前言 本文研究了 Transformer 类模型结构(configration)设计(即模型深度和宽度)与训练目标之间的关系。结论是:token 级的训练目标(如 masked token prediction)相对更适合扩展更深层的模型,而 sequence 级的训练目标(如语句分类)则相对不适合训练深层神经网络,在训练时会遇到 over-smoothing problem。在配置模型的结构时,我们应该注意模型的训练目标。
本文转载自PaperWeekly
作者:陈江海
单位:南开大学
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
本文旨在介绍 ICML 2023 的工作:

论文标题:A Study on Transformer Configuration and Training Objective
论文链接:
https://arxiv.org/abs/2205.10505
论文作者:
(Fuzhao Xue)薛复昭(Jianghai Chen)陈江海 Aixin Sun, Xiaozhe Ren, Zangwei Zheng, Xiaoxin He, Yongming Chen, Xin Jiang, Yang You
1. TL;DR
一般而言,在我们讨论不同的模型时,为了比较的公平,我们会采用相同的配置。然而,如果某个模型只是因为在结构上更适应训练目标,它可能会在比较中胜出。对于不同的训练任务,如果没有进行相应的模型配置搜索,它的潜力可能会被低估。因此,为了充分理解每个新颖训练目标的应用潜力,我们建议研究者进行合理的研究并自定义结构配置。
2. 概念解释
