【引入】
【1】为什么要使用分布式锁
- 我们在开发应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的锁进行处理,并且可以完美的运行,毫无Bug!
- 注意这是单机应用,后来业务发展,需要做集群,一个应用需要部署到几台机器上然后做负载均衡,大致如下图:
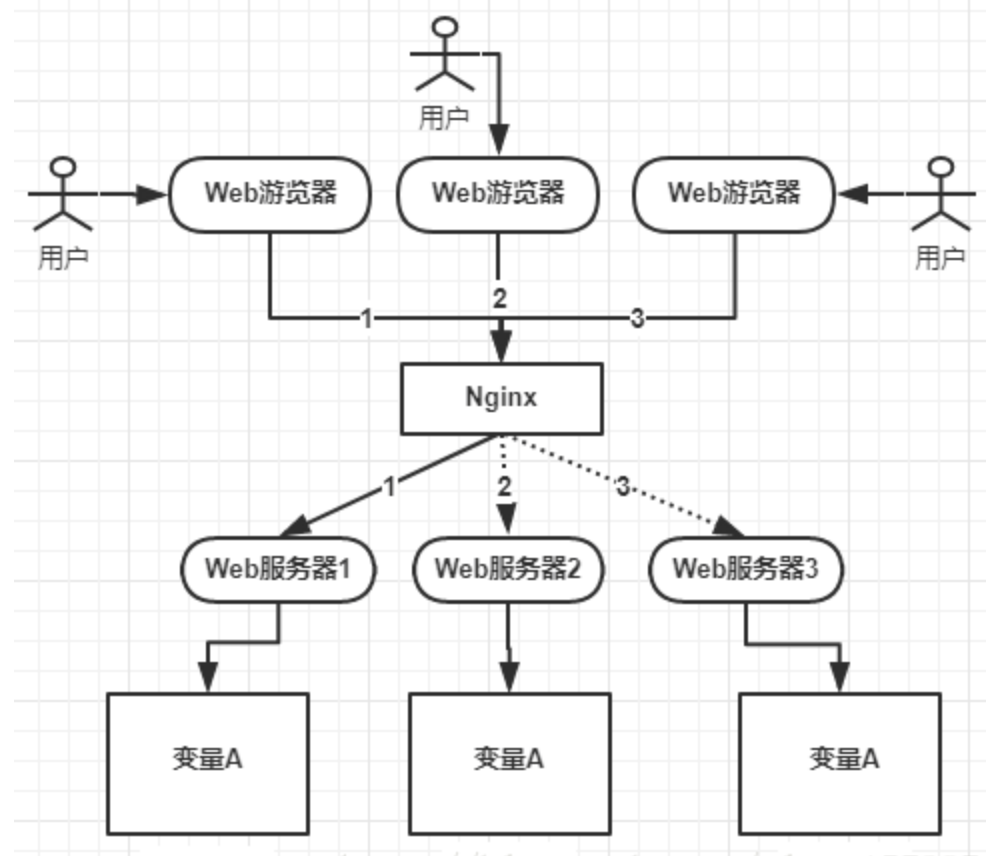
- 上图可以看到
- 变量A存在三个服务器内存中(这个变量A主要体现是在一个类中的一个成员变量,是一个有状态的对象)
- 如果不加任何控制的话,变量A同时都会在分配一块内存,三个请求发过来同时对这个变量操作,显然结果是不对的!
- 即使不是同时发过来,三个请求分别操作三个不同内存区域的数据,变量A之间不存在共享,也不具有可见性,处理的结果也是不对的!
- 如果我们业务中确实存在这个场景的话,我们就需要一种方法解决这个问题!
