栈
394. 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
输入:s = "3[a]2[bc]"
输出:"aaabcbc"
示例 2:
输入:s = "3[a2[c]]"
输出:"accaccacc"
示例 3:
输入:s = "2[abc]3[cd]ef"
输出:"abcabccdcdcdef"
示例 4:
输入:s = "abc3[cd]xyz"
输出:"abccdcdcdxyz"
提示:
1 <= s.length <= 30s由小写英文字母、数字和方括号'[]'组成s保证是一个 有效 的输入。s中所有整数的取值范围为[1, 300]
纯技巧题,栈的常规应用
一种感觉:但凡括号相关(暗含对称)的处理,都可以考虑使用栈
class Solution {
public:
string decodeString(string s) {
stack<int> numStack; // 存放重复次数
stack<string> strStack; // 存放字符串
string curStr = ""; // 当前处理的字符串
int num = 0; // 当前重复次数
for (char c : s) {
if (isdigit(c)) { // 如果是数字,更新重复次数
num = num * 10 + (c - '0');
}
else if (isalpha(c)) { // 如果是字母,直接加入当前字符串中
curStr += c;
}
else if (c == '[') { // 遇到左括号,将当前重复次数和当前字符串入栈,并且重置它们
numStack.push(num);
strStack.push(curStr);
num = 0;
curStr = "";
}
else if (c == ']') { // 遇到右括号,开始处理当前的重复字符串
string temp = curStr;
int repeatTimes = numStack.top(); // 取出重复次数
numStack.pop();
for (int i = 1; i < repeatTimes; ++i) { // 根据重复次数拼接字符串
curStr += temp;
}
curStr = strStack.top() + curStr; // 将拼接好的字符串与之前的字符串拼接
strStack.pop();
}
}
return curStr;
}
};
739. 每日温度
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例 1:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
示例 2:
输入: temperatures = [30,40,50,60]
输出: [1,1,1,0]
示例 3:
输入: temperatures = [30,60,90]
输出: [1,1,0]
提示:
1 <= temperatures.length <= 10530 <= temperatures[i] <= 100
单调栈应用,单调栈的构造过程可以看作原子操作
使用单调栈的思路是维护一个递增或递减的栈,栈中的元素代表数组中的索引,通过栈中的元素可以快速找到左右边界(找到离当前元素最近的较大或较小的元素)。
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int n = temperatures.size(); // 获取温度数组的长度
vector<int> res(n, 0); // 定义一个结果数组,初始化为0
stack<int> st; // 定义一个单调栈,用于存储温度数组的下标
for (int i = n-1; i >= 0; i--) { // 从后往前遍历温度数组
while (!st.empty() && temperatures[i] >= temperatures[st.top()]) { // 如果当前温度大于等于栈顶元素对应的温度
st.pop(); // 弹出栈顶元素
}
if (!st.empty()) { // 如果栈不为空
res[i] = st.top() - i; // 根据栈顶元素对应的下标与当前下标的差值,将结果数组更新
}
st.push(i); // 将当前下标入栈
}
return res; // 返回结果数组
}
};
84. 柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
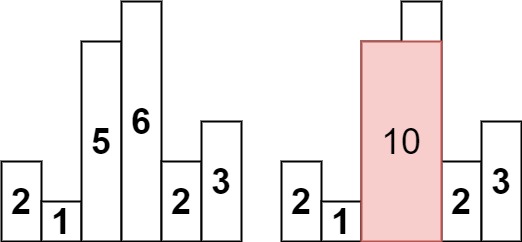
输入:heights = [2,1,5,6,2,3]
输出:10
解释:最大的矩形为图中红色区域,面积为 10
示例 2:
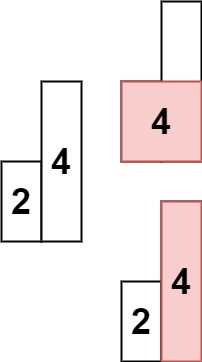
输入: heights = [2,4]
输出: 4
提示:
1 <= heights.length <=1050 <= heights[i] <= 104
单调栈应用,单调栈的构造过程可以看作原子操作
通过维护一个单调递增的栈,可以快速找到以当前元素为高的矩形的左边界和右边界。
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> stk; // 存储最大矩形的下标
int maxArea = 0; // 最大矩形的面积
int index = 0;
// 遍历每一个高度
while (index < heights.size()) {
// 当栈为空或当前高度大于等于栈顶元素,将当前元素下标入栈
if (stk.empty() || heights[index] >= heights[stk.top()]) {
stk.push(index);
index++;
} else {
// 当前高度小于栈顶元素,弹出栈顶元素,并计算面积
int topIndex = stk.top(); // 取出栈顶元素
stk.pop(); // 弹出栈顶元素