下面将集中解释一些概念,以便于快速理解:
2.1 Training Objective(训练目标)
 ▲ Vanilla Classification
▲ Vanilla Classification
 ▲ Mask Autoencoder
▲ Mask Autoencoder
 ▲ Next Token Prediction
▲ Next Token Prediction
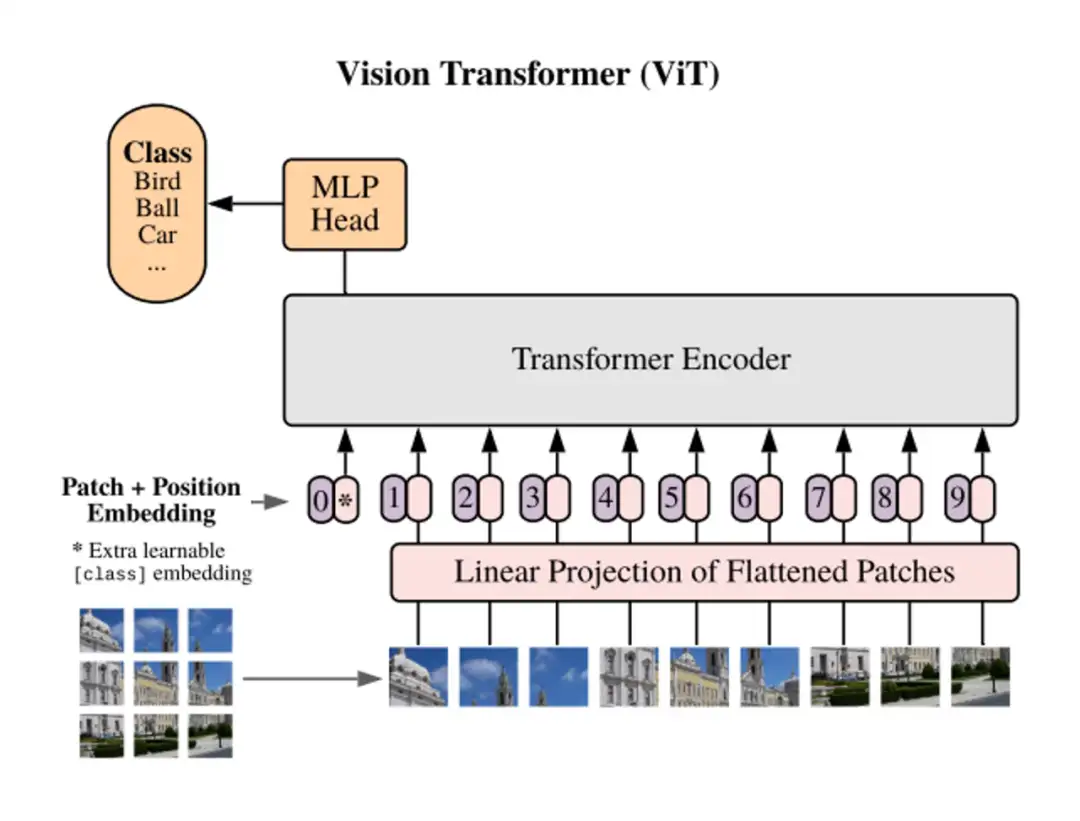
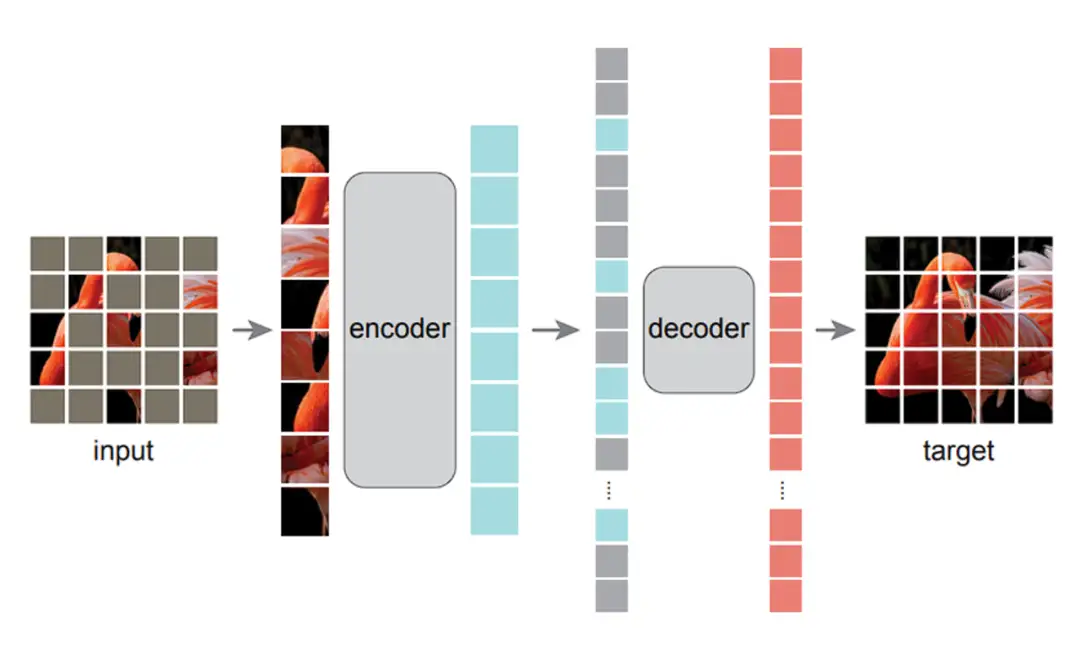
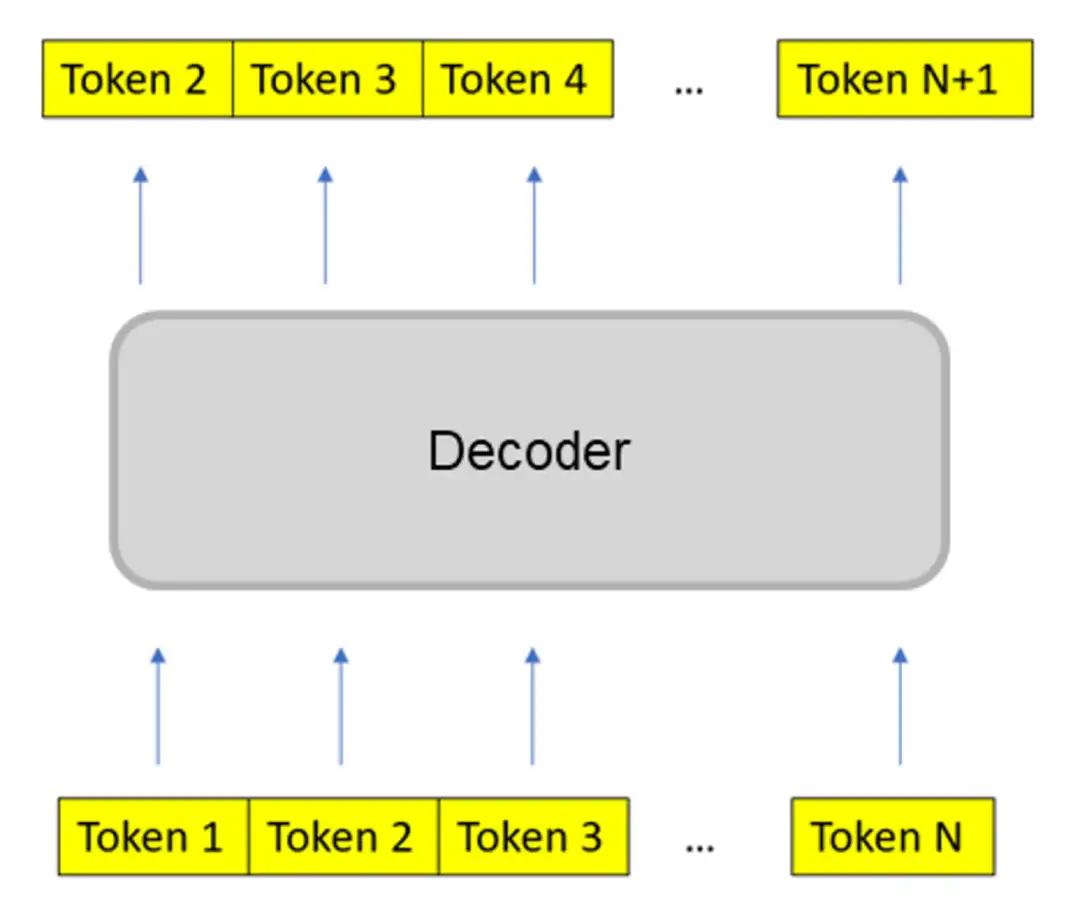
训练目标是模型在训练过程中完成的任务,也可以理解为其需要优化的损失函数。在模型训练的过程中,有多种不同的训练目标可以使用,在此我们列出了 3 种不同的训练目标并将其归类为 token level 和 sequence level:
- sequence level:
- classification 分类任务,作为监督训练任务。简单分类(Vanilla Classification)要求模型对输入直接进行分类,如对句子进行情感分类,对图片进行分类;而 CLIP 的分类任务要求模型将图片与句子进行匹配。
- token level:(无监督)
- masked autoencoder:masked token 预测任务,模型对部分遮盖的输入进行重建
- next token prediction:对序列的下一个 token 进行预测
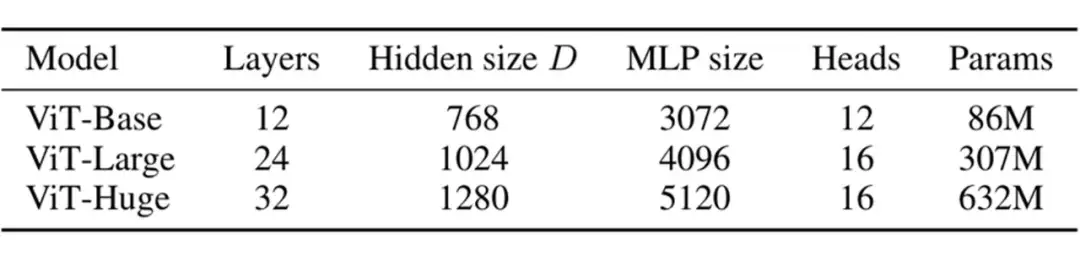