- 为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用并发处理相关的功能进行互斥控制。
- 但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的应用并不能提供分布式锁的能力。
- 为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
【一】分布式系统中加锁-悲观锁
【1】MySQL行锁
- 在分布式系统中,悲观锁可以通过数据库的行锁实现。
- 当多个线程或多个机器同时访问数据库的同一行数据时,行锁可以确保只有一个线程或机器可以对该行进行写操作,以保证数据的一致性。
案例:
- 假设有一个订单表,在多个机器上同时处理订单,我们可以使用MySQL行锁来确保同一时间只有一个机器可以修改订单行。
- 这样可以避免不同机器之间的并发冲突,保证订单数据的一致性。
-- 获取订单行锁
SELECT * FROM orders WHERE order_id = 123 FOR UPDATE;
-- 修改订单数据
UPDATE orders SET status = 'completed' WHERE order_id = 123;
-- 释放订单行锁
COMMIT;
【2】性能更高的分布式锁
- 在高并发环境下,使用数据库行锁的方式可能会导致性能问题。
- 因此,分布式系统中还存在其他性能更高的分布式锁的实现方式。
案例:
- 常见的性能更高的分布式锁实现方式之一是基于缓存(如Redis)来实现。
- 通过在缓存中设置一个特殊的键值对,可以表示某个资源是否被锁定。
- 多个机器或线程可以通过操作缓存来争夺获取锁的权限。
- 以下是使用Redis作为分布式锁的示例代码:
import redis
# 连接Redis服务器
redis_conn = redis.Redis(host='localhost', port=6379)
# 获取锁
lock_acquired = redis_conn.set('my_lock', 'locked', nx=True, ex=10)
if lock_acquired:
# 获得了锁,执行需要加锁的操作
print("Lock acquired. Start processing...")
# 执行加锁的操作
# 释放锁
redis_conn.delete('my_lock')
else:
# 未获得锁,处理加锁失败的逻辑
print("Failed to acquire lock. Try again later.")
- 在以上案例中,我们使用Redis的
set命令来尝试获取锁,并设置键的生存时间(过期时间),以确保即使出现异常情况导致锁未正常释放,锁也会在一定时间后自动释放。 - 当锁被成功获取时,我们可以执行需要加锁的操作,然后再最后释放锁。
【二】Python线程锁
案例:
- 在线程编程中,可以使用Python内置的
threading模块提供的锁机制实现线程锁。 - 通过使用锁对象,可以在多个线程之间实现对共享资源的互斥访问。
- 以下是使用Python线程锁的示例代码:
import threading
# 创建锁对象
lock = threading.Lock()
# 定义需要加锁的函数或代码块
def locked_function():
lock.acquire()
try:
# 加锁的操作
print("Locked function executed.")
finally:
lock.release()
# 创建并启动多个线程
thread1 = threading.Thread(target=locked_function)
thread2 = threading.Thread(target=locked_function)
thread1.start()
thread2.start()
- 在以上案例中,我们首先创建一个
Lock对象。然后,在需要加锁的函数或代码块中,通过调用acquire方法获取锁,在完成操作后再调用release方法释放锁。 - 这样,就可以确保同一时间只有一个线程能够执行被锁定的部分代码,以避免并发冲突和数据竞争。
【三】分布式锁具备的条件和实现方式
【1】分布式锁具备条件
-
分布式锁是在分布式系统中为实现同步和互斥而设计的。
-
它具备一些特定的条件和功能,如下所示:
-
在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行。
-
高可用性:能够在高并发环境下保证锁的可用性。
-
高性能:能够提供高效的加锁和释放锁的性能。
-
可重入特性:允许同一个线程或机器多次获取同一个锁,以避免死锁。
-
锁失效机制:具备自动锁失效功能,防止锁被长期占用导致的死锁问题。
-
非阻塞锁特性:能够通过直接返回获取锁失败来避免阻塞。
-
【2】多种方式可以实现分布式锁:
- 目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。
- 分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。
- ”所以,很多系统在设计之初就要对这三者做出取舍。
- 在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
- 在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持
- 比如分布式事务、分布式锁等。
- 有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。
-
基于数据库实现分布式锁:可以使用数据库的行锁等机制实现分布式锁,但性能可能不高。
-
基于缓存(如Redis)实现分布式锁:Redis提供了原子性的操作,可以很方便地实现分布式锁。
-
基于ZooKeeper实现分布式锁:ZooKeeper是一个分布式协调服务,可以作为分布式锁的实现基础。
【四】官方 Redlock 实现Redis分布式锁
# pip3 install redlock-py
from redlock import Redlock
import time
dlm = Redlock([{"host": "localhost", "port": 6379, "db": 0}, ])
# 获得锁
my_lock = dlm.lock("my_resource_name",1000)
# 业务逻辑代码
print('sdfasdf')
time.sleep(20)
# 释放锁
dlm.unlock(my_lock)
- 这个代码可以放在任意的节点上,使用的是分布式锁,某个节点获取到锁后,别的节点获取不到,操作数据,释放锁后,别的节点的线程才能操作数据
【五】基于数据库的实现方式
- 基于数据库的实现方式的核心思想是:
- 在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
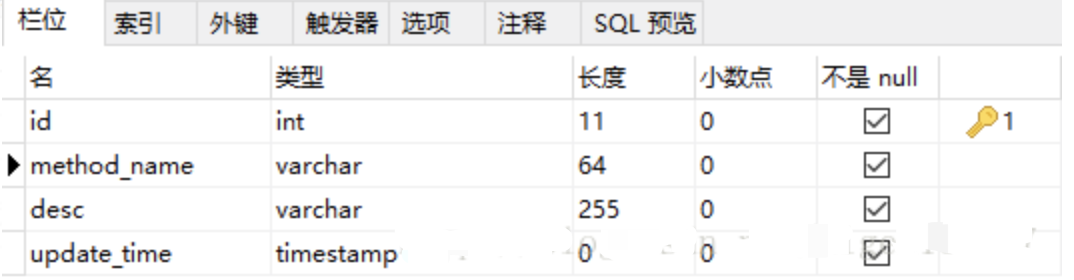
【1】创建一个表
DROP TABLE IF EXISTS `method_lock`;
CREATE TABLE `method_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',