int area = heights[topIndex] * (stk.empty() ? index : (index - stk.top() - 1)); // 计算面积
maxArea = max(maxArea, area); // 更新最大面积
}
}
// 处理栈中剩余元素
while (!stk.empty()) {
int topIndex = stk.top();
stk.pop();
int area = heights[topIndex] * (stk.empty() ? index : (index - stk.top() - 1));
maxArea = max(maxArea, area);
}
return maxArea;
}
};
堆
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 **k** 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
如果没有时间复杂度限制,直接先排序,再输出下标为 k-1 的元素,即可轻松解决
因为时间复杂度限制为 O(n),可以考虑引入堆,堆相关操作的时间复杂度:
- 构造一个堆的时间复杂度为O(n),其中n为堆中元素的个数。
- 插入一个元素到堆中的时间复杂度为O(log n)。
- 查找堆中的最大或最小元素的时间复杂度为O(1)。
因为最大或最小元素总是位于堆的根节点。此时堆分别称为最大(根)堆、最小(根)堆
构建堆的空间复杂度是O(1),因为构建堆的过程是在原始数据上进行的,不需要额外的空间。
用堆查找第 k 个最大元素的思路是:首先将数组构建为最大堆,然后不断交换堆顶元素和最后一个元素,并调整堆,直到找到第K个最大元素为止。最后返回第K个最大元素。
将数组调整为最大堆的过程可以看作原子操作
class Solution {
public:
// 将数组调整为最大堆
void adjustHeap(vector<int>& nums, int start, int end) {
int root = start; // 设置当前节点为根节点
while (root * 2 + 1 <= end) { // 如果当前节点有子节点
int child = root * 2 + 1; // 左子节点
if (child + 1 <= end && nums[child] < nums[child + 1]) { // 如果右子节点存在且比左子节点大
child++; // 将子节点指向右子节点
}
if (nums[root] < nums[child]) { // 如果当前节点小于子节点
swap(nums[root], nums[child]); // 交换节点
root = child; // 更新根节点为子节点
} else {
break; // 若当前节点大于子节点,则不需要调整,跳出循环
}
}
}
int findKthLargest(vector<int>& nums, int k) {
int n = nums.size(); // 数组长度
// 构建最大堆
for (int i = n / 2 - 1; i >= 0; i--) { // 从数组的中间位置开始遍历,向前逐步进行调整
adjustHeap(nums, i, n - 1); // 对每个非叶子节点进行调整
}
// 取出第k个最大元素
for (int i = n - 1; i >= n - k + 1; i--) { // 依次将最大的元素放到数组的末尾
swap(nums[0], nums[i]); // 第一个元素与当前最后一个元素交换位置,即将最大元素放到末尾
adjustHeap(nums, 0, i - 1); // 对剩下的元素进行调整
}
return nums[0]; // 返回第k个最大元素
}
}
347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
1 <= nums.length <= 105k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的
算法思路:
首先,我们需要统计每个元素出现的频率。可以使用哈希表来实现。遍历数组,将每个元素作为键,出现的次数作为值,存储在哈希表中。
之后,我们需要找出出现频率前 k 高的元素。可以使用最小堆来实现。遍历哈希表,将元素和对应的频率作为一个pair,存储在最小堆中。如果堆的大小大于 k,就弹出堆中的最小元素。最后,堆中剩下的元素就是出现频率前 k 高的元素。
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
// 创建一个哈希表,用于统计每个数字出现的频率
unordered_map<int, int> frequency;
for (int num : nums) {
frequency[num]++;
}
// 定义一个比较函数,用于构建小顶堆
auto cmp = [](pair<int, int> a, pair<int, int> b) {
return a.second > b.second; // 按照数字出现频率的升序排序
};
// 创建一个小顶堆来保存前k个频率最高的数字(使用优先队列实现)
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp)> minHeap(cmp);
for (auto& entry : frequency) {
minHeap.push(entry);
if (minHeap.size() > k) {
minHeap.pop();
}
}
// 将堆中的数字按照出现频率从高到低加入结果集中
vector<int> topK;
while (!minHeap.empty()) {
topK.push_back(minHeap.top().first);
minHeap.pop();
}
reverse(topK.begin(), topK.end()); // 反转结果集,使结果按照出现频率从高到低排序
return topK;
}
};