2.2 Transformer Configration(模型结构:配置)
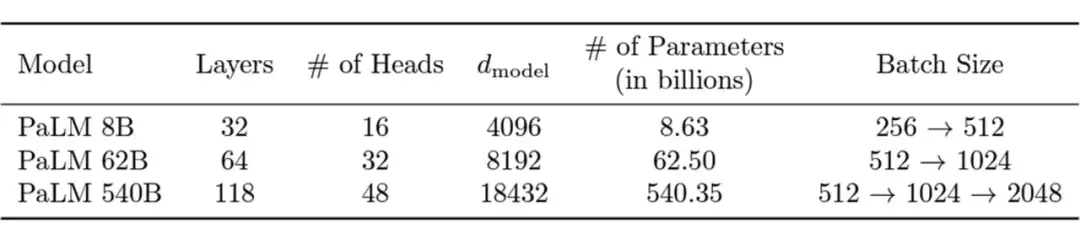 ▲ Configration for Transformers
▲ Configration for Transformers
Transoformer 的配置指的是定义 Transformer 模型结构和大小的超参数,包括层数(深度),隐藏层大小(宽度),注意力头的个数等。
2.3 Over-smoothing (过度平滑)
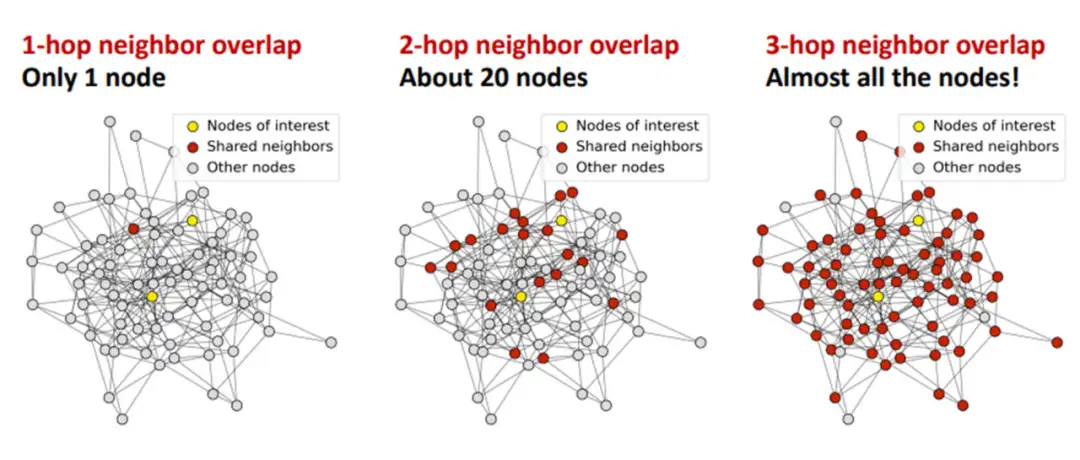 ▲ Over-Smoothing
▲ Over-Smoothing
过度平滑是一个在图神经网络中的概念,具体表示模型输出趋向平滑一致,各个点的输出缺少细节和变化的现象。这一现象在图神经网络中被广泛研究,但它也在 Transformer 模型中存在。(已有研究)发现 Transoformer 模型遇到的 over-smoothing 问题阻碍模型加深。具体而言,当堆叠多层的 Transformer layers 时,transformer layer 输出的 token 表征(向量)会趋于一致,丢失独特性。这阻碍了 Transformer 模型的扩展性,特别是在深度这一维度上。增加 Transformer 模型的深度只带来微小的性能提升,有时甚至会损害原有模型的性能。
1. ViT 和 MAE 中的 over-smoothing