`desc` varchar(255) NOT NULL COMMENT '备注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
【2】执行方法
- 想要执行某个方法,就使用这个方法名向表中插入数据:
INSERT INTO method_lock (method_name, desc) VALUES ('methodName', '测试的methodName');
- 因为我们对
method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
【3】执行完成
- 成功插入则获取锁,执行完成后删除对应的行数据释放锁:
delete from method_lock where method_name ='methodName';
- 注意:这只是使用基于数据库的一种方法,使用数据库实现分布式锁还有很多其他的玩法!
【4】优化问题
-
使用基于数据库的这种实现方式很简单
-
但是对于分布式锁应该具备的条件来说,它有一些问题需要解决及优化:
-
1、因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换;
-
2、不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;
-
3、没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
-
4、不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
-
5、在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
-
【六】自己基于Redis实现分布式锁
【1】选用Redis实现分布式锁原因
- (1)Redis有很高的性能;
- (2)Redis命令对此支持较好,实现起来比较方便
【2】使用命令介绍
(1)SETNX
- SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire
- expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
- delete key:删除key
- 在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
【3】实现思想
- (1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
- (2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
- (3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
- SETNX:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做
- expire:超过这个时间锁会自动释放,避免死锁
- delete:Redis实现分布式锁的时候删除锁
-
分布式锁是一种常用的机制,用于在分布式系统环境下实现资源的互斥访问。
-
基于Redis实现了一个简单的分布式锁。
-
使用
SETNX指令尝试创建一个名为lock的键,该键存储唯一标识符identifier,只有在该键不存在时才能成功创建,并返回1;如果该键已经存在,则说明锁已经被其他客户端持有,无法获取锁。 -
为了避免死锁,需要设置锁的超时时间(
expire),确保在一定时间后即使锁未被主动释放,也会自动过期释放。 -
若获取到锁,则返回唯一标识符
identifier,表示获取锁成功。 -
若未能在规定的等待时间内获取到锁,返回False,表示获取锁失败。
-
-
对于释放锁的过程:
-
首先需要对比存储在
lock键中的值是否与传入的唯一标识符identifier一致,以防止其他客户端释放了不属于自己的锁。 -
如果匹配成功,执行
DELETE指令,删除lock键,并返回True表示锁成功释放。 -
如果匹配失败,则说明锁已经被其他客户端重新获取,返回False表示释放锁失败。
-
【4】分布式锁的简单实现代码
import redis
import uuid
import time
from threading import Thread,get_ident
# 连接redis
redis_client = redis.Redis(host="localhost",
port=6379,
# password=password,
db=10)
# 获取一个锁
# lock_name:锁定名称
# acquire_time: 客户端等待获取锁的时间
# time_out: 锁的超时时间
def acquire_lock(lock_name, acquire_time=10, time_out=10):
"""获取一个分布式锁"""
identifier = str(uuid.uuid4())
end = time.time() + acquire_time
lock = "string:lock:" + lock_name
while time.time() < end:
if redis_client.setnx(lock, identifier):
# 给锁设置超时时间, 防止进程崩溃导致其他进程无法获取锁
redis_client.expire(lock, time_out)
return identifier
elif not redis_client.ttl(lock):
redis_client.expire(lock, time_out)
time.sleep(0.001)
return False
# 释放一个锁
def release_lock(lock_name, identifier):
"""通用的锁释放函数"""
lock = "string:lock:" + lock_name
pip = redis_client.pipeline(True)
while True:
try:
pip.watch(lock)
lock_value = redis_client.get(lock)
if not lock_value:
return True
if lock_value.decode() == identifier:
pip.multi()
pip.delete(lock)
pip.execute()
return True
pip.unwatch()
break
except redis.excetions.WacthcError:
pass
return False
def seckill():
identifier = acquire_lock('resource')
print(get_ident(), "获得了锁")
release_lock('resource', identifier)
if __name__ == '__main__':
for i in range(50):
t = Thread(target=seckill)
t.start()
- 使用了
acquire_lock()函数尝试获取名为resource的分布式锁。- 如果成功获取到锁,则输出线程ID并执行相应的业务逻辑;
- 如果未能获取锁,则继续等待或执行其他处理。
