,
pika,
exchange,
队列,
RabbitMQ,
queue,
交换机,
6.0,
channel
From: https://www.cnblogs.com/dream-ze/p/17691740.html