直观上,掩码自编码器框架(例如 BERT、BEiT、MAE)的训练目标是基于未掩码的 unmasked token 恢复被掩码的 masked token。与使用简单分类目标训练 Transformer 相比,掩码自编码器框架采用了序列标注目标。我们先假设掩码自编码器训练能缓解 over-smoothing,这可能是掩码自编码器 MAE 有助于提升 Transformer 性能的原因之一。
由于不同的 masked token 相邻的 unmaksed token 也不同,unmasked token 必须具有充分的语义信息,以准确预测其临近的 masked token。也即,unmasked token 的表征的语义信息是重要的,这抑制了它们趋向一致。总之,我们可以推断掩码自编码器的训练目标通过对 token 间的差异进行正则化,有助于缓解过度平滑问题。
我们通过可视化的实验来验证了这一观点。我们发现 ViT 的 token 表征在更深的层中更加接近,而 MAE 模型则避免了这个问题,这说明在掩码自编码器中,over-smoothing 问题得到了缓解。通过简单的分类任务训练 Transformer 模型则不具备这一特点。
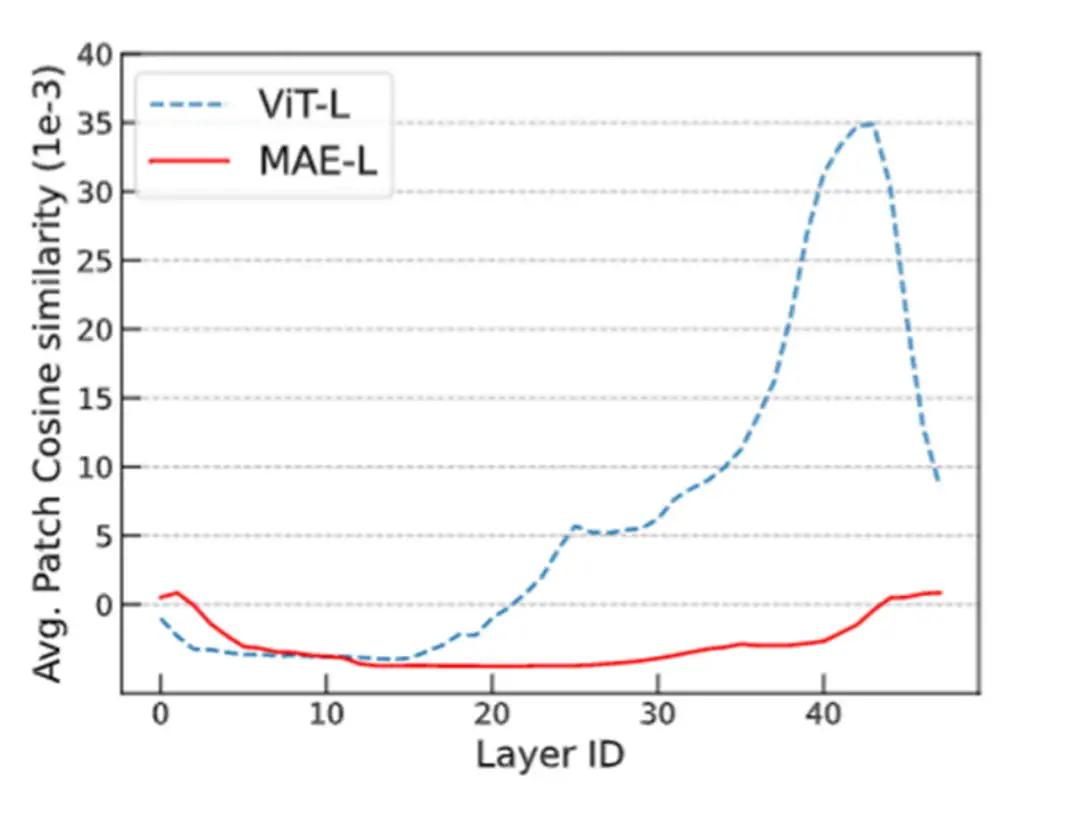 ▲ ViT vs MAE
▲ ViT vs MAE
进一步的,我们还通过傅里叶方法对这一问题进行了研究,具体可以参考我们的论文。
2. CLIP 和 LLM 中的 over-smoothing
根据上述分析,我们可以得出结论:token 级的训练目标(例如语言建模中的:next token prediction)表现出较轻的 over-smoothing。另一方面,基于 sequence 级别的目标(如对比图像预训练)更容易出现 over-smoothing。为了验证这个结论,我们使用 CLIP 和 OPT 进行了类似的 cosine 相似度实验。我们可以看到 CLIP 模型展现了与 Vanilla ViT 类似的 over-smoothing 现象。这一观察结果符合我们的预期。