- 在业务逻辑执行完毕后,通过调用
release_lock()函数释放锁。
【5】测试刚才实现的分布式锁
- 例子中使用50个线程模拟秒杀一个商品,使用–运算符来实现商品减少,从结果有序性就可以看出是否为加锁状态。
def seckill():
identifier=acquire_lock('resource')
print(Thread.getName(),"获得了锁")
release_lock('resource',identifier)
for i in range(50):
t = Thread(target=seckill)
t.start()
【七】基于ZooKeeper的实现方式
-
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
-
基于ZooKeeper实现分布式锁的步骤如下:
-
(1)创建一个目录mylock;
-
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
-
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
-
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
-
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
-
-
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
-
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
-
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
【八】总结
- 上面的三种实现方式,没有在所有场合都是完美的,所以,应根据不同的应用场景选择最适合的实现方式。
- 在分布式环境中,对资源进行上锁有时候是很重要的,比如抢购某一资源,这时候使用分布式锁就可以很好地控制资源。
- 当然,在具体使用中,还需要考虑很多因素,比如超时时间的选取,获取锁时间的选取对并发量都有很大的影响,上述实现的分布式锁也只是一种简单的实现,主要是一种思想
【补充】分布式系统全局唯一ID生成
【1】什么是分布式系统唯一ID
- 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
- 如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
【2】分布式系统唯一ID的特点

- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
- 同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高
- 想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
-
由此总结下一个ID生成系统应该做到如下几点:
-
平均延迟和TP999延迟都要尽可能低(TP90就是满足百分之九十的网络请求所需要的最低耗时。TP99就是满足百分之九十九的网络请求所需要的最低耗时。同理TP999就是满足千分之九百九十九的网络请求所需要的最低耗时);
-
可用性5个9(99.999%);
-
高QPS。
-
补充:QPS和TPS
- QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
- TPS:是TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数
【3】分布式系统唯一ID的实现方案

(1)UUID
- UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符
- 示例:550e8400-e29b-41d4-a716-446655440000
- 到目前为止业界一共有5种方式生成UUID
- 详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点:
- 性能非常高:本地生成,没有网络消耗。
缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用
在Python的uuid模块中,确实没有uuid2这个函数。原因是在标准库的uuid模块中,UUID被分类为四个不同的版本:uuid1、uuid3、uuid4和uuid5。
uuid1:基于主机的MAC地址和时间戳生成,具有全球唯一性。
uuid3和uuid5:基于名称空间和名称生成,保证了相同输入生成相同的输出,适合用于指定名称的命名空间中。
uuid4:基于随机数生成,具有较低的碰撞概率。
而uuid2是一种DCE安全版本的UUID,但很少用到。
- 在RFC 4122规范中,已经弃用了uuid2,并推荐使用uuid4来生成UUID。
- 所以Python的uuid模块没有提供uuid2函数。
如果你需要使用DCE安全版本的UUID(uuid2),你可以考虑使用第三方库或自己实现该算法来生成相应的UUID。
(2)数据库生成
- 以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。

这种方案的优缺点如下:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
(3)Redis生成ID
- 当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。
- 这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
- 比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
- 1)不依赖于数据库,灵活方便,且性能优于数据库。
- 2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 2)需要编码和配置的工作量比较大。
(4)利用zookeeper(分布式应用程序协调服务)生成唯一ID
- zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
- 很少会使用zookeeper来生成唯一ID。
- 主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。
- 因此,性能在高并发的分布式环境下,也不甚理想。
(5)snowflake(雪花算法)方案
- 这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:

- 41-bit的时间可以表示(1L<<41)/(1000L360024*365)=69年的时间,10-bit机器可以分别表示1024台机器。
- 如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。
- 这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。
- 12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。