此外,为了探究 next-token prediction 这一广泛采用的语言建模预训练目标是否可以缓解 over-smoothing,我们对 OPT 进行了评估,并发现它能够有效应对 over-smoothing。这一发现具有重要意义,因为它有助于解释为什么语言建模模型在可扩展性方面(如超大规模预训练语言模型)优于许多视觉模型。
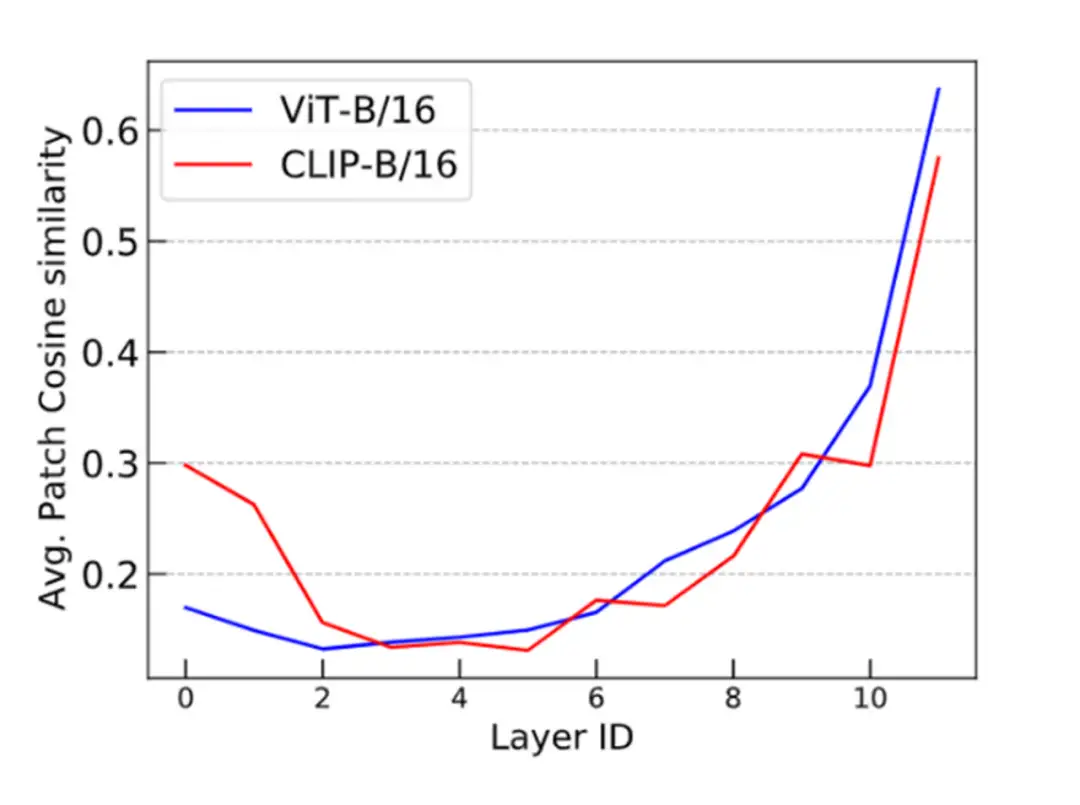 ▲ ViT vs CLIP
▲ ViT vs CLIP
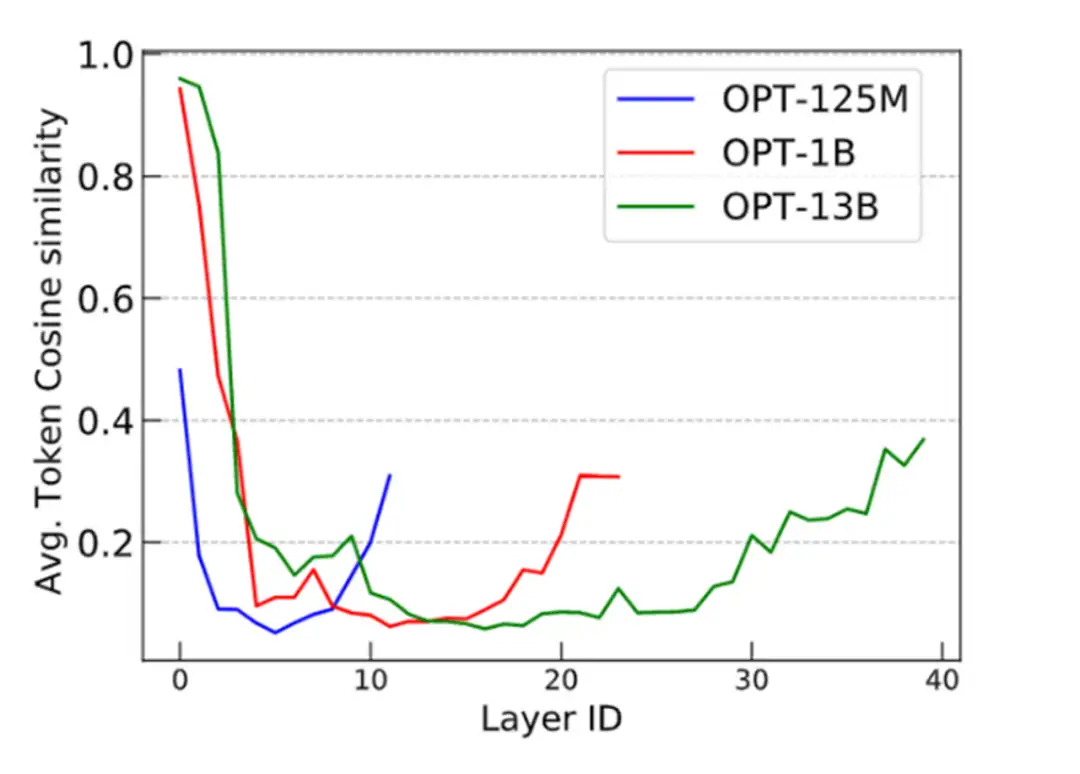 ▲ Different OPTs
▲ Different OPTs
3. 溯源:现有的Transformer架构是怎么来的
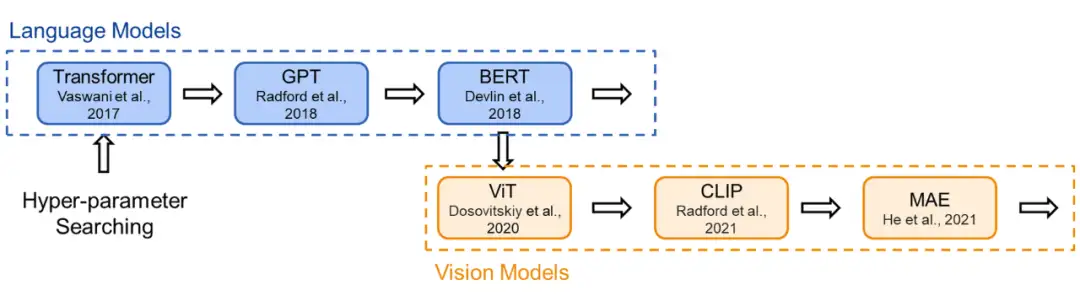 ▲ History for Transformer Configration
▲ History for Transformer Configration
为了在研究时保证公平的比较,现有的 Transformer 类模型通常会遵循固定的结构(small, base, large…),即相同的宽度和深度。比如前面提到的 transformer-base 就是宽度为 768(隐藏层),深度为 12(层数)。然而,对于不同的研究领域,不同的模型功能,为什么仍要采用相同的超参数?
为此,我们首先对 Transformer 架构进行了溯源,回顾了代表性的工作中 Transformer 结构的来源:Vision Transformer 的作者根据 BERT 中 Transformer-base 的结构作为其 ViT 模型配置;而 BERT 在选择配置时遵循了 OpenAI GPT 的方法;OpenAI 则参考了最初的 Transformer 论文。
在最初的 Transformer 论文中,最佳配置来源于机器翻译任务的笑容实验。也就是说,对于不同任务,我们均采用了基于对机器翻译任务的 Transformer 配置。(参考上文,这是一种序列级别的任务)
4. 现状:不同的模型采用不同的训练目标
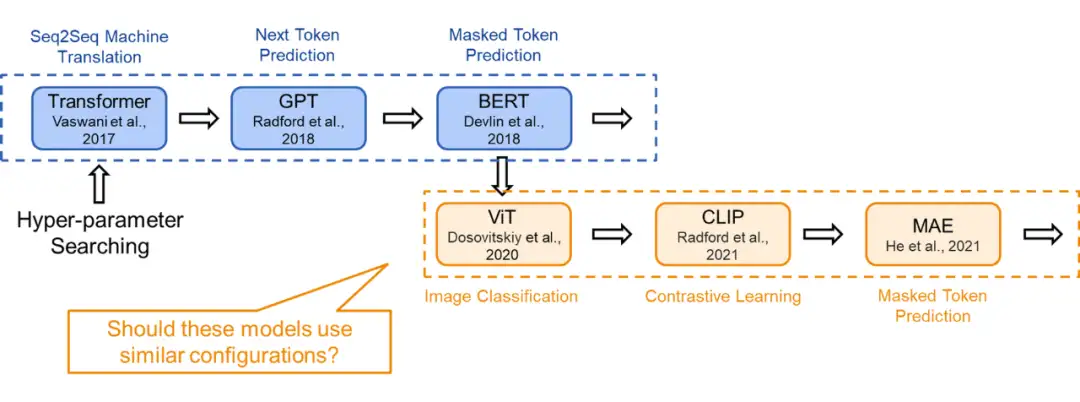 ▲ Different Tasks for Different Models
▲ Different Tasks for Different Models
现在,Transformer 模型通过各种训练目标进行训练。以 ViT 为例,我们可以在图像分类的监督学习环境下从头开始训练 Transformer 模型。在这种直接的图像分类任务中,每个图像被建模为一个 token 序列,其中每个 token 对应图像中的一个图块。我们使用来自图像的所有 token(即图块)的全局信息来预测单个标签,即图像类别。
在这里,由于训练目标是捕捉图像的全局信息,token 表示之间的差异不会直接被考虑。这一训练目标与机器翻译任务完全不同,机器翻译要求模型理解 token 序列,并以此生成另一个序列。
据此,我们可以合理假设对于这两个不同任务,应该存在不同的最佳 Transformer 配置。
5. 对于MAE训练目标调整模型结构
基于上述的讨论,我们得到了如下认识:
- 现有的 Transformer 模型在加深模型深度时会发生 over-smoothing 问题,这阻碍了模型在深度上的拓展。
- 相较于简单分类训练目标,MAE 的掩码预测任务能够缓解 over-smoothing。(进一步地,token 级别的训练目标都能够一定程度地缓解 over-smoothing)
- MAE 的现有模型结构继承于机器翻译任务上的最佳结构设置,不一定合理。
 ▲ Bamboo Configration
▲ Bamboo Configration
综合以上三点,可以推知 MAE 应该能够在深度上更好的拓展,也即使用更深的模型架构。本文探索了 MAE 在更深,更窄的模型设置下的表现:采用本文提出的 Bamboo(更深,更窄)模型配置,我们可以在视觉和语言任务上得到明显的性能提升。
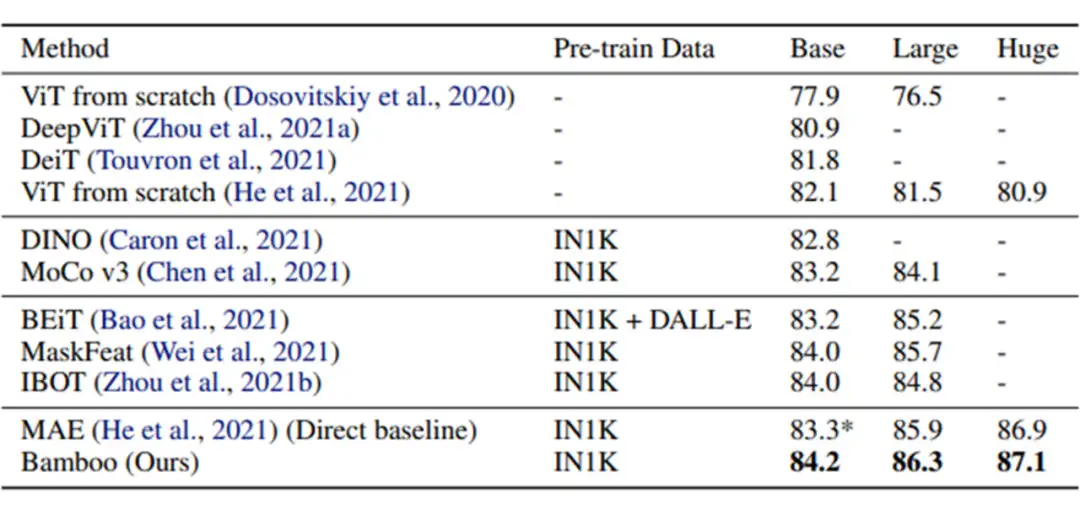 ▲ Vision Experiments
▲ Vision Experiments
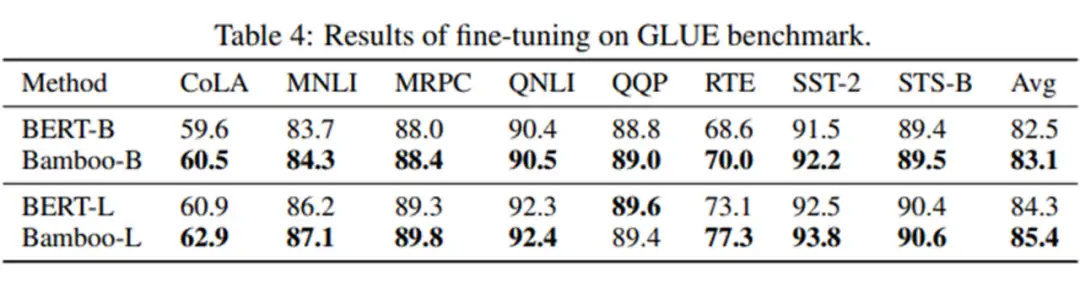 ▲ Language Experiments
▲ Language Experiments
另外,我们在深度拓展性上也做了实验,可以看到,当采用 Bamboo 的配置时,MAE 能够获得明显的性能提升,而对于 ViT 而言,更深的模型则是有害的。MAE 在深度增加到 48 层时仍能获得性能提升,而 ViT 则总是处于性能下降的趋势。
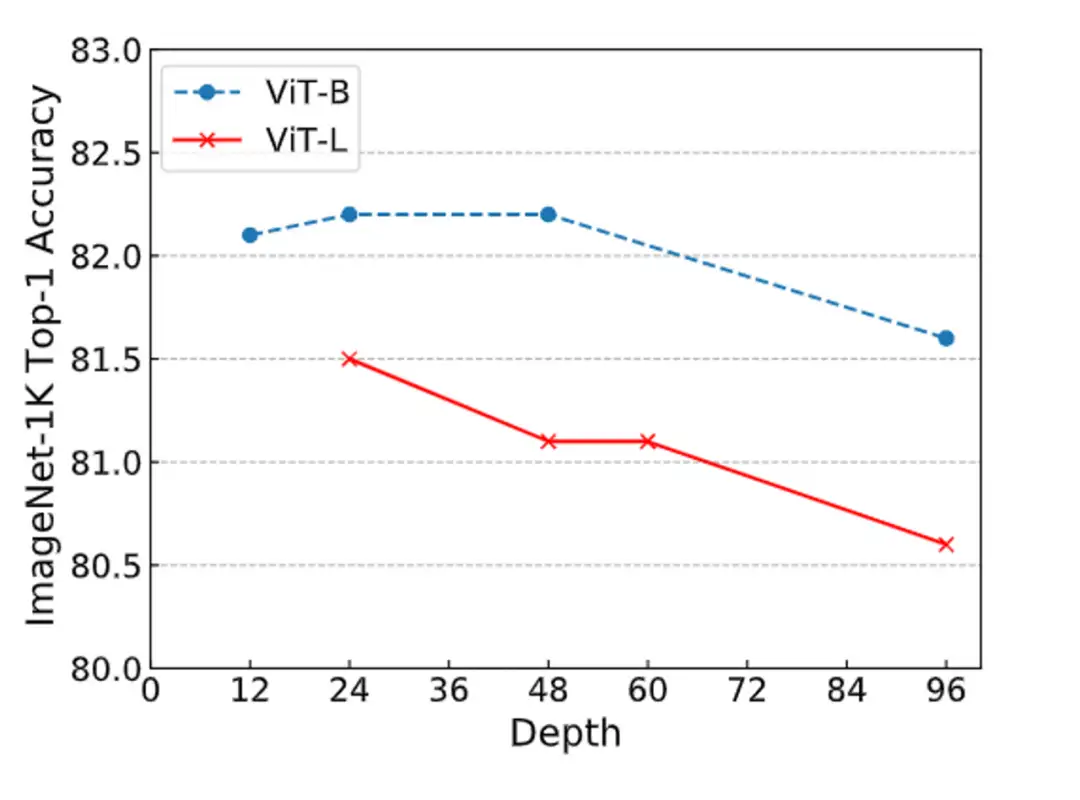 ▲ Scaling of Depth for ViT
▲ Scaling of Depth for ViT
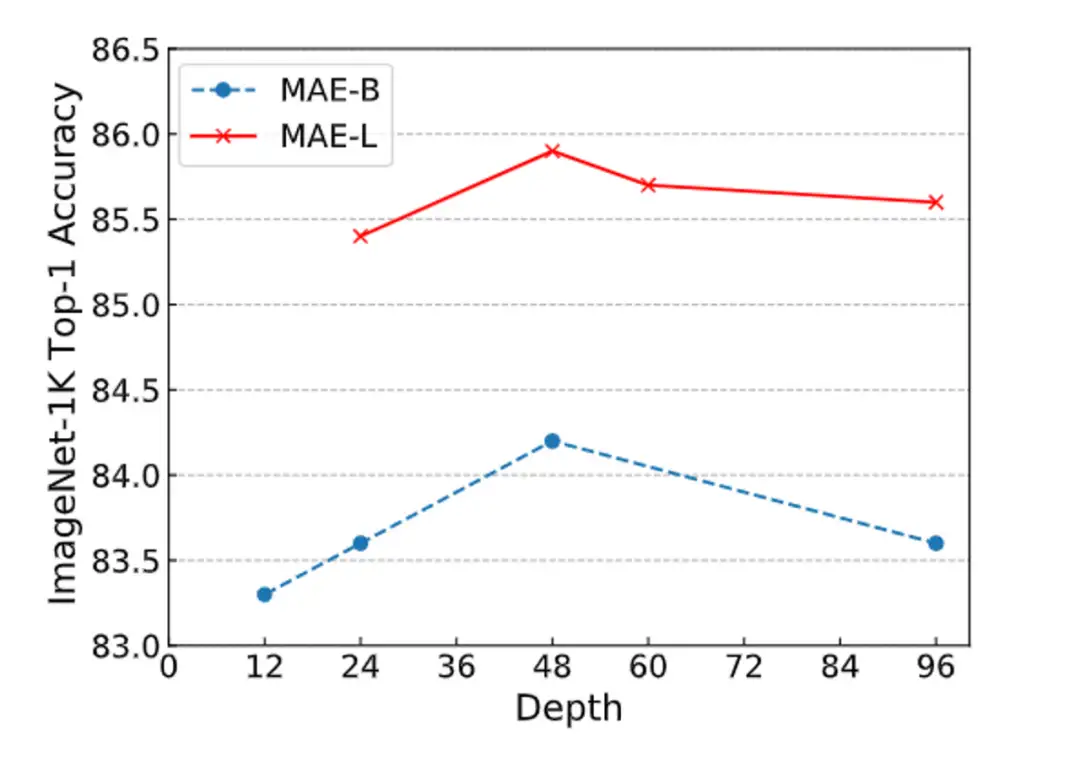 ▲ Scaling of Depth for MAE
▲ Scaling of Depth for MAE
以上的结果佐证了本文提出的观点:训练目标能够影响模型拓展的行为。Training objectives can greatly change the scaling behavior.
6. 结论
本文发现,Transformer 的配置与其训练目标之间存在着密切关系。sequence 级别的训练目标,如直接分类和 CLIP,通常遇到 over-smoothing。而 token 级的训练目标,如 MAE 和 LLMs 的 next token prediction,可以较好地缓解 over-smoothing。这一结论解释了许多模型扩展性研究结果,例如 GPT-based LLMs 的可扩展性以及 MAE 比 ViT 更具扩展性的现象。我们认为这一观点对我们的学术界有助于理解许多 Transformer 模型的扩展行为。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
RecursiveDet | 超越Sparse RCNN,完全端到端目标检测的新曙光
ICCV 2023 | ReDB:可靠、多样、类平衡的域自适应3D检测新方案!
ICCV2023 | 清华大学提出FLatten Transformer,兼顾低计算复杂度和高性能
ICCV'23 | MetaBEV:传感器故障如何解决?港大&诺亚新方案!
RCS-YOLO | 比YOLOv7精度提高了2.6%,推理速度提高了60%
国产130亿参数大模型免费商用!性能超Llama2-13B支持8k上下文,哈工大已用上
KDD 2023奖项出炉!港中文港科大等获最佳论文奖,GNN大牛Leskovec获创新奖
大连理工联合阿里达摩院发布HQTrack | 高精度视频多目标跟踪大模型
ICCV 2023 | Actformer:从单人到多人,迈向更加通用的3D人体动作生成
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:Transformer,训练,ICML,模型,smoothing,token,2023,over From: https://www.cnblogs.com/wxkang/p/17681752.html